文章侧重点
这篇文章关注到了目标追踪的Tracker训练部分。 文中并未针对Tracker的组成部分改进,而是将重点放到Tracker的训练的问题。文中指出,现如今的Tracker通常是针对帧(frame-level),用每一帧中的groundtruth训练Tracker,而测试阶段是对Tracker在一个序列上测试评估(sequence-level),所以带来的问题就是训练的目标损失是保证每一帧定位精度,而测试侧重在一个序列上保持定位精确度。所以本文参考了图像字幕里 SCST(Self-Critical Sequence Training) 方法设计 基于强化学习(RL)框架的同样sequence-level的训练方法。
Sequence-Level Training(SLT)
SLT pipeline图示
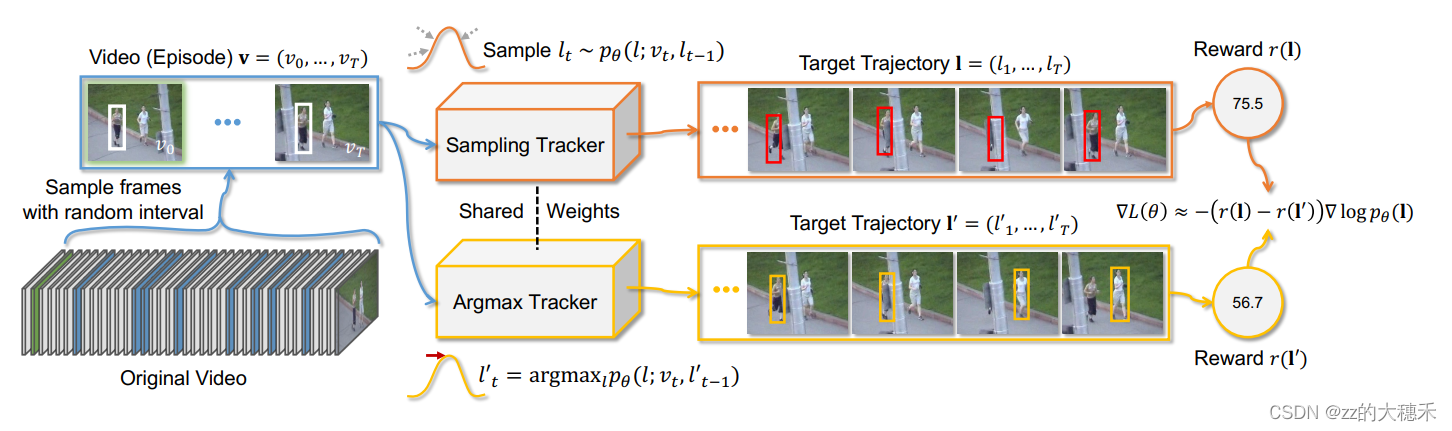
- 输入: 一个训练序列(Original Video)。
- 第一步:数据增强。 对于给出Original Video以随机间隔取一些帧出来,视为含 T + 1 T+1 T+1帧的一次训练事件(Episode),分别输入到共享参数的Sampling tracker和Argmax Tracker中。
- 第二步: 指定一个以上一个目标位置为中心服从的概率分布 p θ p_\theta pθ, l t − 1 l_{t-1} lt−1表示第 t − 1 t-1 t−1帧的预测结果, v t v_t vt表示第 t t t帧,Sampling tracker 随机取一个可能的目标边界框,而Argmax Tracker选择置信度最高的一个边界框。 r ( l ) r(l) r(l)表示对该帧的预测边界框的评估结果。
- 输出: 图中可以看出Reward r ( l ) r(l) r(l)是对这个训练事件(Episode)中Sampling tracker 预测边界框与GroundTruth的评估分数【平均IOU】——75.5;Reward r ( l ′ ) r(l^{')} r(l′)是对这个训练事件(Episode)中Argmax Tracker 预测边界框与GroundTruth的评估分数——56.7。
这里的框架让我想起,这就像目标追踪的某些Tracker会有一些后置操作——窗口惩罚、余弦窗口,就是因为在一帧中目标的移动不会很大,所以一般认为如果预测边界框比上一帧偏移太多,就认为识别错了,可能跳到另一个相似的目标上了,然后就对这种移动过大的目标给予小权重,使得最后这种边界框得分低。
这里的Sampling Tracker本身的操作也是在上一帧的目标位置附近随机采样一个边界框作为预测目标结果,虽然说随机,但是采样是服从概率函数的。所以Argmax Tracker 就是凭特征找到置信度最高的边界框,然后Sampling tracker限制框偏移。
这里很明显训练的参数是这个概率函数的参数。
SLT 伪代码

这个伪代码对应的就是上图pipeline的流程。其中 L L L就是训练概率函数的损失函数。
SLT+TransT
TransT的论文解读如下:单目标追踪——【Transformer】Transformer Tracking
SLT融合到现有Tracker时,只需要改变该Tracker的训练损失函数,加上SLT的损失函数即可。训练过程中,文中采用与TransT论文中相同训练集训练,即用LaSOT, TrackingNet, GOT-10k, and COCO预训练TransT,再用LaSOT, TrackingNet, GOT-10k 微调SLT-TransT。