这篇关于异常检测的论文,是我的夏令营导师供我阅读的几篇文章之一,我的PPT及草稿如下。
(PS:这是首次接触这类论文,且阅读粗浅,因此有很多不懂或错误的地方,请谅解)。
一、背景
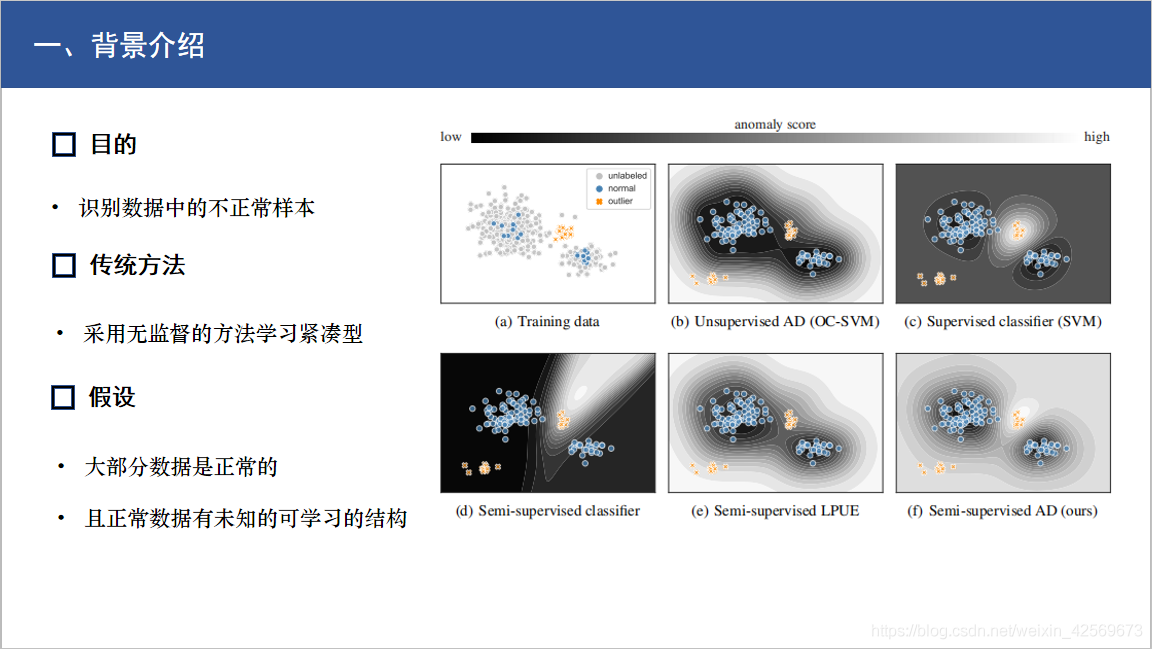
我将要介绍的这几篇论文都是以异常检测为背景的,因此要介绍一下什么是异常检测。
通俗来讲,异常检测的目的就是要从数据集中,把他认为异常的样本挑出来(比如不符合预期的或者不遵循共同模式的样本),如右图所示,蓝色为正常数据,橙色为异常数据,而我们要做的就是把他们分辨出来。 比如SVM分类,他就是通过划分超平面,从而将不同类区分开,如图所示,圈里的就是正常,圈外的就是异常。
那么对于没有标签的数据集来说,传统方法是采用无监督的方法来学习紧凑型,而聚类方法在学习异常的时候是很困难的,因为异常数据不会像正常数据一样扎堆,有明显的特点。而相反的是应该学习正常数据的特点,也就是one class learning,而只要不能判断为正常的就应该全部归为异常。
因此在训练的时候我们必须有个前提,那就是大部分数据都为正常数据,而且正常数据有未知的可学习结构,否则因为没有标签约束就没办法学习了。
二、出发点及要点

第一篇论文,题目是Semi-Supervised,说明这个论文使用的是半监督学习,而不是传统的无监督。
这篇文章研究人员提出,在现实问题中数据集并不是一点标签都没有的,他还存在少量标签。以此来引出我们可以通过半监督学习来利用这部分有标签的数据。 那么有标签就意味着,不光是有样本被标记为正常,还有样本被标记为异常的数据。
我们刚才也提到了,现有的聚类方法对异常样本学习效果是不好的,也正因为这样,传统的半监督AD方法只应用了标记为正常的样本,或者是狭义上的利用了异常样本, 那么从而就引出了如何发明一种具有普适性的可利用所有标记样本的方法的问题。

那么根据这个来判断,这篇文章应该是要达成两个目标,一个就是同时利用有标签和无标签数据,另一个就是对有标记的异常样本的处理问题。
三、相关工作

作者在相关工作部分引出了信息论的思想,这种思想常用在异常检测中。
互信息,衡量两个随机变量之间的相关性。
有监督学习,是希望潜在表示 Z 与 X相关性小,而与Y相关性大,使模型向着标签Y学习,如(1)所示。
但是因为无监督学习没有标签,所以没有Y,需要改写公式,提出了信息最大化的理论,如(2)所示。
左侧希望最大化X与其潜在表示Z的相关性,右侧是正则项不用管。这个公式的意义就是他希望能学习到一种紧凑的结构,任何其他的数据都是异常的。而不是像有监督分类一样,可能要分别学习判断是不是正常类或者异常类。自动编码器就是应用的这种理论,他希望学习一个恒等式,然后通过给模型的输出设定一个阈值,就可以圈定正常和异常的界限。
作者提出的方法就是基于第二个式子的,但是因为这次我们有Y了,就是有一些标签了,于是作者对他进行了改写,给后面的正则项改成了R(Z,Y),在后面实际操作中,这个正则项是基于熵的,如(3)所示 。
接下来他介绍了Deep SVVD方法,而文章提出的方法也是由SVVD改进而来的,这是一种无监督的学习方法,他求了个神经网络与一个已知的超球面中心c的距离,他希望学习一种转换,使以c为中心的,输出空间Z中的封闭超球的体积最小化。
通俗地来讲,训练好之后,模型会倾向于将正常的样本输出映射到距离c比较近的地方,而异常的样本就会映射到比较远的地方,然后就可以通过设置距离阈值来分成正常异常两类。
四、方法及实验

那么作者在这就指出,几何上最小化超球体积的操作,实际上也可以解释为熵最小化的过程。
根据刚才信息论公式的改动,就可以通过最小化熵的方式进行应用。从而把公式扩展到可以同时接受有标签数据,进行训练。
新增的这一项必须保证,对于正常的数据的潜在分布,有低熵。对于异常数据的潜在分布,有高熵。 因此就有了现在这个公式。
对于标记的正常的数据,即y^=+1,对映射点到中心c的距离施加二次损失,我们最小化模型就倾向于把他映射到距离中心更近的地方 对于标记的异常数据,即y ^= -1,对距离的倒数进行了惩罚,这样异常就必须被映射到离中心更远的地方。
因此,这与异常不集中的普遍假设是一致的。 这样他的损失函数就既囊括了无标记的部分,又利用了有正或者负标记的部分,数据就都利用起来了。
在实验阶段,他测试了带标记数据比例、污染比例、还有异常类个数等几个参数,归结起来就是对于更复杂的、有标记的、有污染的数据下,提出的方法相比于传统方法有不错的效果。