Symbol出现的原因/作用
①作为属性 避免属性冲突重复,就是使用它来表示唯一值;
问题是我们什么情况下 要保障属性一定不冲突重复 覆盖呢?
在vue里 有this.$ parent ,this.$ options ,this.$ set 这些,使用$命名开头就是想通过命名约定来减少重复覆盖,
可是通过命名约定没有强制执行,还是存在被新生低级程序员覆盖的可能
在没有Symbol之前 采用 Object.freeze 冻结一个对象 也可以做到 一定不会覆盖修改属性的问题,但是它带来的问题就是失去了灵活性,只想一个属性不被覆盖重复,结果把整个对象都冻结了,这得不偿失。
还要Object.defineProperty(obj,‘a’,{ writable:false }) 这样通过屏蔽一个属性的可写性 来达到不能覆盖一个属性的目的,不好的地方就是麻烦。用symbol最简单。
** 作用一:防止变量名冲突,挂在window下的全局方法属性对象等,还有全局状态等,有很多地方需要保障唯一性。**
//订单已付款
if(orderStatus==='payed'){
//就干点啥
}
//订单已经取消 就干点啥
if(orderStatus==='cancel'){
//就干点啥
}
这个写法存在的问题是什么呢
1.payed cancel字符串可能在多个地方使用时 书写时出现错误;
2.字符串可能会需要修改,认为它表意不准确
3.别人难以一看就知道 orderStatus到底有哪些状态
改成如下:
const OrderStatus={
payed:Symbol('payed'),
cancel:Symbol('cancel')
}
//订单已付款
if(orderStatus===OrderStatus.payed){
//就干点啥
}
//订单已经取消 就干点啥
if(orderStatus===OrderStatus.cancel){
//就干点啥
}
** 作用二:替代字符串 ,规范代码,减少错误。**
BigInt的作用和使用
作用:
BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。
使用:
let max = Number.MAX_SAFE_INTEGER;//Number的最大安全整数
console.log(max);
console.log(max + 1);
//超过number的最大数值范围,运算就会出错
console.log(max + 2);
console.log(BigInt(max));
//BigInt数据类型不能直接和普通数据类型进行运算
console.log(BigInt(max) + BigInt(1));
console.log((BigInt(max) + BigInt(2)));
console.log((BigInt(max) + BigInt(2)).toString());
bigint后面都有一个n,区分Number类型,bigint上可以调用tostring方法转为字符串
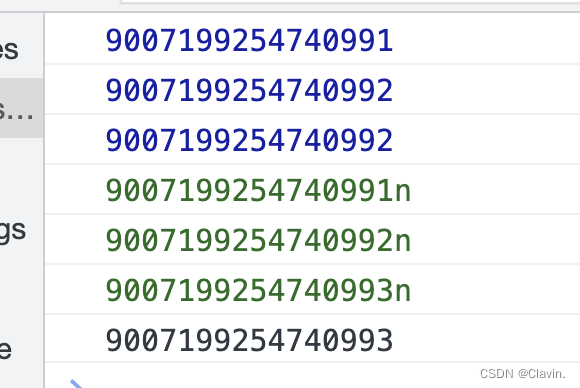
现在typeof symbol和typeof bigint返回symbol和bigint
对堆和栈的理解
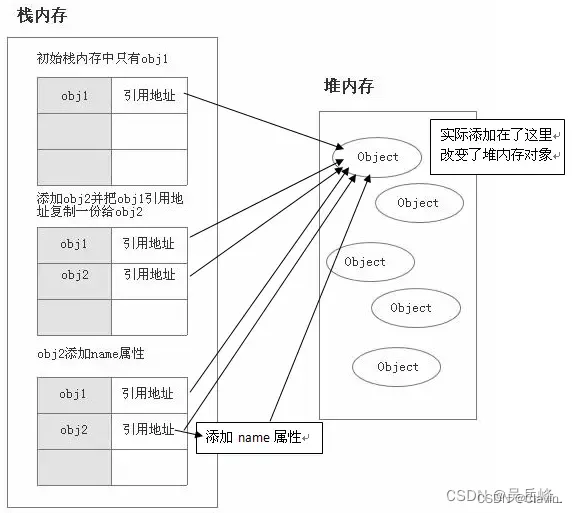
1.stack为自动分配的内存空间,它由系统自动释放;而heap则是动态分配的内存,大小也不一定会自动释放
2.引用类型数据在栈内存中保存的实际上是对象在堆内存中的引用地址。通过这个引用地址可以快速查找到保存中堆内存中的对象
3.基本数据类型存栈,引用数据类型存堆
instanceof
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log('str' instanceof String); // false
console.log([] instanceof Array); // true
console.log(function(){
} instanceof Function); // true
console.log({
} instanceof Object); // true
可以看到,instanceof只能正确判断引用数据类型,而不能判断基本数据类型。instanceof 运算符可以用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。
constructor判断类型
console.log((2).constructor === Number); // true
console.log((true).constructor === Boolean); // true
console.log(('str').constructor === String); // true
console.log(([]).constructor === Array); // true
console.log((function() {
}).constructor === Function); // true
console.log(({
}).constructor === Object); // true
constructor有两个作用,一是判断数据的类型,二是对象实例通过 constrcutor 对象访问它的构造函数。需要注意,如果创建一个对象来改变它的原型,constructor就不能用来判断数据类型了:
这里刨析下(2).constructor === Number)或
var str1 = "oujm";
var str2 = str1.substring(2);
一个基本类型不应该有constructor和substring这些属性和方法,那为什么我们可以调用这些呢?
我们忽略了,在JS的世界中有一种对象类型叫包装对象。
实际上,每当读取一个基本类型的时候,后台就会创建一个对应的基本包装类型的对象。
再来看上面那个?,str1 很明显是一个基本类型实例,问题就出在 str1.substring(2) 字符串怎么会有方法。其实,为了让我们更好的操作基本类型的实例对象,后台进行了一系列的操作:
创建String的实例
在实例上调用指定的方法
销毁这个实例
从这里能够看到,一般的引用类型和包装类型唯一的区别就在于对象的生命周期。包装类型的对象生命周期很短,只有代码执行的一瞬间,然后就被销毁了,所以这也就是为什么我们不能在运行的时候为基本类型的值添加属性和方法。
这也解答了我曾经的一个疑问
var str1 = "oujm";
var str2 = new String("ethan");
console.log(str1.__proto__ === str2.__proto__); // true
console.log(str1 instanceof String); // false
console.log(str2 instanceof String); // true
同样的道理,在调用__proto__ 属性的瞬间,也是使用new String() 先来实例化一个对象,所以那一瞬间他们的构造函数以及原型对象是相同的,但也仅仅是那一瞬间。
Object.prototype.toString.call()和直接调用toString的区别
这是因为toString是Object的原型方法,而Array、function等类型作为Object的实例,都重写了toString方法。不同的对象类型调用toString方法时,根据原型链的知识,调用的是对应的重写之后的toString方法(function类型返回内容为函数体的字符串,Array类型返回元素组成的字符串…),而不会去调用Object上原型toString方法(返回对象的具体类型),所以采用obj.toString()不能得到其对象类型,只能将obj转换为字符串类型;因此,在想要得到对象的具体类型时,应该调用Object原型上的toString方法。
判断数组的方法
Object.prototype.toString.call()
obj.proto === Array.prototype;同instanceof
通过ES6的Array.isArray()做判断
a.constructor===Array
typeof null 的结果为什么是Object?
在 JavaScript 第一个版本中,所有值都存储在 32 位的单元中,每个单元包含一个小的 类型标签(1-3 bits) 以及当前要存储值的真实数据。类型标签存储在每个单元的低位中,共有五种数据类型:
000: object - 当前存储的数据指向一个对象。
1: int - 当前存储的数据是一个 31 位的有符号整数。
010: double - 当前存储的数据指向一个双精度的浮点数。
100: string - 当前存储的数据指向一个字符串。
110: boolean - 当前存储的数据是布尔值。
如果最低位是 1,则类型标签标志位的长度只有一位;如果最低位是 0,则类型标签标志位的长度占三位,为存储其他四种数据类型提供了额外两个 bit 的长度。
有两种特殊数据类型:
undefined的值是 (-2)30(一个超出整数范围的数字);
null 的值是机器码 NULL 指针(null 指针的值全是 0)
那也就是说null的类型标签也是000,和Object的类型标签一样,所以会被判定为Object。
valueOf作用
返回给定对象的原始值
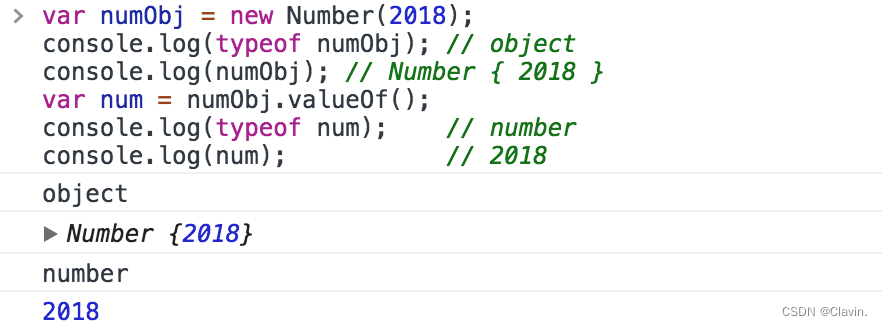

也可以使用valueOf方法将包装类型倒转成基本类型:
var a = 'abc'
var b = Object(a)
var c = b.valueOf() // 'abc'
箭头函数继承来的this指向永远不会改变,call()、apply()、bind()等方法不能改变箭头函数中this的指向,箭头函数没有prototype
var id = 'GLOBAL';
Object.prototype.id='111'
var obj = {
id: 'OBJ',
a: function(){
console.log(this.id);
},
b: () => {
console.log(this.id);
}
};
new obj.a() // 111
new obj.b() // Uncaught TypeError: obj.b is not a constructor
new操作最后一步注意
(1)首先创建了一个新的空对象
(2)设置原型,将对象的原型设置为函数的 prototype 对象。
(3)让函数的 this 指向这个对象,执行构造函数的代码(为这个新对象添加属性)
(4)判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个引用类型的对象。
判断return的result逻辑
result && (typeof result === "object" || typeof result === "function");
什么是尾调用?好处是什么
尾调用指的是函数的最后一步调用另一个函数。代码执行是基于执行栈的,所以当在一个函数里调用另一个函数时,会保留当前的执行上下文,然后再新建另外一个执行上下文加入栈中。使用尾调用的话,因为已经是函数的最后一步,所以这时可以不必再保留当前的执行上下文,从而节省了内存,这就是尾调用优化。但是 ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
function f(x){
return g(x);
}
Es6和commonJs的区别
for… in 会遍历对象的整个原型链,性能非常差
fetch请求的优缺点
Fetch
fetch号称是AJAX的替代品,是在ES6出现的,使用了ES6中的promise对象。Fetch是基于promise设计的。Fetch的代码结构比起ajax简单多。fetch不是ajax的进一步封装,而是原生js,没有使用XMLHttpRequest对象。
fetch的优点:
语法简洁,更加语义化
基于标准 Promise 实现,支持 async/await
更加底层,提供的API丰富(request, response)
脱离了XHR,是ES规范里新的实现方式
fetch的缺点:
fetch只对网络请求报错,对400,500都当做成功的请求,服务器返回 400,500 错误码时并不会 reject,只有网络错误这些导致请求不能完成时,fetch 才会被 reject。
fetch默认不会带cookie,需要添加配置项: fetch(url, {credentials: ‘include’})
fetch不支持abort,不支持超时控制,使用setTimeout及Promise.reject的实现的超时控制并不能阻止请求过程继续在后台运行,造成了流量的浪费
fetch没有办法原生监测请求的进度,而XHR可以
forEach可以改变原数组吗?
every和some的区别
Promise的Race的使用场景

如何避免回流?
1.元素使用absolute或者fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
2.将DOM的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机制。
浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列
浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。
上面,将多个读操作(或者写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。
节流场景:动画场景:避免短时间内多次触发动画引起性能问题
代码输出
const promise = new Promise((resolve, reject) => {
console.log(1);
console.log(2);
});
promise.then(() => {
console.log(3);
});
console.log(4);
代码
Promise.resolve(1)
.then(res => {
console.log(res);
return 2;
})
.catch(err => {
return 3;
})
.then(res => {
console.log(res);
});
上面的输出结果之所以依次打印出1和2,是因为resolve(1)之后走的是第一个then方法,并没有进catch里,所以第二个then中的res得到的实际上是第一个then的返回值。并且return 2会被包装成resolve(2),被最后的then打印输出2。
代码题:
Promise.reject('err!!!')
.then((res) => {
console.log('success', res)
}, (err) => {
console.log('error', err)
}).catch(err => {
console.log('catch', err)
})
输出结果如下:
error err!!!
我们知道,.then函数中的两个参数:
第一个参数是用来处理Promise成功的函数
第二个则是处理失败的函数
也就是说Promise.resolve(‘1’)的值会进入成功的函数,Promise.reject(‘2’)的值会进入失败的函数。
在这道题中,错误直接被then的第二个参数捕获了,所以就不会被catch捕获了,输出结果为:error err!!!’
但是,如果是像下面这样:
Promise.resolve()
.then(function success (res) {
throw new Error('error!!!')
}, function fail1 (err) {
console.log('fail1', err)
}).catch(function fail2 (err) {
console.log('fail2', err)
})
在then的第一参数中抛出了错误,那么他就不会被第二个参数捕获了,而是被后面的catch捕获到。
代码题:
finally本质上是then方法的特例
Promise.resolve('1')
.finally(() => {
console.log('finally1')
throw new Error('我是finally中抛出的异常')
})
.then(res => {
console.log('finally后面的then函数', res)
})
.catch(err => {
console.log('捕获错误', err)
})
‘finally1’
‘捕获错误’ Error: 我是finally中抛出的异常
代码题
var length = 10;
function fn() {
console.log(this.length);
}
var obj = {
length: 5,
method: function(fn) {
fn();
arguments[0]();
}
};
obj.method(fn, 1);
输出结果: 10 2
解析:
第一次执行fn(),this指向window对象,输出10。
第二次执行arguments0,相当于arguments调用方法,this指向arguments,而这里传了两个参数,故输出arguments长度为2。
代码
function foo(something){
this.a = something
}
var obj1 = {
}
var bar = foo.bind(obj1);
bar(2);
console.log(obj1.a); // 2
var baz = new bar(3);
console.log(obj1.a); // 2
console.log(baz.a); // 3
代码:
(function(){
var x = y = 1;
})();
var z;
console.log(y); // 1
console.log(z); // undefined
console.log(x); // Uncaught ReferenceError: x is not defined
这段代码的关键在于:var x = y = 1; 实际上这里是从右往左执行的,首先执行y = 1, 因为y没有使用var声明,所以它是一个全局变量,然后第二步是将y赋值给x,讲一个全局变量赋值给了一个局部变量,最终,x是一个局部变量,y是一个全局变量,所以打印x是报错。
典
function a() {
var temp = 10;
function b() {
console.log(temp); // 10
}
b();
}
a();
function a() {
var temp = 10;
b();
}
function b() {
console.log(temp); // 报错 Uncaught ReferenceError: temp is not defined
}
a();
js中变量的作用域链与定义时的环境有关,与执行时无关。执行环境只会改变this、传递的参数、全局变量等
原型:
console.log(Object.proto)//Function.prototype
代码:
// a
function Foo () {
getName = function () {
console.log(1);
}
return this;
}
// b
Foo.getName = function () {
console.log(2);
}
// c
Foo.prototype.getName = function () {
console.log(3);
}
new Foo().getName(); // 3
new new Foo().getName(); // 3
new Foo().getName(), 这 里等价于 (new Foo()).getName(), 先new一个Foo的实例,再执行这个实例的getName方法,但是这个实例本身没有这个方法,所以去原型链__protot__上边找,实例.protot === Foo.prototype,所以输出 3;
new new Foo().getName(), 这里等价于new (new Foo().getName()),如上述6,先输出 3,然后new 一个 new Foo().getName() 的实例。
代码
function A(){
}
function B(a){
this.a = a;
}
function C(a){
if(a){
this.a = a;
}
}
A.prototype.a = 1;
B.prototype.a = 1;
C.prototype.a = 1;
console.log(new A().a);
console.log(new B().a);
console.log(new C(2).a);
实现一个简易的useState
let memoizedState = []; // 存放hooks
let cursor = 0; // 当前 memoizedState 下标
function reRender() {
cursor = 0;
ReactDOM.render(<App />, rootElement);
}
// 如果是初次执行useState,使用传入的初始值。 更新环节使用缓存的值
function useState(initialValue) {
memoizedState[cursor] = memoizedState[cursor] || initialValue;
const currentCursor = cursor;
const setState = newState => {
memoizedState[currentCursor] = newState;
reRender();
};
return [memoizedState[cursor++], setState]; // 返回当前 state,并把 cursor 加 1
}
useEffect的依赖项数组是如何比较的?
useEffect对于依赖项执行的是浅比较,即Object.is (arg1, arg2),这可能是出于性能考虑。对于原始类型这没有问题,但对于引用类型(数组、对象、函数等),这意味着即使内部的值保持不变,引用本身也会发生变化,导致 useEffect执行副作用。
304状态码出现过多会造成以下问题:
网站快照停止;
收录减少;
权重下降。
OPTIONS请求方法及使用场景
OPTIONS是除了GET和POST之外的其中一种 HTTP请求方法。
OPTIONS请求方法的主要用途有两个:
获取服务器支持的所有HTTP请求方法;
用来检查访问权限。例如:在进行 CORS 跨域资源共享时,对于复杂请求,就是使用 OPTIONS 方法发送嗅探请求,以判断是否有对指定资源的访问权限。
数字证书是什么?
现在的方法也不一定是安全的,因为没有办法确定得到的公钥就一定是安全的公钥。可能存在一个中间人,截取了对方发给我们的公钥,然后将他自己的公钥发送给我们,当我们使用他的公钥加密后发送的信息,就可以被他用自己的私钥解密。然后他伪装成我们以同样的方法向对方发送信息,这样我们的信息就被窃取了,然而自己还不知道。为了解决这样的问题,可以使用数字证书。
首先使用一种 Hash 算法来对公钥和其他信息进行加密,生成一个信息摘要,然后让有公信力的认证中心(简称 CA )用它的私钥对消息摘要加密,形成签名。最后将原始的信息和签名合在一起,称为数字证书。当接收方收到数字证书的时候,先根据原始信息使用同样的 Hash 算法生成一个摘要,然后使用公证处的公钥来对数字证书中的摘要进行解密,最后将解密的摘要和生成的摘要进行对比,就能发现得到的信息是否被更改了。
这个方法最要的是认证中心的可靠性,一般浏览器里会内置一些顶层的认证中心的证书,相当于我们自动信任了他们,只有这样才能保证数据的安全。
DNS使用了tcp还是udp?
DNS占用53号端口,同时使用TCP和UDP协议。
(1)在区域传输的时候使用TCP协议
(2)在域名解析的时候使用UDP协议
this题目
var length = 10;
function fn() {
return this.length
}
var obj = {
length: 5,
test1: function() {
let f=function(){
return this
}
//this是运行时确定的,指向要看调用方式,比如a的this是test1中的this,他是通过obj.的形式调用的,所以this为obj
//b是直接执行的,没有隐式绑定和显式绑定,所以this为window,c也是直接执行的,this为window
const a=this.length
const b=f();
const c=fn()
return [a,b,c]
}
};
console.log(obj.test1())
一道题目
var func1 = x => x;
var func2 = x => {
x};
var func3 = x => ({
x});
console.log(func1(1));
console.log(func2(1));
console.log(func3(1));
常用的meta标签
meta标签是什么
meta 标签由 name 和 content 属性定义,用来描述网页文档的属性,比如网页的作者,网页描述,关键词等
1.charset,用来描述HTML文档的编码类型
2.viewport,适配移动端,可以控制视口的大小和比例:
代码题
作用域是静态的,声明时确定;this是动态的,运行时确定。
const list = [1, 2, 3];
const square = (num) => {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(num * num);
}, 1000);
});
}
function test() {
list.forEach(async (x) => {
const res = await square(x);
console.log(res);
});
}
test()
//相当于下面
new Promise((resolve, reject) => {
setTimeout(() => {
resolve()
}, 1000)
}).then(res=>{
console.log(1)
})
new Promise((resolve, reject) => {
setTimeout(() => {
resolve()
}, 1000)
}).then(res=>{
console.log(4)
})
new Promise((resolve, reject) => {
setTimeout(() => {
resolve()
}, 1000)
}).then(res=>{
console.log(9)
})
this题目
inner = 'window';
var obj1 = (function() {
var inner = '1-1';
return {
inner: '1-2',
say: function() {
console.log(inner);
console.log(this.inner);
}
}
})();
var obj2 = (function() {
var inner = '2-1';
return {
inner: '2-2',
say: function() {
console.log(inner);
console.log(this.inner);
}
}
})();
obj1.say();
obj1.say = obj2.say;
obj1.say();
给一个div设置它父级div的宽度是100px,然后再设置它的padding-top为20%。
问现在的div有多高?如果父级元素定位是absolute呢?
现有div的高度等于自身高度+父级块的宽度*20%,如果父级元素定位是absolute,结果不变;
当margin/padding取形式为百分比的值时,无论是left/right,还是top/bottom,都是以父元素的width为参照物的!
如果子元素的padding and margin 基于父元素的高度来判断的话 会陷入死循环
for in 与for of区别?
for in 应用于数组中
使用for-in会遍历数组所有的可枚举属性,包括原型。原型方法method和name属性都会被遍历出来,通常需要配合hasOwnProperty()方法判断某个属性是否该对象的实例属性,来将原型对象从循环中剔除。
Array.prototype.sayHello = function(){
console.log('hello');
}
Array.prototype.str = 'world'
var myArray = [1,2,10,30,34]
myArray.name = '数组'
for (const key in myArray) {
console.log(key);
}
//迭代的是属性key,不是值。
//结果 0 1 2 3 4 name sayHello str
故for in适用于遍历对象中的键值对,for of适用于遍历数组
为什么要有 useRef?
保存 DOM 元素的引用
在函数组件中,我们无法像类组件中那样直接使用 this 来获取 DOM 元素的引用。而 useRef 可以用来保存 DOM 元素的引用,方便我们获取或修改其属性。
保存组件的状态
在函数组件中,每次组件重新渲染时,所有的变量都会被重新声明和初始化。为了在多次渲染之间保留一些数据,我们可以使用 useRef 来保存这些数据,它们在组件的整个生命周期中保持不变。
避免重新渲染的性能问题
在某些情况下,我们需要保存一些数据,但是这些数据并不需要触发重新渲染。如果使用 useState,每次更新这些数据都会触发组件的重新渲染,从而浪费性能。而使用 useRef 可以避免这个问题。
代码
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);
return <h1>{
count}</h1>;
}
- count输出是啥 ? 为什么? 如何修改?
从0变成1,然后不变,因为依赖数组是空,所以只执行一次
想要一秒count+1可以在依赖数组里面写上count
代码题
new Array(100).map((_, i) => i);返回什么?
length为100的数组,没有元素
请创建一个长度为100的数组,在里面存入[0,1,2,…,99]
const arr = […Array(100)].map((, i) => i);
Array(100).fill().map((, i) => i)
如何判断事件是不是可以冒泡?
每个 event 都有一个event.bubbles属性,通过该属性可知是否冒泡
其中 price 为酒店的价格,score 为酒店评分,按照以下策略给酒店排序:
先按价格由低到高排序,价格相等时,按评分由高到低排序
代码
const a={
hotels: [{
id: 1,
price: 100,
score: 80
}, {
id: 2,
price: 70,
score: 90,
}, {
id: 3,
price: 70,
score: 95
}]
}
a.hotels.sort((a,b) => {
if (a.price === b.price) {
return b.score-a.score
} else {
return a.price - b.price
}
})
console.log(a)
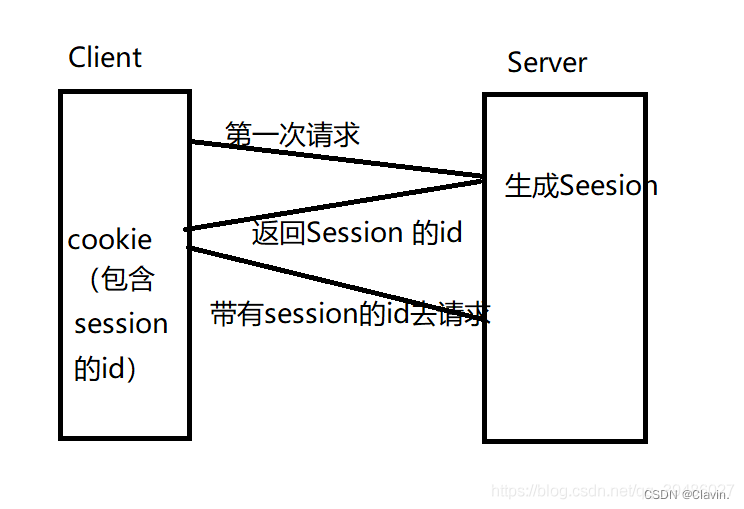
cookie和session机制
Session 和 Cookie 功能效果是差不多的,区别就是session 是记录在服务端的,Cookie是记录在客户端的。都是记录一系列状态的。
结合:就是把session的id 放在cookie里面(为什么是使用cookies存放呢,因为cookie有临时的,也有定时的,临时的就是当前浏览器什么时候关掉即消失,也就是说session本来就是当浏览器关闭即消失的,所以可以用临时的cookie存放。保存再cookie里的sessionID一定不会重复,因为是独一无二的。),当允许浏览器使用cookie的时候,session就会依赖于cookies,当浏览器不支持cookie后,就可以通过第二种方式获取session内存中的数据资源。
absolute元素会相对设置position: fixed的元素定位吗?
答案
设置postion: absolute;的元素会相对于值不为 static的第一个父元素进行定位
xhr.abort()取消发送ajax请求
promise值穿透
.then 或者 .catch 的参数期望是函数,传入非函数则会发生值穿透。
Promise方法链通过return传值,没有return就只是相互独立的任务而已
1
Promise.resolve('foo').then(Promise.resolve('bar')).then(function (result) {
console.log(result);});
2
Promise.resolve(1)
.then(function(){
return 2})
.then(function(){
return Promise.resolve(3)})
.then(console.log)
3
Promise.resolve(1)
.then(function(){
return 2})
.then(Promise.resolve(3))
.then(console.log)
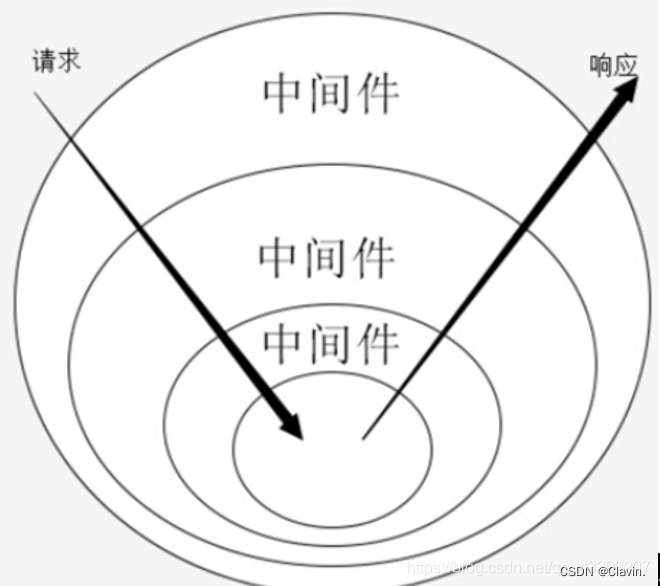
洋葱模型
可以看到要从洋葱中心点穿过去,就必须先一层层向内穿入洋葱表皮进入中心点,然后再从中心点一层层向外穿出表皮,这里有个特点:进入时穿入了多少层表皮,出去时就必须穿出多少层表皮。先穿入表皮,后穿出表皮,符合我们所说的栈列表,先进后出的原则。
浮动&行内块元素特点
首先行内块元素的宽度不设置的话不会继承父级的100%,需手动设置
浮动元素具有行内块的特性,设置浮动的元素只会影响它后面元素的标准流,不会影响它前面的元素布局。
设置inline-block的元素并排后后出现空白缝隙怎么解决?
方法一:父元素设置font-size为0,子元素单独再设置字体大小
代码题
const bbb = {
abc:1
}
function a(o) {
const f = function () {
}
f.prototype = o
return new f()
}
const bb = new a(bbb)
//12行是往bb实例上添加abc属性,不会去改变原型的abc就被拦截了
bb.abc = 2;
console.log(bbb,bb)
css实现宽高比固定的元素
1.当普通元素的宽高都未知时,不用 css 的话,我们可以想到使用 js 实时获取元素的 width 或者 height,然后按照比例计算另一个值,用 css 的话就得需要一点技巧,总的来说就是使用 padding 来撑大高度,代码如下:
<div class="mainWrap">
<div class="main"></div>
</div>
css:
.mainWrap {
width: 20vw;
}
.main {
width: 100%;
padding-bottom: 75%;
background: black;
}
2.使用 aspect-ratio,这个 css 属性是专门用来设定固定宽高比的,不过使用的时候需要注意看一下浏览器的兼容性
代码题:
console.log(['1','2','3'].map(parseInt))//1 NAN NAN
所以实际执行的的代码是:
[‘1’, ‘2’, ‘3’].map((item, index) => {
return parseInt(item, index)
})
即返回的值分别为:
parseInt(‘1’, 0) // 1
parseInt(‘2’, 1) // NaN
parseInt(‘3’, 2) // NaN, 3 不是二进制