点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在CVer微信公众号后台回复:VisorGPT,可以下载本论文pdf、代码

代码:https://github.com/Sierkinhane/VisorGPT
论文:https://arxiv.org/abs/2305.13777
论文简介
可控扩散模型如ControlNet、T2I-Adapter和GLIGEN等可通过额外添加的空间条件如人体姿态、目标框来控制生成图像中内容的具体布局。使用从已有的图像中提取的人体姿态、目标框或者数据集中的标注作为空间限制条件,上述方法已经获得了非常好的可控图像生成效果。那么如何更友好、方便地获得空间限制条件?或者说如何自定义空间条件用于可控图像生成呢?例如自定义空间条件中物体的类别、大小、数量、以及表示形式(目标框、关键点、和实例掩码)。
本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式来建模上述视觉先验。因此,我们可以从学习好的先验中通过Prompt从多个层面,例如表示形式(目标框、关键点、实例掩码)、物体类别、大小和数量,来采样空间限制条件。我们设想,随着可控扩散模型生成能力的提升,以此可以针对性地生成图像用于特定场景下的数据补充,例如拥挤场景下的人体姿态估计和目标检测。
欢迎加入CVer计算机视觉知识星球!每天更新最新最前沿的AI论文、项目,扫描下方二维码,即可加入学习!

方法介绍
表1 训练数据

本文从当前公开的数据集中整理收集了七种数据,如表1所示。为了以Generative Pre-Training的方式学习视觉先验并且添加序列输出的可定制功能,本文提出以下两种Prompt模板:

使用上述模板可以将表1中训练数据中每一张图片的标注格式化成一个序列x。在训练过程中,我们使用BPE算法将每个序列x编码成tokens={u1,u2,…,u3},并通过极大化似然来学习视觉先验,如下式:
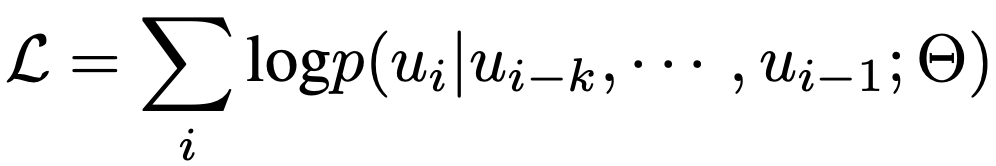
最后,我们可以从上述方式学习获得的模型中定制序列输出,如下图所示。
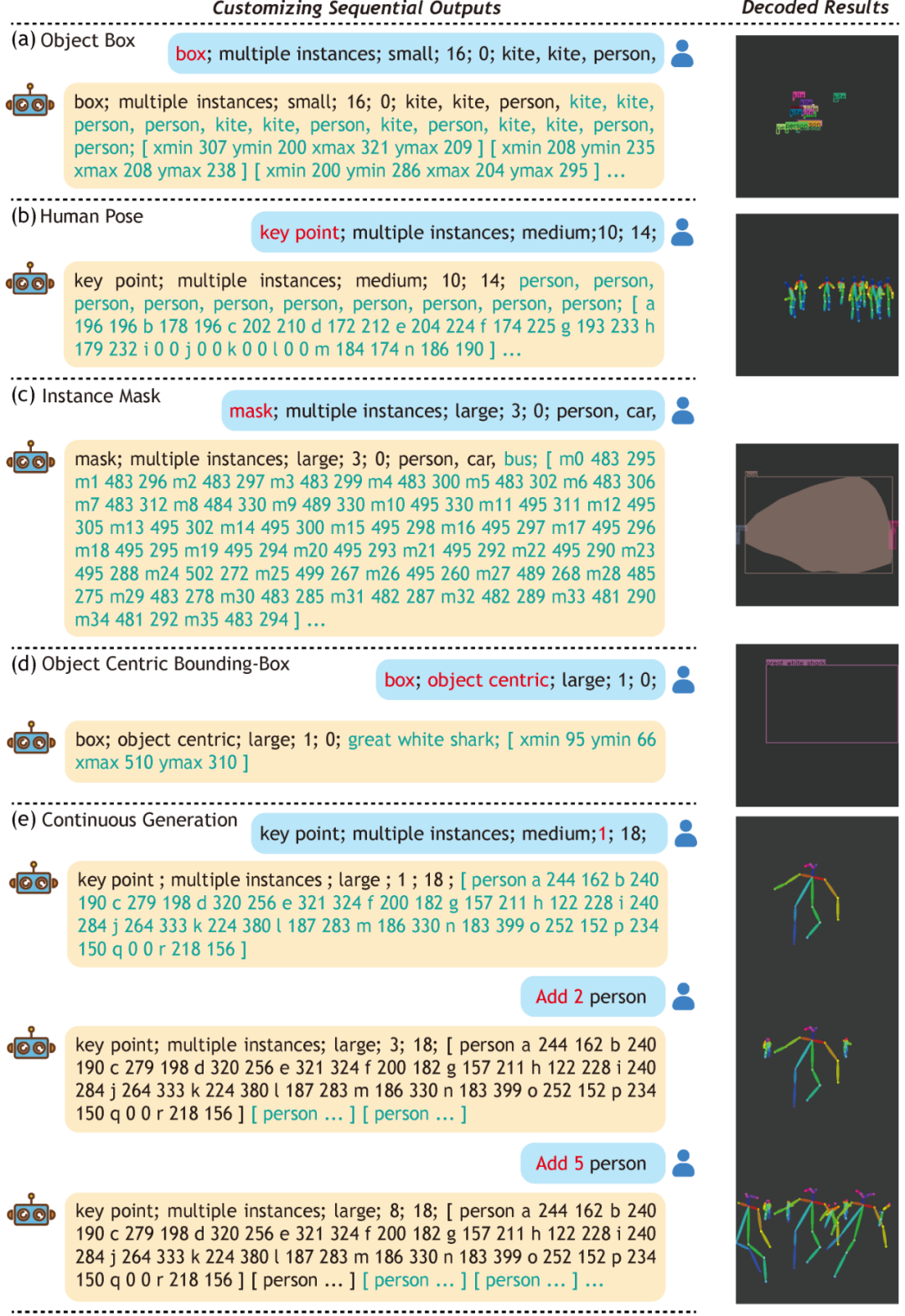
图1 定制序列输出
效果展示



更多技术细节请参阅原论文。
在CVer微信公众号后台回复:VisorGPT,可以下载本论文pdf、代码
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集扩散模型和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-扩散模型或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如扩散模型或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看