SSR-NET: Spatial–Spectral Reconstruction Network for Hyperspectral and Multispectral Image Fusion
(SSR-NET:用于高光谱和多光谱图像融合的空间-光谱重构网络)
将低空间分辨率高光谱图像(LR-HSI)与高空间分辨率多光谱图像(HR-MSI)融合重建高空间分辨率高光谱图像(HR-HSI)是近年来的一个重要研究课题。然而,现有的方法在重建HR-HSI时仍然难以实现空间模式和谱模式的跨模式信息融合。在这篇文章中,基于卷积神经网络(CNN),一个可解释的空间光谱重建网络(SSR-NET)提出了更有效的HSI和MSI融合。更具体地说,所提出的SSR-NET是一个物理straightforward模型,由三个组件组成:1)跨模式消息插入(CMMI);该操作可以产生初步融合的HR-HSI,保留LR-HSI和HR-MSI的最有价值的信息;2)空间重建网络(SpatRN); SpatRN集中于在空间边缘丢失(Lspat)的指导下重建LR-HSI的丢失的空间信息; 3)光谱重建网络(SpecRN); SpecRN注重在空间边缘损失(Lspec)的约束下重建HR-MSI的丢失的光谱信息。
INTRODUCTION
超光谱成像是一种可以获得具有不同波长的数百个窄光谱带的图像的技术。由于高光谱图像(HSI)具有高光谱覆盖率,可以准确地识别地面上的材料和物体,因此HSI在图像分类、物体检测、波段选择、变化检测等领域有广泛的应用。然而,高光谱系统的长曝光是必要的足够的信噪比(SNR),这导致低空间分辨率的高光谱系统(LR-HSIs)。相比之下,多光谱系统可以获取高空间分辨率的多光谱图像(MSI)(HR-MSI)。因此,利用LR-HSI和HR-MSI重建高空间分辨率的HSI(HR-HSI),即HSI和MSI融合,具有重要的意义。
近年来,在HSI和MSI融合领域进行了大量研究,大致可分为两类:传统方法和深度学习方法。在传统的方法中,有一些不同的方法,包括基于矩阵分解的方法,基于贝叶斯的方法和基于张量的方法。虽然这些方法在LR-HSI和HR-MSI融合上取得了优异的性能,但是在空间和光谱模式之间有效地传递消息仍然具有挑战性,这对于提高融合质量至关重要。
与传统方法相比,基于深度学习的方法,特别是卷积神经网络(CNN),由于其强大的特征提取能力,表现出上级的性能。因此,基于CNN,如图1所示。首次提出了一种用于LR-HSI和HR-MSI融合的空间-光谱重建网络(SSR-NET)。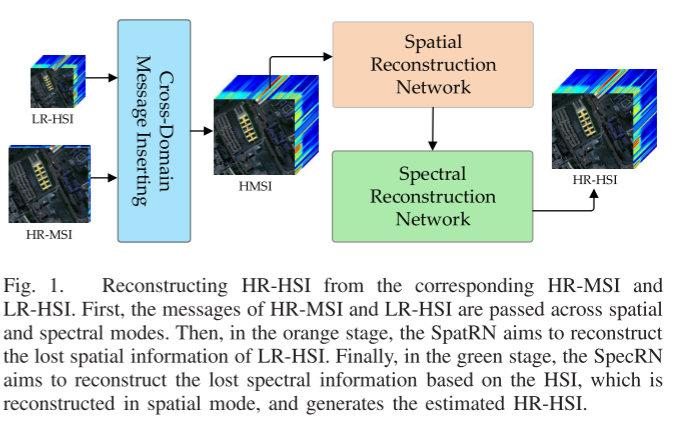
与以前的工作不同,所提出的方法侧重于以高效和可解释的方式跨空间和光谱模式传递有价值的消息。更具体地说,所提出的SSR-NET是由三个模块组成的三级网络模型:1)跨模式消息插入(CMMI); 2)利用Lspat优化空间边缘损失的空间重建网络(SpatRN); 3)频谱重构网络(SpecRN),其频谱边缘损耗由Lspec优化。
首先,作为SSR-NET的输入,LR-HSI和HR-MSI被发送到CMMI中,CMMI维护LR-HSI的有价值的光谱信息和HR-MSI的空间信息,然后将它们融合成具有与参考HR-HSI相同大小的超倍数光谱图像(HMSI)(即,地面实况HR-HSI)。其次,SpatRN被设计来重建丢失的HMSI空间信息。然而,CNN是一个黑箱模型,学习到的特征缺乏足够的解释。为了赋予SpatRN物理意义,提出了Lspat的空间边缘损失以约束SpatRN专注于空间重构。最后,SpecRN被设计为在空间模式中从重建的HMSI重建丢失的光谱信息。类似地,Lspec的频谱边缘损失被设计成使SpecRN关注频谱恢复。
综上所述,本文的主要贡献包括以下几个方面。
1)基于CNN,本文首次提出了一种新的SSR-NET,用于更高效的HSI和MSI融合。
2)所提出的SSR-NET是一种物理straightforward的CNN模型,其在空间边缘损失Lspat和频谱边缘损失Lspec的约束下。Lspat和Lspec是专为空间和光谱重建而设计的。
RELATED WORK
Traditional Methods
通常,传统方法包括以下三类方法。
1) Matrix Factorization-BasedMethods: 这种类型的方法通常展开的3-D HSI,其中的三个维度,分别表示的宽度,高度,和光谱带的数量,到一个2-D矩阵,其中的两个维度表示平坦的空间位置和频带数。在这些方法中,预期分别从LR-HSI和HR-MSI估计端元矩阵和丰度矩阵的两个矩阵,并用于重建相应的HR-HSI。例如,基于无监督解混,Yokoya等人提出了一种用于LR-HSI和HR-MSI融合的耦合非负矩阵分解(CNMF)方法,其中从MSIs获得的高空间分辨率丰度矩阵和高光谱端元矩阵被集成以生成新的HR-HSI。然后,Lanaras等人提出了一种方法,该方法集中于两个输入图像的光谱解混问题,其中根据光谱解混的物理性质添加了一些约束。Dong等人在字典学习和稀疏表示的基础上提出了一种基于稀疏的HSI超分辨率方法。在此基础上,Lin等人提出了一种基于ADMM的CO-CNMF算法。[21]为了进一步优化CNMF,其中1-范数和SSD正则化器被合并并添加到CNMF标准中。
2) Bayesian-BasedMethods: 这种类型的方法通常利用给定图像的适当先验分布来解决LR-HSI和HR-MSI的融合问题。例如,基于贝叶斯稀疏表示的方法首先由Akhtar等人提出。在这项工作中,非参数贝叶斯字典学习被用来学习的分布的场景频谱和他们在图像中的比例,其中的分布将被用来计算的稀疏码的高分辨率图像。Wei等人提出了一种基于西尔维斯特方程解的快速多波段图像融合算法(FUSE)。结合乘子交替方向法和块坐标下降法,该算法可以很容易地扩展到计算融合的贝叶斯估计。
3) Tensor Factorization-Based Methods: 与基于矩阵因式分解的方法不同,基于张量因式分解的方法通常将HSI视为3-D张量,其具有如前所述的三种模式。在这些方法中,HR-HSI被切割成一些立方体,然后,相似的立方体将被分组的基础上学习的集群和一些特定的先验知识。
例如,基于Tucker因子分解,Dian等人首先提出了一种新的HSI超分辨率方法,称为NLSTF。它将稀疏张量分解和非局部均值方法统一到一个框架中,从而从字典估计和每个立方体的稀疏核心张量的角度考虑HSI超分辨问题。类似地,在[23]中提出了一个名为CSTF的基于耦合稀疏张量因式分解的框架,其中核心张量和三个字典的估计被公式化为HR-MSI和LR-HSI的耦合稀疏张量分解。在文献[24]中,Zhang等人提出了一种考虑几何结构的空间谱图正则化低秩张量分解方法(SSGLRTD)。同时,为了更好地优化融合模型,设计了一种基于ALM的融合算法。在[16]中的先前工作之后,Dian等人在学习非局部相似HR-HSI立方体的光谱、空间和非局部模式之间的关系之前,设计了一种新的LTTR。在这项工作中,相似的HR-HSI立方体被组成一个4-D张量,并采用ADMM算法来解决优化问题。
Deep Learning Methods
随着深度学习方法的快速发展,特别是CNN,这些类型的方法已经成为各种HSI处理的增长趋势。在LR-HSI和HR-MSI融合中,深度学习方法表现出出色的性能。与传统方法不同,在基于深度学习的方法中,通常利用各种神经网络以可学习的方式增强图像融合的性能。
例如,Palsson等人首先提出了一种3-D-CNN来从LR-HSI和HR-MSI中获取HR-HSI,其中PCA先验用于融合的降维。在此基础上,Dian等人提出了一种深度HSI锐化方法(DHSIS),通过残差学习来学习先验,实现图像融合问题的正则化。一种新型的MS/HS融合网络是由Xie等人提出的,其考虑了MSI/HSI融合数据的生成机制。接着,基于CNN去噪器和子空间表示,Dian等人提出了一种新的HSI-MSI融合方法,可以应用于不同的HSI数据集,而无需重新训练。通过利用网络中网络卷积单元、跳过连接和批量归一化的技术,Xu等人在本文中提出了一种新的卷积神经网络模型。[36]提出了一种双分支网络(HAM-MFN),通过在不同尺度上融合LR-HSI和HR-MSI来逐渐重建HR-HSI,其中RAP损失被设计用于处理光谱和空间失真。
METHODOLOGY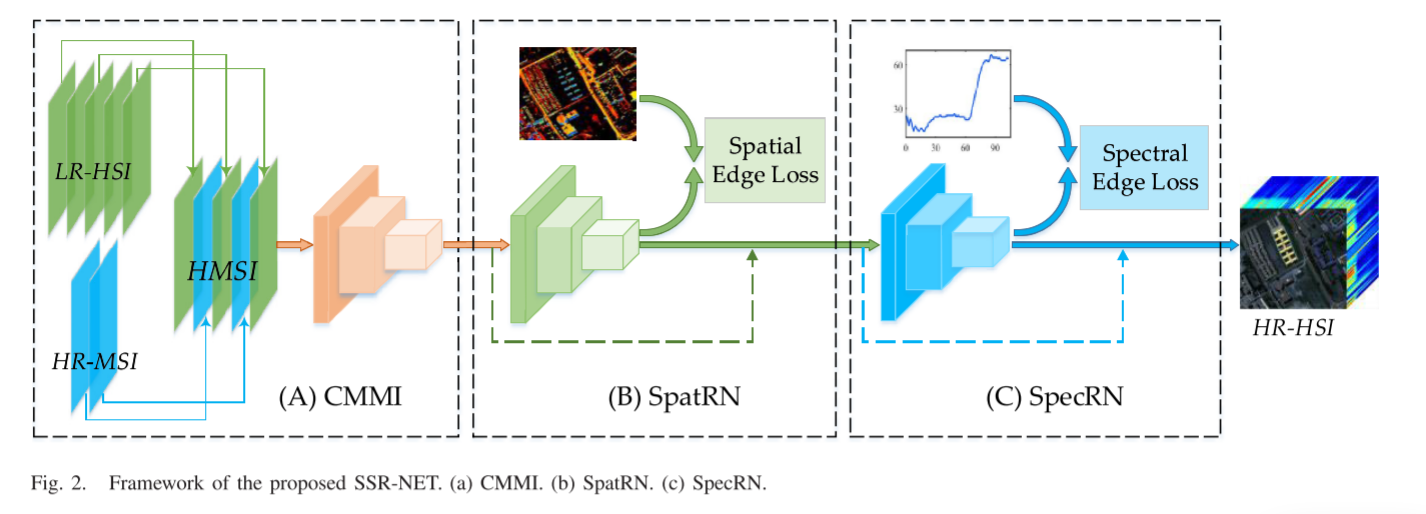
在本节中,提出的SSR-NET,如图2所示。将详细介绍。总体而言,所提出的SSR-NET是一个物理简单的CNN模型,并且它主要由三个模块组成:1) CMMI;2)具有空间边缘损失的SpatRN(Lspat);以及3)具有频谱边缘损失(Lspec)的SpecRN。
Cross-Mode Message Inserting
在所提出的SSR-NET中,参考HR-HSI和估计HR-HSI表示为R ∈ R H × W × L R^{H×W×L} RH×W×L和Z ∈ R H × W × L R^{H×W×L} RH×W×L,其中H和W分别表示高度和宽度的维度,L表示光谱带的数量。此外,它的输入是表示为X ∈ R h × w × L R^{h×w×L} Rh×w×L(h<< H,w <<W)的LR-HSI和表示为Y ∈ R H × W × l R^{H×W×l} RH×W×l(l <<L)的aHR-MSI。X和Y分别在空间和光谱模式中被采样,其通过下式获得: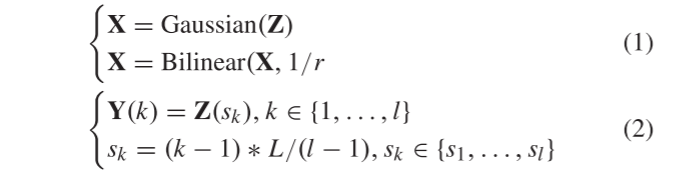
其中X通过双线性运算以r与Z的比率进行空间下采样,其预先通过高斯滤波器进行模糊。Y以相等的频带间隔从Z采样。Y(k)表示Y的第k个频带,并且{s1,…sl }表示HR-HSI中的采样频带编号。
CMMI的目标是产生一个初步的级联超多光谱图像(HMSI)表示为Zpre ∈ R H × W × L R^{H×W×L} RH×W×L,它利用了HR-MSI的空间信息和LR-HSI的光谱信息保持其相对的空间-光谱位置。
通过利用双线性内插,X的LR-HSI将在空间模式中被上采样到与Y的HR-MSI相同的大小,其被表示为
然后,HR-MSI和上采样LR-HSI将被初步融合,其被公式化为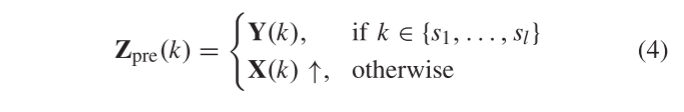

为了初步传递空间模式和频谱模式之间的信息,在HMSI中应用了核大小设置为3×3和空间高度和宽度步长设置为1的卷积层。则记为

Spatial Reconstruction Network With Spatial Edge Loss
为了从Zpre重构空间信息,高度/宽度步幅设置为1的另一个3 × 3卷积层用作SpatRN,其公式为: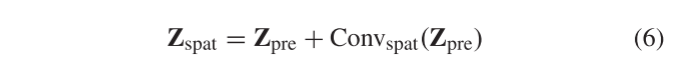
其中Convspat表示卷积层。值得一提的是,在训练阶段使用跳跃连接操作来提高模型的稳定性。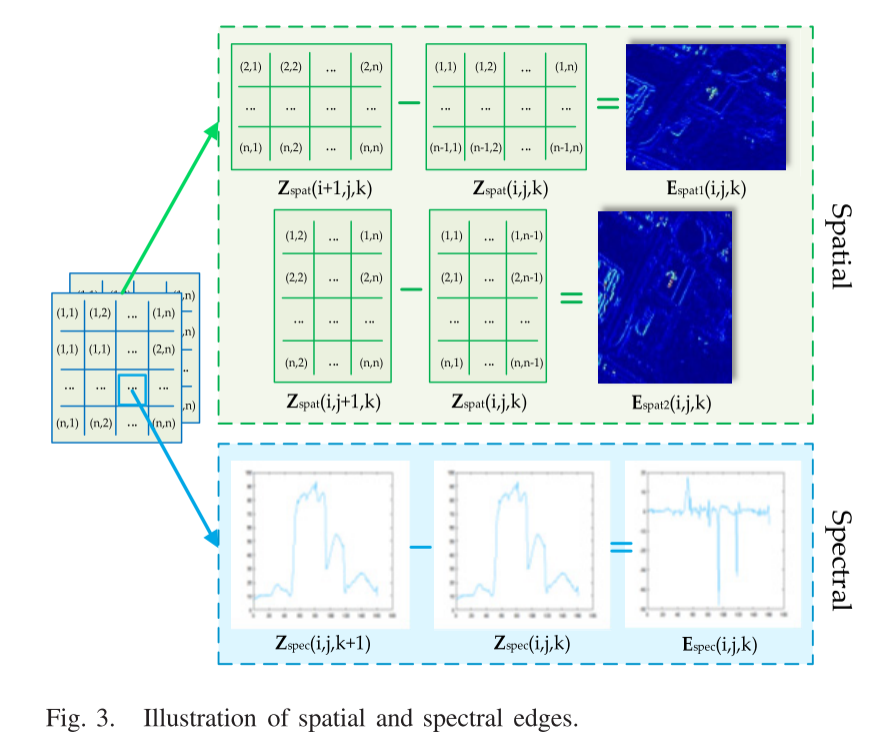
然而,由于CNN的黑箱特性,它是不可控的学习特征映射。众所周知,图像的空间边缘包含着高频特征,这对于图像的空间重构至关重要。为了使SpatRN专注于空间信息的恢复,基于空间边缘,如图3所示。提出了一种新的空间边缘损失(Lspat)来约束SpatRN的输出。Lspat的计算公式为


Spectral Reconstruction Network With Spectral Edge Loss
在空间重构之后,使用与SpatRN具有相同架构的充当SpecRN的又一个卷积层来进一步基于Zspat重构光谱信息。它被制定为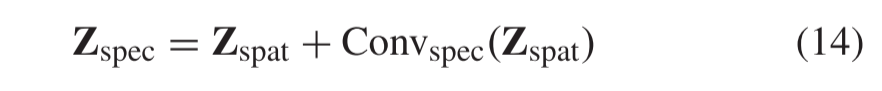
其中Convspec表示卷积层。在SpatRN中也应用跳过连接操作。
类似于空间边缘,如图3所示。频带的谱边缘包含对谱重构至关重要的高频信息。为了使SpecRN重视频谱恢复,本文还提出了频谱边缘损失(Lspec)来约束SpecRN的输出。Lspec的计算公式为
在CMMI、SpatRN和SpecRN之后,Zspec被用作最终估计的HR-HSI,表示为Zfus。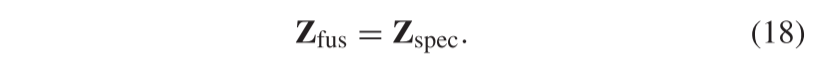
对于Zfus,其通过表示为Lspec的融合损耗来优化,其公式为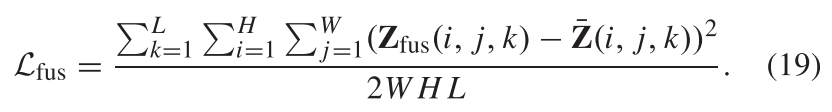
在所提出的SSR-NET中,表示为L的总损耗是Lspat、Lspec和Lfus的总和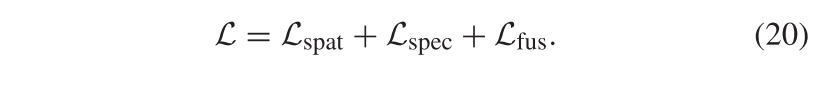
Variations of SSR-NET
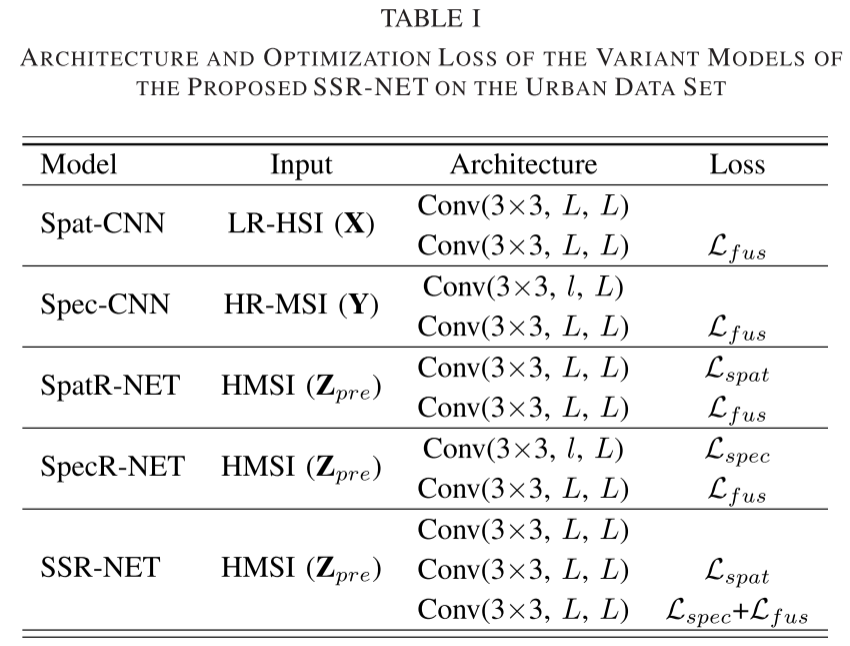
为了探索SSR-NET的组件(包括CMMI、SpatRN和SpecRN)的有效性,设计了Spat-CNN、Spec-CNN、SpatR-NET、SpecRNET和SSR-NET的五种变体模型用于消融实验。
表I中提供了这五种模型的架构和逐层损耗。在Lfus的融合损失的约束下,Spat-CNN和Spec-CNN旨在分别使用LR-HSI和HR-MSI重建HR-HSI。相比之下,SpatR-NET、SpecR-NET和SSR-NET的输入都是HMSI。SpatR-NET侧重于在Lfus的指导下和Lspat的空间边缘损失下恢复HMSI的空间信息,而SpatR-NET侧重于在Lfus的指导下和Lspec的光谱边缘损失下恢复HMSI的光谱信息。SSR-NET是SpatR-NET和SpecR-NET的组合。在该表中,Conv(3 × 3,l,L)表示3 × 3卷积层,其输入和输出通道号分别为l和L,高度/宽度步长设置为1。此外,每个卷积层后面都是ReLU的非线性激活函数。