引言
近年来深度学习的技术在计算机视觉领域中大放异彩,使得对多光谱数据分类的研究迅速发展,结合2D-CNN,3D-CNN,注意力机制,PCA降维等方法均可使得对多光谱图像的分类精度得以提升。目前CNN网络大量用于传统的CV领域,而对于高光谱图像的分类仍比较缺乏,本文章基于CNN网络在高光谱图像中的分类做一个综述。根据CNN网络对高光谱图像特征提取方式的不同,分为基于谱特征,空间特征,和空谱特征的分类方法。
卷积神经网络(Convolutional Neural Networks, CNN)是深度学习中的一种网络结构,特别适合处理具有网格结构(如图像)的数据。因其在图像分类等任务上展现出的强大能力,近年来,CNN也被广泛应用于高光谱图像的分类任务。
高光谱图像概述:
- 高光谱图像具有连续的光谱带,对比于多光谱图像,高光谱包含了大量连续的光谱带(数十到数百个光谱带),这也意味着高光谱图像能够提供更加丰富的信息和更加精细的分辨率。
- 每一个像素都具有一个光谱,所以我们不仅能知道图像的空间信息,还能知道其光谱信息
- 高光谱图像中的每个像素都含有大量的光谱信息,所以其数据量通常非常大
- 高光谱图像可以探测到微小的物质差异,这使得它们在诸如疾病诊断、污染物检测和植被分析等领域具有特殊的价值
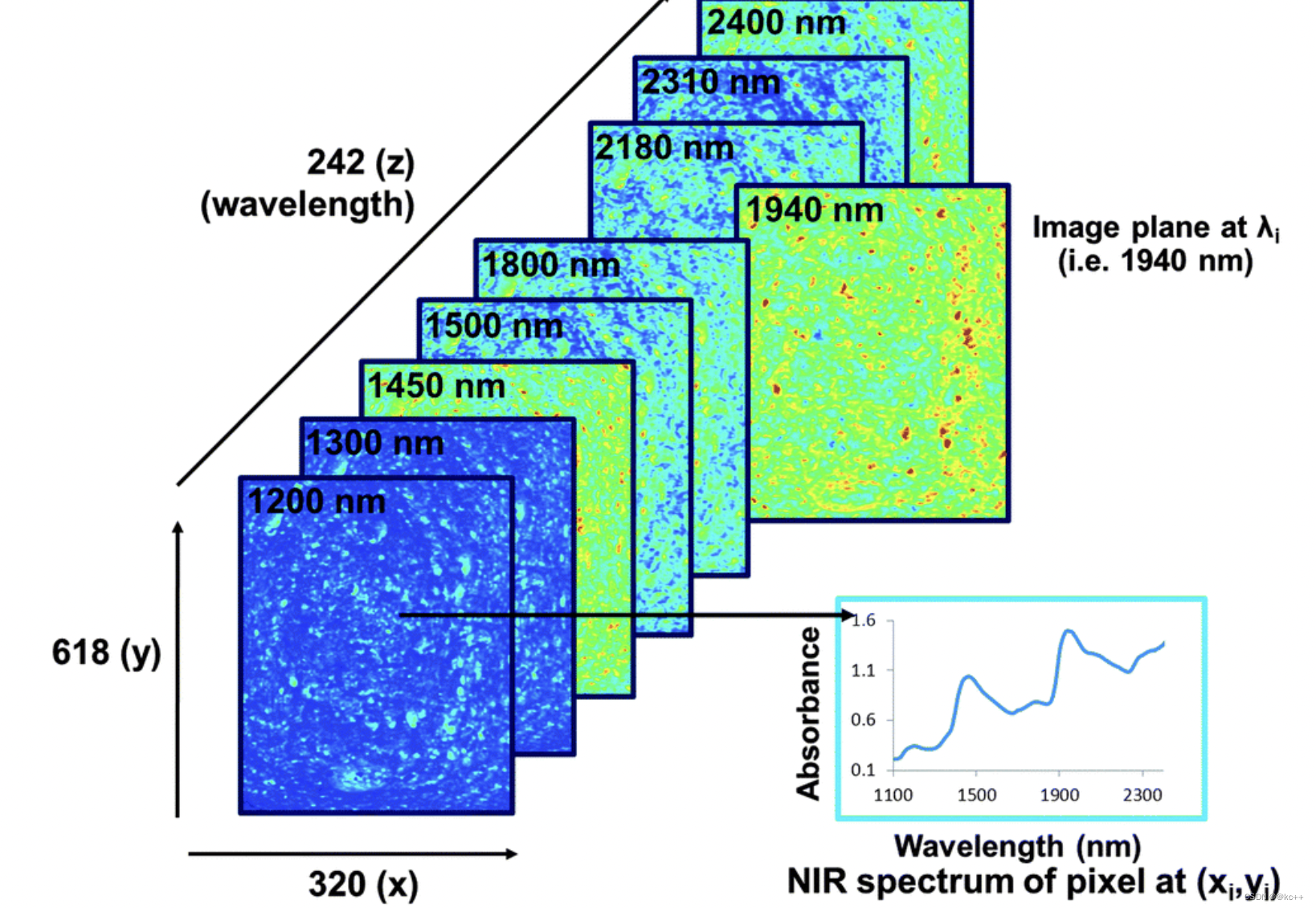
高光谱图像与传统RGB图像区别
- 光谱分辨率:RGB图像只包含三个波段,即红色、绿色和蓝色,每个波段代表了特定的颜色范围。高光谱图像包含数十到数百个连续的光谱波段,提供了更详细的光谱信息,能揭示更多关于物体的信息。例如,不同的物质会在不同的光谱波段上产生独特的反射、吸收和发射特性。
- 颜色深度:RGB图像是彩色图像,可以显示几百万种颜色。然而,这些颜色是通过三种基本颜色的混合来产生的,所以RGB图像的颜色深度相对较浅。高光谱图像每个像素的颜色深度非常深,因为每个像素都有一个完整的光谱,所以它们可以展示更精确和复杂的颜色信息。
1. 基于光谱特征
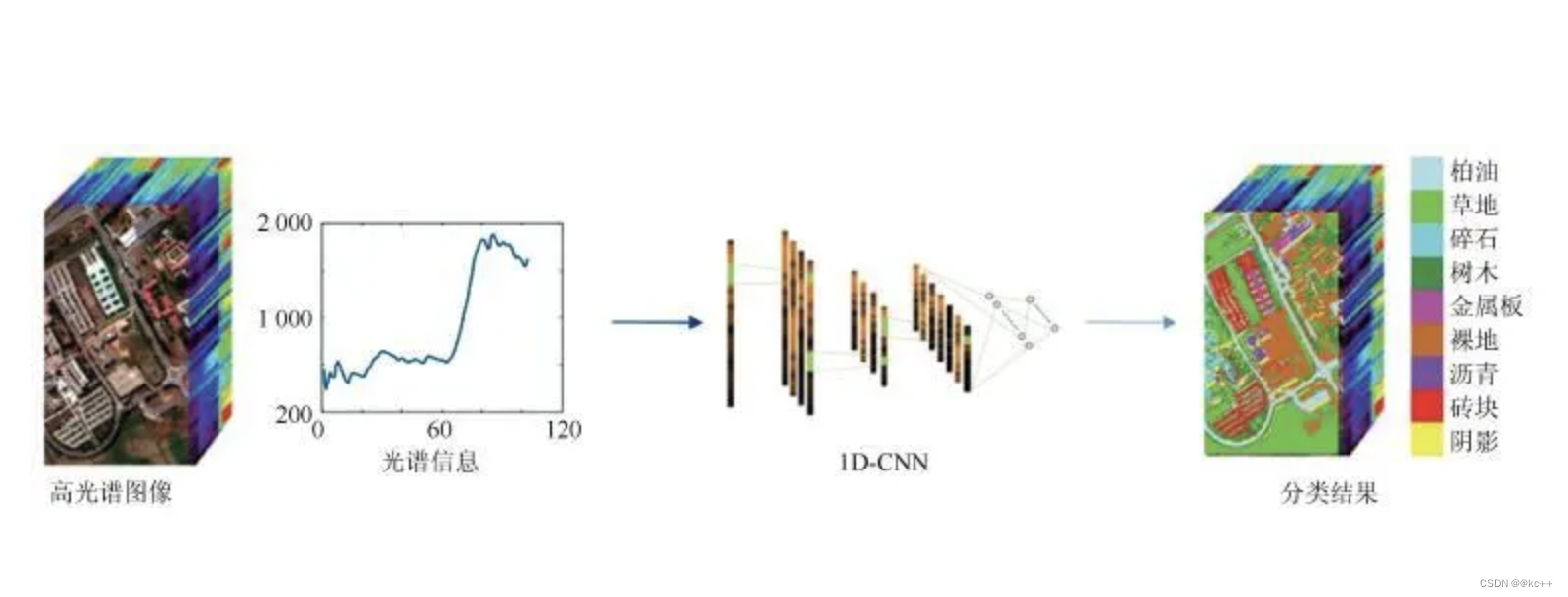
基于光谱特征进行CNN分类利用了1D-CNN在光谱层进行卷积
光谱特征是指物体在不同波长下的反射、吸收和发射的光线强度,这些特征可以反映出物体的物理和化学性质。在高光谱图像中,每一个像素都包含一个光谱,这个光谱就是由该像素在各个波长下的光强度组成的。因此,光谱特征提取就是提取每个像素在各个波长下的光强度。
在使用卷积神经网络(CNN)进行光谱特征提取时,通常使用一维卷积层。一维卷积层可以看作是一个滤波器,它会在光谱的波长轴上滑动,提取出光谱的局部特征。通过堆叠多个一维卷积层,我们可以提取出更深层次的光谱特征。
光谱特征提取的步骤通常如下:
预处理:对高光谱图像进行必要的预处理,如噪声去除、归一化等。
- 预处理:对高光谱图像进行必要的预处理,如噪声去除、归一化等。
- 设计一维卷积层:设计一维卷积层的核大小和步长,以适应光谱的特点。例如,如果光谱的变化比较缓慢,我们可以选择大一点的核大小;如果光谱的变化比较快,我们可以选择小一点的核大小。
- 卷积操作:将设计好的一维卷积层应用到每一个像素的光谱上,提取出光谱的局部特征。
- 非线性激活:对卷积的结果进行非线性激活,增强模型的表达能力。
- 池化操作:对激活后的特征进行池化操作,减小特征的维度,同时增强特征的鲁棒性。
- 堆叠卷积层:重复上述步骤,堆叠多个卷积层,提取出更深层次的光谱特征。
下面是一个基于Python和深度学习库Keras的简单例子,展示如何使用一维卷积神经网络(1D-CNN)进行光谱特征提取和分类。
from keras.models import Sequential
from keras.layers import Conv1D, MaxPooling1D, Flatten, Dense
# 假设高光谱数据具有100个频道
n_channels = 100
# 创建一个序贯模型
model = Sequential()
# 添加一维卷积层,用于光谱特征提取
model.add(Conv1D(filters=32, kernel_size=3, activation='relu', input_shape=(n_channels, 1)))
# 添加最大池化层
model.add(MaxPooling1D(pool_size=2))
# 添加另一维卷积层
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
# 再添加一个最大池化层
model.add(MaxPooling1D(pool_size=2))
# 将卷积的输出展平,以便连接全连接层
model.add(Flatten())
# 添加一个全连接层
model.add(Dense(128, activation='relu'))
# 假设有10个类别,添加一个输出层
model.add(Dense(10, activation='softmax'))
# 编译模型,设置优化器和损失函数
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 输出模型的结构
model.summary()
# x_train和y_train分别是训练数据和标签,进行模型训练
# model.fit(x_train, y_train, epochs=10, batch_size=32)
2. 基于空间特征
目前已有研究证明,像素周围的空间信息对高光谱图像分类算法性能有至关重要的影响,在高光谱图像分类中,像素周围的空间信息起着重要的作用。这是因为在许多情况下,单个像素可能无法提供足够的信息来进行精确的分类,尤其是在存在噪声或者光谱混合的情况下。然而,当我们考虑到像素周围的空间环境时,我们就能得到更多的信息。这主要有以下几个原因:
- 上下文信息:在很多情况下,一个像素的类别通常与其周围像素的类别有关。例如,在一个农田的高光谱图像中,一个玉米像素通常会被其他玉米像素包围。因此,考虑空间信息可以帮助我们更好地利用这种上下文信息。
- 降低噪声的影响:像素周围的空间信息可以帮助我们对噪声有更强的鲁棒性。例如,即使某个像素由于噪声而被误分类,其周围的像素仍可能被正确分类。这可以通过某种形式的空间平滑或滤波来利用。
- 解决光谱混合问题:在许多高光谱图像中,一个像素可能包含多种物质的光谱混合。通过考虑空间信息,我们可以更好地解决这种光谱混合问题。
- 改善分类精度:多数高光谱分类算法通过结合空间和光谱信息,能够显著提高分类的准确性。
空间特征是指图像中的像素及其邻近像素之间的关系。在高光谱图像中,空间特征通常表示物体的形状、纹理、大小以及这些物体在图像中的相对位置等信息。对于许多应用来说,尤其是那些涉及到地理、环境或生物学的应用,空间特征是至关重要的。
对于空间特征的提取,通常使用二维卷积神经网络(2D-CNN)。卷积神经网络可以在局部邻域上提取特征,从而捕获像素之间的空间关系。
在使用2D-CNN进行空间特征提取时,通常的做法是将每一个高光谱像素的光谱视为一个多通道的2D图像。然后,对这个2D图像应用一系列2D卷积层和池化层,提取出空间特征。
下图为相关操作:
与1D-CNN不同,2D-CNN会在长和宽两个维度上用卷积核进行卷积,但在使用2D-CNN对高光谱图像进行特征提取时,由于高光谱图像通常包含成百上千个通道,所以会导致网络参数过大,容易导致模型过拟合。因此我们引入PCA降维来解决过拟合问题。
以下是一个使用2D CNN进行空间特征提取的基本步骤:
- 预处理:对高光谱图像进行必要的预处理,如噪声去除、归一化等。
- PCA降维:对高光谱图像应用PCA降维。PCA降维的目标是找到一个新的坐标系统,使得数据在这个新的坐标系统上的方差最大。在新的坐标系统上,我们可以只保留前几个主成分,从而实现降维。
- 提取空间特征:使用卷积神经网络(CNN)提取空间特征。这可以通过设计2D卷积层,对降维后的高光谱图像进行卷积操作,提取出空间特征。
- 全连接层和分类:将提取的空间特征通过全连接层进行融合,并通过Softmax分类器进行分类。
这里需要注意的是,PCA降维可能会导致一些信息的丢失,因此需要根据具体的任务和数据来选择合适的降维比例。另外,虽然PCA可以有效地降低数据维度,但是它是一种线性降维方法,可能无法处理具有复杂非线性结构的数据。对于这种情况,可能需要考虑使用一些非线性的降维方法,如t-SNE、Autoencoder等。

以下是一个基于Python和深度学习库Keras,利用2D-CNN网络提取特征并用PCA进行降维的例子。
import numpy as np
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 加载高光谱图像数据和标签,这里假设数据已经加载到变量data和labels中
# data shape: (num_samples, img_height, img_width, num_channels)
# labels shape: (num_samples, num_classes)
# 对数据进行预处理
scaler = StandardScaler()
data = scaler.fit_transform(data.reshape(data.shape[0], -1)).reshape(data.shape)
# 使用PCA进行降维
n_components = 50 # 可以根据需要调整
pca = PCA(n_components=n_components)
data_pca = pca.fit_transform(data.reshape(data.shape[0], -1))
data_pca = data_pca.reshape(data_pca.shape[0], int(np.sqrt(n_components)), int(np.sqrt(n_components)), 1)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data_pca, labels, test_size=0.2, random_state=42)
# 创建一个CNN模型
model = Sequential()
# 添加卷积层
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(int(np.sqrt(n_components)), int(np.sqrt(n_components)), 1)))
# 添加池化层
model.add(MaxPooling2D(pool_size=(2, 2)))
# 添加另一卷积层
model.add(Conv2D(64, (3, 3), activation='relu'))
# 添加池化层
model.add(MaxPooling2D(pool_size=(2, 2)))
# 展平输出,以便添加全连接层
model.add(Flatten())
# 添加全连接层
model.add(Dense(128, activation='relu'))
# 添加输出层,假设有10个类别
model.add(Dense(10, activation='softmax'))
# 编译模型,设置优化器和损失函数
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=32)
# 测试模型
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
3. 基于空谱特征
近些年,关于分类算法的一个主要趋势是将高光谱图像的空间和光谱信息融合,这种方法已经将分类性能提升到新的高度,这里又可以细分为2中方法,一种是先分别提取空间信息和光谱信息,然后将两种信息融和得到新的空谱联合特征,最后把融合得到的特征送入分类器进行分类,第二种方法是直接利用3D-CNN实现对空间特征和光谱特征同时提取
3.1 空间特征和光谱特征的融合
我们先分别提取空间信息和光谱信息,然后将两种信息融和得到新的空谱联合特征,最后把融合得到的特征送入分类器进行分类,以下是一个基本的步骤:
- 提取光谱特征:使用一维卷积神经网络(1D-CNN)提取每个像素的光谱特征。
- 提取空间特征:使用二维卷积神经网络(2D-CNN)提取高光谱图像的空间特征。
- 融合特征:将提取的光谱特征和空间特征进行融合,得到空谱联合特征。融合的方式可以有多种,例如简单的拼接,或者使用更复杂的方法如特征级联或多视图学习等。
- 分类:将融合得到的特征送入一个分类器进行分类,分类器可以是全连接神经网络、支持向量机、随机森林等。
下面是一个基于Keras库的详细的光谱和空间特征提取、融合及分类的示例代码。此处,我们使用1D卷积网络提取光谱特征,使用2D卷积网络提取空间特征,最后通过全连接层进行特征融合和分类。
from keras.models import Model
from keras.layers import Input, Conv1D, Conv2D, Flatten, Dense, Concatenate
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
# 高光谱图像数据集(data)和对应的标签(labels)已经准备好
# 数据格式如下:(num_samples, img_height, img_width, num_channels)
# 数据预处理
data = data / np.max(data) # 数据归一化
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
y_train, y_test = to_categorical(y_train), to_categorical(y_test) # one-hot编码
# 提取光谱特征的1D-CNN
spectral_input = Input(shape=(img_height, img_width, num_channels))
spectral_conv = Conv1D(32, 5, activation='relu')(spectral_input)
spectral_conv = Flatten()(spectral_conv)
spectral_model = Model(inputs=spectral_input, outputs=spectral_conv)
# 提取空间特征的2D-CNN
spatial_input = Input(shape=(img_height, img_width, num_channels))
spatial_conv = Conv2D(32, (3, 3), activation='relu')(spatial_input)
spatial_conv = Flatten()(spatial_conv)
spatial_model = Model(inputs=spatial_input, outputs=spatial_conv)
# 融合特征并分类
combined = Concatenate()([spectral_model.output, spatial_model.output])
combined = Dense(128, activation='relu')(combined)
combined = Dense(num_classes, activation='softmax')(combined) # 假设你有num_classes个类别
model = Model(inputs=[spectral_input, spatial_input], outputs=combined)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit([x_train, x_train], y_train, epochs=10, batch_size=32)
# 测试模型
score = model.evaluate([x_test, x_test], y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
3.2 基于3D-CNN分类
人们联想到视频序列的数据形式与高光谱图像的数据形式非常相似,并逐渐把用 3D-CNN 提取高光谱空谱联合信息作为新的特征提取方式,由此衍生出一系列基于 3D-CNN 的空谱联合分类方法

3D-CNN与2D-CNN类似,但它在三个维度上进行卷积,因此可以同时考虑空间信息和光谱信息。其操作方式是在输入数据的三个维度上(例如,高度、宽度和深度)滑动并应用滤波器,以此在输入数据中找到有意义的模式。
3D-CNN与2D-CNN类似,但它在三个维度上进行卷积,因此可以同时考虑空间信息和光谱信息。其操作方式是在输入数据的三个维度上(例如,高度、宽度和深度)滑动并应用滤波器,以此在输入数据中找到有意义的模式。
以下是一个基本的3D-CNN模型的搭建和训练流程:
- 预处理:对高光谱图像进行必要的预处理,如噪声去除、归一化等。
- 建立模型:设计一个3D-CNN模型。这个模型的输入是一个三维的数据立方体,输出是每个类别的概率。
- 训练模型:使用标注的高光谱图像训练模型。
- 评估模型:在测试集上评估模型的性能。
以下是一个将 2D-CNN 和 3D-CNN相结合,构建一个 3 层 3D-CNN、2 层 2D-CNN的模型,同时引入通道三维卷积 ( Depthwise3DCNN) 和通道二维卷积 ( Depthwise 2D-CNN) 以减少参数量,并配合 Adam 优化算法的代码示例:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Conv3D, DepthwiseConv2D, MaxPooling2D, MaxPooling3D, Flatten, Dense
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# 定义参数
num_samples = 100
img_height, img_width = 64, 64
num_channels = 100
num_classes = 10
# 生成模拟数据
data = np.random.rand(num_samples, img_height, img_width, num_channels)
labels = np.random.randint(0, num_classes, num_samples)
# 数据预处理
data = data / np.max(data) # 数据归一化
labels = to_categorical(labels) # one-hot编码
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# 建立模型
model = Sequential()
# 添加3层3D-CNN
model.add(Conv3D(32, (3, 3, 3), activation='relu', padding='same', input_shape=(img_height, img_width, num_channels, 1)))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
model.add(Conv3D(64, (3, 3, 3), activation='relu', padding='same'))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
model.add(Conv3D(128, (3, 3, 3), activation='relu', padding='same'))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
# 转换为2D数据
model.add(Reshape((-1, num_channels // 8)))
# 添加2层2D-CNN和深度卷积
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(DepthwiseConv2D((3, 3), depth_multiplier=1, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(DepthwiseConv2D((3, 3), depth_multiplier=1, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 添加全连接层和输出层
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=32)
4. 总结
高光谱图像(HSI)由大量连续的光谱带组成,每个像素包含从不同波长反射的光的信息。这种丰富的光谱信息使得HSI在许多领域,如农业、环境科学和军事中具有广泛的应用。
传统的高光谱图像分类方法,一方面只利用光谱信息进行分类,没有充分考虑高光谱遥感图像中所包含的丰富的空间信息,另一方面,模型的泛化能力不佳,普适性不强,因此分类效果不理想。为了进行高光谱图像分类,研究者们已经提出了许多基于机器学习的方法,其中卷积神经网络(CNN)已经成为一个非常流行的选择,因为CNN在图像分类任务中已经表现出了极高的性能。
在应用CNN进行HSI分类时,主要的挑战是如何处理HSI的空间和光谱信息。有两种主要的处理方法:一种是分别处理空间和光谱信息,然后将这两种信息融合;另一种是直接使用三维CNN(3D-CNN)同时处理空间和光谱信息。其中,2D-CNN主要用于处理空间信息,而1D-CNN和3D-CNN则可用于处理光谱信息。
对于2D-CNN,常见的方法是将HSI中的每个像素及其周围的像素看作一个小块,然后将这个小块作为2D-CNN的输入。对于1D-CNN和3D-CNN,常见的方法是将整个HSI或者HSI的一部分作为输入。
在处理HSI时,由于其高维性,往往会产生所谓的“维度灾难”。因此,通常会在训练CNN之前对HSI进行降维,如使用主成分分析(PCA)等方法。
另外,还有一些高级的技术,如深度卷积(Depthwise Convolution),可以有效地处理多通道的HSI并减少模型的参数量。
在研究中,我们同样需要解决一些存在的问题:
- 训练数据的获取:标注高光谱图像需要大量的专业知识和时间。因此,获取大量的标注数据往往是一个挑战。在这方面,一种可能的解决方案是使用半监督或无监督的学习方法,这些方法可以使用未标注的数据进行训练。
- 模型的解释性:虽然CNN在HSI分类中表现出了高效的性能,但其工作原理往往难以理解。这在某些应用中可能是一个问题,因为用户可能需要理解模型为什么做出某个分类决策。为了解决这个问题,可以考虑开发新的解释性模型,或者使用模型可视化等技术提高模型的透明度。
- 处理高维数据:HSI通常具有非常高的维度,这可能导致“维度诅咒”问题,即随着维度的增加,需要的数据量呈指数级增长。一种可能的解决方案是使用降维技术,如主成分分析(PCA)或者自动编码器(Autoencoder)。然而,这些方法可能会丢失一些重要的信息。因此,开发新的降维方法,可以保留更多的信息是一个重要的研究方向。
- 模型的泛化能力:许多现有的CNN模型在特定数据集上表现得很好,但在其他数据集上的性能可能就会下降。这可能是因为模型过拟合了训练数据,或者训练数据和测试数据的分布不同。为了解决这个问题,可以考虑使用更复杂的数据增强技术,或者开发新的正则化方法。