目录
习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
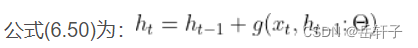
梯度爆炸问题:在公式 Z k = U h k − 1 + W x k + b Z_k=Uh_{k-1}+Wx_k +b Zk=Uhk−1+Wxk+b为在第k kk时刻函数 g ( ∗ ) g(*) g(∗)的输入,在计算公式(6.34)中的误差项 δ t , k = ∂ L t ∂ z k δ_{t,k} = \frac{\partial L_{t}}{\partial z_{k}} δt,k=∂zk∂Lt,梯度可能会过大,从而导致梯度爆炸问题。
解决办法:增加门控装置。
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果编辑
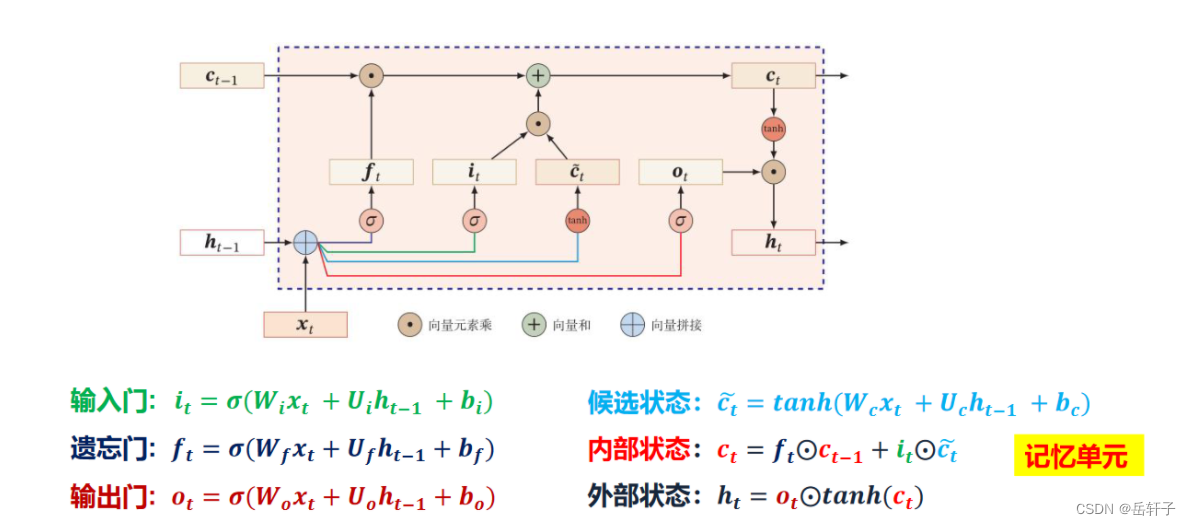
手动推导一下

分析避免梯度消失的效果:简单的来讲,RNN的输出由连乘决定,连乘可能会出现梯度消失。LSTM的输出由累加决定,累加的方式克服了上述的问题。
梯度更新时,梯度的大小主要取决于前后状态导数再连乘关系,即: ∏ j t ∂ c j ∂ c j − 1 \prod_{j}^{t}\frac{\partial c_{j}}{\partial c_{j-1}} ∏jt∂cj−1∂cj 。
RNN两个状态求导满足(tanh激活函数类似): σ ( 1 − σ ) W \sigma\left( 1-\sigma \right)W σ(1−σ)W,求导绝对值范围为: [ 0 ∼ 1 4 W ] [0\sim\frac{1}{4}W] [0∼41W] 。
而LSTM输入门状态更新时,两个状态求导则中有一部分直接取决于forget gate的输出值: σ ( W x + b ) \sigma\left( Wx+b \right) σ(Wx+b),求导绝对值范围为 [ 0 ∼ 1 ] \left[ 0\sim1 \right] [0∼1] 。
由于RNN很大程度上取决于W 的取值(与4的大小关系),若认定最终所期望学得的系数W 是绝对值稀疏的,即其要么大要么小,对于RNN而言是容易产生梯度消失和梯度爆炸的。而LSTM相比于RNN更稳定,稀疏的话其对应的求导范围看极端一点也是0和1,是不是就类似Relu的作用了呢?因此,在通过几次连乘操作时LSTM相比RNN而言能缓解梯度的消失问题。
习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果

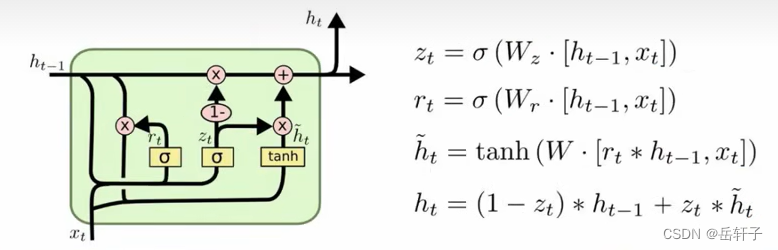
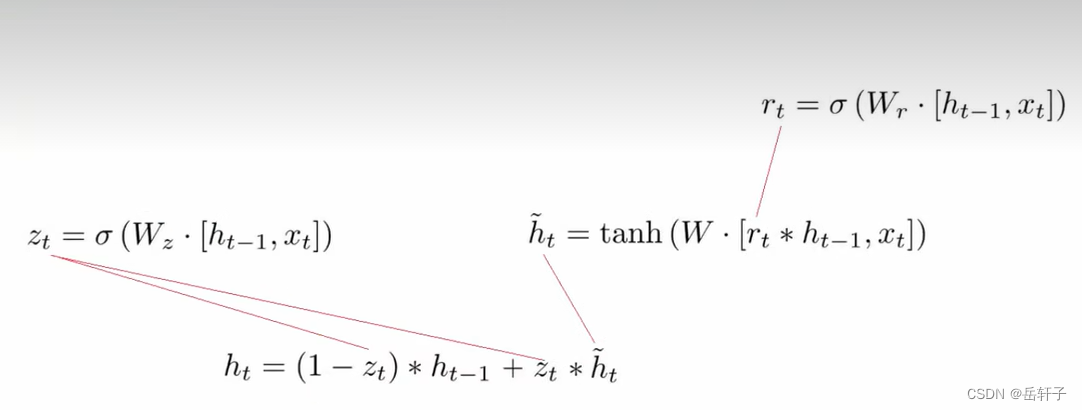
推导一下:
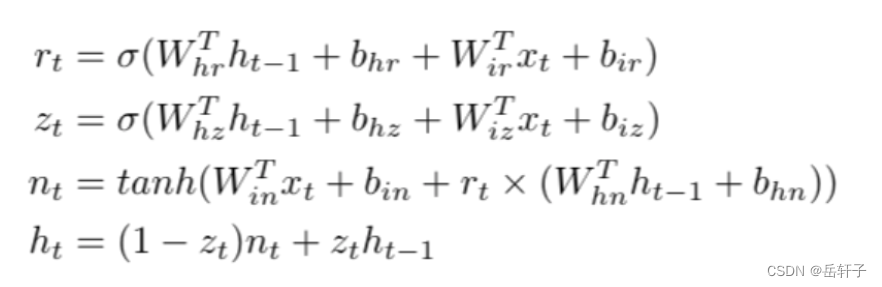
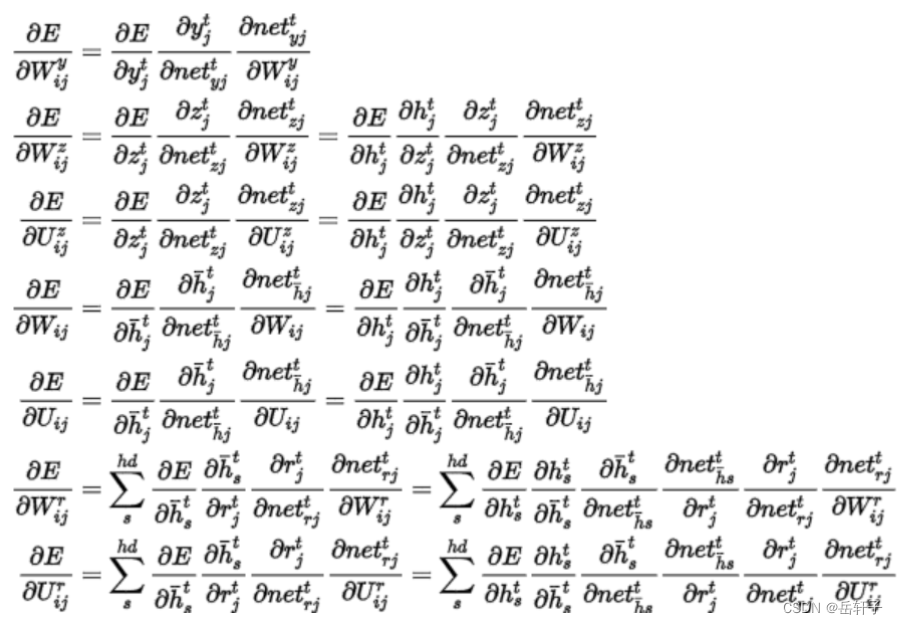
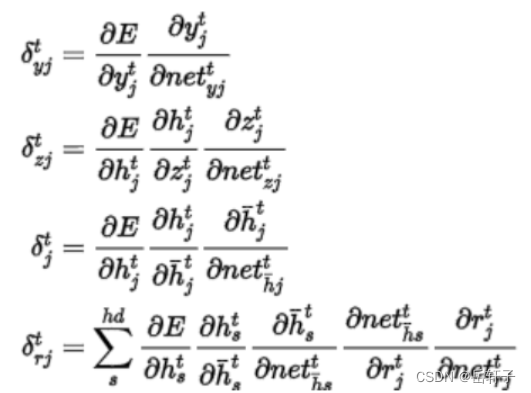
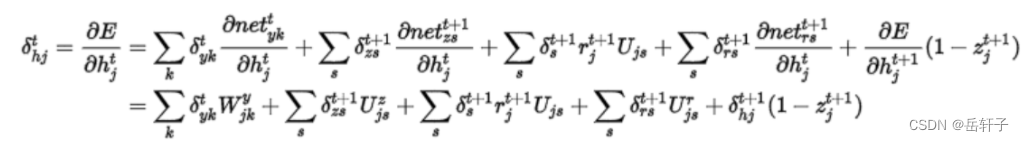
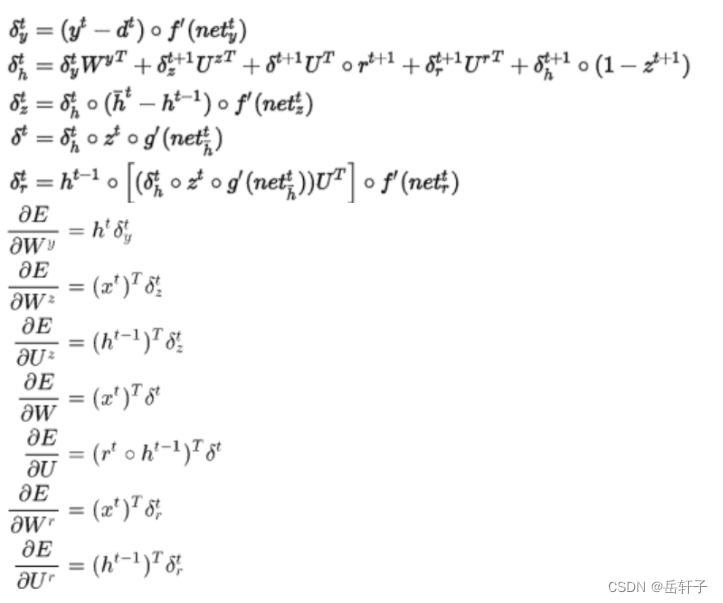
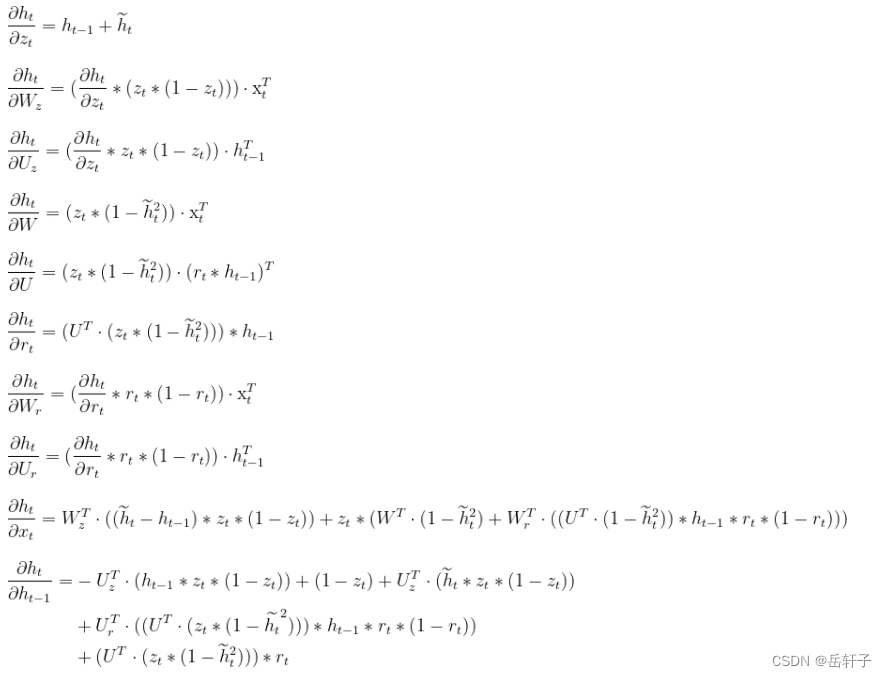
分析:LSTM和GRU里面都存储了一个中间状态,并把中间状态持续从前往后传,和当前步的特征合并来做预测,合并过程用的是加法模型,这点其实和ResNet的残差模块有点类似。
附加题 6-1P 什么时候应该用GRU? 什么时候用LSTM?
先说明一下GRU和LSTM的区别:GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。GRU 输入输出的结构与普通的 RNN 相似,其中的内部思想与 LSTM 相似。与 LSTM 相比,GRU 内部少了一个”门控“,参数比LSTM 少,但是却也能够达到与 LSTM 相当的功能。
对于 LSTM 与 GRU 而言, 由于 GRU 参数更少,收敛速度更快,因此其实际花费时间要少很多,这可以大大加速了我们的迭代过程。 而从表现上讲,二者之间孰优孰劣并没有定论,这要依据具体的任务和数据集而定,而实际上,二者之间的 performance 差距往往并不大,远没有调参所带来的效果明显
附加题 6-2P LSTM BP推导
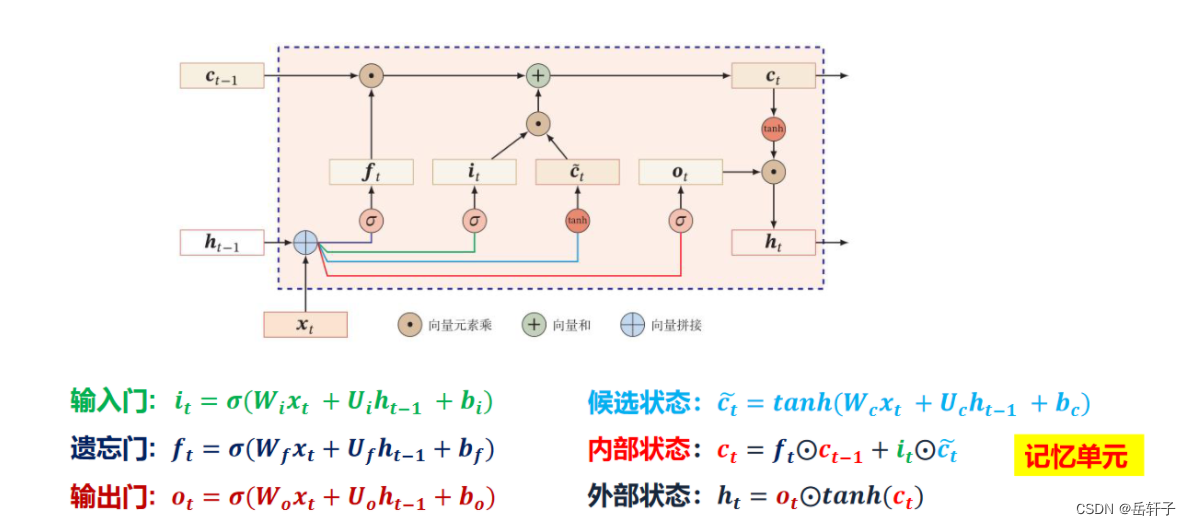

import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
def softmax(x):
e_x = np.exp(x-np.max(x))# 防溢出
return e_x/e_x.sum(axis=0)
def lstm_cell_forward(xt, a_prev, c_prev, parameters):
"""
Implement a single forward step of the LSTM-cell as described in Figure (4)
Arguments:
xt -- your input data at timestep "t", numpy array of shape (n_x, m).
a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m)
c_prev -- Memory state at timestep "t-1", numpy array of shape (n_a, m)
parameters -- python dictionary containing:
Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
bf -- Bias of the forget gate, numpy array of shape (n_a, 1)
Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
bi -- Bias of the update gate, numpy array of shape (n_a, 1)
Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x)
bc -- Bias of the first "tanh", numpy array of shape (n_a, 1)
Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x)
bo -- Bias of the output gate, numpy array of shape (n_a, 1)Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a_next -- next hidden state, of shape (n_a, m)
c_next -- next memory state, of shape (n_a, m)
yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m)
cache -- tuple of values needed for the backward pass, contains (a_next, c_next, a_prev, c_prev, xt, parameters)
"""
# 获取参数字典中各个参数
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
# 获取 xt 和 Wy 的维度参数
n_x, m = xt.shape
n_y, n_a = Wy.shape
# 拼接 a_prev 和 xt
concat = np.zeros((n_a + n_x, m))
concat[: n_a, :] = a_prev
concat[n_a :, :] = xt
# 计算遗忘门、更新门、记忆细胞候选值、下一时间步的记忆细胞、输出门和下一时间步的隐状态值
ft = sigmoid(np.matmul(Wf, concat) + bf)
it = sigmoid(np.matmul(Wi, concat) + bi)
cct = np.tanh(np.matmul(Wc, concat) + bc)
c_next = ft*c_prev + it*cct
ot = sigmoid(np.matmul(Wo, concat) + bo)
a_next = ot*np.tanh(c_next)
# 计算 LSTM 的预测输出
yt_pred = softmax(np.matmul(Wy, a_next) + by)
# 保存各计算结果值
cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)
return a_next, c_next, yt_pred, cache
def lstm_forward(x, a0, parameters):
"""
Arguments:
x -- Input data for every time-step, of shape (n_x, m, T_x).
a0 -- Initial hidden state, of shape (n_a, m)
parameters -- python dictionary containing:
Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
bf -- Bias of the forget gate, numpy array of shape (n_a, 1)
Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
bi -- Bias of the update gate, numpy array of shape (n_a, 1)
Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x)
bc -- Bias of the first "tanh", numpy array of shape (n_a, 1)
Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x)
bo -- Bias of the output gate, numpy array of shape (n_a, 1)
Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
Returns:
a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x)
y -- Predictions for every time-step, numpy array of shape (n_y, m, T_x)
caches -- tuple of values needed for the backward pass, contains (list of all the caches, x)
"""
# 初始化缓存列表
caches = []
# 获取 x 和 参数 Wy 的维度大小
n_x, m, T_x = x.shape
n_y, n_a = parameters['Wy'].shape
# 初始化 a, c 和 y 的值
a = np.zeros((n_a, m, T_x))
c = np.zeros((n_a, m, T_x))
y = np.zeros((n_y, m, T_x))
# 初始化 a_next 和 c_next
a_next = a0
c_next = np.zeros(a_next.shape)
# 循环所有时间步
for t in range(T_x):
# 更新下一时间步隐状态值、记忆值并计算预测
a_next, c_next, yt, cache = lstm_cell_forward(x[:,:,t], a_next, c_next, parameters)
# 在 a 中保存新的激活值
a[:,:,t] = a_next
# 在 a 中保存预测值
y[:,:,t] = yt
# 在 c 中保存记忆值
c[:,:,t] = c_next
# 添加到缓存列表
caches.append(cache)
# 保存各计算值供反向传播调用
caches = (caches, x)
return a, y, c, caches
def lstm_cell_backward(da_next, dc_next, cache):
"""
Arguments:
da_next -- Gradients of next hidden state, of shape (n_a, m)
dc_next -- Gradients of next cell state, of shape (n_a, m)
cache -- cache storing information from the forward pass
Returns:
gradients -- python dictionary containing:
dxt -- Gradient of input data at time-step t, of shape (n_x, m)
da_prev -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m)
dc_prev -- Gradient w.r.t. the previous memory state, of shape (n_a, m, T_x)
dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x)
dWo -- Gradient w.r.t. the weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x)
dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1)
dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1)
dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1)
dbo -- Gradient w.r.t. biases of the output gate, of shape (n_a, 1)
"""
# 获取缓存值
(a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) = cache # 获取 xt 和 a_next 的维度大小
n_x, m = xt.shape
n_a, m = a_next.shape
# 计算各种门的梯度
dot = da_next * np.tanh(c_next) * ot * (1 - ot)
dcct = dc_next * it + ot * (1 - np.tanh(c_next) ** 2) * it * da_next * cct * (1 - np.tanh(cct) ** 2)
dit = dc_next * cct + ot * (1 - np.tanh(c_next) ** 2) * cct * da_next * it * (1 - it)
dft = dc_next * c_prev + ot * (1 - np.tanh(c_next) ** 2) * c_prev * da_next * ft * (1 - ft) # 计算各参数的梯度
dWf = np.dot(dft, np.concatenate((a_prev, xt), axis=0).T)
dWi = np.dot(dit, np.concatenate((a_prev, xt), axis=0).T)
dWc = np.dot(dcct, np.concatenate((a_prev, xt), axis=0).T)
dWo = np.dot(dot, np.concatenate((a_prev, xt), axis=0).T)
dbf = np.sum(dft, axis=1, keepdims=True)
dbi = np.sum(dit, axis=1, keepdims=True)
dbc = np.sum(dcct, axis=1, keepdims=True)
dbo = np.sum(dot, axis=1, keepdims=True)
da_prev = np.dot(parameters['Wf'][:,:n_a].T, dft) + np.dot(parameters['Wi'][:,:n_a].T, dit) + np.dot(parameters['Wc'][:,:n_a].T, dcct) + np.dot(parameters['Wo'][:,:n_a].T, dot)
dc_prev = dc_next*ft + ot*(1-np.square(np.tanh(c_next)))*ft*da_next
dxt = np.dot(parameters['Wf'][:,n_a:].T,dft)+np.dot(parameters['Wi'][:,n_a:].T,dit)+np.dot(parameters['Wc'][:,n_a:].T,dcct)+np.dot(parameters['Wo'][:,n_a:].T,dot)
# 将各梯度保存至字典
gradients = {
"dxt": dxt, "da_prev": da_prev, "dc_prev": dc_prev, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradients
def lstm_backward(da, caches):
"""
Arguments:
da -- Gradients w.r.t the hidden states, numpy-array of shape (n_a, m, T_x)
dc -- Gradients w.r.t the memory states, numpy-array of shape (n_a, m, T_x)
caches -- cache storing information from the forward pass (lstm_forward)
Returns:
gradients -- python dictionary containing:
dx -- Gradient of inputs, of shape (n_x, m, T_x)
da0 -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m)
dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x)
dWo -- Gradient w.r.t. the weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x)
dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1)
dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1)
dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1)
dbo -- Gradient w.r.t. biases of the save gate, of shape (n_a, 1)
"""
# 获取第一个缓存值
(caches, x) = caches
(a1, c1, a0, c0, f1, i1, cc1, o1, x1, parameters) = caches[0] # 获取 da 和 x1 的形状大小
n_a, m, T_x = da.shape
n_x, m = x1.shape
# 初始化各梯度值
dx = np.zeros((n_x, m, T_x))
da0 = np.zeros((n_a, m))
da_prevt = np.zeros((n_a, m))
dc_prevt = np.zeros((n_a, m))
dWf = np.zeros((n_a, n_a+n_x))
dWi = np.zeros((n_a, n_a+n_x))
dWc = np.zeros((n_a, n_a+n_x))
dWo = np.zeros((n_a, n_a+n_x))
dbf = np.zeros((n_a, 1))
dbi = np.zeros((n_a, 1))
dbc = np.zeros((n_a, 1))
dbo = np.zeros((n_a, 1))
# 循环各时间步
for t in reversed(range(T_x)):
# 使用 lstm 单元反向传播计算各梯度值
gradients = lstm_cell_backward(da[:, :, t] + da_prevt, dc_prevt, caches[t])
# 保存各梯度值
dx[:,:,t] = gradients['dxt']
dWf = dWf + gradients['dWf']
dWi = dWi + gradients['dWi']
dWc = dWc + gradients['dWc']
dWo = dWo + gradients['dWo']
dbf = dbf + gradients['dbf']
dbi = dbi + gradients['dbi']
dbc = dbc + gradients['dbc']
dbo = dbo + gradients['dbo']
da0 = gradients['da_prev']
gradients = {
"dx": dx, "da0": da0, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradients