文章目录
一、BDD100K
数据集推动视觉进步,但现有的驾驶数据集在视觉内容和支持的任务方面缺乏,无法研究自动驾驶的多任务学习。 研究人员通常只能研究一个数据集上的一小部分问题,而现实世界的计算机视觉应用程序需要执行各种复杂的任务。 我们构建了 BDD100K,这是最大的驾驶视频数据集,包含 100K 视频和 10 个任务,以评估自动驾驶图像识别算法的令人兴奋的进展。 该数据集具有地理、环境和天气多样性,这对于训练不太可能对新条件感到惊讶的模型很有用。 基于这个多样化的数据集,我们构建了异构多任务学习的基准,并研究如何共同解决任务。 我们的实验表明,现有模型需要特殊的训练策略来执行此类异构任务。 BDD100K 为未来在这个重要场所的研究打开了大门。 更多详细信息请参见数据集主页。

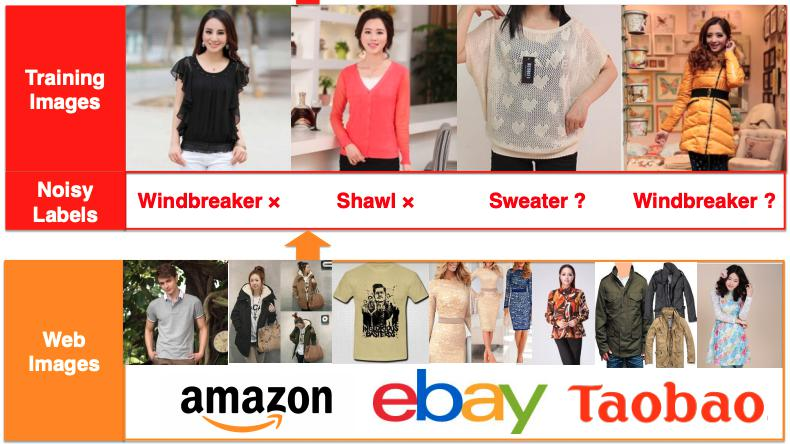
二、Clothing1M
Clothing1M 包含 100 万张服装图像,分为 14 个类别。 这是一个带有噪声标签的数据集,因为数据是从多个在线购物网站收集的,并且包含许多错误标记的样本。 该数据集还包含 50k、14k 和 10k 图像,分别具有用于训练、验证和测试的干净标签。
三、EMNIST (Extended MNIST)
EMNIST(扩展MNIST)的数据量是MNIST的4倍。 它是一组 28 x 28 格式的手写数字。

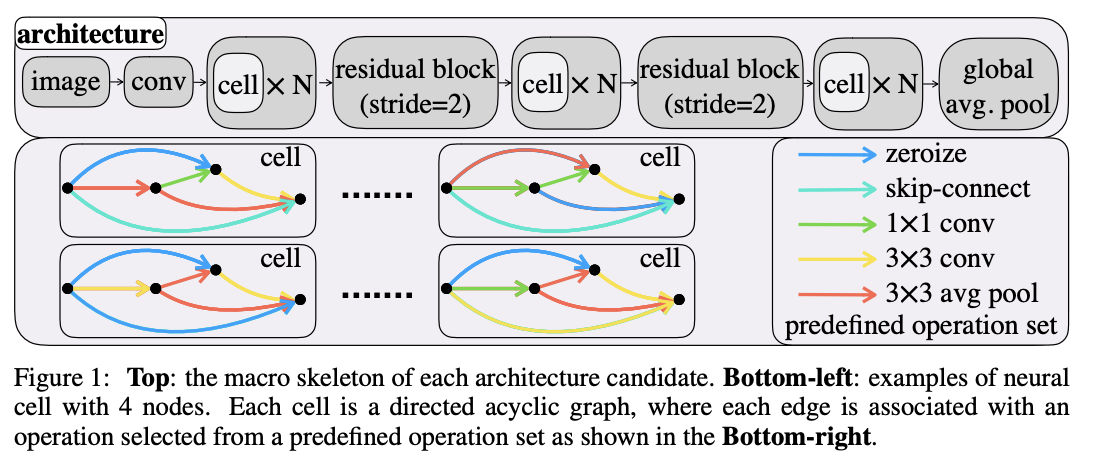
四、NAS-Bench-201
NAS-Bench-201 是神经架构搜索的基准(和搜索空间)。 每个架构都由一个预定义的骨架和一堆搜索单元组成。 这样,架构搜索就转化为搜索好单元格的问题。
五、YFCC100M
YFCC100M 是一个数据集,总共包含 1 亿个媒体对象,其中约 9920 万个照片和 80 万个视频,所有这些都带有知识共享许可证。 数据集中的每个媒体对象都由多个元数据表示,例如 Flickr 标识符、所有者姓名、相机、标题、标签、地理位置、媒体源。 该合集提供了从 2004 年 Flickr 成立到 2014 年初这些年来照片和视频的拍摄、描述和共享方式的全面快照。

六、Extended Yale B
Extended Yale B 数据库包含 38 个受试者的 2414 张尺寸为 192×168 的正面图像,每个受试者大约有 64 张图像。 这些图像是在不同的照明条件和不同的面部表情下拍摄的。

七、HumanEval
这是论文“评估在代码上训练的大型语言模型”中描述的 HumanEval 问题解决数据集的评估工具。 它用于测量从文档字符串合成程序的功能正确性。 它由 164 个原创编程问题组成,评估语言理解、算法和简单数学,其中一些问题相当于简单的软件面试问题。

八、LabelMe
LabelMe 数据库是一个带有用于对象检测和识别的地面真实标签的图像的大型集合。 注释来自两个不同的来源,包括 LabelMe 在线注释工具。

九、Stanford Online Products
斯坦福在线产品 (SOP) 数据集包含 22,634 个类别和 120,053 张产品图像。 前 11,318 个类别(59,551 张图像)被分割用于训练,其他 11,316 个类别(60,502 张图像)用于测试。

十、WebVision
WebVision 数据集旨在促进从嘈杂的网络数据中学习视觉表示的研究。 它是一个大规模网络图像数据集,包含从 Flickr 网站和 Google 图片搜索爬取的超过 240 万张图像。
与 ILSVRC 2012 数据集相同的 1,000 个概念用于查询图像,这样可以直接研究一堆现有方法并与从 ILSVRC 2012 数据集训练的模型进行比较,并且还可以研究 大规模场景。 伴随这些图像的文本信息(例如标题、用户标签或描述)也作为附加元信息提供。 提供包含 50,000 张图像(每个类别 50 张图像)的验证集以促进算法开发。

十一、ImageNet-Sketch
ImageNet-Sketch 数据集由 50000 张图像组成,1000 个 ImageNet 类别中每个类别有 50 张图像。 该数据集是通过 Google Image 查询“sketch of”构建的,其中 是标准类名。 仅在“黑白”配色方案内进行搜索。 最初为每个类别查询 100 张图像,并通过删除不相关的图像和相似但不同类别的图像来清理拉取的图像。 对于某些类,手动清理后图像数量不足 50 张,然后通过翻转和旋转图像来扩充数据集。

十二、Oxford5k (Oxford Buildings)
Oxford5K 是牛津建筑数据集,包含从 Flickr 收集的 5062 张图像。 它为 11 个地标建筑提供了一组 55 个查询,每个地标建筑有 5 个查询。

十三、CINIC-10
CINIC-10 是图像分类的数据集。 它总共有27万张图像,是CIFAR-10的4.5倍。 它由两个不同的来源构建:ImageNet 和 CIFAR-10。 具体来说,它被编译为 CIFAR-10 和 ImageNet 之间的桥梁。 它分为三个相等的子集 - 训练、验证和测试 - 每个子集包含 90,000 张图像。

十四、PASCAL VOC 2007
PASCAL VOC 2007 是用于图像识别的数据集。 已选择的二十个对象类别是:
人:人动物:鸟、猫、牛、狗、马、羊车辆:飞机、自行车、船、公共汽车、汽车、摩托车、火车室内:瓶子、椅子、餐桌、盆栽、沙发、电视/显示器
该数据集可用于图像分类和对象检测任务。
