模型介绍
本项目是使用Bert模型来进行文本的实体识别。
Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类(Bert)pytorch_bert文本分类_牧子川的博客-CSDN博客
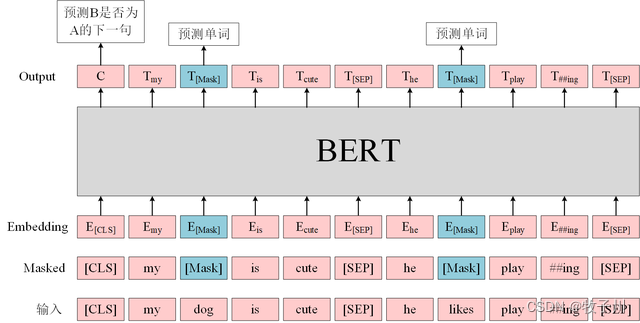
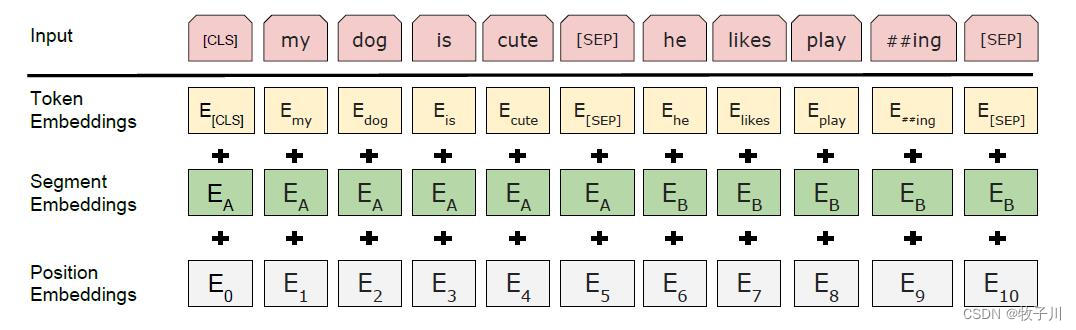
模型结构
Bert模型的模型结构:
数据介绍
数据网址:https://github.com/buppt//raw/master/data/people-relation/train.txt
实体1 实体2 关系 文本
input_ids_list, token_type_ids_list, attention_mask_list, e1_masks_list, e2_masks_list, labels_list = [], [], [], [], [], []
for instance in batch_data:
# 按照batch中的最大数据长度,对数据进行padding填充
input_ids_temp = instance["input_ids"]
token_type_ids_temp = instance["token_type_ids"]
attention_mask_temp = instance["attention_mask"]
e1_masks_temp = instance["e1_masks"]
e2_masks_temp = instance["e2_masks"]
labels_temp = instance["labels"]
# 添加到对应的list中
input_ids_list.append(torch.tensor(input_ids_temp, dtype=torch.long))
token_type_ids_list.append(torch.tensor(token_type_ids_temp, dtype=torch.long))
attention_mask_list.append(torch.tensor(attention_mask_temp, dtype=torch.long))
e1_masks_list.append(torch.tensor(e1_masks_temp, dtype=torch.long))
e2_masks_list.append(torch.tensor(e2_masks_temp, dtype=torch.long))
labels_list.append(labels_temp)
# 使用pad_sequence函数,会将list中所有的tensor进行长度补全,补全到一个batch数据中的最大长度,补全元素为padding_value
return {"input_ids": pad_sequence(input_ids_list, batch_first=True, padding_value=0),
"token_type_ids": pad_sequence(token_type_ids_list, batch_first=True, padding_value=0),
"attention_mask": pad_sequence(attention_mask_list, batch_first=True, padding_value=0),
"e1_masks": pad_sequence(e1_masks_list, batch_first=True, padding_value=0),
"e2_masks": pad_sequence(e2_masks_list, batch_first=True, padding_value=0),
"labels": torch.tensor(labels_list, dtype=torch.long)}模型准备
def forward(self, token_ids, token_type_ids, attention_mask, e1_mask, e2_mask):
sequence_output, pooled_output = self.bert_model(input_ids=token_ids, token_type_ids=token_type_ids,
attention_mask=attention_mask, return_dict=False)
# 每个实体的所有token向量的平均值
e1_h = self.entity_average(sequence_output, e1_mask)
e2_h = self.entity_average(sequence_output, e2_mask)
e1_h = self.activation(self.dense(e1_h))
e2_h = self.activation(self.dense(e2_h))
# [cls] + 实体1 + 实体2
concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=-1)
concat_h = self.norm(concat_h)
logits = self.hidden2tag(self.drop(concat_h))
return logits模型预测
输入中文句子:丁一岚与丈夫邓拓
句子中的实体1:丁一岚
句子中的实体2:邓拓
在丁一岚与丈夫邓拓中丁一岚与邓拓的关系为:夫妻
输入中文句子:丁一岚与丈夫邓拓
句子中的实体1:邓拓
句子中的实体2:丁一岚
在【丁一岚与丈夫邓拓】中【邓拓】与【丁一岚】的关系为:夫妻
输入中文句子:京德云社演出相声,演员包括郭德纲、于谦、李菁、高峰、何云伟、曹云金、刘云天、栾云平、岳云鹏等,段子包括《兵器谱》、《大西厢》、《梦中婚
句子中的实体1:郭德纲
句子中的实体2:刘云天
在【京德云社演出相声,演员包括郭德纲、于谦、李菁、高峰、何云伟、曹云金、刘云天、栾云平、岳云鹏等,段子包括《兵器谱》、《大西厢》、《梦中婚】中【郭德纲】与【刘云天】的关系为:师生
输入中文句子:在荣国府里,虽然官爵是由贾政承继,但真正主持家政的却是贾赦这一派,而且贾赦在贾母面前似乎并不得宠。
句子中的实体1:贾母
句子中的实体2:贾赦
在【在荣国府里,虽然官爵是由贾政承继,但真正主持家政的却是贾赦这一派,而且贾赦在贾母面前似乎并不得宠。】中【贾母】与【贾赦】的关系为:父母
源码获取
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!