文章目录
-
- 一、SIDD-Image (Segmented Intrusion Detection Dataset)
- 二、Sports10
- 三、Stream-51
- 四、ASIRRA ((Animal Species Image Recognition for Restricting Access)
- 五、AdvNet
- 六、BCNB (Early Breast Cancer Core-Needle Biopsy WSI)
- 七、Deep PCB (Deep Printed Circuit Board)
- 八、Endotect Polyp Segmentation Challenge Dataset
- 九、FMD (materials) (Flickr Material Dataset)
- 十、Image and Video Advertisements
一、SIDD-Image (Segmented Intrusion Detection Dataset)
这是第一个基于图像的网络入侵检测数据集。 这个大规模数据集包括来自亚洲不同国家 15 个不同观测地点的基于网络流量协议通信的图像。 该数据集用于从良性网络流量中识别两种不同类型的异常。 每张尺寸为48×48的图像包含128秒内的多协议通信。 SIDD 数据集可应用于广泛的任务,例如基于机器学习的网络入侵检测、非独立同分布联邦学习等。
二、Sports10
游戏数据集包含 100,000 个游戏图像,涉及 10 个体育类型的 175 个视频游戏 - 美式足球、篮球、自行车赛车、赛车、格斗、曲棍球、足球、乒乓球、网球。
手工策划的图像,用于删除菜单/过渡框架,仅包含游戏序列。
游戏分为三个视觉风格类别:复古(街机风格,1990 年代及更早)现代(大约 2000 年代)PHOTOREAL(大约 2010 年代末)。

三、Stream-51
用于流分类的新数据集,由来自 51 个不同对象类别的时间相关图像和训练分布之外的其他评估类组成,用于测试新颖性识别。
四、ASIRRA ((Animal Species Image Recognition for Restricting Access)
Web 服务通常受到一些挑战的保护,这些挑战对于人们来说很容易解决,但对于计算机来说却很困难。 这种挑战通常被称为 CAPTCHA(区分计算机和人类的完全自动化公共图灵测试)或 HIP(人类交互证明)。 HIP 有多种用途,例如减少电子邮件和博客垃圾邮件以及防止对网站密码的暴力攻击。
Asirra(限制访问的动物物种图像识别)是一种 HIP,其工作原理是要求用户识别猫和狗的照片。 这项任务对于计算机来说是困难的,但研究表明人们可以快速准确地完成它。 许多人甚至认为这很有趣! 这是 Asirra 界面的示例:
Asirra 的独特之处在于它与 Petfinder.com 的合作,Petfinder.com 是世界上最大的致力于为无家可归的宠物寻找家园的网站。 他们向微软研究院提供了超过三百万张猫和狗的图像,这些图像是由美国各地数千个动物收容所的人们手动分类的。 Kaggle 很幸运地提供了这些数据的一个子集,以供娱乐和研究之用。
五、AdvNet
AdvNet 是交通标志图像的数据集。 具体来说,它包括对抗性交通标志图像(即表面带有贴纸的交通标志图片),可以欺骗最先进的基于神经网络的感知系统,以及干净的没有任何贴纸的交通标志图像。
如果您使用 AdvNet,请引用以下论文:
Y. Kantaros、T. Carpenter、K. Sridhar、I. Lee、J. Weimer:“感知系统对抗性数字和物理输入的实时检测器”,第 12 届 ACM/IEEE 国际网络物理系统会议 (ICCPS) , 2021

六、BCNB (Early Breast Cancer Core-Needle Biopsy WSI)
乳腺癌(BC)已成为全球女性健康的最大威胁。 临床上,识别腋窝淋巴结(ALN)转移以及ER、PR等其他肿瘤临床特征,对于评估BC患者的预后和指导治疗具有重要意义。
几项研究旨在通过临床病理数据和基因检测评分来预测 ALN 状态和其他肿瘤临床特征。 然而,由于预测价值相对较差且基因检测成本较高,这些方法往往受到限制。 近年来,深度学习(DL)使得计算病理学快速发展,DL可以对医学图像进行高通量特征提取并分析原发肿瘤特征与上述状态之间的相关性。 迄今为止,还没有根据原发性BC样本的WSI来术前预测ALN转移和其他肿瘤临床特征的相关研究。
我们的论文介绍了早期乳腺癌核心针活检 WSI (BCNB) 的新数据集,其中包括早期乳腺癌患者的核心针活检全切片图像 (WSI) 和相应的临床数据。 WSI 已由两名独立且经验丰富的病理学家进行了检查和注释,他们对所有患者相关信息不知情。
基于该数据集,我们研究了使用多实例学习(MIL)术前预测 ALN 转移状态的深度学习算法,并在独立测试队列中取得了最佳 AUC 0.831。 欲了解更多详细信息,请查看我们的论文。
有1058名患者的WSI,并且WSI中仅注释了部分肿瘤区域。 除WSI外,我们还提供了每位患者的临床特征,包括年龄、肿瘤大小、肿瘤类型、ER、PR、HER2、HER2表达、组织学分级、手术、Ki67、分子亚型、淋巴结转移数量 ,以及腋窝淋巴结(ALN)的转移状态。 数据集经过脱敏处理,不包含患者隐私信息。
基于该数据集,我们在论文中研究了腋窝淋巴结(ALN)转移状态的预测,这是一项弱监督分类任务。 然而,基于我们的数据集的其他研究也是可行的,例如组织学分级、分子亚型、HER2、ER和PR的预测。 我们不限制您研究的具体内容,欢迎任何基于我们数据集的研究。
请注意,该数据集仅用于教育和研究,不允许用于商业和临床应用。 该数据集的使用必须遵循许可协议。

七、Deep PCB (Deep Printed Circuit Board)
深PCB
数据集链接:
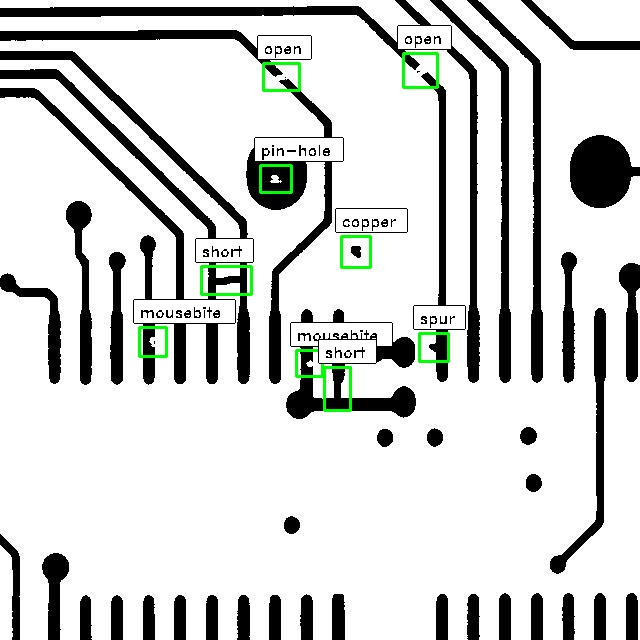
数据集包含 1,500 个图像对,每个图像对均由无缺陷模板图像和对齐的测试图像组成,并带有注释,其中包括 6 种最常见 PCB 缺陷类型的位置:开路、短路、鼠咬、支线、针孔和杂铜 。
数据集描述
图片集
该数据集中的所有图像均从线性扫描 CCD 获得,分辨率约为每 1 毫米 48 像素。
以上述方式从采样图像中手动检查并清除无缺陷的模板图像。
模板和测试图像的原始尺寸约为 16k x 16k 像素。
然后将它们裁剪成许多尺寸为 640 x 640 的子图像,并通过模板匹配技术进行对齐。
接下来,仔细选择阈值以采用二值化以避免照明干扰。
请注意,预处理算法可以根据具体的 PCB 缺陷检测算法而有所不同,但是,图像配准和阈值技术是高精度 PCB 缺陷定位和分类的常见过程。
下图展示了 DeepPCB 数据集中的一对示例,其中右侧是无缺陷模板图像,左侧是带有真实注释的缺陷测试图像。
图像标注
我们对测试图像中的每个缺陷使用带有类 ID 的轴对齐边界框。 如上图所示,我们标注了六种常见的 PCB 缺陷类型:开路、短路、鼠咬、毛刺、针孔和杂铜。 由于真实测试图像中只有少数缺陷,我们根据PCB缺陷模式在每个测试图像上手动争论一些人为缺陷,这导致每个640 x 640图像中大约有3到12个缺陷。 PCB缺陷数量如下图所示。 我们分离出 1,000 张图像作为训练集,剩下的作为测试集。 每张标注图像都有一个同名的标注文件,例如00041000_test.jpg、00041000_temp.jpg、00041000.txt分别是测试图像、模板图像和对应的标注文件。 测试图像上的每个缺陷都注释为格式:x1,y1,x2,y2,类型,其中(x1,y1)和(x2,y2)是缺陷边界框的左上角和右下角 。 type 是一个整数 ID,紧随以下匹配项:0-背景(未使用)、1-开路、2-短路、3-鼠咬、4-马刺、5-铜、6-针孔。
现在,注释工具的源代码位于 ./tools 目录中。
基准测试
使用平均准确率和F-score进行评估。 仅当检测到的边界框与任何具有相同类别的地面实况框之间的单位交集(IoU)大于 0.33 时,检测才是正确的。 F-score的计算公式为:F-score=2PR/(P+R),其中P和R是精确率和召回率。 请注意,F 分数是阈值敏感的,这意味着您可以调整分数阈值以获得更好的结果。 虽然F-score不像mAP标准那么公平,但更实用,因为在部署模型时总是应该给出一个阈值,并且并非所有算法都有对目标的分数评估。 因此,F-score 和 mAP 都在基准测试中得到考虑。
mAP和F-score的评估脚本借鉴了Icdar2015的评估脚本,稍加修改(可以先注册一个账号)。 在这里,我们在evaluation/目录中给出了修改后的评估脚本和测试集的groundtruth gt.zip文件。 您可以按照以下说明评估您自己的方法: * 运行您的算法并将每个图像的检测结果保存为 image_name.txt,其中 image_name 应与 gt.zip 中的相同。 您应该遵循评估/gt.zip 的格式,除了算法中每个缺陷的输出描述应为:x1,y1,x2,y2,置信度,类型,其中 (x1,y1) 和 (x2,y2) 是 缺陷边界框的左上角和右下角。 置信度是一个浮点数,表示您对此类检测结果的置信度。 type 是一个字符串,应该是以下之一:open、short、mousebite、spur、copper、pin-hole。 请注意,除了逗号之外没有空格。 * 将 .txt 文件压缩为 res.zip。 (res.zip 文件中不应包含任何子目录) * 运行评估脚本: python script.py -s=res.zip -g=gt.zip
方法
这部分的源代码将在论文接受后公开。
实验结果
在这里,我们展示了基于深度神经网络的模型的一些结果。 我们的模型在 62FPS 下实现了 98.6% mAp、98.2% F 分数。 更多统计分析将在论文被接受后公开。 绿色边界框是 PCB 缺陷的预测位置,每个边界框的顶部都有置信度。
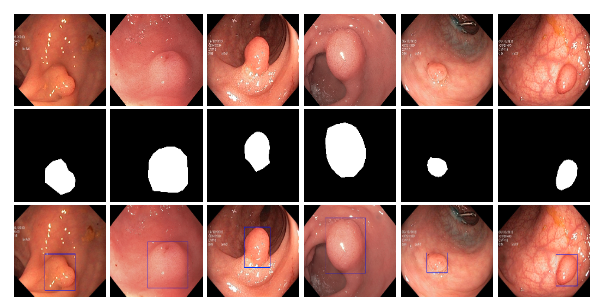
八、Endotect Polyp Segmentation Challenge Dataset
该挑战由三项任务组成,每项任务针对临床使用的不同要求。 第一项任务是将胃肠道图像分为 23 个不同的类别。 第二个任务侧重于通过处理每个图像所花费的时间来衡量的有效分类。 最后一个任务涉及自动分割息肉。
如果您使用该数据集,请引用“EndoTect 2020 挑战:内窥镜分类、分割和推理时间的评估和比较”。
九、FMD (materials) (Flickr Material Dataset)
沙兰、拉瓦尼娅、露丝·罗森霍尔茨和爱德华·阿德尔森。 《物质知觉:一眼就能看到什么?》 视觉杂志 9.8 (2009): 784-784。
http://people.csail.mit.edu/celiu/CVPR2010/FMD/FMD.zip
十、Image and Video Advertisements
图像和视频广告集合由包含 64,832 个图像广告的图像数据集和包含 3,477 个广告的视频数据集组成。 数据包含丰富的注释,涵盖广告的主题和情绪、描述提示观看者采取哪些行动的问题和答案以及广告为说服观看者而呈现的推理(“根据这则广告我应该做什么,为什么 我应该这样做吗?”),以及广告中的象征性参考(例如,鸽子象征着和平)。