做回归分析时当自变量为类别变量时,我们关注的重点会从预测转向组别差异分析,这种分析法称作方差分析。
9.1 术语速成
组间因子是指每个受测者只接受一个类型的测试,不会接受多种类型的测试,例如每位患者都仅被分配到一个组别中,没有患者同时接受两种治疗方法。
组内因子与组间因子正好相反。比如比较不同时间患者的治疗情况,则时间因子就是组内因子,因为每一位患者都会经历不这两种时间。
均衡设计,不同组间的观测数(样本)相同的设计叫做均衡设计,反之就是非均衡设计。
当设计包含两个甚至更多的因子时,便是因素方差分析设计,比如两因子时被称作双因素方差分析,三因子时被称作三因素方差分析,
非分析的因子叫做混淆因素或者干扰变数,比如从时间和疗法这两个维度分析治疗(对焦虑症的治疗)效果。患者是否有抑郁症(因为抑郁症对焦虑症有影响)这个维度就是干扰变数
疗法和时间都作为因子时,我们即可分析疗法的影响和时间的影响,又可分析疗法和时间的交互影响。前两个被称作主效应,交互部分称作交互效应
9.2 ANOVA模型拟合
虽然ANOVA和回归方法都是独立发展而来,但是从函数形式上看,它们都是广义线性模型的特例。
9.2.1 aov()函数
aov()函数的语法为aov(formula, data=dataframe)
常见研究设计的表达式
单因素ANOVA y~A
含单个协变量的单因素ANCOVA y~x+A
双因素 y~AB
含两个协变量的双因素ANCOVA y~x1+x2+AB
随机化区组 y~B+A(B是区组因子)
单因素组内 y~A + Error(Subject/A)
含单个组内因子(W)和单个组间因子(B)的重复测量ANOVA y~B*W + Error(Subject/W)
表达式中各项的顺序
表达式中的效应的顺序在两种情况下会造成影响:(a)因子不止一个,并且是非平衡设计;(b)存在协变量。
样本大小越不平衡,效应项的顺序对结果的影响越大。
一般来说,越基础性的效应越需要放在表达式前面。具体来讲,首先是协变量,然后是主效应,接着是双因素的交互项,再是三因素的交互项以此类推。
对于主效应越基础的变量越应放在表达式前面
9.3 单因素方差分析
例子
使用来自multcomp包中的cholesterol数据集
50个患者均接受降低胆固醇药物治疗(trt)五中治疗中的一种。其中三种治疗条件使用药物相同,但是每天的用药次数及量不同,剩下的两种方式代表候选药物
> library(multcomp)
> head(cholesterol)
trt response
1 1time 3.8612
2 1time 10.3868
3 1time 5.9059
4 1time 3.0609
5 1time 7.7204
6 1time 2.7139
> attach(cholesterol)
> #各组样本的大小
> table(trt)
trt
1time 2times 4times drugD drugE
10 10 10 10 10
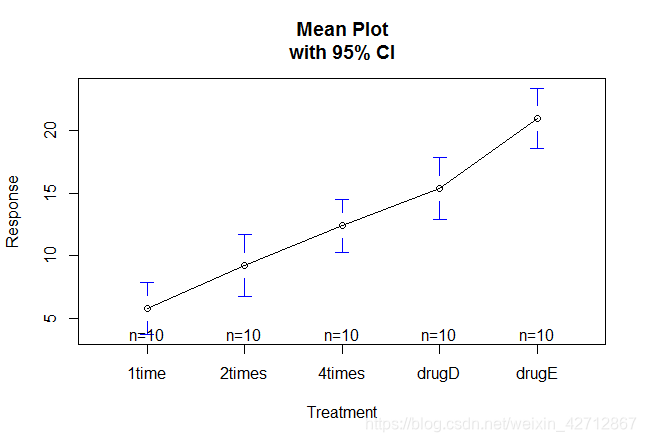
> #各组均值
> aggregate(response,by=list(trt=trt),FUN=mean)
trt x
1 1time 5.78197
2 2times 9.22497
3 4times 12.37478
4 drugD 15.36117
5 drugE 20.94752
> #各组标准差
> aggregate(response,by=list(trt=trt),FUN=sd)
trt x
1 1time 2.878113
2 2times 3.483054
3 4times 2.923119
4 drugD 3.454636
5 drugE 3.345003
> #检验组间差异
> #从结果上看ANOVA对治疗方式的F检验非常显著(p<0.0001),说明五中疗法的效果不同(但是不能显示是哪些治疗方法的效果不同)
> fit <- aov(response~trt)
> summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
trt 4 1351.4 337.8 32.43 9.82e-13 ***
Residuals 45 468.8 10.4
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> #绘制各组均值及置信区间的图形
> library(gplots)
> #plotmeans可以绘制各组的均值点,并画出各组均值的0.95(默认)的置信区间
> plotmeans(response~trt,xlab="Treatment",ylab="Response",
+ main="Mean Plot\nwith 95% CI")
> detach(cholesterol)
>
9.3.1多重比较
ANOVA只能告诉你F检验表明五种药物治疗效果不同,但是没有告诉你哪种治疗与其他治疗不同,多重比较可以解决这个问题。
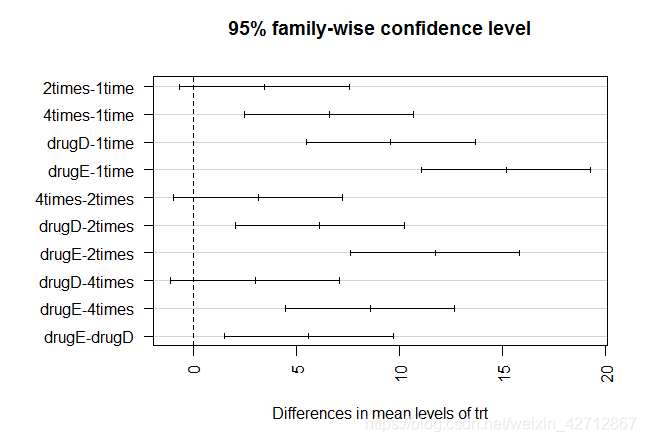
TukeyHSD()函数提供了对各组均值差异的成对检验
> attach(cholesterol)
> fit <- aov(response~trt)
> TukeyHSD(fit)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = response ~ trt)
$trt
diff lwr upr p adj
2times-1time 3.44300 -0.6582817 7.544282 0.1380949
4times-1time 6.59281 2.4915283 10.694092 0.0003542
drugD-1time 9.57920 5.4779183 13.680482 0.0000003
drugE-1time 15.16555 11.0642683 19.266832 0.0000000
4times-2times 3.14981 -0.9514717 7.251092 0.2050382
drugD-2times 6.13620 2.0349183 10.237482 0.0009611
drugE-2times 11.72255 7.6212683 15.823832 0.0000000
drugD-4times 2.98639 -1.1148917 7.087672 0.2512446
drugE-4times 8.57274 4.4714583 12.674022 0.0000037
drugE-drugD 5.58635 1.4850683 9.687632 0.0030633
可以看到1time和2times的均值差异不显著(9=0.138),而1times和4times间的差异非常显著(p<0.001)
图形中置信区间包含0的疗法说明显著不显著(p>0.5)
opar <- par(no.readonly = TRUE)
par(las=2)
par(mar=c(5,8,4,2))
plot(TukeyHSD(fit))
mulcomp包中的glht()函数提供了多重均值比较更为全面的方法,即适用于线性模型,也适用于广义线性模型
代码示例
library(multcomp)
par(mar=c(5,4,8,2))
par(las=1)
#Tukey表示不同类型之间两两比较,参数linfct设置要进行多重比较的分组变量和方法
tuk <- glht(fit, linfct=mcp(trt="Tukey"))
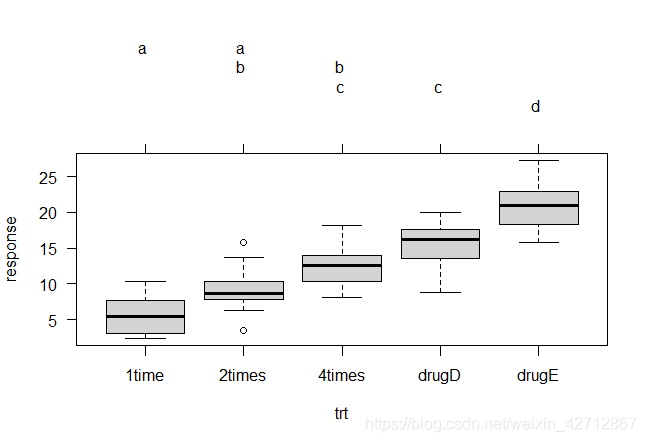
#cld()函数中的level选项设置了使用的显著水平(0.05,即本例中的95%的置信区间)
#有相同字母的组(用箱线图表示)说明均值差异不显著。
#本例中1time和2time不显著(拥有相同的字母a)2times和4times不显著(拥有相同的字母b)
#cld(tuk,level=0.05)返回下图中的字母
> cld(tuk,level = 0.05)
1time 2times 4times drugD drugE
"a" "ab" "bc" "c" "d"
plot(cld(tuk,level = 0.05),col="lightgrey")
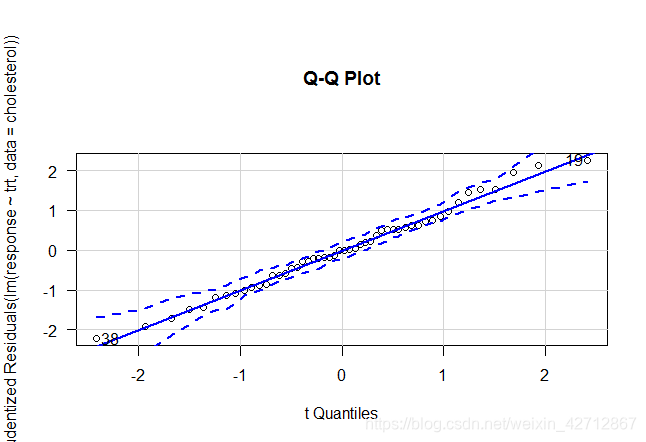
9.3.2 评估检验的假设条件
单因素方差分析中,我们假设因变量服从正态分布,各组方差等。可以使用QQ图来验证正态性假设
> library(car)
> #当simulate=TRUE时,95%的置信区间将会用参数自助法生成
> qqPlot(lm(response ~ trt,data=cholesterol),simulate=TRUE,main="Q-Q Plot",labels=FALSE)
检验方差齐性(使用函数bartlett.test())
bartlett.test(response ~ trt, data=cholesterol)
Bartlett test of homogeneity of variances
data: response by trt
Bartlett's K-squared = 0.57975, df = 4, p-value = 0.9653
> #Bartlett检验表明五组的方差并没有显著的不同(p=0.97)
> #同样可以进行方差齐性的检验还有Fligner-Killeen检验(fligner.test())和Brown-Forsythe检验(HH包中的hov()函数)
> #需要注意的是方差齐性分析对离群点非常敏感。可利用car包中的outlierTest()函数来检测离群点
> library(car)
> outlierTest(lm(response ~ trt,data=cholesterol))
No Studentized residuals with Bonferroni p < 0.05
Largest |rstudent|:
rstudent unadjusted p-value Bonferroni p
19 2.251149 0.029422 NA
#从输出结果来看,并没有证据说明数据含有离群点(当p>1时将产生NA)
#因此根据QQ图,Bartlett检验和离群点的检验。该数据用ANOVA模型拟合的很好
