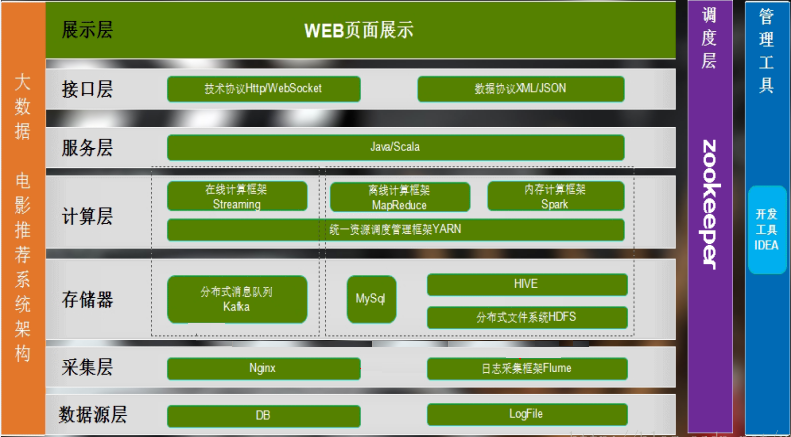
数据库和分布式数据计算平台
一、概述
常见的数据库和分布式数据计算平台有:MySQL、Redis、HybridDB for MySQL、Hbase(100亿)、MongoDB(10亿)、MemcacheDB;Spark、Hadoop、Hive、kafka、Flume、zookeper、MyBatis
- RDBMS:relational database management system
- HybridDB for MySQL:在线事务(OLTP)和在线分析(OLAP)的 关系型 HTAP(Hybrid(混合) Transaction/Analytical Processing)类数据库
- HBase:是一个分布式的、面向 列 的开源数据库。一个非结构化数据的分布式存储系统,HBase基于列的而不是基于行的模式。HBase更适合低延时的数据访问
- HBase 和 Redis 在功能上比较类似:比如它们都属于 NoSQL 级别的数据库,都支持数据分片等
- HBase:适用于简单数据写入(如“消息类”应用)和海量、结构简单数据的查询(如“详单类”应用)
- HBase用于在线应用的实例:Facebook的消息类应用,包括Messages、Chats、Emails和SMS系统,用的都是HBase;淘宝的WEB版阿里旺旺,后台是HBase;小米的米聊用的也是HBase;移动某省公司的手机详单查询系统,去年也由原先的Oracle改成了一个32节点的HBase集群
- MongoDB:是一个基于分布式文件存储的数据库,由 C++ 语言编写,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案
- MemcacheDB:是一款分布式键值持久存储系统。MemcacheDB支持memcached协议,但是 MemcacheDB系统是持久化存储,MemcacheDB和MySQL组合使用提高MySQL写的效率
- 数据计算框架:在线计算框架:Streaming;离线计算框架:MapReduce;内存计算框架:Spark。
- Spark:是一个快速、通用的大规模数据处理引擎
- Hadoop:是一个分布式系统基础架构
- Hive:是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载(ETL工具:Extract 抽取-Transform 转换-Load 加载)。这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。底层是基于MapReduce,但是是符合SQL语法
- kafka:是一个分布式、支持分区的(partition)、多副本的(replica),基于 zookeeper 协调的分布式消息系统,可以实时的处理大量数据以满足各种需求场景
- Flume:是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据
- zookeeper:是一个分布式服务框架。zookeeper主要用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等
- MyBatis:是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。iBATIS提供的持久层框架包括 SQL Maps 和Data Access Objects(DAOs)
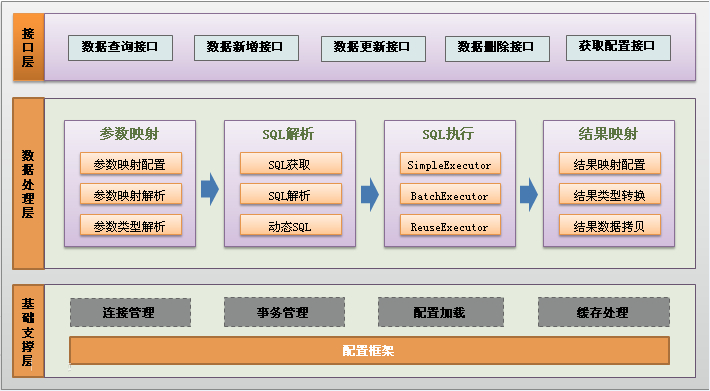
二、分布式数据计算平台
1、Hadoop/MapReduce和Spark最适合的都是做离线型的数据分析,但Hadoop特别适合是单次分析的数据量“很大”的情景,而Spark则适用于数据量不是很大的情景。数据量是相对于整个集群中的内存容量而言的,因为Spark是需要将数据HOLD在内存
2、基于Flume采集到 HDFS 中的数据,MapReduce 将数据清理(选择合适的信息字段,或者根据业务需求解析源数据中的信息字段包含的信息并增加新的信息字段)之后将数据保存到 HDFS,根据 HDFS 中规整的数据按照业务需求进行数据的统计分析。
3、MapReduce 程序的编写又分为写Mapper(拉取数据)、Reducer、Job三个基本的过程。
4、Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功,能将SQL语句转变成MapReduce任务来执行。由于底层是MapReduce,与shark(改进hive中的内存管理,执行等部分)和spark相比,运行速度不佳。
5、离线型的数据处理和在线型的数据处理,基本的数据来源都是日志数据。如针对于web应用来说,则可能是用户的访问日志、用户的点击日志等
6、离线型的数据处理和在线型的数据处理架构
图-1 数据处理架构图
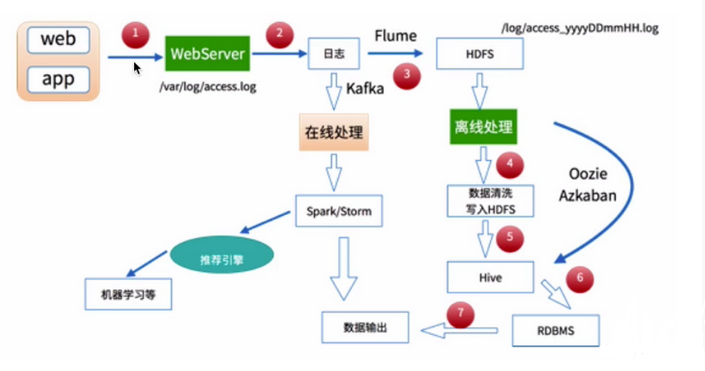
7、数据处理软件架构示例: