词嵌入
类比推理

是否一个算法能够知道man->woman,King->queen?
1.将两者的embedding encoding相减时得到:

2.即找到一个ew,to make sim(ew,eking-eman+ewoman)=》1或接近1.
即:
这个式子称为余弦相似。
(如果u,t相似时,u,t的内积将会最大,即sim=1,而cos在角为0度时为1,90度时为0.)
在类比类时用余弦相似更常见。
3.最终实现效果类似于下图:

算法
一.预测词的算法
1.传统的基础算法
如何预测下一个词语?
例如:如果是一个10k词的300维矩阵E,推辞orange之后的词:

将它们的embedding放入隐藏层训练后,最后进入10k的softmax层。谁的概率更高,则更可能是谁。(softmax最大值对应的词)softmax的输出时10k维。
如果一个句子的长度太长,可以选择固定的窗口,使得这个词的前后固定词语数量作为它的上下文来推测。如下推断juice:

2.word2vec的skip-grams
随机选择一个词语作为上下文。例如:

选择orange之后预测词。softmax的计算公式如下:

上述所有算法的问题都是显而易见的,由于softmax的维度高,计算速度慢
解决方法:
- softmax的多分类器。更常见的词语会在树的更顶端,从而减少检索时间。
- context上下文的内容如何更好的选择。
3.负采样
构造一个新的监督学习问题:
在字典中随机选择一些词作为负样本,正样本记为1,负样本记为0:

如何选择负样本的数量k?
- 若数据集很大,k 5-20个
- 相反,k 2-5个
此时,1000维的sotfmax变成了k+1个logistic二分类问题。大大加快了计算速度。
如何选择负样本?
- 对于词出现的频率
- 均匀分布
- 如下图:

4.glove词向量
选择一个词语i在预测词语j出现的频率为xij。
即:glove的具体步骤如下:
- 构建词语共现矩阵:首先,需要对大量的文本语料进行预处理,包括分词、去除停用词和标点符号等。然后,通过遍历文本语料,统计每个词语与其他词语共同出现的次数。这个过程会生成一个称为词语共现矩阵的矩阵,其中每个元素表示两个词语在同一上下文中出现的次数。
- 计算词语之间的共现概率。
- 构建词向量:为每个词语随机初始化一个向量表示,使用最小化损失函数的优化算法(如梯度下降),更新词向量,使得词向量之间的差异与共现概率的对数之间的差异最小化。通过迭代优化过程,逐渐调整词向量,使得它们能够更好地反映词语之间的语义关系。
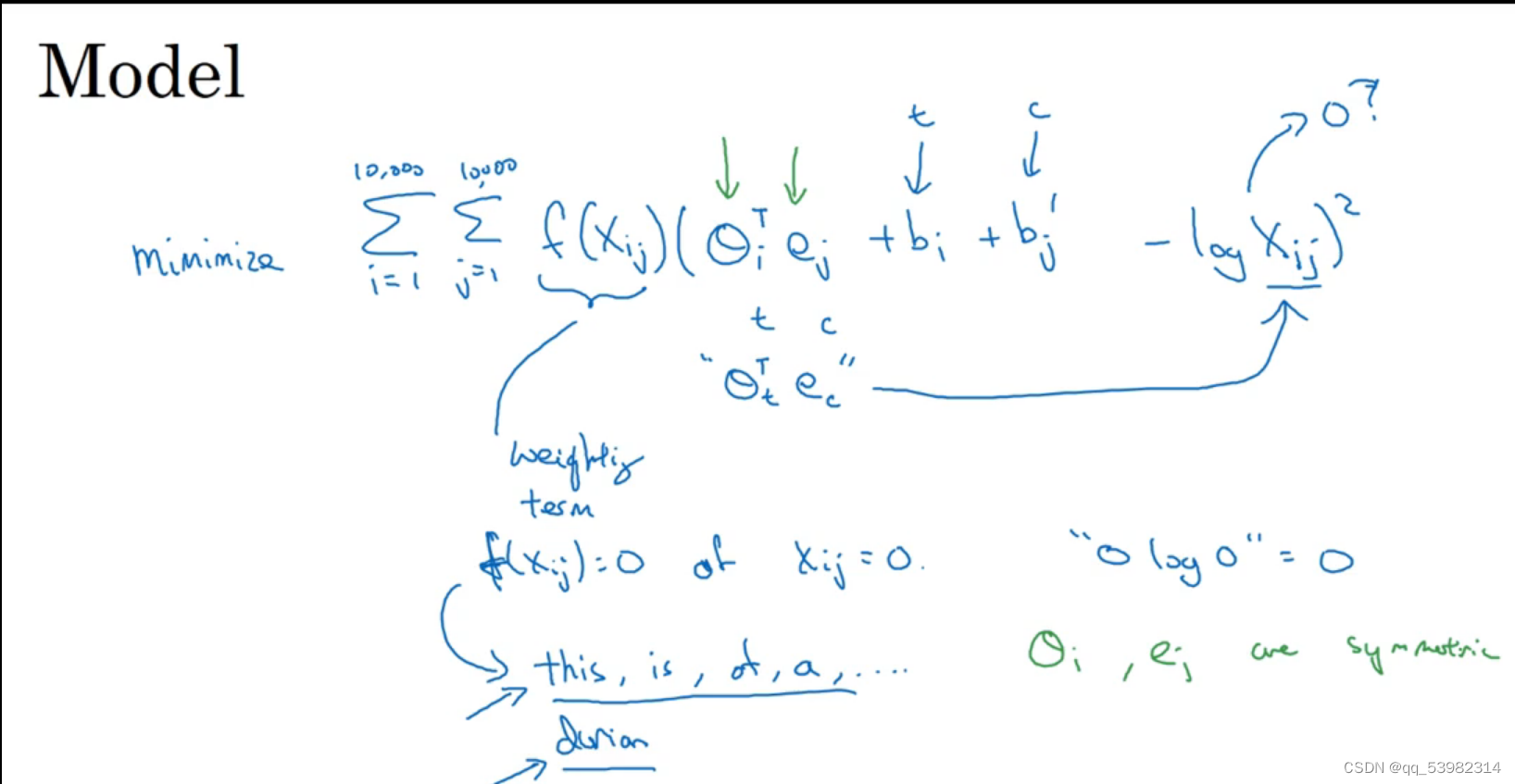
f为权重,当出现this is of a an等词时给较小的权重值;当xij=0时,f为0.
二.情绪分析问题
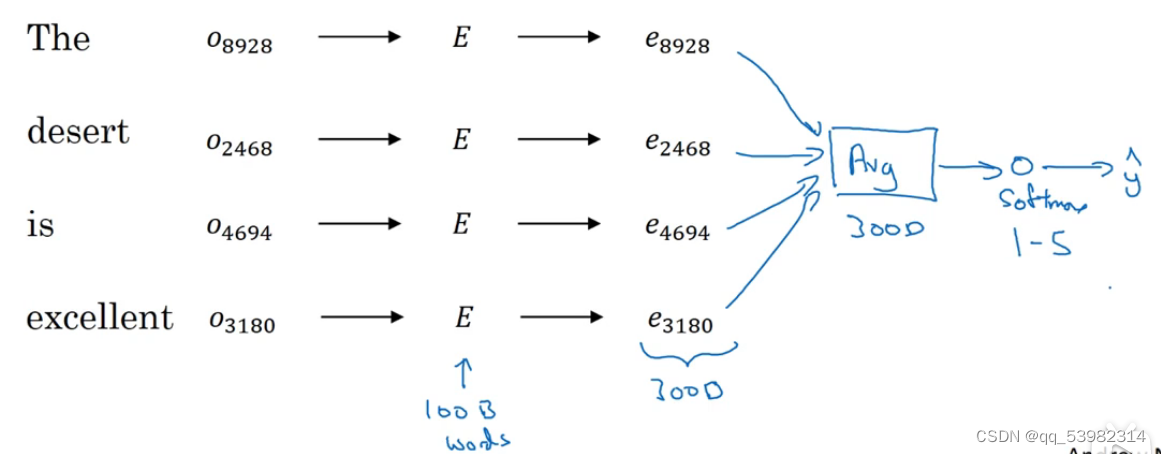
得到评论x与情绪y之间映射。softmax此时为5维。average为计算4个300维度的词向量的相加后平均值,依旧是300维。softmax最大值为y。
问题:在出现there is no good ,lack in good 这类负面语句时,可能会分析出来是高分的正面,需要进一步更精确的检验
1.RNN做情感分析
为了解决上述问题:
RNN如下图:
能够将上一词作为当前词语的输入。
三.debiasing word embedding-词嵌入取消偏见
word embedding的执行可能会使得训练出来的模型有bias。like:

如何消除这种bias?
1.例子
- 辨别要减少的bias:使用特定的测试集来识别包含偏见的词语对,并通过重新调整向量来减少它们之间的偏见。
- 中和:一种方法是使用特定的偏见词语对进行校准,通过计算偏见词语对的差异来重新调整词嵌入向量。一旦识别到偏见,就需要确定修正策略。这可能包括调整词嵌入向量的值、增加新的词语对或样本来平衡偏见,或者使用其他技术来调整词嵌入的表示。修正词嵌入后,需要对其进行评估和验证,以确保修正策略的有效性。
- 均衡:通过在训练过程中对不同群体的样本进行加权,来增加多样性并减少偏见。