Word Vector
词向量模型可表示为含有一层隐藏层的前向神经网络,词向量为输入层到隐藏层的参数,即参数矩阵的行向量.
- 语料库总词数为|V|
- embedding后的单词维度为n
- 输入层为n维向量
- 输入层到隐藏层参数矩阵
- 隐藏层到输出层参数矩阵 ,输出经过softmax归一化为概率分布

模型具有两种变体:skip-grams (sg)和continuous bag of words(cbow).
Skip-grams model with negative sampling
skip-grams是基于中心词预测上下文,示意图如下:
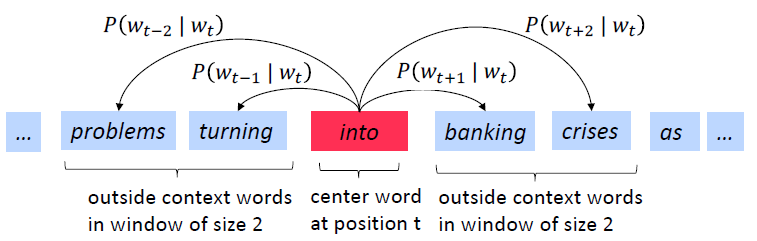
输出层的维度等于语料库单词总数,使用naive softmax计算简单,但是计算代价太高.
给定词 ,上下文 ,随机采样K个词构成词集 ,其中 ,可将 和 分别视为 的正、负样本, 个负采样仅构成 个logisti回归,从而退化softmax.
我们希望中心词与真实上下文单词向量的內积更大,与
次随机采样词的內积更小,对于单个窗口的负采样似然函数可表示为:
式中 和 分别为上下文单词和负采样单词的onehot向量, 为中心词在输出层向量表示.
负样本词被采样的概率与其在语料库中的频率正相关,为相对减少常见词被采样频率。增加稀有词被采样概率,可将语料库生成的unigram分布,通过3/4次方,w被采样的概率为
上式中Z为归一化因子,用于生成概率分布.
Continuous Bag of Words
CBOW: Predict center word from (bag of) context words.
假设n_gram总数为 (窗口数/训练样本数), 为窗口 中心词的onehot向量,输入层向量 为所有邻近词onehot向量, 为窗口 中心词的概率分布.
模型目标函数为
由于
较大(中文词约几十万),而且大语料集下
也非常大,模型的复杂度较大,通常是采用Negtive Sample或Hierarchical Softmax求近似解.
Document Vector
与word2vec类似,doc2vec也可采用两种训练方式:pv-dm类似于cbow(如下图),pv-dbow类似于skip-ngram.
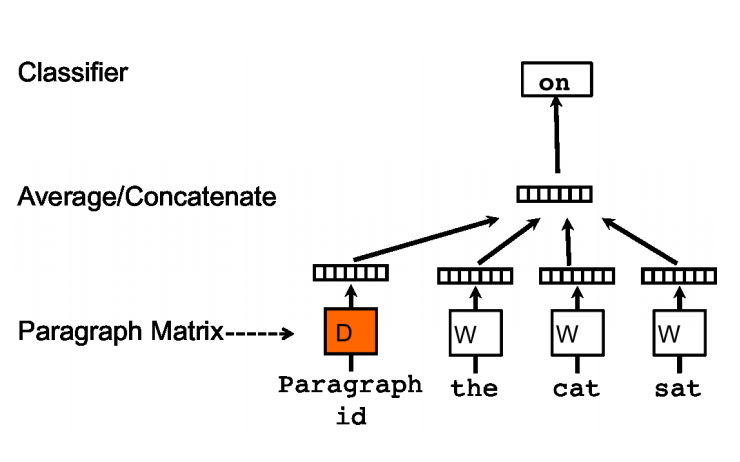
滑动窗口从句中采样固定长度的词,将其中一个词向量作为预测,其他词向量和句向量作为输入(累加平均).
同一句在不同滑动窗口训练时共享句向量.