点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:火木鱼(源:知乎,已授权)| 编辑:CVer公众号
https://zhuanlan.zhihu.com/p/620884206
在CVer微信公众号后台回复:H2R,可以下载本论文pdf、代码
一、引言
H2RBox-v2发布了,这篇文章作为H2RBox的新版本,提出了对称感知学习(Symmetry-aware Learning),即通过对称性自监督学习目标的角度,性能相比H2RBox提升明显。
这篇文章的研究主题是:从水平框标注学习有向目标检测(弱监督学习),即在人工标注仅有水平框,没有旋转角度的情况下,神经网络是否能学习出每个目标的旋转角度。

H2RBox-v2: Incorporating Symmetry for Boosting Horizontal Box Supervised Oriented Object Detection论文:https://arxiv.org/abs/2304.04403代码(已开源):https://github.com/open-mmlab/mmrotate
在目前现有的几种方案上做了个对比,包括基于SAM(Segment Anything Model)的方法:

二、灵感
对称性是广泛存在于各类场景中的天然属性,以DOTA数据集为例,其中飞机、球场、汽车、船舶等诸多类别都具有显著的对称性。在人工对图像进行有向标注的过程中,目标的对称性同样是重要考虑因素之一,人们通常会很自然地将对称轴的方向作为目标朝向,那么在水平框弱监督中通过对称性学习目标的朝向,理论上也是可行的。
原理解析
轴对称的定义:如果一个平面图形沿着一条直线翻转后,与原本的图形能够互相重合,那么这个图形为轴对称图形,这条直线为对称轴。



于是驱动H2RBox-v2的核心理论就诞生了:假如网络输入了一个轴对称图像作为激励, 训练这个网络去满足翻转一致性和旋转一致性,就相当于用输入图像的对称性对网络进行监督。如果网络成功学习到了翻转一致性和旋转一致性,那么网络的输出就会刚好是这张图像的对称轴方向。
上面这个结论虽然是在输入图像只有单个目标且完全对称的情况下推导的,但是实验表明,即使对于多目标检测,包括目标并非完美对称的情况下,都可以学习到近似于对称轴的方向,也就是说这个原理其实适用于几乎所有的长条形目标,和有向目标检测的应用场景可以说是完美契合。
顺便提一下,其实这里为了比较容易看懂,没有把旋转周期性加上,严谨的结论是有两个解,要么是对称轴方向,要么垂直于对称轴方向。这其实不影响网络的训练,当自监督分支学习到垂直于对称轴方向的时候,弱监督分支也会自动调换长边和短边,最终的输出总是对的。
三、方法介绍
先简单提一下老版本,H2RBox-v1包含一个弱监督分支和一个自监督分支,其中目标的尺寸和角度都主要靠弱监督分支学习,本质是通过水平框的外接几何约束学习角度,学习到的角度有若干种对称的解,再依靠自监督分支提供的角度约束消除其中的错误解。这种方式对水平框的标注精度要求较高,对训练数据量要求也较大。
H2RBox-v2同样包含一个弱监督分支和一个自监督分支,其中弱监督分支在H2RBox-v1的基础上稍微改进,而自监督分支采用了全新的Symmetry-aware Learning范式,能够独立于弱监督分支工作,直接从图像中根据目标的对称性学习目标的方向。
整体结构图:
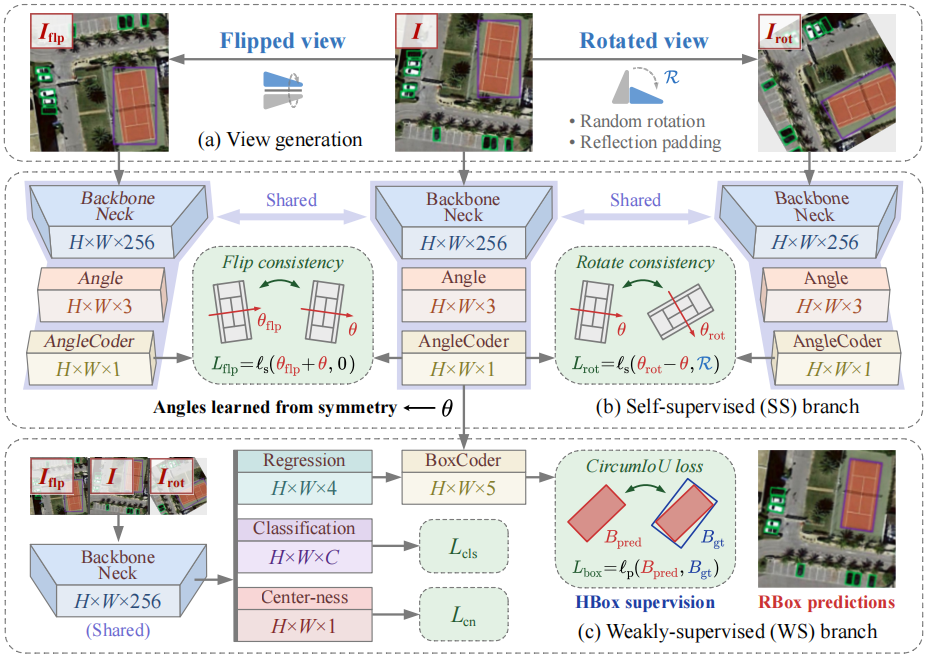
自监督分支
H2RBox-v2的自监督分支首先要将原图像生成两个视图,1)上下翻转,2)随机旋转。自监督分支中网络只预测一个角度值(首先为每个像素输出长度为3的向量,再通过PSC角度编码后得到角度)。
这个角度编码方法是源自:
https://zhuanlan.zhihu.com/p/620775646

弱监督分支
H2RBox-v2的弱监督分支核心改进有两点:
1)因为H2RBox-v2的自监督可以独立工作,也就不需要从弱监督学习角度了,所以弱监督这边不需要给角度回归的Subnet传递任何信息,在代码中用了detach断开梯度。
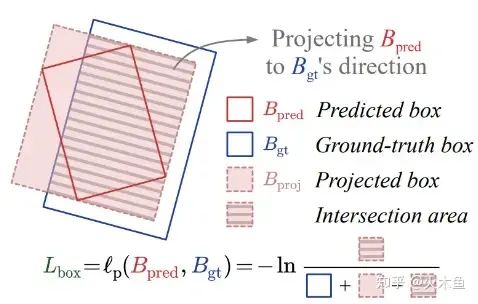
2)H2RBox-v1的弱监督分支中要把旋转框转换成水平框,再计算IoU Loss。但是一旦使用随机旋转数据增强,标注框就不再是水平框了,这就导致H2RBox-v1无法使用随机旋转数据增强。为了解决这个问题,H2RBox-v2提出了一种CircumIoU Loss,直接计算外接关系的两个框之间的IoU损失:
最终的Loss就只要把弱监督分支和自监督分支直接相加就好了。
推理过程
前面的两个分支都是在训练的时候用于计算Loss的,在推理的时候则不需要生成视角。由于不同分支共享参数,只要推理一次(Backbone+Angle/Regression/Classification/Centerness Heads),推理过程和原始的检测器或H2RBox-v1相比,只多了一次PSC解码,因此推理速度几乎相同。
四、实验
消融实验
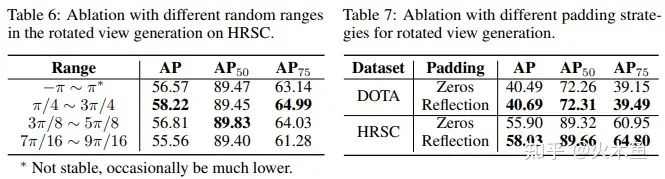
Table 3-4:首先是针对自监督和弱监督中提出的新Loss进行验证,可以看出PSC编码器和Snap Loss(表中 ls 列)都是必须的,否则因为边界问题会导致训练很不稳定,而CircumIoU Loss(表中 lp 列)也确实解决了H2RBox-v1不能旋转增强的问题。DOTA上面旋转增强后性能没有提高应该是因为对比的时候统一用的1x训练量,对旋转增强来说是不够的。
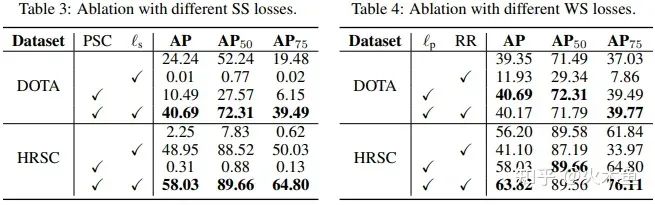
Table 5:再来看翻转和旋转之间的权重,翻转的权重要比旋转小,0.05或者0.1比较好,大了不收敛。
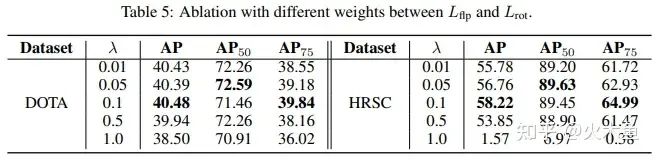

Table 7:最后还有一个Padding的实验,H2RBox-v1里面Padding很重要,不能留黑边,必须用反射填充。但是在H2RBox-v2里面,黑边影响已经很小了,只低一丢丢(不排除是随机因素,也可能其实是没影响)。
对比实验
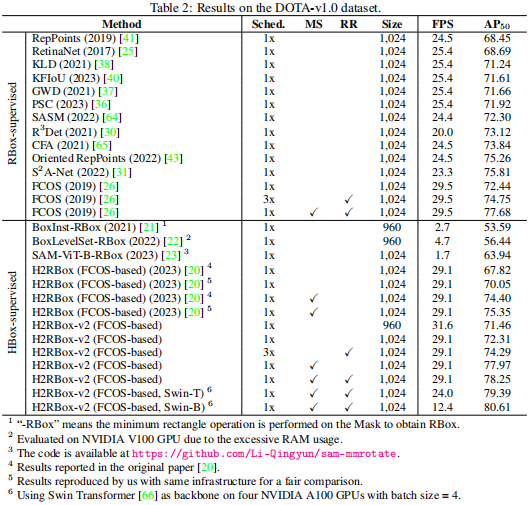
H2RBox-v2在DOTA的v1.0/1.5/2.0三个版本,以及HRSC和FAIR1M数据集上都进行了实验。其中DOTA-v1.0上面做了比较多的实验,H2RBox-v2相比v1的提升是2.26%。这里对比的v1是用MMRotate1.0新代码,并且重新调整学习率等参数后的复现结果,本身基准是比原始的v1论文高2个点的。
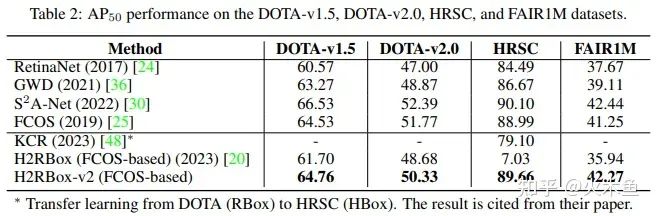
在DOTA-v1.5/2.0上,也是类似的提升幅度,三个版本的DOTA平均下来提高2.32%。
HRSC因为数据集比较小,H2RBox-v1基本上是训练不了的,而H2RBox-v2在这种小数据集上效果同样很好。这里提一下KCR(CVPR 2023),这个方法是迁移学习,用有向框标注的DOTA训练,迁移到水平框标注的HRSC,达到了79.10%,已经是当前的SOTA了。而H2RBox-v2单纯使用水平框标注的HRSC,就达到了89.66%。
最后再说一下FAIR1M,这个数据集和DOTA相比,包含更多飞机、汽车、球场这种对称性非常显著的目标,因此H2RBox-v2在这个数据集上效果非常好,比v1提高了6.33%,甚至比完全监督的FCOS还高1.02%(H2RBox-v2的检测器也是基于FCOS的,所以这两个的对比可以说明弱监督和完全监督之间的差距)。
五、总结
H2RBox-v2的主要创新在于对称性自监督学习,直接从目标的对称性获取方向信息,在Plane、Ship、Vehicle等类别上取得了相当好的效果,但也有一些类别是不太适用的,比如Baseball-diamond。如果对其中一些类别按照v2的方式学习,而另一些对称性不佳的目标仍然保留v1的外接矩形几何约束方式,有可能获得更高的性能。
在CVer微信公众号后台回复:H2R,可以下载本论文pdf、代码
点击进入—>【遥感图像和目标检测】交流群
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集遥感图像和目标检测交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-遥感图像或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如遥感图像或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看