文章目录
一、ACL-Fig
ACL-Fig 是一个大型自动注释语料库,由从 ACL Anthology 中的 56K 研究论文中提取的 112,052 个科学图形组成。 ACL-Fig-pilot 数据集包含 1,671 个手动标记的科学图形,属于 19 个类别。
二、ARC-100
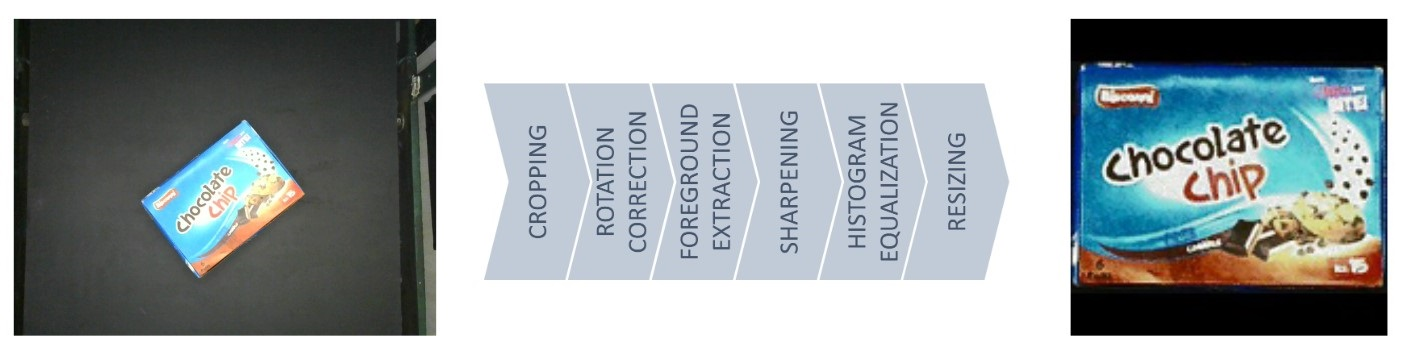
ARC-100 数据集是作为名为 ARC(自动零售结账)的原型零售结账系统的一部分收集的。 它由 31,000巴基斯坦拉合尔 100 种常见零售商品的 RGB 图像。 每个零售商品都有 310 张图像,由 Logitech C310 网络摄像头以不同的逻辑方向(在黑色哑光传送带上)捕获,在由 LED 灯带照明的木质罩框架下(亮度设置为大约)。 在所提出的设置中,图像在输入卷积神经网络进行识别之前经过预处理和标准化。
三、Animals-10
它包含约 28K 个中等质量的动物图像,属于 10 个类别:狗、猫、马、spyder、蝴蝶、鸡、羊、牛、松鼠和大象。
所有图像均来自“谷歌图像”,并经过人工检查。 有一些错误的数据来模拟真实条件(例如,您的应用程序的用户拍摄的图像)。 主目录分为多个文件夹,每个类别一个。 每个类别的图像数量从 2K 到 5K 单位不等。
四、ArtDL
ArtDL 是一个新颖的绘画数据集,用于图像分类,由从在线资源收集的图像组成。 大多数画作来自文艺复兴时期,描绘基督教艺术的场景或人物。 该数据集用表示属于 Iconclass 分类系统的特定字符的类进行注释。
五、BankNote-Net
世界各地有数百万人视力低下或没有视力。 辅助软件应用程序已开发用于各种日常任务,包括货币识别。 为了帮助完成这项任务,我们提出了 BankNote-Net,这是一个用于辅助货币识别的开放数据集。 该数据集包含在各种辅助场景中捕获的总共 24,816 个钞票图像嵌入,涵盖 17 种货币和 112 种面额。 这些合规嵌入是使用监督对比学习和 MobileNetV2 架构学习的,它们可用于训练和测试任何货币的专用下游模型,包括我们的数据集未涵盖的货币或每个面额只有几个真实图像可用的货币( 少样本学习)。 我们在 Microsoft 开发的 Seeing AI 应用程序的最新版本中部署了该模型的变体供公众使用,该应用程序每月有超过 10 万活跃用户。
六、Cervix93 Cytology Dataset
该数据集有 93 个图像堆栈及其相应的扩展景深 (EDF) 图像,这些图像是从具有阴性、LSIL 或 HSIL(Bethesda 系统)等级的案例中获取的: - 阴性:16 - LSIL:46 - HSIL:31 基本事实包括 每个帧的等级标签以及每个帧中宫颈细胞内的手动标记点。 所有帧内总共有 2705 个手动标记点: - Negative:238 - LSIL:1536 - HSIL:931
七、Cross-View Time Dataset (Cross-Camera Split)
交叉视图时间数据集的标准评估协议允许在训练集和测试集之间共享某些相机。 该协议可以模拟我们需要验证来自一组特定设备和位置的图像的真实性的场景。 考虑到当今监控系统 (CCTV) 的普遍存在,这是一种常见的情况,特别是对于大城市和高知名度事件(例如抗议、音乐会、恐怖袭击、体育赛事)。 在这种情况下,我们可以利用该设备历史照片的可用性,并收集前几天、前几个月和前几年的其他图像。 这将使模型能够更好地捕捉时间如何影响特定地点的外观的特殊性,可能会带来更好的验证准确性。 然而,在某些情况下,数据可能来自异构来源,例如社交媒体。 从这个意义上说,模型必须在相机不相交的集合上进行优化,以避免学习传感器特定的特征,这些特征在推理过程中可能无法相应地推广到新图像。
考虑到这一点,我们提出了一种新的 CVT 数据集组织方式。 我们将可用数据分为训练集和测试集,确保来自单个相机的所有图像都分配给同一组。 在此划分过程中,我们的目标是保持每个集合的大小与原始划分大致相似,从而允许使用相似数量的数据来优化模型。
八、DF20 - Mini (Danish Fungi 2020 - Mini)
丹麦真菌 2020 (DF20) 是一个新颖的细粒度数据集和基准。 该数据集是根据提交给丹麦真菌图集的观察结果构建的,其独特之处在于分类准确的类标签、少量错误、高度不平衡的长尾类分布、丰富的观察元数据和明确定义的类层次结构。 DF20 与 ImageNet 零重叠,允许对从公开可用的 ImageNet 检查点微调的模型进行无偏差比较。

九、DIB-10K (DongNiao International Birds 10000)
是一个具有挑战性的图像数据集,其中包含 10,000 多种不同类型的鸟类。 它的创建是为了促进机器学习和鸟类学研究。
十、Dirty-MNIST
DirtyMNIST 是 MNIST + AmbigouslyMNIST 的串联,训练集中每个样本有 60k 个样本。 AmbigeousMNIST 包含具有不同歧义度的附加歧义数字。 AmbigitudeMNIST 测试集还包含 60k 个模糊样本。
额外指导
DirtyMNIST 是 MNIST + AmbigouslyMNIST 的串联,训练集中每个样本有 60k 个样本。
当前的 AmbigouslyMNIST 包含 6k 个独特的样本,每个样本有 10 个标签。 这个多标签数据集被扁平化为 60k 样本。 假设不明确的样本具有多个“有效”标签,因为它们是不明确的。 MNIST 样本被故意欠采样(相比之下),这有利于 AL 采集函数可以选择明确的样本。
从 DirtyMNIST 的 MNIST 一半中选择初始训练样本(用于热启动主动学习),以避免使用可能非常模糊的样本开始训练,这可能会给您的实验增加很多方差。
出于与上述相同的原因,请确保也从 MNIST 一半中选择验证集。
鉴于 Ambigitude-MNIST 中每个样本有 10 个多标签,请确保您的批量采集大小 >= 10(可能)。
默认情况下,stddev 0.05 的高斯噪声被添加到每个样本中,以防止采集函数(在主动学习中)通过丢弃“重复项”而作弊。
如果要将 Ambigitude-MNIST 拆分为子集(或将 Dirty-MNIST 拆分为第二个模糊部分中的子集),请确保拆分为 10 的倍数,以避免在扁平多标签样本中拆分。

十一、FathomNet2023 (FathomNet2023 Competition Dataset)
FathomNet2023 竞赛数据集是更广泛的 FathomNet 海洋图像存储库的子集。 比赛的训练和测试图像均由蒙特利湾水族馆研究所在蒙特利湾地区水面至1300米深度之间采集。 这些图像包含 290 类底栖动物的边界框注释。 训练和验证数据按 800 米深度阈值划分:所有训练数据均从 0-800 米收集,评估数据来自整个 0-1300 米范围。 由于生物体的栖息地范围部分是深度的函数,因此两个区域的物种分布重叠但不相同。 测试图像是从同一区域绘制的,但可能来自深度水平线上方或下方。 竞赛目标是对给定图像中存在的动物进行标记(即多标签分类)并确定图像是否样本外。