记录一下论文中看到的一些对自己可能有用的内容。
-
图像预处理及扩增
在分割之前,进行图像配准,配准过程如下:首先采用阈值分割法(阈值设置为200Hu)将每个病人的CT图像中的颅骨分离出来,然后随机选择一个病人的颅骨图像作为模板,将其他病人的颅骨图像配准到该模板图像获得放射变换矩阵,最后将该仿射变换矩阵应用于对应的PET图像以及标签图像,得到配准后的PET图像以及配准后的标签图像(在口咽癌数据集中,已经有了CT图像和PET图像,但是是否配准过并不清楚,配准这一部分的代码实现,自己还不会)。在数据预处理的最后一步,分别计算被裁剪的PET和CT训练图像的均值和标准差,然后对PET图像和CT图像进行减均值除以标准差操作(这一部分在口咽癌数据集处理方面已经包括了)。训练集计算的均值和标准差也被用于归一化测试集(口咽癌数据集预处理方面的归一化操作好像是训练集用的训练集的均值和标准差,测试集用的测试集的均值和标准差)。
为了增加训练集的数量以及缓解过拟合,本文尝试对现有数据进行在线数据扩增。在训练的过程中,将每个二维 训练图像在5°之内随机地进行旋转,以0.95~1.05之间的一个随机数缩放图像,以15个像素内的一个随机距离对图像进行水平和竖直平移,最后将图像随机地进行左右翻转。(这里旋转的是二维图像,三维图像怎么旋转???) -
本文所使用的网络结构

与现有UNet代码差不多,区别在于通道数以及最后的两个卷积层之前有一个概率为0.5的Dropout层,以缓解过拟合问题。 -
损失函数
在训练用于分割医学图像的网络时,存在一个严重的问题:按照每个类别的像素点的比例计算,类分布是严重不平衡的。例如,就本研究所使用的数据而言,裁剪之后的一个三维图像中非肿瘤像素点的个数占所有像素点总个数的99%以上,即使一个包含肿瘤区域的二维切面中,非肿瘤像素点的比例也在95%以上。这样,模型容易收敛至局部最小值,即将每个像素点都预测为非肿瘤像素点。为了解决这一问题,本文在交叉熵误差函数中赋予每个像素点一个额外的权重系数,权重系数定义如下:
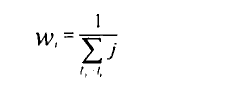
简单而言,就是按照每个类别的像素点的总个数的倒数来加权该类像素点的误差函数。这样,由于肿瘤像素点的总个数要比非肿瘤像素点的总个数少得多,所以肿瘤像素点的误差将获得一个非常大的权重系数。(每个类别的像素点的总个数怎么求呢?按下文中的意思,应该是统计标签中每个类别的像素点的总个数进行计算。)
另外,通过观察发现肿瘤的边界像素点很容易预测错误,因此,考虑增大靠近肿瘤边界的非肿瘤像素点的误差函数的权重。先用一个半径为R的盘形结构元对二值标签进行膨胀操作,然后用膨胀后的标签计算上述的权重系数。这样,靠近肿瘤边界的非肿瘤像素点的误差函数就获得了和肿瘤像素点一样大的权重系数。(为什么要有和肿瘤像素点一样大的权重系数呢?因为非肿瘤像素点的权重系数很小,所以靠近肿瘤的部分很容易预测错,也就是把非肿瘤像素点预测为肿瘤像素点,增大权重系数之后,就减少了预测错误的概率。)
上述是交叉熵损失函数。
下面讲一下Dice损失函数。Dice损失函数的定义如下:
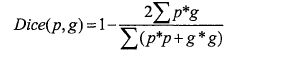
其中,p,g分别表示网络预测结果和真值标签,*表示点乘。
Focal损失函数
对于二分类问题,交叉熵损失函数定义为:



因为本研究所使用的数据负样本的数量远大于正样本的数量,设置alpha为0.9。另外,gama设置为2。
4. 后处理
后处理阶段包括两个简单的步骤用于减少假阳性像素点的个数。(1)在二维切面中,肿瘤区域的面积一般大于某个小的阈值,而一些零星的小块可能错误地被预测为肿瘤区域,针对这个问题,在每个二维切面的预测结果中将面积小于150个像素点的小块标记为非肿瘤区域。(2)鼻咽部肿瘤一般出现在鼻咽前壁和咽部凹陷处,这意味着肿瘤的位置是先对固定的且连续的,因此,在将二维预测结果拼接获得的三维预测中,仅最长相连的预测有肿瘤的切面被保留作为肿瘤区域,其他所有的切面都标记为非肿瘤区域。(没有很懂,最长相连的预测有肿瘤的切面?)
5. 对U-Net的改进

为了提取高度具有表达力的特征,U-Net的网络结构非常深,且每次池化操作后的第一次卷积运算的输出通道数都变为原来的两倍,最小分辨率的特征图的通道数达到了1024,这导致有大量的权重系数需要训练。而本研究所获取到的数据集优先,用一个小的数据集训练如此多的参数及如此深的网络,可能会存在梯度小时的问题,使得千层的权重系数并没有别训练到最优。因此,考虑将辅助路径添加至网络中,辅助路径引入的深度监督直接指导中低隐藏层的训练,使其权重系数获得更大的梯度信息以随着训练过程进行更好地更新。如图所示,三个辅助路径添加至主网络的上采样部分,根据添加辅助路径的特征图的大小,辅助路径1、辅助路径2、辅助路径3分别应用1次、2次、3次反卷积操作获得与输入图像相同大小的特征图。随后,采用1x1的卷积运算获得标签概率图,Softmax激活函数应用于1x1卷积运算的输出。最后,分别计算主路径和三个辅助路径的加权的交叉熵损失函数,总的损失函数定义为这四个损失函数的加权求和:
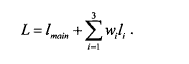
在实验中,设置w1、w2、w3分别为0.5,0.3, 0.1,使主路径仍占主导地位,较低层的误差只占总误差的一小部分。这里的w和上面第二条里的w不一样,这是辅助路径所占的权重,那是前景和背景的权重。
6. 其他网络结构示意图
DenseU-Net

注意跳跃连接是在过渡层之前连接的。

UNet++:

U-Net++的网络结构。黑色部分是U-net的结构,蓝色和绿色部分是U-net++不同于U-net的地方
