一、研究背景及问题提出
2023年1月初,B站在港交所公布的业绩报告显示,从2022年第二季度开始,公司合计统计移动应用和PC端的活跃用户。截至2022年9月30日,公司平均月活跃用户为3.33亿人,环比增加2690万人,创下历史新高;同期平均日活跃用户9030万人,同比增长25%,环比二季度增长680万人。相比其他长视频平台,多次出圈之后的B站,用户增长尚未遭遇瓶颈。但是相对于,不同的up主的收入也有很大的差别,不同的up主在B站的播放收入都是存在差别的。因此,需要使用聚类的方法对up主进行了一个划分。
二、研究目标与意义
本次分析使用了80个体育的up主的"播放量",“投币”,“点赞”,“收藏”,“分享"这五列数据进行聚类。分别展示每个类别的视频平均的"播放量”,“投币”,“点赞”,“收藏”,"分享"等相关数据信息。对于,想做b站的up主来说,可能会产生一定的价值。
三、研究思路
在数据分析中,首先先对相关的特征进行描述分析,然后绘制肘部图,用来确定最佳聚类簇数目。主要采用了Kmean聚类,对不同的结果绘制了五张密度图,分别展示每个类别的视频平均的"播放量",“投币”,“点赞”,“收藏”,“分享”,最后将聚类后的结果保存起来
四、数据收集
数据是给出的 80 个 b 站运动类 up 主的基本数据,主要是2022 年 2 月 26 日获取的 Fitness_up.csv 数据表,baseinfo_标签——up 主基本数据,多余的列选择直接删除。
用"播放量",“投币”,“点赞”,“收藏”,"分享"这五列数据进行聚类筛选。
最终数据集一共有6 列,28501行组成的数据框

五、研究内容
对整理的数据集进行数据描述性统计分析,主要计算发布的视频数量,播放量",“投币”,“点赞”,“收藏”,"分享的平均值


求汇总的数据进行一个描述性统计分析,主要计算出平均值,标准差和中位数

其中一共有80个up主,然后平均每一个up主发布的视频数量是356个,平均的播放量是426445,平均投币是7583,平均点赞是19676,平均收藏是16775,平均分享是2492.6。
基于80个up主各项指标的平均值,绘制肘部图,用来确定最佳聚类簇数目
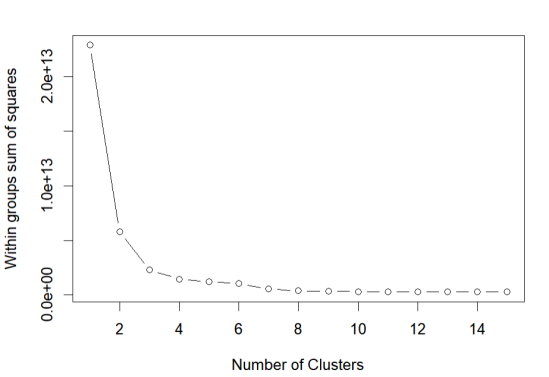
画出组内的平方和和提取的聚类个数的对比。从一类到三类下降得很快(之
后下降得很慢),建议选用聚类个数为三的解决方案。

接下来使用kmean聚类的方法,设置聚类的个数是3。对up主进行划分,然后求出不同聚类中的平均的"播放量",“投币”,“点赞”,“收藏”,“分享”
从结果来看,聚类1 应该是发布视频比较少,播放量,投币,点赞, 收藏,分享属于中等的水平。聚类2应该是发布视频比较多,播放量,投币,点赞, 收藏,分享属于低的水平。聚类3 应该是发布视频比较少,播放量,投币,点赞, 收藏,分享属于高的水平。
基于划分的结果,分别绘制密度图。

代码
library(tidyverse)
up <- read_csv("Fitness_up.csv") %>% select(baseinfo_id,baseinfo_name)
Video <- read_csv("CombineBiliUpVideo.csv")
## 筛选 "播放量","投币","点赞","收藏","分享"这四列聚类
df <- Video %>% select("播放量","投币","点赞","收藏","分享","up_name")
df$播放量 <- as.numeric(df$播放量)
data <- merge(df,up,by.x = "up_name",by.y = "baseinfo_name" )
res <- data %>%
group_by(baseinfo_id) %>%
summarise(视频数量 = n(),
平均播放量 = mean(播放量,na.rm = TRUE),
平均投币 = mean(投币,na.rm = TRUE),
平均点赞 = mean(点赞,na.rm = TRUE),
平均收藏 = mean(收藏,na.rm = TRUE),
平均分享 = mean(分享,na.rm = TRUE))
library(psych)
result <- describe(res)[2:5]
result
wssplot <- function(data, nc=15, seed=1234){
wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:nc){
set.seed(seed)
wss[i] <- sum(kmeans(data, centers=i)$withinss)}
plot(1:nc, wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares")}
wssplot(na.omit(res[-1]))
r <- na.omit(res)
km <- kmeans(r[-1],3)
r$cluster <- paste0("cluster",km$cluster)
r %>%
group_by(cluster)%>%
summarise(平均视频数量 = mean(视频数量),
平均播放量 = mean(平均播放量),
平均投币 = mean(平均投币),
平均点赞 = mean(平均点赞),
平均收藏 = mean(平均收藏),
平均分享 = mean(平均分享))
r %>% ggplot(aes(视频数量,fill =cluster) ) + geom_density() + theme(legend.position = "top")
r %>% ggplot(aes(平均播放量,fill =cluster) ) + geom_density()+ theme(legend.position = "top")
r %>% ggplot(aes(平均投币,fill =cluster) ) + geom_density()+ theme(legend.position = "top")
r %>% ggplot(aes(平均点赞,fill =cluster) ) + geom_density()+ theme(legend.position = "top")
r %>% ggplot(aes(平均收藏,fill =cluster) ) + geom_density()+ theme(legend.position = "top")
r %>% ggplot(aes(平均分享,fill =cluster) ) + geom_density()+ theme(legend.position = "top")
write.csv(r,"聚类结果.csv",row.names = FALSE)