参考书目《机器学习实战》
花了两个晚上把k-近邻算法学习了一下,书讲的很不错,但是python代码读起来有点麻烦,主要是很多用法习惯和我的基本不一样。基本上都是按照原理揣摩着作者的源码重写的,现在将部分代码重写如下。
k-近邻算法原理其实很简单,说白了就是“物以类聚,人以群分”。想看你是个什么人,就看和你关系很好的人是什么人。举个例子,假如和你关系最好的五个人有四个都是大学霸,那你是学霸的可能性就很高了。
k-近邻算法就和例子一样,首先通过某种方法(欧拉距离等),计算出未知样本和已知样本集中各个样本的距离,然后选取距离最近的几个样本,这几个样本中出现频率最高的类别就认为是未知样本的类别了。
用科学的语言描述就是:

这里计算使用的是欧拉距离
计算两个样本点xA,xB间的距离
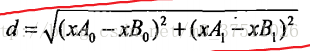
考虑到样本比重的问题,一般会对样本做归一化处理

好了,终于可以上代码了
读入读出,分类,归一化,功能函数
import numpy as np
from array import array
import operator
def classify0 (ninX, ndataSet, labels, k):
'''
define:用于分类
inX:用于分类的输入向量,应为numpy数组
dataSet:输入的训练样本集,应为numpy数组
labels:标签向量
k:用于选择最近邻居的数目
return: 分类
'''
#计算分类向量和样本集各点的欧拉距离,利用了广播
ndistance = np.sqrt(np.sum(np.square(ninX.reshape(1,-1) - ndataSet),1))
#确定前K个最小元素所在的主要分类
sortDisIndicies = np.argsort(ndistance)
dic = {}
for i in range(0,k,1):
votelabel = labels[sortDisIndicies[i]]
#dic.get(D,K),如果字典dic含有D,则返回当前D的个数,否则返回K
dic[votelabel] = dic.get(votelabel,0)+1
sortedDic = sorted(dic.items(),key = operator.itemgetter(1),reverse = True)
return sortedDic[0][0]
def file2matrix(filename):
'''
define:用于读入数据
filename:文件名称
return:读入文件的数据
'''
a=array('d')
b=array('d')
#with语句来自动帮我们调用close()方法
with open(filename, 'r', encoding = 'ANSI') as f: #以只读的方式打开文件
for line in f.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
line = line.split()
if not len(line): #判断是否是空行
continue #是的话,跳过不处理
for word in line[0:3]:
a.append(float(word)) #将分类存入数组
b.append(int(line[3]))
#将数据转换为numpy的数组
na = np.frombuffer(a,dtype = float)
na = np.reshape(na,(-1,3))
nb = np.frombuffer(b,dtype = float)
return na,nb
def autoNorm(dataSet):
'''
define:对数据做归一化处理
dataSet:需要做归一化的数据集
return:归一化的数据集
'''
minVals = np.min(dataSet,0)
maxVals = np.max(dataSet,0)
#求取最大最小值间的距离
ranges = maxVals - minVals
#利用广播进行计算
newDataSet = (dataSet-minVals)/ranges
return newDataSet,ranges,minVals
测试函数
import numpy as np
from first.kNN import file2matrix, autoNorm, classify0
def datingClassTest():
'''
define:读入文件并检测
'''
#获取数据文件
datingDataMat,datinglabels = file2matrix('C:/Users/Desktop/datingTestSet2.txt')
#对数据归一化处理
normMat,ranges,minvals = autoNorm(datingDataMat)
#用来检测的数据,取0.1
numTestVecs = int(0.1*normMat.shape[0])
errorCount = 0.0
for i in range(0,numTestVecs):
#训练并检测结果
classifierResult = classify0(normMat[i,:], normMat[numTestVecs:,:],\
datinglabels[numTestVecs:], 3)
#print("the classifier came back with: %d, the real answer is: %d" \
# % (classifierResult, datinglabels[i]))
#检测错误率
if(classifierResult != datinglabels[i]):
errorCount += 1.0
print("the total error rate is:%f" % (errorCount/float(numTestVecs)))
datingClassTest() 
基本就是这样了。明天继续第二章决策树