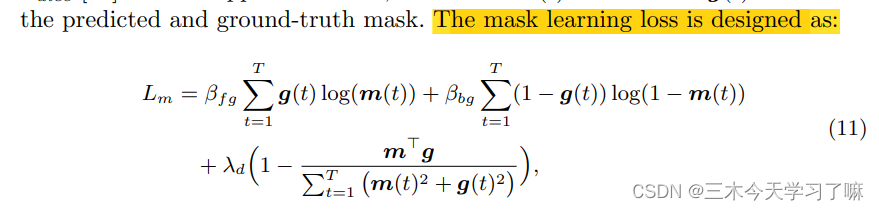文章目录

本博客将阅读 Semi-Supervised Action Detection任务下,表现最好的三篇论文。并思考如何设计或者改进以达到STOA。
1. Learning Temporal Action Proposals With Fewer Labels (ICCV 2019)
论文目的——拟解决问题
- 目前大多数训练动作建议模块的方法都依赖于完全监督的方法,这需要在长视频序列中有大量注释的时间性动作间隔,需要大量的成本和注释工作,促使我们研究用较少的监督来训练建议模块的问题。
- 半监督学习方法的一个核心理念是用平滑和一致的分类边界来训练模型,对随机扰动具有鲁棒性。对于视频中的时间性动作建议任务,扰动的设计应该有利于序列学习。然而,先前的工作并没有为视频等序列数据提出适当的扰动。
贡献——创新
- 是第一个将半监督学习纳入到时间性动作建议中,以实现标签效率利用。
- 为这个半监督框架设计了两种基本类型的顺序扰动sequential perturbations,并在时态动作建议的关键实验中对它们进行了验证,以对抗强大的半监督基线。
实现流程
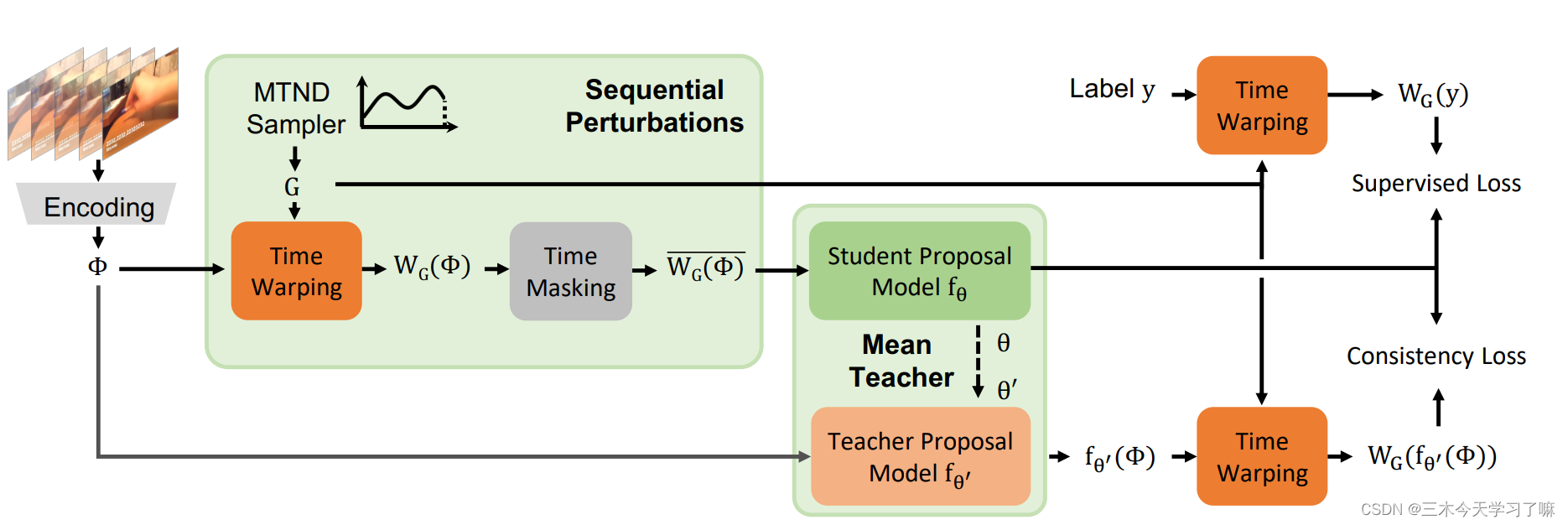
输入一个未经修剪的视频,首先将其编码为一个特征序列Φ。接下来,包括时间扭曲和时间遮蔽在内的序列扰动被应用到Φ上,学生提案模型将这个扰动的序列作为输入。
相反,教师模型直接对未受干扰的Φ进行预测。最后,学生模型与应用于标记视频的监督损失和应用于所有视频的一致性损失联合优化。
详细方法
在一个最先进的全监督提议生成网络——边界敏感网络(BSN)上建立了我们的模型。我们将平均教师框架扩展为两种类型的连续扰动 时间扭曲和时间掩码 来训练提案模型。
-
Video Encoding:
给定一个有N个帧的未经修剪的视频作为输入,我们首先把它分成不重叠的短片段,对每个视频的RGB帧和光流都进行编码,然后将编码的向量连接起来。有标签的视频和无标签的视频共享同一个视频编码器,它们共同存在于同一个批次中。 -
Temporal Action Proposal Model:
编码后的序列送入BSN提议模型。BSN由两个可训练的模块序列组成:时态评估模块(TEM)和提议评估模块(PEM)。
视频编码后,TEM将片段特征序列Φ作为输入。序列Φ通过时间卷积层,生成三个系列的概率信号:动作性,开始和结束。
然后根据这三个信号序列生成建议。最后,PEM为每个提议预测一个置信度分数pconf,表示一个提议与最接近的地面真相区间的重叠程度,以决定该提议是否被接受或拒绝。 -
Mean Teacher Framework:
如何构建半监督学习框架来进行时间性动作建议?当只有少量标记的训练样本可用时,像BSN这样的深度模型往往会过度拟合,无法从训练集中提取足够的知识来归纳到未见过的视频。 这可以通过半监督学习来缓解,在半监督学习中,未标记的视频也可以用来训练。如果没有GT,监督分类的损失在未标记的视频上是无法定义的。
相反,我们需要引入一个无监督的辅助任务来利用来自无标签视频的信息。
作为一个baseline,可以直接将平均教师法应用于时间动作建议模型,形成半监督学习框架。

-
Sequential Perturbations:
加入随机扰动,对于半监督算法学习一个鲁棒的模型是有非常帮助的。
Time Warping: Time Warping本质上是一个重采样层,它在随机生成的一维流场网格的引导下,沿时间维度对特征向量序列Φ进行重采样。
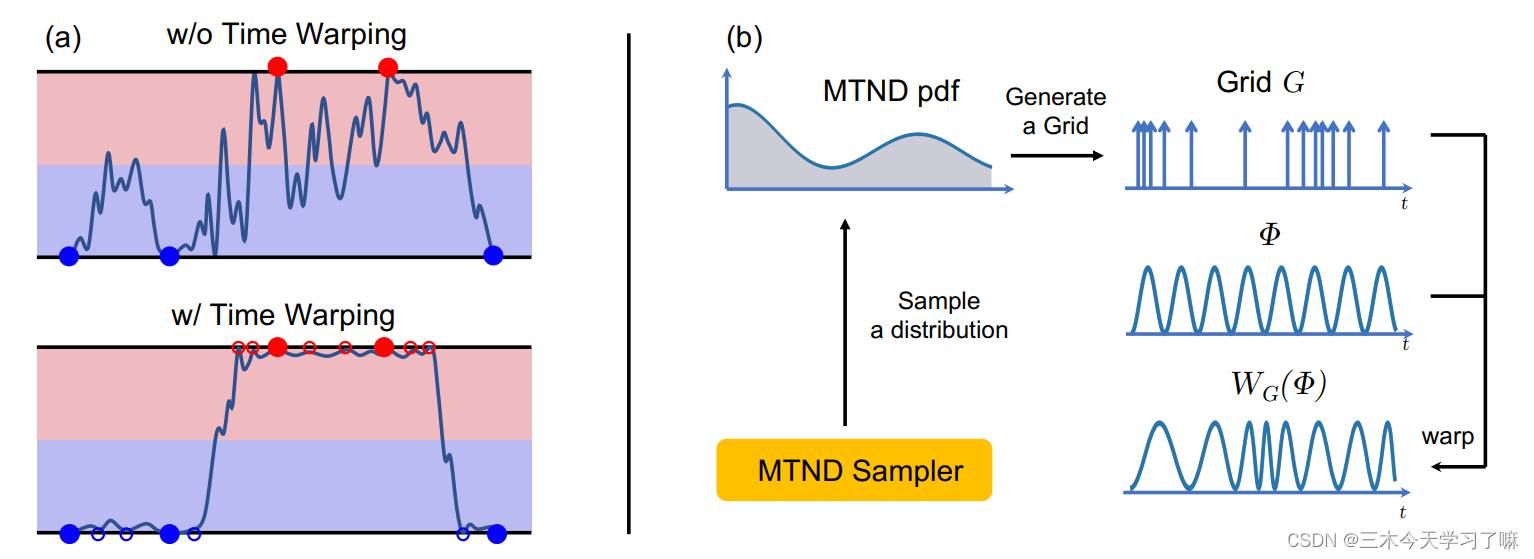
左图:通时间扭曲Time Warping,可以在编码空间中对更多的片段特征进行采样。在已标记的片段特征(填充的圆圈)中重新取样新的特征点(空的圆圈),鼓励学生模型产生一个更平滑的流形来进行预测。
首先,通过将标签传播到特征空间中未标记的位置,重采样导致更平滑的预测(左图);
其次,时间翘曲作为一种数据增强的方式,为训练提供更多的标记数据,这在标签很少的情况下特别有帮助;
第三,拉伸和压缩输入信号可以产生更多的变体来学习某些任务,如时间动作建议,这需要准确的开始和结束位置预测。
为了对输入特征序列Φ进行扭曲,每个输出特征向量都是根据密集的一维网格G对Φ进行线性采样计算的,其中gt是对输出特征向量进行采样的时间位置。在执行时间扭曲的过程中,网格应该包括长期失真,使视频的某些部分变慢,而其他部分变快;它还应该包含短期随机噪声。 基于这些考虑,提出了一个混合截断正态分布(MTND)采样器(右图)来生成网格。
Time Masking: 时间掩码,作为训练期间顺序扰动的另一个来源。时间掩码紧随时间扭曲之后,以WG(Φ)作为输入。时间屏蔽的想法很简单:输入序列中的一些片段被屏蔽在学生模型之外,而教师模型可以看到整个无遮挡的视频序列。我们把时间屏蔽的输出表示为WG(Φ)。在训练过程中,鼓励被屏蔽的学生模型在每次迭代中产生与教师相同的输出,尽管他们无法获得输入视频的全部信息。
时间屏蔽可以被看作是一个特殊的Dropout层。 在常规的Dropout层中,一个片段中的神经元不可能完全被丢弃,这就给了模型一个机会从感受野中的每个片段中偷取一些信息。相反,在时间屏蔽中,被丢弃的片段的任何信息都不会被传递到下一个层。学生模型将被迫从时间背景中聚合信息,以对丢失的片段进行预测。这种时间背景聚合的能力将从标记的视频上的监督损失和所有训练数据上与教师模型的一致性中学到。扫描二维码关注公众号,回复: 15219966 查看本文章
-
Training:
训练我们的半监督框架包括两部分:最小化标记数据的监督损失和所有训练数据的一致性损失。
Supervised Losses: 与完全监督的建议模型相一致,半监督框架使用与BSN中相同的监督损失进行训练。
Consistency Regularization: 一致性损失将教师模型的输出视为标签,并鼓励学生学习像教师那样的平滑流形。与监督损失不同的是,一致性损失可以应用于训练集中有标签和无标签的视频。

对于距离函数D,我们在所有实验中使用平均平方误差。与有监督的优化一样,只训练学生模型中的权重。一致性损失和监督性损失相加为总损失。
2. Self-Supervised Learning for Semi-Supervised Temporal Action Proposal (CVPR 2021)
论文目的——拟解决问题
几乎所有的方法都依赖于训练视频的密集时间标注。然而,标注任务是繁琐的,需要大量的人力劳动,这可能在满足实际需求方面能力有限。
贡献——创新
- 设计统一的SSTAP框架,首次将自监督学习纳入半监督的时间行动建议中;
- 设计了两种简单而有效的时间顺序扰动,并为SSTAP定义了两种自监督的pretext任务;
实现流程
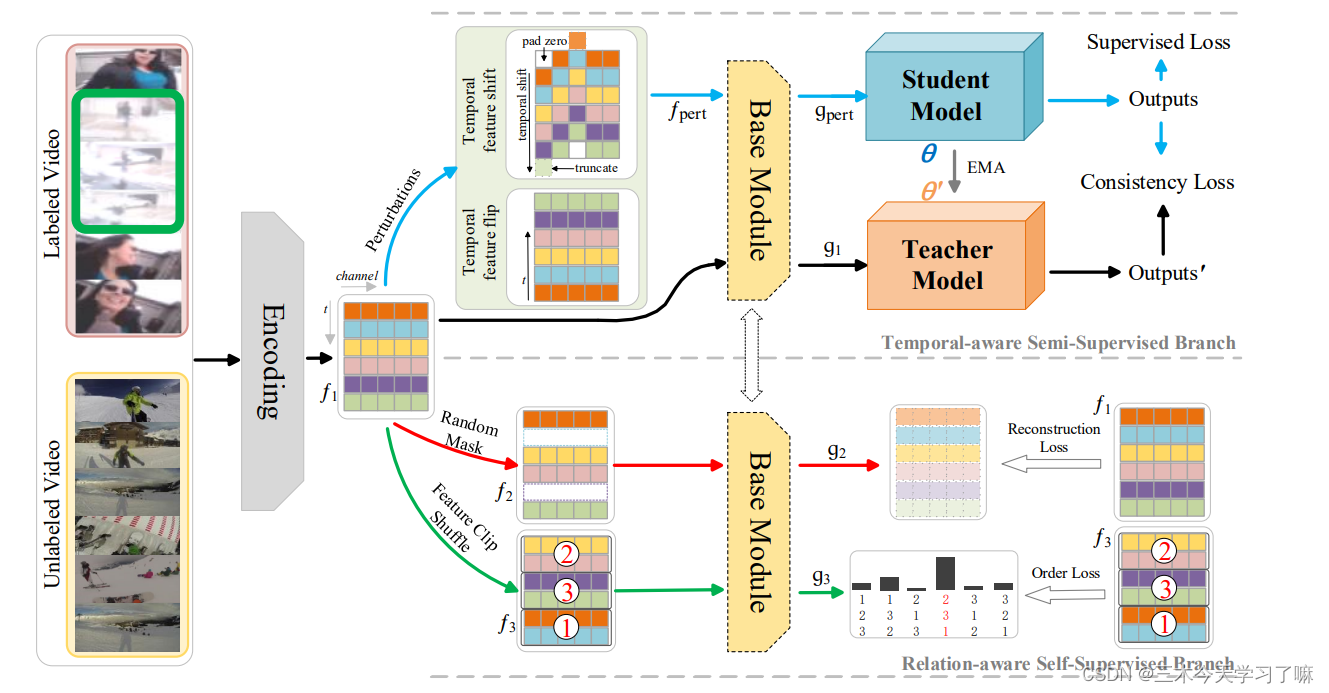
SSTAP概述。首先将一个采样的未修剪的输入视频编码为一个特征序列f1。在时间感知的半监督分支(右上角),有两个连续的扰动操作:时间特征转移和时间特征翻转。而基础模块将被扰动的序列f_pert和未被扰动的f_1作为输入。接下来,同一网络结构的学生模型和教师模型产生输出。
在关系感知的自监督分支(右下角),有两个自监督的前文任务:遮蔽特征重建和剪辑顺序预测。
最后,一个统一的多任务框架被利用来进行优化。彩色编码的箭头表示框架中的特征与各自模块之间的关联。
详细方法
-
Feature Encoding: 先将其分为不重叠的短片段,每个片段包含σ帧。然后采用双流网络来提取视觉特征序列φ。
-
Temporal-aware Semi-Supervised Branch: 简单介绍了预选框生成网络BMN和Mean Teacher模型,并讲述了加入扰动项对半监督系统学习一个稳健的模型具有好处。但是上一篇文章所加入的扰动忽略了时间上的相互作用。于是提出本文的两个扰动:temporal feature shift and temporal feature flip(时间特征的转移和时间特征的翻转)
temporal feature shift 时间特征移动扰动是在输入视频的特征图上沿时间维度双向移动一些随机选择的通道。因此,时间特征移动可以大大增加输入特征的多样性,即作为一种数据增强的方式,为训练提供更多的数据。
temporal feature flip 时间特征翻转使原始和翻转的视频特征中的提议之间的一对一对应关系可以很容易地对齐。
由于具有不同扰动的连续视频特征可能有不同位置和大小的建议数量,因此,要匹配给定的视频特征是具有挑战性的。因此,采用水平翻转的视频特征,在训练过程中,鼓励每个迭代中的学生模型产生与教师模型对称的输出。在训练过程中,每个小批次都包括有标签和无标签的数据。平均教师框架工作中的一致性正则化利用了未标记的数据,其假设是当输入相同输入的扰动版本时,模型应该输出类似的预测。在时间感知半监督分支中,一致性损失被应用于标记的和未标记的数据。请注意,一致性损失(L2-loss)添加到BMN输出的边界概率序列和边界匹配置信图中。
因此,在时间感知的半监督分支中,总损失公式为:

-
Relation-aware Self-Supervised Branch: 假设半监督的时间动作提议方法可以极大地受益于自监督学习技术。而基于这种洞察力,在关系感知的自监督分支中,我们提出了两个辅助性任务。这两个辅助任务,即Masked feature reconstruction遮蔽特征重建和clip-order prediction片段顺序预测,可以帮助网络学习时间关系和判别性表征。
Masked feature reconstruction: 遮蔽特征的重建。这个自监督的辅助任务的关键思想是通过沿时间维度随机掩盖视频特征f1的一些时间点来生成特征f2。然后,基础模块利用f2来重建f1。 掩蔽特征重建从原始特征f1中产生自监督信号,可以以一种简单而有效的方式学习鉴别性的表征。
在掩蔽特征重构的辅助任务中,基础模块将被驱动去感知和聚合来自上下文的信息,以预测掉落的片段。这样一来,学习到的时间语义关系和判别特征自然有利于半监督的时间行动建议。
clip-order prediction: 这个辅助任务需要预测片段特征序列在随机洗牌的特征图中的正确顺序。 具体来说,三个随机洗牌的特征序列的重新排序主图所示。实际上,片段顺序预测被表述为一个分类任务。输入是一个片段特征序列的元组,输出是一个不同顺序的概率分布。
在实验中,我们根据经验设计了两个随机洗牌的特征序列的重新排序。片段顺序预测可以利用特征f1的时间顺序来学习鉴别性的时间表征。而且片段顺序预测是在片段序列层面,可以减少顺序的不确定性,更适合于学习视频特征表征。 -
Overall Loss:

3. Semi-Supervised Temporal Action Detection with Proposal-Free Masking (ECCV 2022)
论文目的——拟解决问题
- 现有的时间性动作检测(TAD)方法依赖于大量的训练数据和片段级的注释。因此,收集和标注这样一个训练集是非常昂贵的,而且无法扩展。
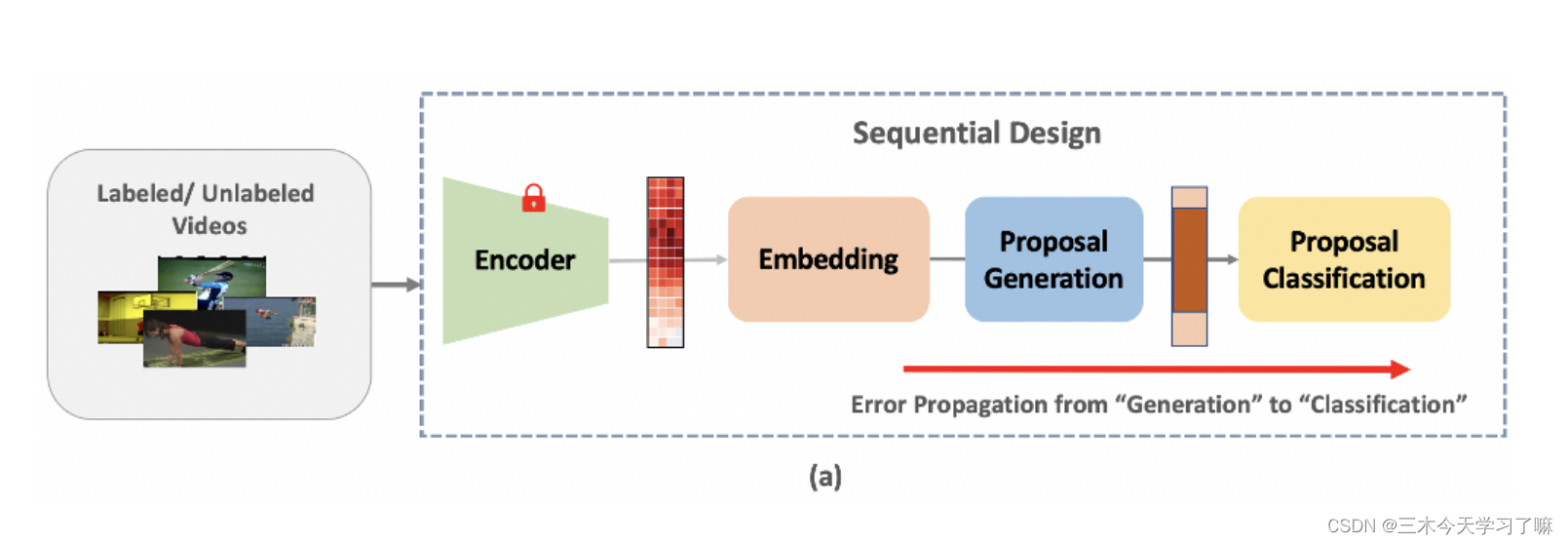
- 先前的SS-TAD方法直接结合了现有的基于建议的TAD方法和SSL方法。由于它们的顺序定位(如候选框生成)和分类设计,它们很容易出现候选框错误传播。这是因为现有的TAD模型采用了连续的定位(例如,建议生成)和分类设计。当扩展到SSL设置时,在用未标记的数据训练时不可避免的定位错误会很容易传播到分类模块,导致类别预测的累积错误。
贡献——创新
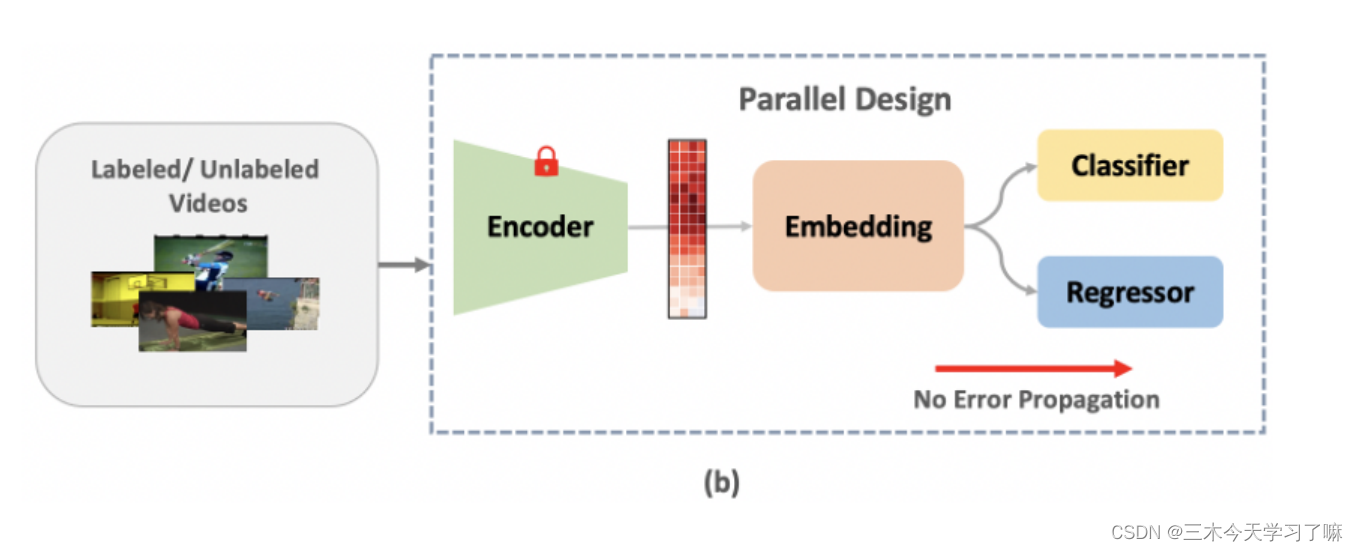
- 提出了一种新型的基于无提议时空掩码(SPOT)的半监督时空动作检测模型,它具有并行的定位(掩码生成)和分类架构。这种新颖的设计通过切断中间的错误传播途径,有效地消除了定位和分类之间的依赖性。
- 进一步引入了边界细化算法,以实现预测的细化,并为自监督的模型预训练引入了一个新的pretext任务。将SPOT与SS-TAD的伪标签相结合,并为并行设计专门制定了新的分类和掩码损失函数。
实现流程
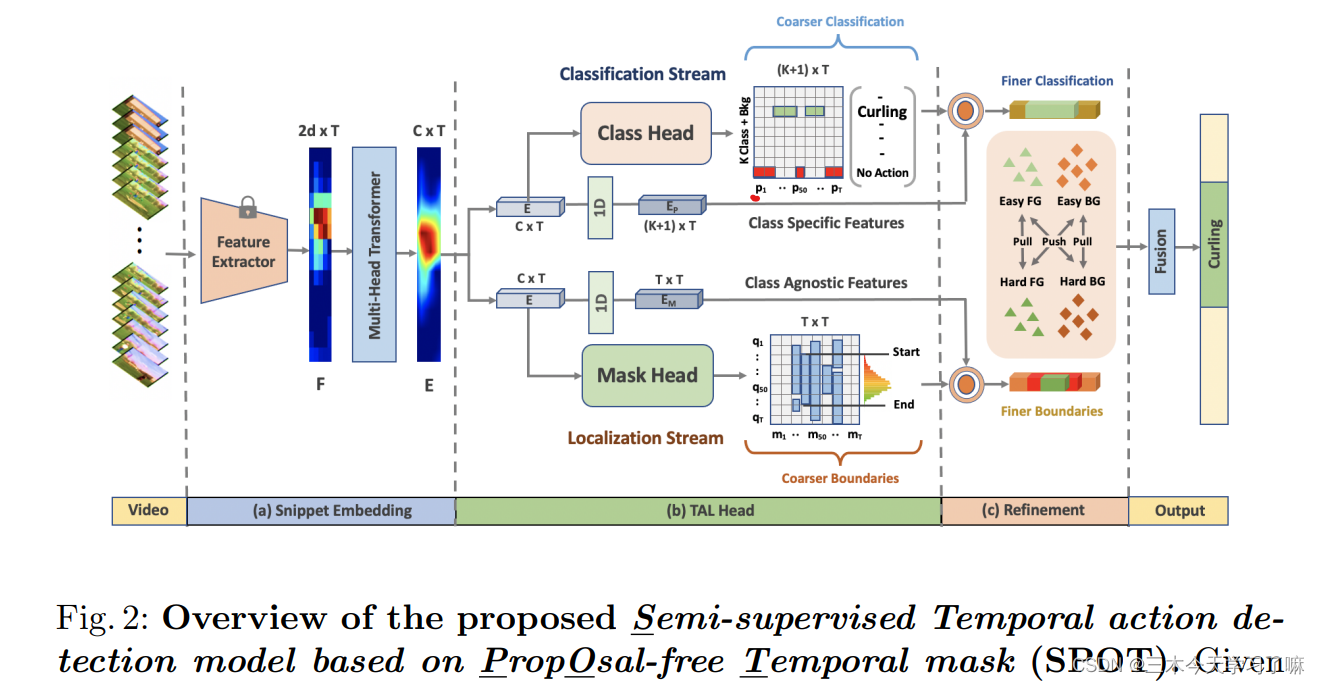
Overview of the proposed Semi-supervised Temporal action detection model based on Proposal-free Temporal mask
给定一个未经修剪的视频V,首先用预先训练好的视频编码器提取一连串的T片段特征,并进行自我注意学习以获得具有全局背景的片段编码E。对于每个片段编码,我们用分类流预测一个分类分数P,用掩码流预测一个前景掩码M,两者都进一步用于边界细化。它是基于挖掘难易程度的前景(FG)和背景(BG)片段。对于SS-TAD,交替地预测和利用未标记的训练视频的伪类和掩码标签,以及标记的视频。
详细方法
-
Proposal-Free Temporal Mask Learning:

Video Snippet Embedding: 将未经修剪的视频分割成T个等距的时间片段,并利用双流网络来提取RGB特征和光流特征,并将二者串联为序列F,虽然F包含局部的时空信息,但它缺乏对TAD至关重要的全局背景。因此,我们利用自我注意机制来学习全局背景。形式上,我们将多头变形器编码器 T() 的输入{query, key, value}设定为特征{F, F, F}。
TAD Head: 为了实现无建议的设计,引入了一个基于时空掩码学习的TAD头。它由两个平行的流组成:一个用于片段分类,另一个用于时间掩码推理。 这种设计打破了定位和分类之间的顺序依赖,这种依赖会导致现有TAD模型中不必要的错误传播。
Snippet classification stream: 鉴于第t个片断,分类分支预测了Y的概率分布pt∈R (K+1)×1。对于一个有T个片段的视频,分类分支的输出可以表示为。
Temporal mask stream: 与分类流并行,该流预测整个视频时间跨度内的动作实例的时间掩码。给定第t个片段E(t),它输出一个掩码向量mt,每个元素qi表示第i个片段的前景概率。这是由三个一维卷积层Hm叠加实现的。
有了提议的掩码信号作为模型输出监督,就不再需要提议来促进SS-TAD学习。
Boundary Refinement: 在TAD头的末端设计了一个流间互动机制(inter-steam interaction mechanism) 来完善TAD,专注于前景和背景之间的过渡(即时间边界)的模糊片段(hard snippets)。它们被认为是困难的片段,与那些位于远离时间边界的掩码或背景区间内的容易的片段相比,有更多值得信赖的干扰。通过检查时间掩码M的结构来检测困难片断。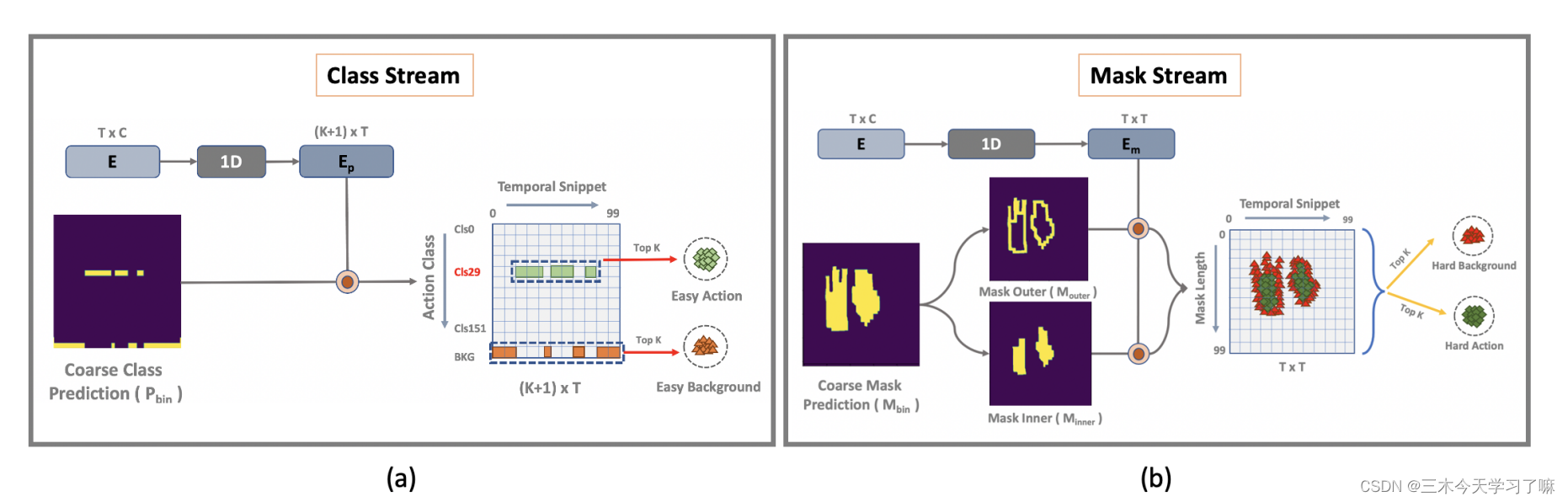
如上图b所示,被侵蚀的掩码边界所跨越的片段为硬背景,而被非边界掩码所跨越的片段为硬前景。 -
Model Training:
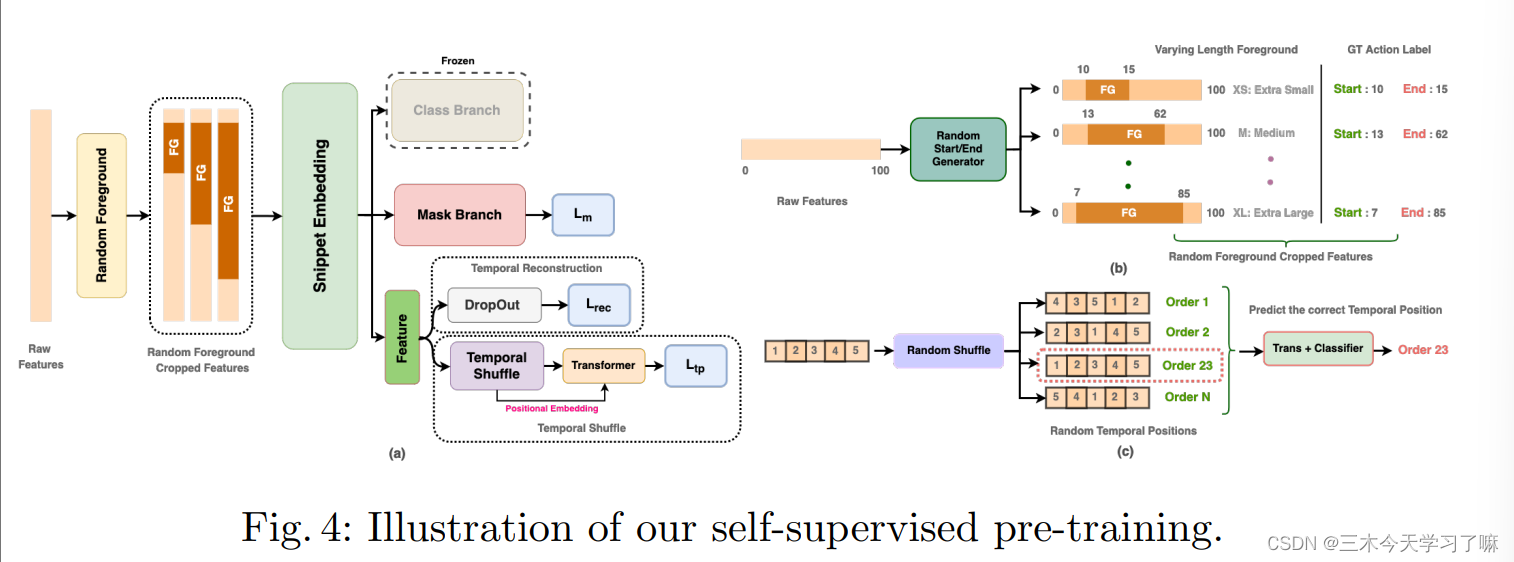
Stage I: Self-supervised pre-training
在video-level特征层面随机选取起止时间不同的特征为前景,剩余部分为背景,并随之将背景特征置0,只保留伪前景。
在获得masked feature sequence后,前置任务旨在同时预测:
1)具有开始和结束的时间遮蔽
2)时间洗牌后每个片段的时间位置
3)片段特征的重建
通过丢弃随机片段,转化器被迫聚合并利用来自上下文的信息来预测丢弃的片段。
该模型可以学习时间语义关系和对TAD有用的鉴别性特征。预训练的语境任务损失被表述为:
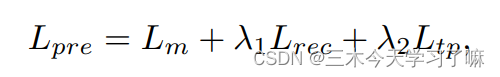
其中, 为mask learning loss, 为feature reconstruction loss, 为temporal position prediction loss。
Stage II: Semi-supervised fine-tuning:
Pseudo class label:
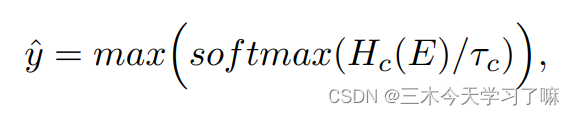
Pseudo mask label:
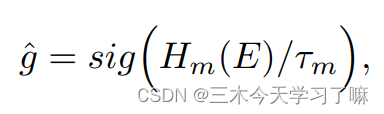
使用伪标签和真实标签来最小化目标函数:
classifcation stream
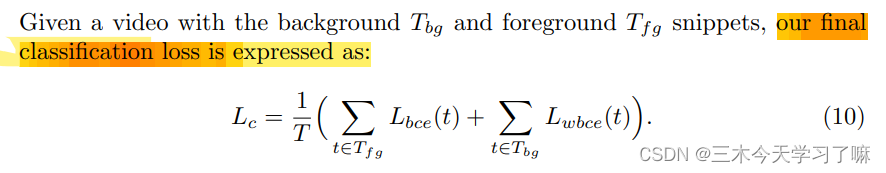
mask stream