图(Graph / Network)数据类型可以自然地表达物体和物体之间的联系,在我们的日常生活与工作中无处不在。例如:微信和新浪微博等构成了人与人之间的社交网络;互联网上成千上万个页面构成了网页链接网络;国家城市间的运输交通构成了物流网络。
图片来源:The power of relationships in data
通常定义一个图 G=(V,E),其中 V 为顶点(Vertices)集合,E 为边(Edges)集合。对于一条边 e=u,v 包含两个端点(Endpoints) u 和 v,同时 u 可以称为 v 的邻居(Neighbor)。当所有的边为有向边时,图称之为有向(Directed)图,当所有边为无向边时,图称之为无向(Undirected)图。对于一个顶点 v,令 d(v) 表示连接的边的数量,称之为度(Degree)。对于一个图 G=(V,E),其邻接矩阵(Adjacency Matrix) A∈A|V|×|V| 定义为:

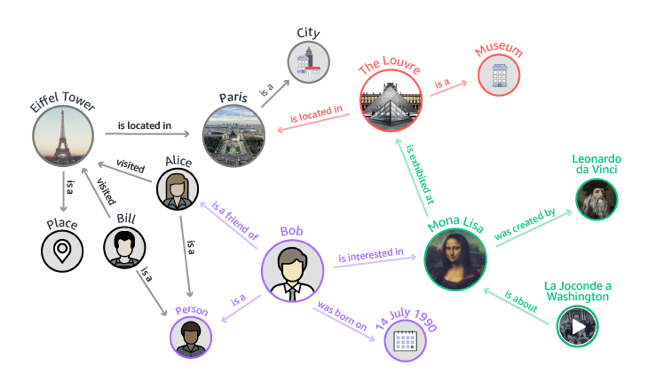
作为一个典型的非欧式数据,对于图数据的分析主要集中在节点分类,链接预测和聚类等。对于图数据而言,图嵌入(Graph / Network Embedding)和图神经网络(Graph Neural Networks, GNN)是两个类似的研究领域。图嵌入旨在将图的节点表示成一个低维向量空间,同时保留网络的拓扑结构和节点信息,以便在后续的图分析任务中可以直接使用现有的机器学习算法。一些基于深度学习的图嵌入同时也属于图神经网络,例如一些基于图自编码器和利用无监督学习的图卷积神经网络等。下图描述了图嵌入和图神经网络之间的差异:

本文中图嵌入和网络表示学习均表示 Graph / Network Embedding。
图嵌入
本节内容主要参考自:
A Comprehensive Survey of Graph Embedding: Problems, Techniques and Applications 1
Graph Embedding Techniques, Applications, and Performance: A Survey 2
Representation Learning on Graphs: Methods and Applications 3
使用邻接矩阵的网络表示存在计算效率的问题,邻接矩阵 A 使用 |V|×|V| 的存储空间表示一个图,随着节点个数的增长,这种表示所需的空间成指数增长。同时,在邻接矩阵中绝大多数是 0,数据的稀疏性使得快速有效的学习方式很难被应用。
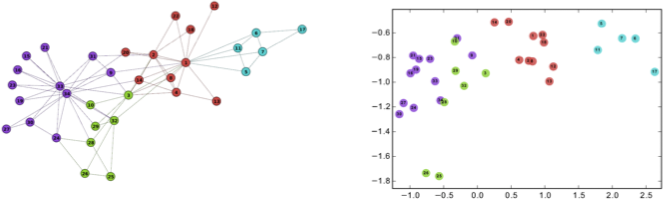
网路表示学习是指学习得到网络中节点的低维向量表示,形式化地,网络表示学习的目标是对每个节点 v∈V 学习一个实值向量 Rv∈Rk,其中 k≪|V| 表示向量的维度。经典的 Zachary’s karate club 网络的嵌入可视化如下图所示
Random Walk
基于随机游走的图嵌入通过使得图上一个短距的随机游走中共现的节点具有更相似的表示的方式来优化节点的嵌入。
DeepWalk
DeepWalk 4 算法主要包含两个部分:一个随机游走序列生成器和一个更新过程。随机游走序列生成器首先在图 G 中均匀地随机抽样一个随机游走 Wvi 的根节点 vi,接着从节点的邻居中均匀地随机抽样一个节点直到达到设定的最大长度 t。对于一个生成的以 vi 为中心左右窗口为 w 的随机游走序列 vi−w,…,vi−1,vi,vi+1,…,vi+m,DeepWalk 利用 SkipGram 算法通过最大化以 vi 为中心,左右 w 为窗口的同其他节点共现概率来优化模型:

DeepWalk 和 Word2Vec 的类比如下表所示:

node2vec
node2vec 5 通过改变随机游走序列生成的方式进一步扩展了 DeepWalk 算法。DeepWalk 选取随机游走序列中下一个节点的方式是均匀随机分布的,而 node2vec 通过引入两个参数 p 和 q,将宽度优先搜索和深度优先搜索引入了随机游走序列的生成过程。 宽度优先搜索注重邻近的节点并刻画了相对局部的一种网络表示, 宽度优先中的节点一般会出现很多次,从而降低刻画中心节点的邻居节点的方差, 深度优先搜索反映了更高层面上的节点之间的同质性。
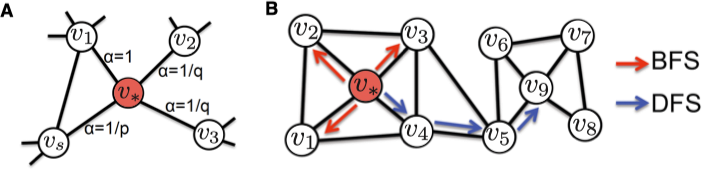
node2vec 中的两个参数 p 和 q 控制随机游走序列的跳转概率。假设上一步游走的边为 (t,v), 那么对于节点 v 的不同邻居,node2vec 根据 p 和 q 定义了不同的邻居的跳转概率,p 控制跳向上一个节点的邻居的概率,q 控制跳向上一个节点的非邻居的概率,具体的未归一的跳转概率值如下所示:
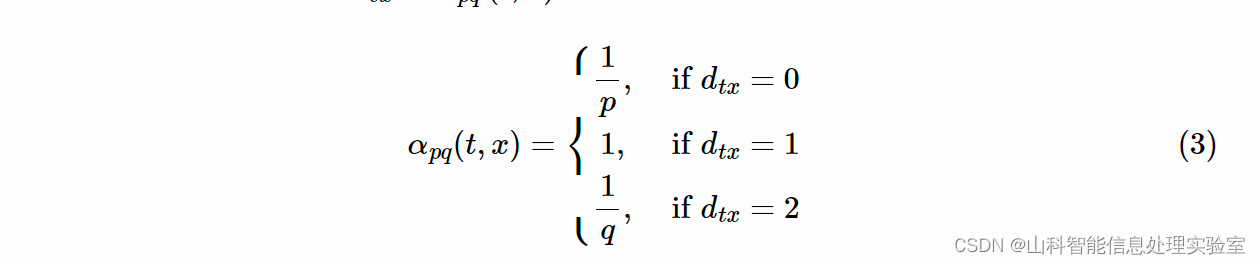
其中,表示节点 t 和 x 之间的最短距离。为了获得最优的超参数 p 和 q 的取值,node2vec 通过半监督形式,利用网格搜索最合适的参数学习节点表示。
APP
之前的基于随机游走的图嵌入方法,例如:DeepWalk,node2vec 等,都无法保留图中的非对称信息。然而非对称性在很多问题,例如:社交网络中的链路预测、电商中的推荐等,中至关重要。在有向图和无向图中,非对称性如下图所示:
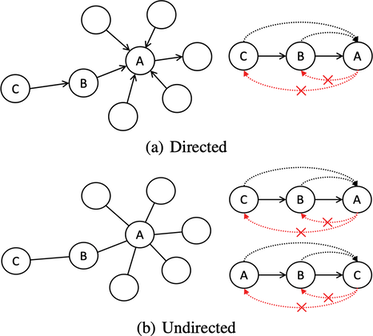
为了保留图的非对称性,对于每个节点 v 设置两个不同的角色:源和目标,分别用 sv→ 和 tv→
表示。对于每个从 u 开始以 v 结尾的采样序列,利用 (u,v) 表示采样的节点对。则利用源节点 u 预测目标节点 v 的概率如下:
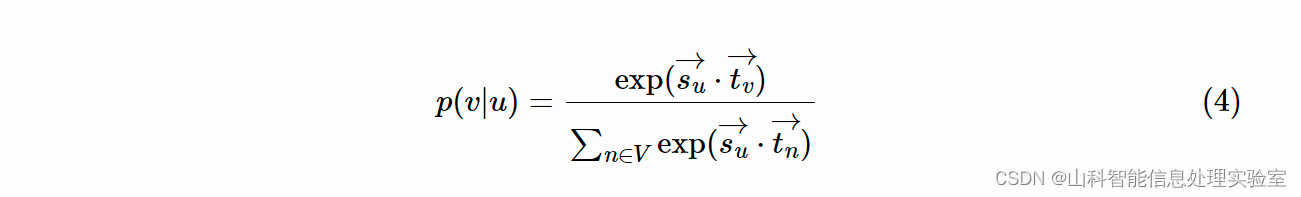
通过 Skip-Gram 和负采样对模型进行优化,损失函数如下:

其中,我们根据分布 PD(n)∼1|V| 随机负采样 k 个节点对,
为采样的 (u,v) 对的个数,σ 为 sigmoid 函数。通常情况下,#Sampledu(v)≠#Sampledv(u)
,即 (u,v) 和 (v,u) 的观测数量是不同的。模型利用 Monte-Carlo End-Point 采样方法 6 随机的以 v 为起点和 α 为停止概率采样 p 条路径。这种采样方式可以用于估计任意一个节点对之间的 Rooted PageRank 7 值,模型利用这个值估计由 v 到达 u 的概率。
Matrix Fractorization
GraRep
GraRep 8 提出了一种基于矩阵分解的图嵌入方法。对于一个图 G,利用邻接矩阵 S 定义图的度矩阵:

则一阶转移概率矩阵定义如下:

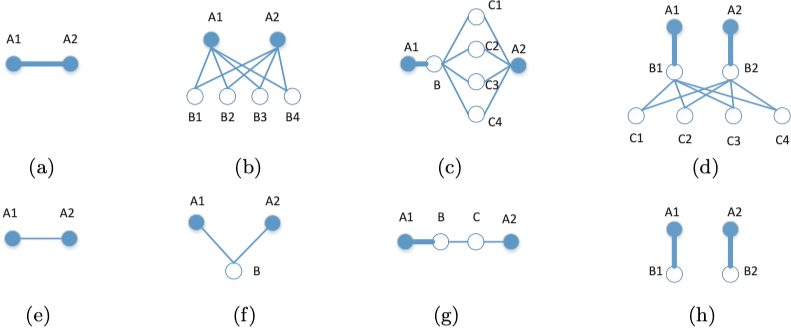
其中,Ai,j 表示通过一步由 vi 转移到 vj 的概率。所谓的全局特征包含两个部分:
- 捕获两个节点之间的长距离特征
- 分别考虑按照不同转移步数的连接
下图展示了 k=1,2,3,4 情况下的强(上)弱(下)关系:
利用 Skip-Gram 和 NCE(noise contrastive estimation)方法,对于一个 k 阶转移,可以将模型归结到一个矩阵 Yi,jk 的分解问题:
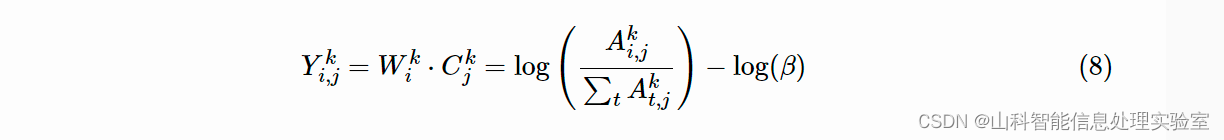
其中,W 和 C 的每一行分别为节点 w 和 c 的表示,β=λ/N,λ 为负采样的数量,N 为图中边的个数。
之后为了减少噪音,模型将 Yk 中所有的负值替换为 0,通过 SVD(方法详情见参见之前博客)得到节点的 d 维表示:
 最终,通过对不同 k 的表示进行拼接得到节点最终的表示。
最终,通过对不同 k 的表示进行拼接得到节点最终的表示。
HOPE
HOPE 9 对于每个节点最终生成两个嵌入表示:一个是作为源节点的嵌入表示,另一个是作为目标节点的嵌入表示。模型通过近似高阶相似性来保留非对称传递性,其优化目标为:

其中,S 为相似矩阵,和
分别为源节点和目标节点的向量表示。下图展示了嵌入向量可以很好的保留非对称传递性:

对于 S 有多种可选近似度量方法:Katz Index,Rooted PageRank(RPR),Common Neighbors(CN),Adamic-Adar(AA)。这些度量方法可以分为两类:全局近似(Katz Index 和 RPR)和局部近似(CN 和 AA)。
算法采用了一个广义 SVD 算法(JDGSVD)来解决使用原始 SVD 算法计算复杂度为过高的问题,从而使得算法可以应用在更大规模的图上。
Meta Paths
matapath2vec
matapath2vec 10 提出了一种基于元路径的异构网络表示学习方法。在此我们引入 3 个定义:
- 异构网络((Heterogeneous information network,HIN)可以定义为一个有向图
,一个节点类型映射
和一个边类型映射
,其中对于
有
,
有 ϕ(e)∈R,且 |A|+|R|>1。
- 网络模式(Network schema)定义为
,为一个包含节点类型映射
- 元路径(Meta-path)定义为网络模式
下图展示了一个学术网络和部分元路径:
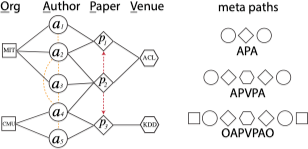
其中,APA 表示一篇论文的共同作者,APVPA 表示两个作者在同一个地方发表过论文。
metapath2vec 采用了基于元路径的随机游走来生成采样序列,这样就可以保留原始网络中的语义信息。对于一个给定的元路径模板,第 i 步的转移概率为:
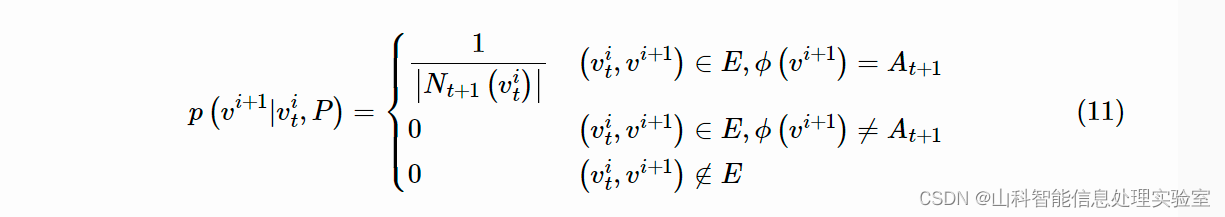
其中,表示节点
类型为
的邻居。之后,则采用了类似 DeepWalk 的方式进行训练得到节点表示。
HIN2Vec
HIN2Vec 11 提出了一种利用多任务学习通过多种关系进行节点和元路径表示学习的方法。模型最初是希望通过一个多分类模型来预测任意两个节点之间所有可能的关系。假设对于任意两个节点,所有可能的关系集合为
假设一个实例和
包含两种关系:P-A 和 P-P-A,则对应的训练数据为
但实际上,扫描整个网络寻找所有可能的关系是不现实的,因此 HIN2Vec 将问题简化为一个给定两个节点判断之间是否存在一个关系的二分类问题,如下图所示:

模型的三个输入分别为节点 x 和 y,以及关系 r。在隐含层输入被转换为向量和
。需要注意对于关系 r,模型应用了一个正则化函数
使得 r 的向量介于 0 和 1 之间。之后采用逐元素相乘对三个向量进行汇总
。在最后的输出层,通过计算
得到最终的预测值。
在生成训练数据时,HIN2Vec 采用了完全随机游走进行节点采样,而非 metapath2vec 中的按照给定的元路径的方式。通过随机替换 x,y,r 中的任何一个可以生成负样本,但当网络中的关系数量较少,节点数量远远大于关系数量时,这种方式很可能产生错误的负样本,因此 HIN2Vec 只随机替换 x,y,保持 r 不变。
Deep Learning
SDNE
SDNE 12 提出了一种利用自编码器同时优化一阶和二阶相似度的图嵌入算法,学习得到的向量能够保留局部和全局的结构信息。SDNE 使用的网络结构如下图所示:
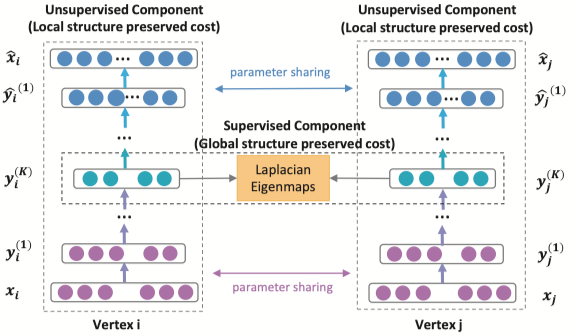
对于二阶相似度,自编码器的目标是最小化输入和输出的重构误差。SDNE 采用邻接矩阵作为自编码器的输入,,每个
包含了节点
的邻居结构信息。模型的损失函数如下:
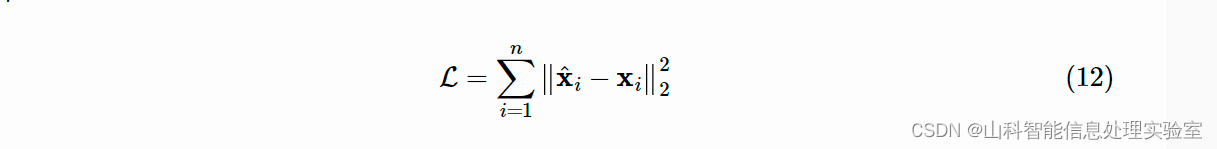
由于网络的稀疏性,邻接矩阵中的非零元素远远少于零元素,因此模型采用了一个带权的损失函数:

其中,⊙ 表示按位乘,,如果 si,j=0 则 bi,j=1 否则 bi,j=β>1。
对于一阶相似度,模型利用了一个监督学习模块最小化节点在隐含空间中距离。损失函数如下:
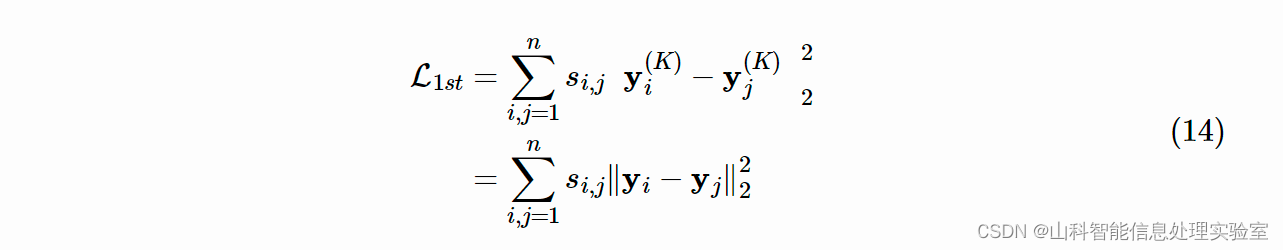
最终,模型联合损失函数如下:
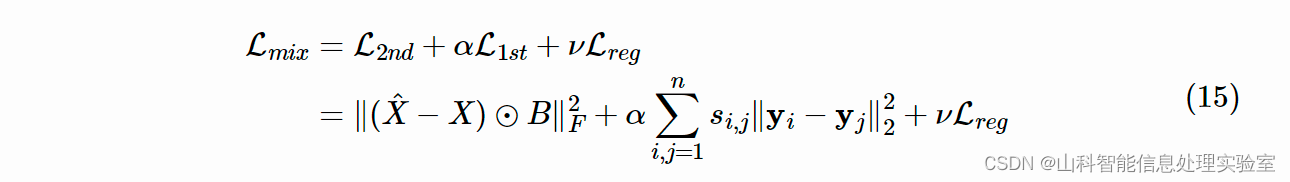
DNGR
DNGR 13 提出了一种利用基于 Stacked Denoising Autoencoder(SDAE)提取特征的网络表示学习算法。算法的流程如下图所示:
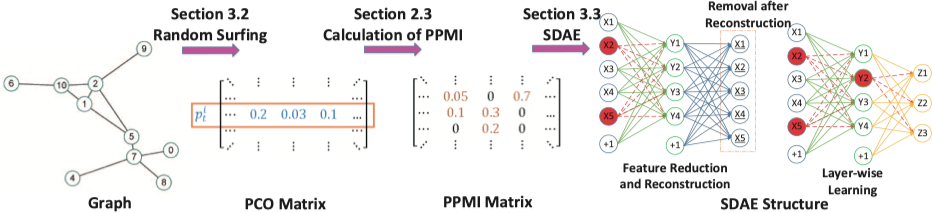
模型首先利用 Random Surfing 得到一个概率共现(PCO)矩阵,之后利用其计算得到 PPMI 矩阵,最后利用 SDAE 进行特征提取得到节点的向量表示。
对于传统的将图结构转换为一个线性序列方法存在几点缺陷:
- 采样序列边缘的节点的上下文信息很难被捕捉。
- 很难直接确定游走的长度和步数等超参数,尤其是对于大型网络来说。
受 PageRank 思想影响,作者采用了 Random Surfing 模型。定义转移矩阵 A,引入行向量 pk,第 j 个元素表示通过 k 步转移之后到达节点 j 的概率。p0 为一个初始向量,其仅第 i 个元素为 1,其它均为 0。在考虑以 1−α 的概率返回初始节点的情况下有:
 在不考虑返回初始节点的情况下有:
在不考虑返回初始节点的情况下有:
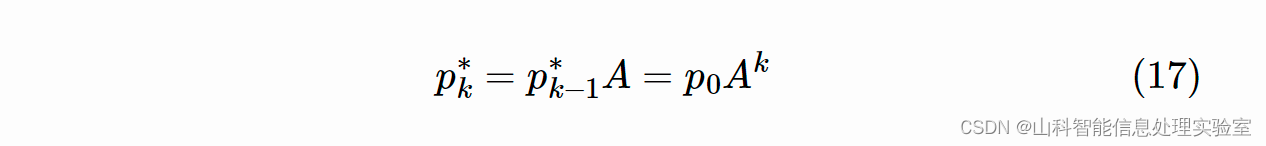
直观而言,两个节点越近,两者的关系越亲密,因此通过同当前节点的相对距离来衡量上下文节点的重要性是合理的。基于此,第 i 个节点的表示可以用如下方式构造:
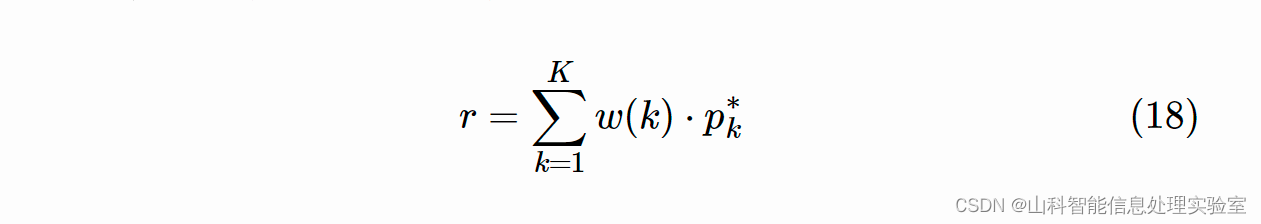 其中,w(⋅) 是一个衰减函数。
其中,w(⋅) 是一个衰减函数。
利用 PCO 计算得到 PPMI 后,再利用一个 SDAE 进行特征提取。Stacking 策略可以通过不同的网络层学习得到不同层级的表示,Denoising 策略则通过去除数据中的噪声,增加结果的鲁棒性。同时,SNGR 相比基于 SVD 的方法效率更高。
Others
LINE
LINE 14 提出了一个用于大规模网络嵌入的方法,其满足如下 3 个要求:
- 同时保留节点之间的一阶相似性(first-order proximity)和二阶相似性(second-order proximity)。
- 可以处理大规模网络,例如:百万级别的顶点和十亿级别的边。
- 可以处理有向,无向和带权的多种类型的图结构。
给定一个无向边 (i,j),点 vi 和 vj 的联合概率如下:

其中, 为节点 vi 的低维向量表示。在空间 V×V 上,分布 p(⋅,⋅) 的经验概率为
,其中
。通过最小化两个分布的 KL 散度来优化模型,则目标函数定义如下:
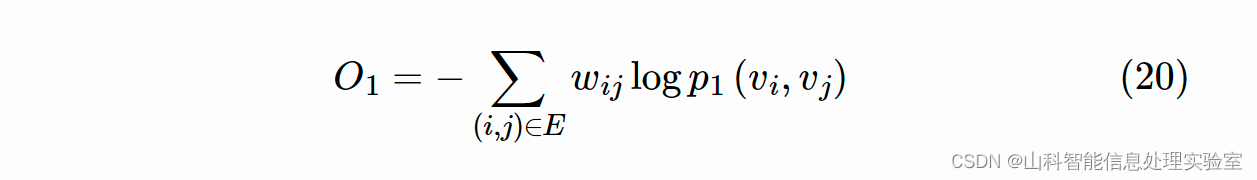
需要注意的是一阶相似度仅可用于无向图,通过最小化上述目标函数,我们可以将任意顶点映射到一个 d 维空间向量。
二阶相似度既可以用于无向图,也可以用于有向图。二阶相似度假设共享大量同其他节点连接的节点之间是相似的,每个节点被视为一个特定的上下文,则在上下文上具有类似分布的节点是相似的。
在此,引入两个向量 和
,其中
是 vi 做为节点的表示,
是 vi 做为上下文的表示。对于一个有向边 (i,j),由 vi 生成上下文 vj 的概率为:
 其中,|V| 为节点或上下文的数量。在此我们引入一个参数 λi 用于表示节点 vi 的重要性程度,重要性程度可以利用度或者 PageRank 算法进行估计。经验分布
其中,|V| 为节点或上下文的数量。在此我们引入一个参数 λi 用于表示节点 vi 的重要性程度,重要性程度可以利用度或者 PageRank 算法进行估计。经验分布定义为
,其中
为边 (i,j) 的权重,di 为节点 vi 的出度。LINE 中采用 di 作为节点的重要性 λi,利用 KL 散度同时忽略一些常量,目标函数定义如下:
 LINE 采用负采样的方式对模型进行优化,同时利用 Alias 方法 15 16 加速采样过程。
LINE 采用负采样的方式对模型进行优化,同时利用 Alias 方法 15 16 加速采样过程。
开放资源
开源实现
| 项目 | 框架 |
|---|---|
| rusty1s/pytorch_geometric | PyTorch |
| dmlc/dgl | PyTorch, TF & MXNet |
| alibaba/euler | TF |
| alibaba/graph-learn | TF |
| deepmind/graph_nets | TF & Sonnet |
| facebookresearch/PyTorch-BigGraph | PyTorch |
| tencent/plato | |
| PaddlePaddle/PGL | PaddlePaddle |
| Accenture/AmpliGraph | TF |
| danielegrattarola/spektral | TF |
| THUDM/cogdl | PyTorch |
| DeepGraphLearning/graphvite | PyTorch |
论文列表和评测
- Must-read papers on network representation learning (NRL) / network embedding (NE)
- Must-read papers on graph neural networks (GNN)
- DeepGraphLearning/LiteratureDL4Graph
- nnzhan/Awesome-Graph-Neural-Networks
- graphdeeplearning/benchmarking-gnns
- Open Graph Benchmark
- Cai, H., Zheng, V. W., & Chang, K. C. C. (2018). A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Transactions on Knowledge and Data Engineering, 30(9), 1616-1637. ↩
- Goyal, P., & Ferrara, E. (2018). Graph embedding techniques, applications, and performance: A survey. Knowledge-Based Systems, 151, 78-94. ↩
- Hamilton, W. L., Ying, R., & Leskovec, J. (2017). Representation learning on graphs: Methods and applications. arXiv preprint arXiv:1709.05584. ↩
- Perozzi, B., Al-Rfou, R., & Skiena, S. (2014). Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 701-710). ↩
- Grover, A., & Leskovec, J. (2016). node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 855-864). ↩
- Fogaras, D., Rácz, B., Csalogány, K., & Sarlós, T. (2005). Towards scaling fully personalized pagerank: Algorithms, lower bounds, and experiments. Internet Mathematics, 2(3), 333-358. ↩
- Haveliwala, T. H. (2002). Topic-sensitive PageRank. In Proceedings of the 11th international conference on World Wide Web (pp. 517-526). ↩
- Cao, S., Lu, W., & Xu, Q. (2015). Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM international on conference on information and knowledge management (pp. 891-900). ↩
- Ou, M., Cui, P., Pei, J., Zhang, Z., & Zhu, W. (2016). Asymmetric transitivity preserving graph embedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1105-1114). ↩
- Dong, Y., Chawla, N. V., & Swami, A. (2017). metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 135-144). ↩
- Fu, T. Y., Lee, W. C., & Lei, Z. (2017). Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (pp. 1797-1806). ↩
- Wang, D., Cui, P., & Zhu, W. (2016). Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1225-1234). ↩
- Cao, S., Lu, W., & Xu, Q. (2016). Deep neural networks for learning graph representations. In Thirtieth AAAI conference on artificial intelligence. ↩
- Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J., & Mei, Q. (2015). Line: Large-scale information network embedding. In Proceedings of the 24th international conference on world wide web (pp. 1067-1077). ↩
- Walker, A. J. (1974). New fast method for generating discrete random numbers with arbitrary frequency distributions. Electronics Letters, 10(8), 127-128. ↩
- Walker, A. J. (1977). An efficient method for generating discrete random variables with general distributions. ACM Transactions on Mathematical Software (TOMS), 3(3), 253-256. ↩