引言
近期一直在寻找一种用CPU就可以快速识别图像的方法,从经典的特征匹配方式到后面的深度学习,过程涉及了sift、surf、tensorflow2、yolov4-tiny、nanodet、yolo-fastest。经过层层筛选,最后确定了yolo-fastest,官方称树莓派4b可以达30+fps官方地址。刚好有个树莓派在手上,于是决定试试。
官方预训练模型测试
下载官方源码Yolo-Fastest-master.zip,把源码放到树莓派,解压源码
unzip Yolo-Fastest-master.zip
进入源码目录,在编译之前先确定下树莓派的gcc/g++、opencv、python版本,我的环境:
gcc (Raspbian 8.3.0-6+rpi1) 8.3.0
Python 3.7.3
opencv 4.5.1 (最好是4.x版本以上的,因为后续要用到DNN模块)
说一下opencv 4.5.1的安装方法:
输入命令
pip3 install opencv-python
这个会默认安装最新版的opencv-python,因为国外的资源非常慢,最好是通过命令后显示的网址拷贝到迅雷下载,下载好后文件是,然后输入命令进行安装
opencv_python-4.5.1.48-cp37-cp37m-linux_armv7l.whl
pip3 install opencv_python-4.5.1.48-cp37-cp37m-linux_armv7l.whl
这个时候提示需要下载numpy,用同样的方法迅雷下载numpy后,再进行pip3安装,下载完后先安装numpy再安装opencv,如果安装过程遇到需要安装其他的库,用同样的方法下载后安装。
pip3 install numpy-1.19.5-cp37-cp37m-linux_armv7l.whl
pip3 install opencv_python-4.5.1.48-cp37-cp37m-linux_armv7l.whl
完成opencv的安装后,就可以进行yolo-fastest的编译,编译之前先修改下Makefile文件,一下是我的配置,只改了一个地方。
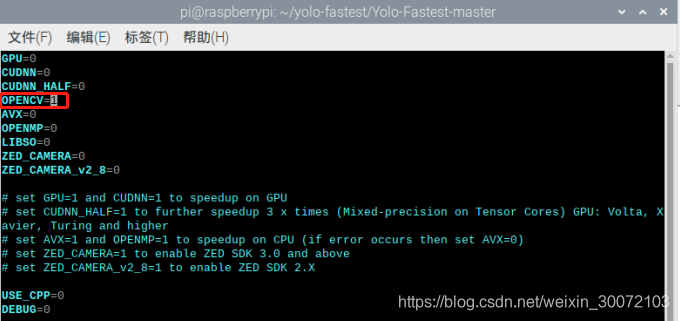
改好后保存,然后输命令
make
编译成功后,就会在目录下生成darknet文件,这个时候就可以进行测试了,输入命令:
sh image_yolov3.sh
注意,我示例是用的yolo-fastest-xl的权重,如果要用yolo-fastest的权重,需要修改下image_yolov3.sh脚本里的内容。
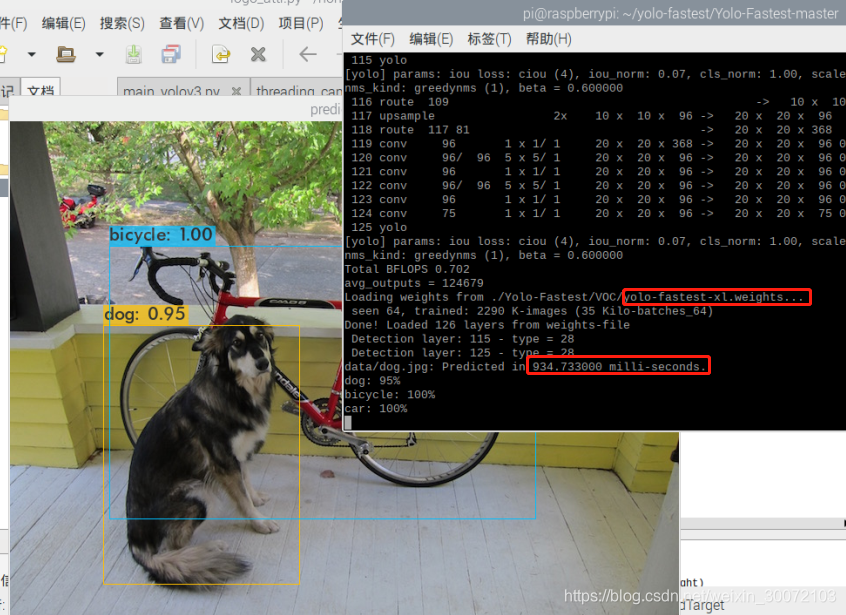
权重文件都在Yolo-Fastest文件夹里面

可以看到,官方的例子成功跑起来了,fastest-xl比fast好,我用fast测试的时候,图片里面狗被识别成了猫。但是耗时还是很高934毫秒?怎么回事???
不急,重新去官网看了资料,发现Darknet CPU推理效率优化不好,CPU建议使用NCNN

很明显,我们直接编译出来的是darknet框架,要想实时看来只能选NCNN或者MNN框架。因为之前没接触过NCNN和MNN,百度了下,是腾讯和阿里的基于arm的推理框架,可以把其他模型转成各自框架的模型,然后再去推理。也就说,你可以tflite、yolo等去训练,然后再转成NCNN/MNN模型,再通过NCNN/MNN方法去推理。
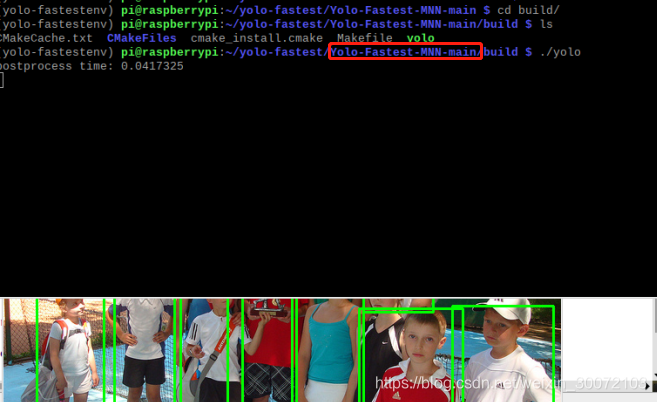
NCNN是nihui大佬在搞的一个框架,貌似只有c++,不支持python;而MNN是阿里的团队搞的,有python api也有c++ api。根据yolo-fastest官网的连接,在树莓派上都部署了MNN和NCNN,试了下速度,果然能达到40ms一张示例图。至于怎么部署MNN和NCNN可以到官网去了解,这个就不赘述了。贴张图
训练自己的数据
我的目的是测试自己训练的数据,看下识别率和处理速率。
关于训练,按官网说明进行
(1)下载yolov4的源码https://github.com/AlexeyAB/darknet[github地址],看官网关于训练的说明文档(https://github.com/AlexeyAB/darknet)
(2)按VOC的数据结构,准备好数据集,我只训练一个对象,准备了269张图片(640*480),目录结构如下
└── VOC2007
├── Annotations
│ └── data
├── ImageSets
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages
└── labels
Annotations里面是通过labelImg软件生成的标注.xml文件
data文件夹可以不用
ImageSets里面的三个文件夹都不需要
JPEGImages文件夹是装的原始图片
labels是voc_label.py生成的txt文件,每个文件里面的内容大致如下

0 0.4609375 0.45625 0.328125 0.7541666666666667
还需要生成训练文件train.txt和测试文件test.txt,可以参考这个链接
https://blog.csdn.net/Creama_/article/details/106209388 yolov4训练
(3)按照官网生成yolo-fastest.conv.109文件
(4)创建obj.data、obj.names文件,并修改好内容

(5)修改配置文件yolo-fastest.cfg,主要修改[yolo]下的classes 和 挨着[yolo]上面的fitters。具体填写需要根据你的classes来填,我只改了3个地方,如下:
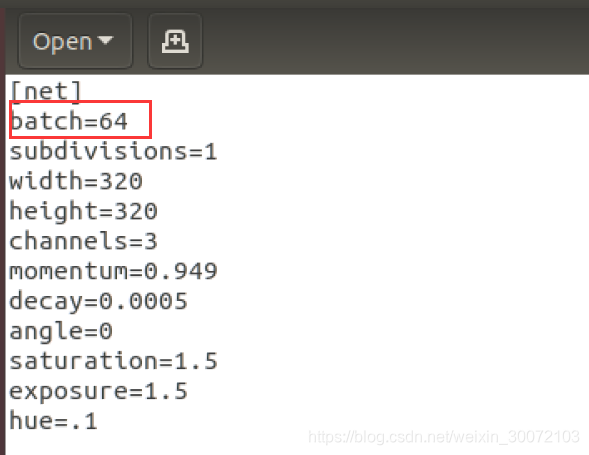


(6)改完后就可以进行训练了,我的是用虚拟机训练,8个小时训练完269张图片,效果还可以。
./darknet detector train obj.data yolo-fastest.cfg yolo-fastest.conv.109
(7)训练完成后会再backup的路劲下生成自己的权重文件,拷贝出来就可以用了。
测试
把训练好的.cfg和.weight及.names文件复制到树莓派,进行测试
本来要通过NCNN框架进行测试的,后面发现opencv4.x的DNN支持读取darknet训练的配置文件。
官方上有示例:https://blog.csdn.net/nihate/article/details/108670542 根据官方的这个示例,修改下自己的代码就可以运行了。视频检测的话60ms-100ms,够用了。
