更多内容详情请点击查看数据可视化 | 没错!在 Python 中也能像 ggplot2 一样绘图
目录
Part 1 引言
正所谓 “一图抵千言”,优秀的数据可视化能够帮助你洞悉蕴含在数据中的现象和规律。当我们谈到数据可视化时,就一定会提到数据可视化领域的佼佼者——R 语言,尤其是 R 语言中的ggplot2包,ggplot2中的 gg 表示图形语法(grammar of graphic),这个包的开发理念就是使用“语法”来绘图。笔者了解过它的强大的功能,同时也感慨在 Python 中是否有类似的功能呢?
答案是肯定的,如果你更加擅长使用 Python 并且对可视化的功能有一些要求,那么plotnine库就是一个很好的选择,它几乎可以说是ggplot2的 Python 版本,其语法和ggplot2大体相同。plotnine库是 Hassan Kibirige 基于matplotlib、pandas等库开发的,开发者的目的是为 Python 用户提供一个简单灵活且强大的绘图库。使用plotnine库,我们就可以利用ggplot2的核心概念,如图层、映射,来创建各种类型的图表。 下面我们向大家介绍plotnine这个库的基本用法,并且给出两个基于该库绘制的实例的详细过程。
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写。
Part 2 强大的 plotnine 库
plotnine库与底层matplotlib库复杂的绘图规则不同,图形语法的引入使得plotnine的绘图代码的风格更加优雅、规则化,我们可以按照逻辑顺序构建图形;同时,由于该库使用图层系统来构建图形,我们可以更加灵活地创建各种类型的图表,并且进行自定义设置。
下图展示几张我们使用plotnine库绘制的多种类型的数据可视化图。
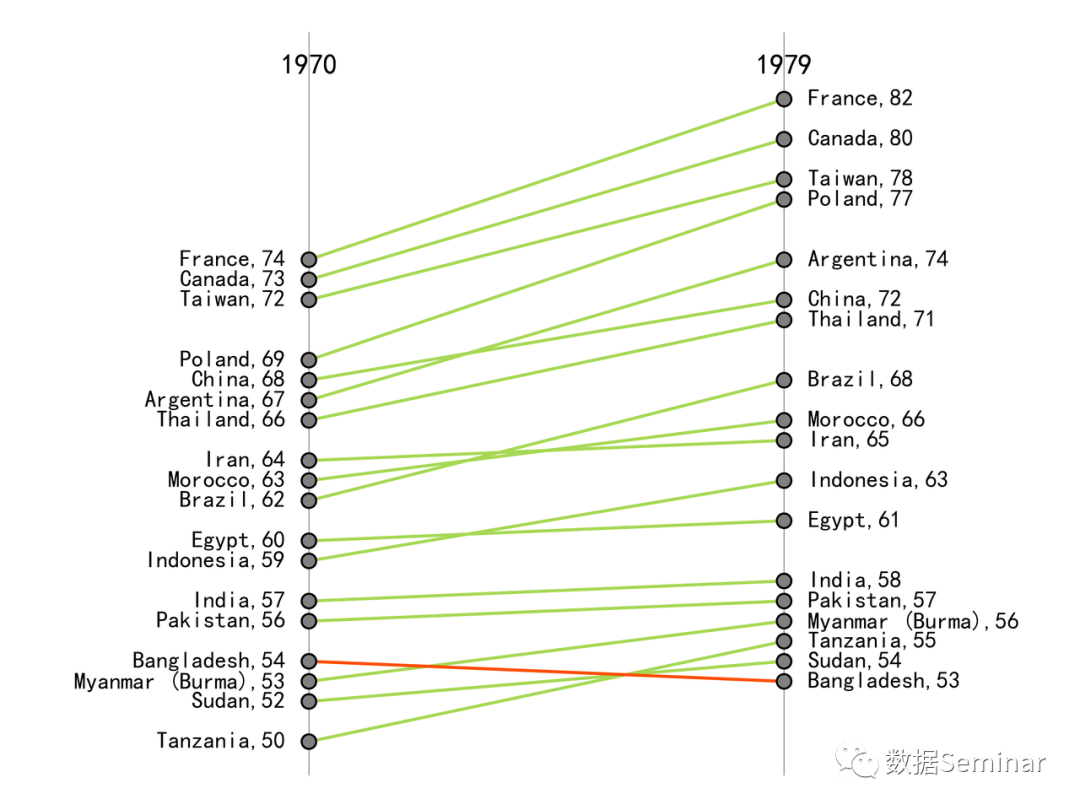
图1 坡度图
图2 小提琴图
图3 核密度估计图
图4 百分比堆积柱状图
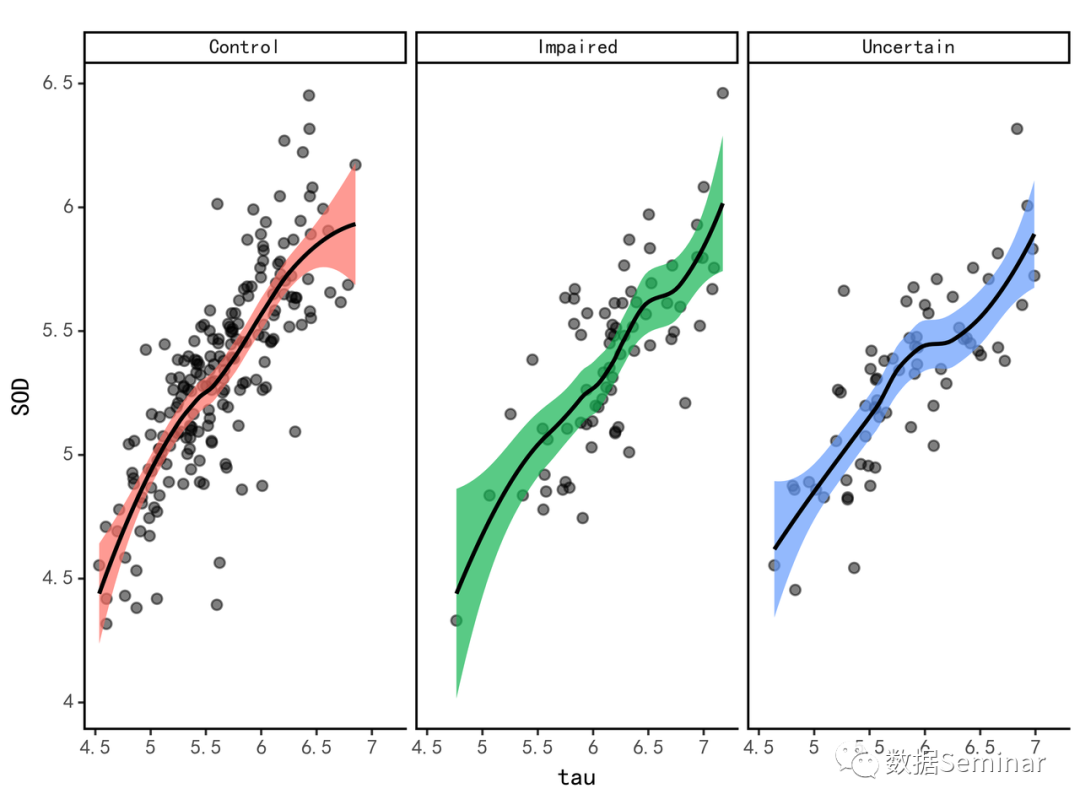
图5 列分面带拟合曲线的散点图
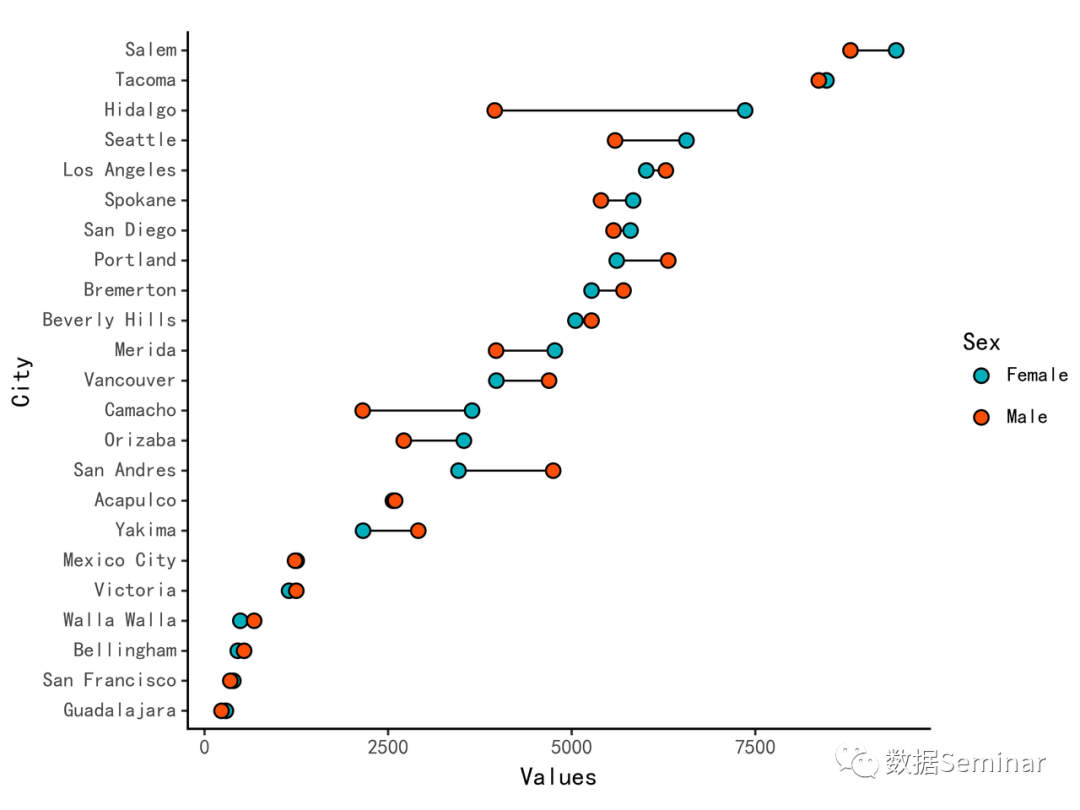
图6 哑铃图
上图呈现了六种类型的可视化图形,虽然它们的类别不同,但本质都是使用图形语法绘制而成,代码的逻辑是一致的。在plotnine库中,所有的图表都是由图层叠加而成,各个图层之间用加号(+)连接,这也是其绘图语法非常流畅、可读性更高的原因。
由于篇幅原因,我们着重介绍如何绘制如下所示的哑铃图和坡度图,并在这个过程中说明如何使用plotnine库实现数据可视化。
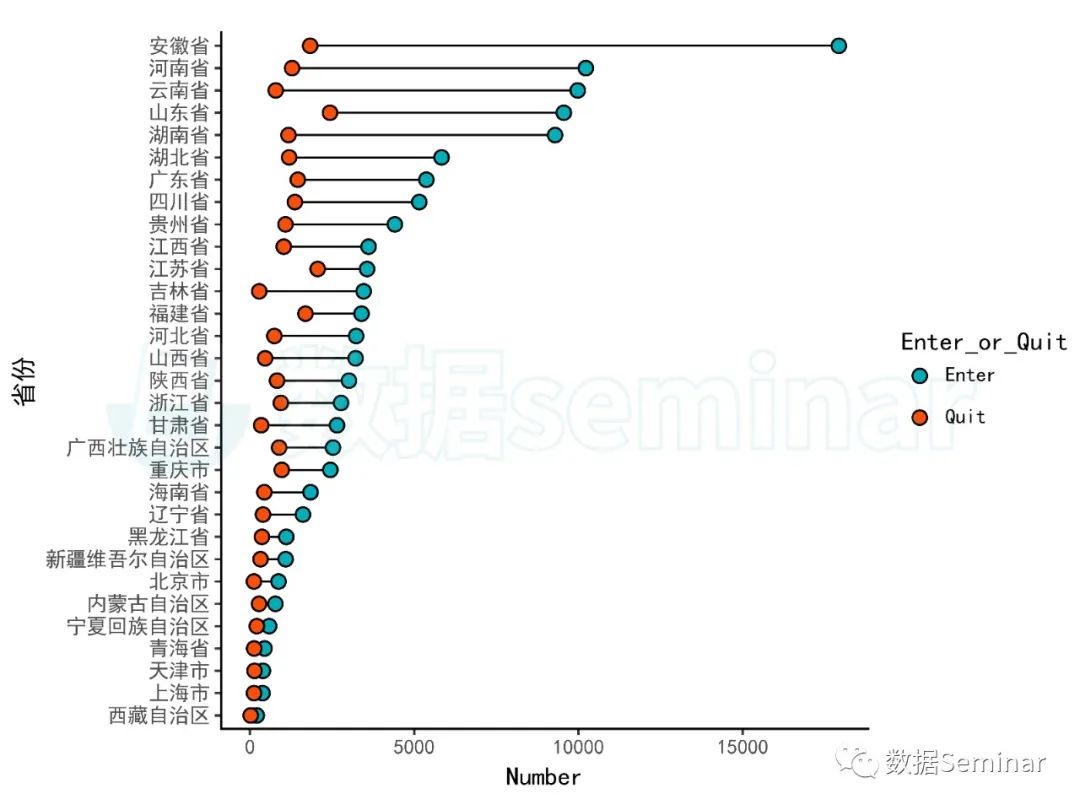
图7 哑铃图示例
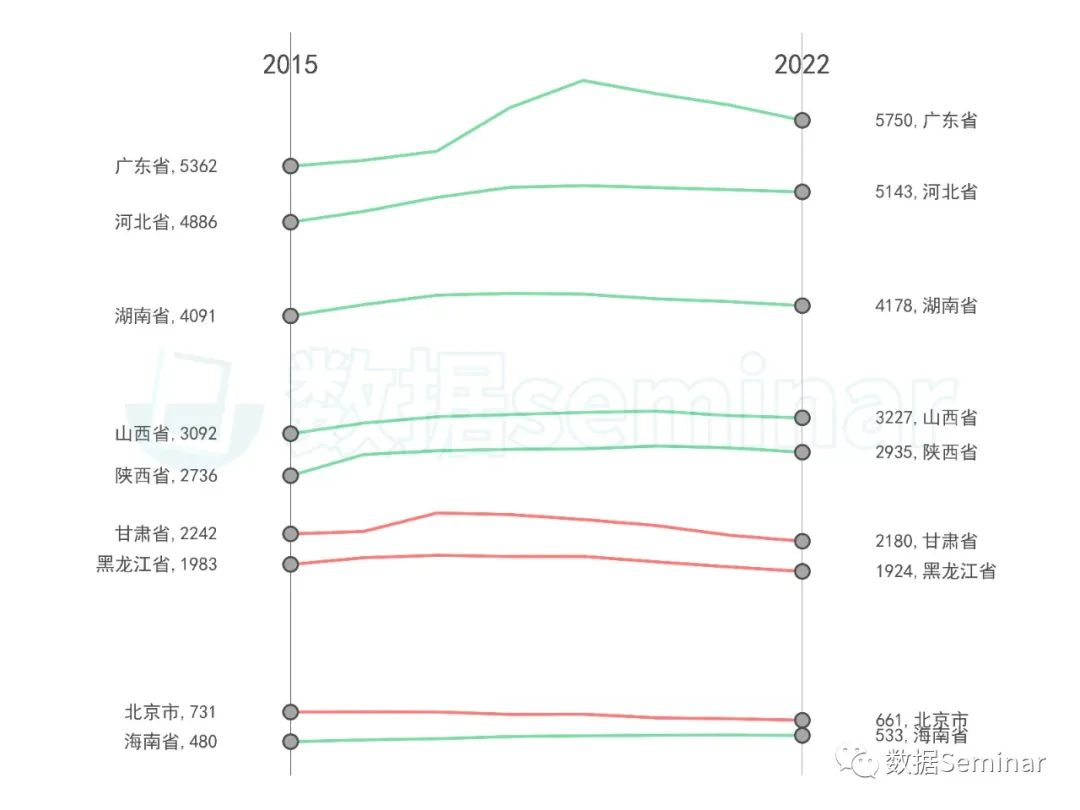
图8 坡度图示例
首先,我们需要了解通过哑铃图和坡度图能够分别给我们呈现数据的什么信息?
哑铃图(Dumbbell plot)是展示数据差异的可视化图表之一,适用于比较两个不同群体之间的差异或变化,比如显示两个时间点或两个组别的比较情况。哑铃图的形状类似于哑铃,两端是两个圆圈,中间的连线是一个线段,线段代表两个群体之间的差距,而圆圈代表每个群体的具体数值。哑铃图可以将两个群体的数据进行对比,从而直观地看出同一分类下两个群体之间数据的差异。
坡度图(slope chart)可以看成是一种多分组下的折线图。在组别较多的时候,传统折线图会由于折线的重叠而出现线条难以区分、组别易混淆的问题;而坡度图强调了每条折线的起点和终点,大大降低了因分组增加而出现的视觉混乱,同时坡度图保留了传统折线图的作用,每一组的两个端点间的折线可以很好的反应数据的变化过程和趋势。
在绘制图形之前,我们先来了解plotnine库绘图的基础知识(如需略过基础部分,可以转至第四章)。
Part 3 plotnine 数据可视化基础
1、图形语法
首先,我们来看一下plotnine库绘图的底层逻辑。图形语法具有两大特点:第一,使用图层绘图的设计方式,在绘图过程中将一幅复杂的图表拆分成多个图层,从ggplot()函数开始,将各个图层使用加号(+)连接,越往后的图层位置越靠上。第二,数据可视化的核心是数据,使用图形语法可以在绘图时把数据和图形细节分开处理,单独定义图形细节,这种分离方法使得绘图更加灵活,在调整完数据格式之后,我们只需要专注于图形的外观和呈现方式,而不必再次考虑数据的处理和转换。
plotnine绘图时需要输入的必要信息如下:
-
ggplot(data, mapping = aes()):最底层函数,标志着绘图的开始。其中参数data表示使用的数据,一般是 DataFrame 格式;参数mapping表示绘图中默认的美学映射,使用 aes() 的格式指定,可以用来表示变量,控制颜色、大小等等。 -
geom_*()或stat_*():前者表示几何图形,后者表示统计变换,两者都可以创建一个图层。 使用geom_*()可以绘制大部分图表,如geom_point()可以绘制散点图,geom_line()可以绘制折线图等等。在geom_*()中也可以通过设置参数stat来实现统计变换,该参数的默认值是不变换。使用stat_*()会根据函数作用实现统计变换,此时必须在参数geom中指定要绘制的图表类型。
需要注意的是,成对出现的geom_*()和stat_*()函数实现的效果通常是一致的,比如:
# 1. 使用 geom_*() 并指定参数 stat
(ggplot(df, aes(x='class', y='value')) +
geom_point(stat='summary', ……))
# 2. 使用 stat_*() 并指定参数 geom
(ggplot(df, aes(x='class', y='value')) +
stat_summary(geom='point', ……))
以上代码实现的功能一致,两者都表示绘制的图表类型为散点图,统计变换方式为 summary。
既然功能一致为何要将两者区分开呢?这看似多此一举,实际上是两者的侧重点不同。geom_*()指定了绘制的图表类型(如geom_point()表明绘制散点图),在这一确定类型下可以通过指定不同的统计变换方式来得到不同的散点图,即这一类函数的侧重点是几何图形;stat_*()指定了统计变换方式(如stat_summary()表明根据变量 x 汇总),在这种统计变换下可以通过指定不同的几何图形来得到不同类型的图表,即这一类函数的侧重点是统计变换。
此外,plotnine绘图也可以输入一些可选信息,如下表:
| 可选信息 | 作用 |
|---|---|
scale_*() |
设置度量,控制从数据到美学映射的尺度。这一类函数接收并调整数据以适应视觉感知的不同方面,如长度、颜色、大小和形状等。 |
theme() |
设置主题,主要用于调整图表的细节,如背景、网格线、色彩等。 |
coord_*() |
设置坐标系,需要注意一点,与 ggplot2 不同,plotnine 目前只支持笛卡尔坐标系,不支持实现极坐标系和地理空间坐标系。 |
2、美学映射参数
我们在上节介绍图形语法时,提到了ggplot()等函数中一个重要的参数mapping = aes(),这个参数代表了可视化中从数据到美学的映射关系,是可视化的核心。从数据到美学的映射关系以各种参数的形式包含在 aes() 中,plotnine提供了大量美学映射参数,可以灵活地实现用户的各种绘图需求,常用的美学映射参数如下表:
| 美学映射参数 | 作用 |
|---|---|
x |
设置 x 轴的数据 |
y |
设置 y 轴的数据 |
color |
设置点、线和填充区域轮廓的颜色 |
fill |
设置填充区域的颜色 |
alpha |
设置色彩透明度,取值介于0-1,0 表示完全透明,1 表示完全不透明 |
shape |
设置点的形状 |
linetype |
设置线的类型 |
size |
设置对象的尺寸 |
参数shape的选择有很多,常用的是shape='o'绘制圆形点,其他常见选择如下表:
| 符号 | 点的形状 |
|---|---|
. |
点(point marker) |
, |
像素点(pixel marker) |
s |
正方形(square marker) |
p |
五边星(pentagon marker) |
* |
星型(star marker) |
参数linetype常见的一些选择如下表:
| 符号 | 线的类型 |
|---|---|
blank |
白线 |
solid |
实线 |
dashed |
短虚线 |
dotted |
点线 |
值得注意的是,美学映射参数在不同的函数中可能是不通用的,比如使用geom_point()绘制散点图时设置参数linetype自然是无效的。
由于可视化涉及内容很多,本文无法面面俱到,更多的是帮助读者入门图形语法可视化,如有更进一步的绘图需求,可以查阅 plotnine 的官方文档。
Part 4 使用 plotnine 实现数据可视化
基本内容我们已经上文中已经介绍,现在我们来看如何使用 plotnine 绘制哑铃图和坡度图。
1、哑铃图
本节使用的数据为“2022 年各省绿色农业企业数量统计.xlsx”,该数据包含31个省份(直辖市)绿色农业企业进入数量和退出数量,使用 WPS 打开后如下图所示:
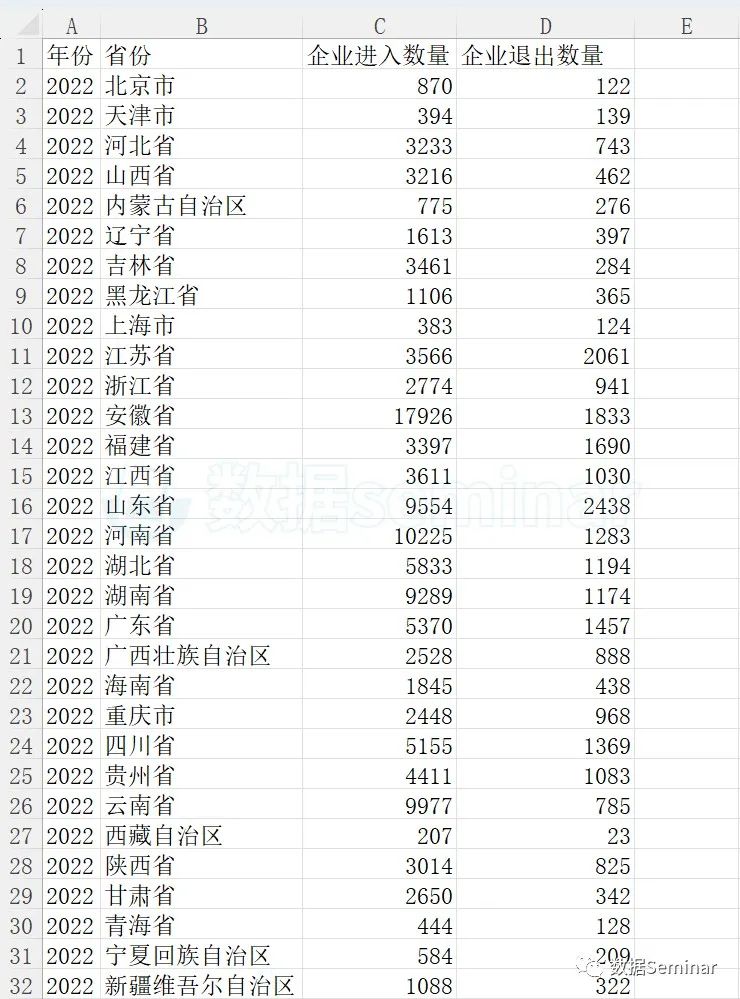
该数据来源于浙大卡特-企研中国涉农研究数据库(CCAD),如需了解更多详情请前往
https://r.qiyandata.com/data_centre/CCAD
“
2022 年各省绿色农业企业数量统计.xlsx”来源于CCAD中的“涉农主体-特色统计库”。CCAD(全称:浙大卡特-企研中国涉农研究数据库)是由企研数据携手浙江大学中国农村发展研究院(简称“卡特”)共同发起,为助力国家乡村振兴发展战略,服务“三农”及相关领域学术研究及智库建设而倾力打造的涉农研究大数据库。>>>点此查看CCAD更多介绍
首先,我们导入数据并将数据按照“企业进入数量”字段的升序排序,使用函数pd.categorical()将“省份”字段转换为 Categorical (分类)类型,代码如下:
df = df.sort_values(by='企业进入数量', ascending=True)
# pd.categorical(values, categories=None, ordered=None)
df['省份'] = pd.Categorical(df['省份'], categories=df['省份'], ordered=True)
pd.categorical()的参数values表示要转换为分类类型的数据,可以是一个列表、数组或Series,参数categories用于指定类别,如果不指定,则根据数据中的唯一值自动创建;参数ordered用于指定分类类型是否有序。
由于绘图时需要将企业进入数量和退出数量映射到色彩填充中,因此需要将原先的宽表数据转换为长表,代码如下:
df = pd.melt(df, id_vars=['省份', '年份'], var_name='Enter_or_Quit', value_name='Number')
df['Enter_or_Quit'] = df['Enter_or_Quit'].map(lambda x: 'Enter' if x == '企业进入数量' else 'Quit')
至此,我们完成了对原始数据的处理。下面开始绘图操作,代码如下:
plot = (# 基础图层, 指定数据并设定默认的美学映射参数
ggplot(df, aes(x='Number', y='省份', fill='Enter_or_Quit')) +
# 绘制几何对象
geom_line(aes(group='省份')) +
geom_point(shape='o', size=3, color='black') +
scale_fill_manual(values=('#00AFBB', '#FC4E07')) +
# 调整主题和细节
theme_classic() +
theme(text=element_text(family='SimHei')))
print(plot)
-
ggplot()函数定义了基础图层,标志着绘图开始,设定“Number”字段作为 x 轴,“省份”字段作为 y 轴,“Enter_or_Quit”字段映射到色彩填充; -
geom_line()函数绘制了折线图层,在这一层中美学映射参数group指定为“省份”字段,于是将按照“省份”的内容绘制多条折线; -
geom_point()函数绘制了散点图层,形状为圆形,大小为 3,轮廓黑色; -
scale_fill_manual()函数设定了填充度量,参数values指定了“Enter_or_Quit”字段映射到色彩填充后的具体颜色,'#00AFBB'和'#FC4E07'是 16 进制颜色码,到这里我们绘制的几何对象就完成了。
数据可视化的配色其实是非常重要的一环,同样涉及很多内容,介于篇幅有限,在此不作赘述。我们推荐两个网站,有兴趣的读者可以参考学习有关配色的知识:
十六进制颜色码介绍:https://www.mathsisfun.com/hexadecimal-decimal-colors.html
在线调色模拟:http://www.ku51.net/color/rgb.html
最后两行代码中的函数theme_classic()表示使用经典主题、函数theme(text = element_text(family = 'SimHei'))进一步设置了主题的细节。由于绘图元素中涉及中文字符,因此应该指定图表中的字符使用黑体,否则将不能正常显示。现在我们得到绘制的图表结果如下图所示:
上图中红色的散点代表退出的绿色农业企业数量,蓝色的散点代表进入企业数量,连接两者的线段代表进入企业与退出企业的差值,在这幅图中表示的是 2022 年省份净增加的绿色农业企业。通过这个哑铃图,我们可以非常清晰地看出,安徽省、河南省、云南省和湖南省等省份绿色农业企业的净增加值位于全国前列;西藏自治区、上海市、天津市和青海省等省份(直辖市)的绿色农业企业进入数量和退出数量都处于较低水平。
2、坡度图
本节使用的数据为“历年各省农村金融机构网点数量统计.xlsx”,该数据包含 9 个省份 2015 年至 2022 年农村金融机构网点数量,使用 WPS 打开后如下图所示:
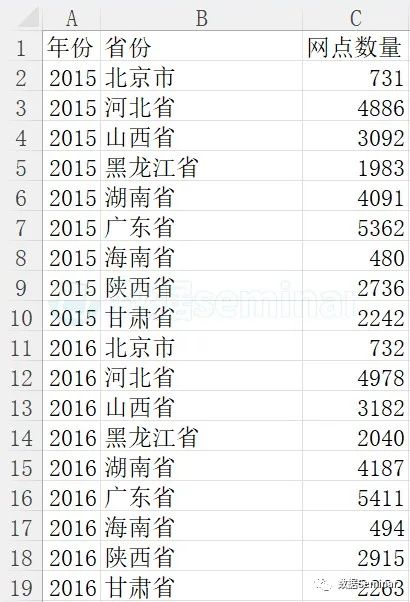
该数据来源于浙大卡特-企研中国涉农研究数据库(CCAD),如需了解更多详情请前往
https://r.qiyandata.com/data_centre/CCAD
“
历年各省农村金融机构网点数量统计.xlsx”来源于CCAD中的“农村金融”子库。CCAD(全称:浙大卡特-企研中国涉农研究数据库)是由企研数据携手浙江大学中国农村发展研究院(简称“卡特”)共同发起,为助力国家乡村振兴发展战略,服务“三农”及相关领域学术研究及智库建设而倾力打造的涉农研究大数据库。>>>点此查看CCAD更多介绍
由于该数据本身是一份长表数据,在后续的绘图中我们想要将数量增加的省份表示的折线,和数量减少的省份表示的折线用不同颜色来区分,因此需要先将原始数据转换为短表数据,根据 2015 年和 2022 年的农村金融机构网点数量构建一个“up_or_down”字段,再转换回长表:
df = pd.read_excel('.\\Data\\历年各省农村金融机构网点数量统计.xlsx')
# 将原数据转换为短表
df = pd.pivot(df, index='省份', values='网点数量', columns='年份')
df.reset_index(inplace=True)
df.columns
df.columns = ['省份', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']
# 增加一个用于线条颜色分类的字段
df['up_or_down'] = df.apply(lambda x: 'Increase' if x['2015'] < x['2022'] else 'Decrease', axis=1)
# 将数据转换回长表
df = pd.melt(df, id_vars=['省份', 'up_or_down'], var_name='年份', value_name='网点数量')
df['年份'] = df['年份'].astype('int32')
由于我们需要在绘制的图形的两端显示起始年份和最终年份的数量,因此需要先将标注的内容提取出来并储存在变量中,代码如下:
left_label = df.apply(lambda x: x['省份'] + ',' + str(x['网点数量']) if x['年份'] == 2015 else '', axis=1)
right_label = df.apply(lambda x: str(x['网点数量']) + ',' + x['省份'] if x['年份'] == 2022 else '', axis=1)
left_point = df.apply(lambda x: x['网点数量'] if x['年份'] == 2015 else np.nan, axis=1)
right_point = df.apply(lambda x: x['网点数量'] if x['年份'] == 2022 else np.nan, axis=1)
至此,我们的原始数据已经处理完成,下面开始绘图操作。
由于坡度图的细节比哑铃图多,因此代码实现的过程会比上一节复杂,但是绘制的原理仍然是多个图层的叠加,理解并不难。实现代码可以分为三个部分:绘制几何对象、标注文字内容以及调整主题和细节(这里是限于篇幅长度,实际使用可以合并为完整的代码),这里顺便提及plotnine的另一个小优点,由于在图形语法中各个图层用+连接,因此可以将很长的代码拆开编写,或者在图表制作完成后继续用+添加新的细节。代码如下:
# 第一部分:绘制几何对象
plot = (# 基础图层, 指定数据并限制 y 轴长度
ggplot(df, aes(yend=max(df['网点数量'])*1.02)) +
# 绘制几何对象
geom_line(aes(x='年份', y='网点数量', group='省份', color='up_or_down'), size=0.75) +
scale_color_manual(values=('#FF4040', '#43CD80')) +
geom_vline(xintercept=2015, linetype='solid', size=0.1) +
geom_vline(xintercept=2022, linetype='solid', size=0.1) +
geom_point(aes(x='年份', y=left_point), size=3, shape='o', fill='grey', color='black') +
geom_point(aes(x='年份', y=right_point), size=3, shape='o', fill='grey', color='black') +
xlim(2012, 2025))
第一步是完成几何对象的绘制。我们仍然使用ggplot()函数绘制基础图层,在其中指定使用的数据,并在美学参数中使用参数yend设置 y 轴的上限为“网点数量”最大值的 1.02 倍;
geom_line()函数绘制了折线图层,我们使用“省份”字段分组,将“up_or_down”映射到线条的色彩上,之后用scale_color_manual()指定了具体的颜色;
接下来两次使用geom_vline()函数在 x=2015 和 x=2022 的位置绘制了两条垂直于 x 轴的竖线,线条类型是实线;然后两次使用geom_point()函数以散点的形式绘制了左侧端点和右侧端点,最后一行代码xlim()指定了 x 轴的范围,这里设定 x 轴的范围是 2012 ~ 2025,比原始数据范围稍宽,更利于放置两侧的标注内容。至此,几何对象的绘制就完成了。
第二步是标注文字内容。代码如下:
# 第二部分:添加文字描述
plot = (plot +
geom_text(label=left_label, x=2014, y=df['网点数量'], size=8, ha='right') +
geom_text(label=right_label, x=2023, y=df['网点数量'], size=8, ha='left') +
geom_text(label='2015', x=2015, y=max(df['网点数量'])*1.02, size=12) +
geom_text(label='2022', x=2022, y=max(df['网点数量'])*1.02, size=12))
上面代码中,前两次使用函数geom_text()是用来添加两侧的文本标签,其中参数ha的作用是定义对齐方式,左侧标签设置为右对齐,右侧标签设置为左对齐,标签的 x 坐标分别比 2015 和 2022 差 1,y 坐标与散点的 y 坐标相等;后两次使用函数geom_text()添加的是左右两侧竖线代表的时间,其 y 坐标位于 y 轴的上限。
第三步我们使用theme_void()指定使用简明主题。代码如下:
# 第三部分:调整主题和细节
plot = (plot +
theme_void() +
theme(panel_background=element_rect(fill="white"),
legend_position='none',
axis_text=element_blank(),
axis_title=element_blank(),
axis_ticks=element_blank(),
text=element_text(family='SimHei')))
上面代码中,函数theme()中的参数panel_background指定背景为白色,参数legend_position指定不显示图例,axis_text、axis_title和axis_ticks三个参数分别控制坐标轴的标签、标题和刻度线,这里都指定为不显示。最终,我们得到绘制的图表如下图所示:
在这个坡度图中,绿色的折线代表从 2015 年到 2022 年间农村金融机构网点数量增加的省份,红色代表数量减少的省份,端点间的连线代表农村金融机构网点数量的变化情况。
Part 5 总结
想必经过本文的学习,你应该体会到plotnine库的强大之处,plotnine库的出现很大程度上强化了 Python 的数据可视化功能,掌握plotnine的图形语法、图层式绘图思维可以帮助我们优雅、精确的实现数据可视化。当然,笔者认为数据可视化易学难精,考虑篇幅原因,一些细节部分本文也不能一一呈现,我们希望这篇文章能够激发各位读者的兴趣,给大家的数据可视化工作带来一些帮助。下期再见。

