前言
生存分析对应于一组统计方法,用于调查感兴趣事件发生所花费的时间。生存分析被用于各种领域,例如:癌症研究为患者生存时间分析,“事件历史分析”的社会学在工程的“故障时间分析”。在癌症研究中,典型的研究问题如下:某些临床特征对患者的生存有何影响?个人三年存活的概率是多少?各组患者的生存率有差异吗?
目标:
本文的目的是描述生存分析的基本概念。在癌症研究中,大部分生存分析使用以下方法:Kaplan-Meier绘制可视化生存曲线对数秩检验比较两组或更多组的生存曲线Cox比例风险回归来描述变量对生存的影响。
安装并加载所需的R包我们将使用两个R包:生存计算生存分析survminer的总结和可视化生存分析结果安装软件包
install.packages(c("survival","survminer"))
library("survival")
library("survminer")
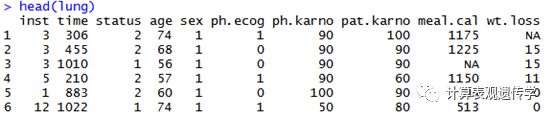
示例数据集,我们将使用生存包中提供的肺癌数据。
data("lung")
计算生存曲线:survfit()
例如我们要按性别来计算生存概率。
函数survfit()可以被用来计算Kaplan-Meier存活估计。其主要论点包括:
使用函数Surv()创建的生存对象和包含变量的数据集。
fit<-survfit(Surv(time,status)~sex,data=lung)

默认情况下,函数print()显示生存曲线的简短摘要。它显示观察次数,事件数量,中位数生存和中位数的置信限。如果要显示生存曲线的更完整摘要:
summary(fit)
可视化生存曲线:
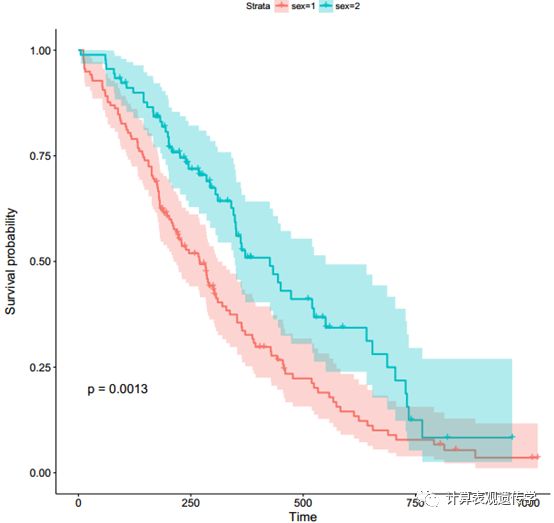
我们将使用函数ggsurvplot()(在SurvminerR软件包中)来生成两组受试者的生存曲线。命令如下:
ggsurvplot(fit,risk.table=T,pval =T,conf.int = T)
risk.table表示风险个体的数量和/或百分比。risk.table允许的值包括:指定是否显示风险表的TRUE或FALSE。默认值是FALSE。
使用参数conf.int = TRUE的幸存函数的95%置信区间。
Log-Rank测试的p值使用pval = TRUE比较组。

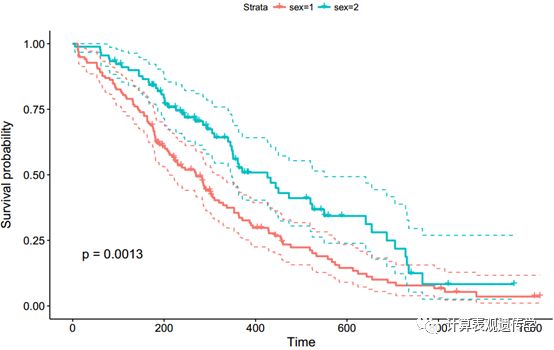
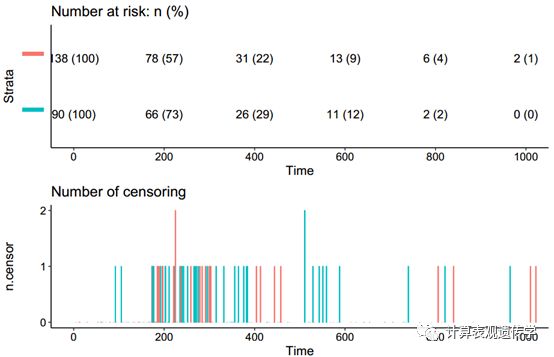
也可以进一步定制使用以下参数:
conf.int.style =“step”改变置信区间带的样式。
xlab更改x轴标签。
break.time.by = 200在时间间隔中将x轴断开200。
risk.table =“abs_pct”显示绝对数量和风险个体的百分比。
risk.table.y.text.col = TRUE和risk.table.y.text= FALSE在风险表的文本注释中提供条而不是名称。
ncensor.plot = TRUE绘制在时间t的审查主题的数量。这是对生存曲线的一个很好的附加反馈,所以人们可以认识到:生存曲线是怎样的,风险集合的数量是多少,风险集合的大小是多少?由事件或审查事件造成的?
legend.labs更改图例标签。
命令如下:
ggsurvplot(fit,pval = T,conf.int =T,conf.int.style ="step",break.time.by = 200,risk.table="abs_pct",risk.table.y.text = FALSE,ncensor.plot = TRUE)
参考文献:
http://blog.sina.com.cn/s/blog_14154cb430102wxah.html
往期「精彩内容」,点击回顾
DNA测序历史 | CircRNA数据库 | Epigenie表观综合 | 癌症定位
BWA介绍 | 源码安装R包 | CancerLocator | lme4 | 450K分析
乳腺癌异质性 | BS-Seq | 隐马模型 | Circos安装 | Circos画图
KEGG标记基因 | GDSC | Meta分析 | R线性回归和相关矩阵
精彩会议及课程,点击回顾