一个好的可视化例子
各国家都喜爱哪些宠物?
by La Nación
作品地址

该作品于2017年10月14日发表在《阿根廷国家报》上,并获得了2018凯度信息之美奖艺术、娱乐与文化类奖项。该作品以GFK研究所对22个国家的网民进行的调查为基础。
从该作品的图表类型来看,可视为簇状条形图。创作者采用人物和宠物的卡通形象巧妙地替代条形图,极具趣味也不失直观性,受众能够从中获知的信息也比较充实,比如:鱼在中国比其他地方更受欢迎,而猫是法国人最喜欢的宠物,其他国家的人们大多最喜欢狗;阿根廷和巴西的毛绒和羽毛宠物的喜欢人数多于其他国家。该作品较好地符合了“一张好的图表应具有的基本特征”:
- 显示数据:动物卡通图片上标注了该动物受国民喜爱的占比,并用虚线标注了该占比数值在x轴上的刻度位置。
- 让读者将注意力集中在图表内容上,而不是制作程序上。总体来说该作品所要表达的信息比较明了直接,创意点也是图表内容的一部分,既吸引了读者的注意力,又突出了图表内容。
- 避免歪曲:坐标轴标度合适,信息表达直观准确。
- 强调数据间的比较:对不同动物采取对比鲜明的色彩,使得无论是同一国家不同宠物之间的比较,还是不同国家间的比较都得到很好的突出。
- 服务于一个明确的目的:该作品的目的在于展示研究者对各国国民的宠物偏好的调查结果。
- 有对图表的统计描述和文字说明:图中缺少具体的描述和说明,但该作品作为报刊插图,配合文章内容可被较好地理解。
数据可视化的实现
使用来自北大国家发展中心的数据中的数据表demographic_background,选取其中的三个变量进行研究:
- 年龄,定量变量。部分空值通过(调查年份-出生年份) 进行填补。
- 最高学历,定性变量。
- 婚姻状态,定性变量。
数据导入与处理:
library(foreign)
#导入数据
db_all<-read.dta("D:/4数据集四:北大国家发展中心数据/demographic_background/demographic_background.dta")
#选择变量
db_data<-data.frame(age=db_all$ba004,edu=db_all$bd001,mrg=db_all$be001)
#利用出生年份计算受访者受访时的年龄以填补缺失
db_data$age[is.na(db_data$age)]<-(2012-db_all$ba002_1)[is.na(db_data$age)]
#查看数据缺失情况
library(mice)
md.pattern(db_data,plot=F)
数据缺失情况如下:
## age mrg edu
## 17650 1 1 1 0
## 23 1 1 0 1
## 1 1 0 1 1
## 8 1 0 0 2
## 2 0 1 1 1
## 21 0 0 0 3
## 23 30 52 105
在填补后的数据中,绝大多数记录不存在缺失。将仍存在缺失的记录移除,得到17650条完整记录。
单变量制图:
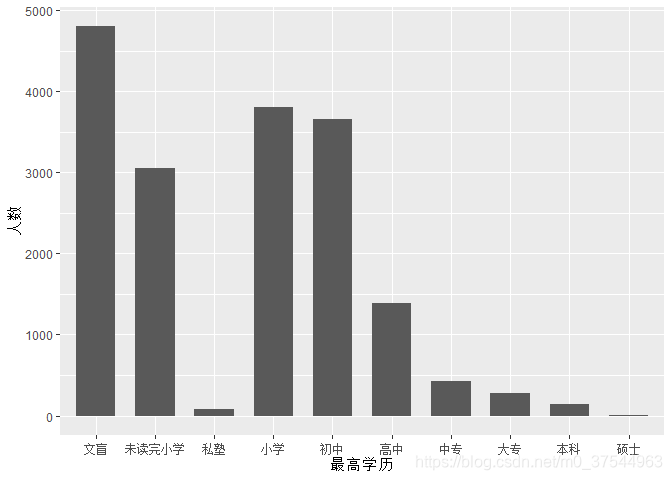
对所调查人群的最高学历作图:
- 条形图
为了读图更直观,将定型变量的各个水平用对应的中文表示。按照学历水平从低到高对人群的最高学历分布情况作条形图:
library(ggplot2)
#最高学历
levels(db_data$edu)<-c("文盲", "未读完小学","私塾","小学","初中",
"高中","中专","大专","本科","硕士","博士")#用中文表述不同学历水平
edu_table<-table(db_data$edu)
#条形图
#R基础作图
barplot(edu_table,space = 1/2,ylim=c(0,5000),xlab = "最高学历",ylab="人数")
#ggplot2
ggplot(db_data,aes(x=edu))+
geom_bar(width = 2/3)+
xlab( "最高学历")+ylab("人数")
R基础作图:

ggplot2:
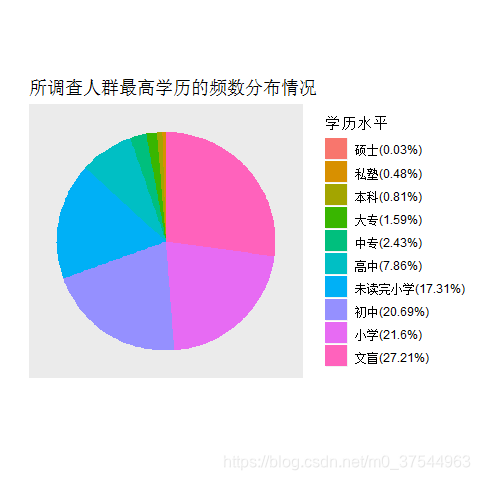
2. 饼图
按频数从大到小顺时针作饼图:
#R基础作图工具
pie(sort(edu_table,T),clockwise=T,main = "所调查人群最高学历的频数分布情况")
#ggplot2
reorder_size <- function(x,descending=T) {#自定义函数对levels按照频数进行重新排列
factor(x, levels = names(sort(table(x),descending)))
}
label_per = paste(names(sort(table(db_data$edu),F)), "(",
round(prop.table(table(reorder_size(db_data$edu,F))),4)*100,
"%)", sep = "")#将百分比加到标签文字上
ggplot(db_data,aes(x=factor(1),fill=reorder_size(edu,F))) +
geom_bar() +
coord_polar(theta = "y")+#变化为极坐标以形成饼图
labs(x = "", y = "", title = "所调查人群最高学历的频数分布情况",
fill='学历水平')+ #去除饼图旁边的标签
theme(axis.ticks = element_blank()) +
theme(axis.text.x = element_blank(),axis.text.y = element_blank())+ #把原坐标轴的刻度文字去掉
theme(panel.grid=element_blank())+ # 去掉白色圆框和中间的坐标线
scale_fill_discrete(labels = label_per[-1]) #使用含有百分比的图例
R基础作图工具:

ggplot2:
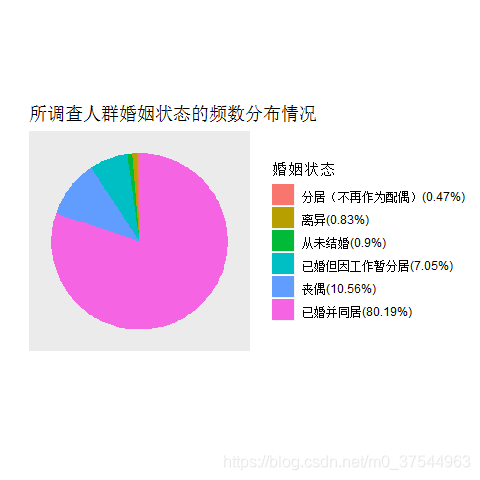
对所调查人群的婚姻状态作图:
- 条形图
按照不同婚姻状态频数从多到少作条形图:
#婚姻状态
levels(db_data$mrg)<-c("已婚并同居","已婚但因工作暂分居","分居(不再作为配偶)",
"离异","丧偶","从未结婚")#用中文表述不同婚姻状态
mrg_table<-sort(table(db_data$mrg),T)
knitr::kable(t.data.frame(mrg_table), caption = "所调查人群婚姻状态的频数分布情况")
#条形图
#R基础作图
barplot(mrg_table,space = 1/2,xlab = "婚姻状态",ylab="人数")
#ggplot2
ggplot(db_data,aes(reorder_size(mrg)))+
geom_bar(width = 2/3)+
xlab("婚姻状态")+ylab("人数")+
theme(axis.text.x = element_text(size=8,angle = 60, hjust = 1, vjust = 1))
#旋转x轴刻度标签文字,以完整显示
R基础作图工具:

ggplot2:

2. 饼图
按频数从大到小顺时针作饼图:
#R基础作图工具
pie(sort(mrg_table,T),clockwise=T,main = "所调查人群婚姻状态的频数分布情况")
#ggplot2
label_per = paste(names(sort(table(db_data$mrg),F)), "(",
round(prop.table(table(reorder_size(db_data$mrg,F))),4)*100,
"%)", sep = "")#将百分比加到标签文字上
ggplot(db_data,aes(x=factor(1),fill=reorder_size(mrg,F))) +
geom_bar() +
coord_polar(theta = "y")+#变化为极坐标以形成饼图
labs(x = "", y = "", title = "所调查人群婚姻状态的频数分布情况",
fill='婚姻状态')+ #去除饼图旁边的标签
theme(axis.ticks = element_blank()) +
theme(axis.text.x = element_blank(),axis.text.y = element_blank())+ #把原坐标轴的刻度文字去掉
theme(panel.grid=element_blank())+ # 去掉白色圆框和中间的坐标线
scale_fill_discrete(labels = label_per) #使用含有百分比的图例
R基础作图工具:

ggplot2:
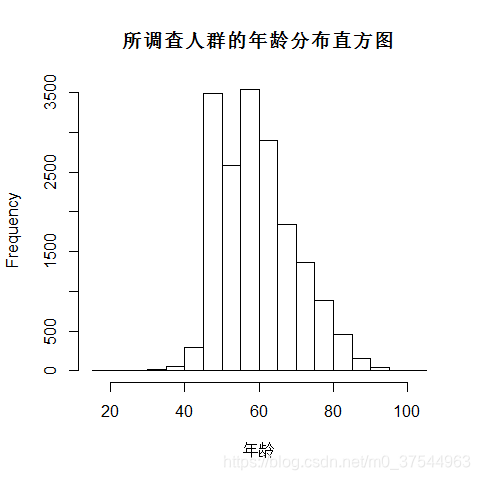
对所调查人群的年龄分布作图:
- 直方图
由于年龄数据的范围是19-102,因而可在15-105岁的范围内按每5岁为1组进行分组,绘制直方图。
summary(db_data$age)
#R基本绘图工具hist
hist(db_data$age, breaks = seq(15,105,5), xlab = "年龄",main = "所调查人群的年龄分布直方图")
#ggplot2
ggplot(db_data,aes(age))+
geom_histogram(breaks=seq(15,105,5),color="white")+
xlab("年龄")
R基本绘图工具:
ggplot2:

对比R基础作图工具和ggplot2
联系
同一数据的同一统计图形绘制结果大体一致,都能够根据数据准确地绘制相应图形。
区别
- 逻辑上的区别:基础绘图包所提供的函数主要通过调节参数对图形进行绘制和修改,而ggplot2除了提供更丰富的参数外,最核心的特点是基于图层进行绘图。
- 绘图风格有所区别:基础绘图包的绘图风格更为简洁,ggplot2的绘图风格更为精致,且允许使用者进行丰富的个性化,如主题风格、背景、配色等。
- 在本题绘制的几种图形中体现的具体的区别:
- 条形图:当x轴的刻度文字较长时,barplot()函数绘制的直方图则不能显示部分较长的文字,而ggplot2可通过theme函数调整文字的角度,从而完整展示文字。另外,barplot()所需的数据是频数分布表,而ggplot2可直接使用原始数据,对其进行频数统计并作图,对于频数为0的分类,如最高学历为博士的,barplot()会作出该类的条形图,而geom_bar()不予显示。
- 饼图:pie()函数所作的饼图存在标签文字的重叠,极大影响了使用者读图。ggplot2不直接提供饼图工具,但通过将条形图的坐标轴修改为极坐标轴可绘制出饼图,图例的使用也可解决文字重叠的问题。
- 直方图:两个包中的直方图绘制函数中分组数目的默认设定有所区别,但都可通过修改breaks参数进行重新设置。
以两个定性变量作为分类变量绘制分面统计图
facet_wrap 缠绕分面
按单个分类变量进行分面。
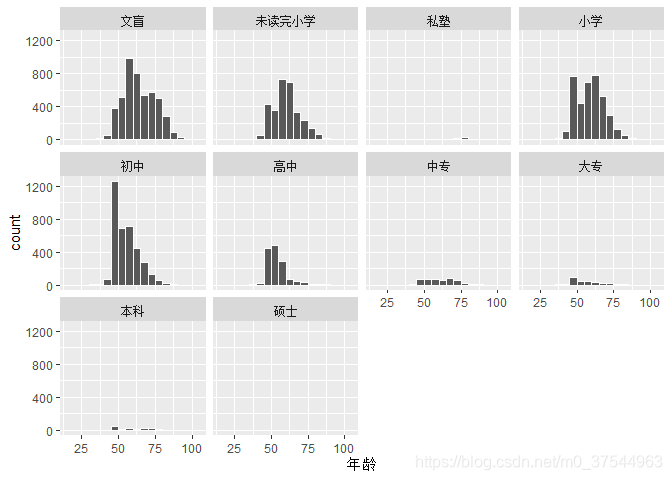
- 按最高学历进行分面绘制年龄分布的直方图:
ggplot(db_data,aes(age))+
geom_histogram(breaks=seq(15,105,5),color="white")+
xlab("年龄")+facet_wrap(~edu)
2. 按婚姻状态进行分面绘制年龄分布的直方图:
ggplot(db_data,aes(age))+
geom_histogram(breaks=seq(15,105,5),color="white")+
xlab("年龄")+facet_wrap(~mrg)

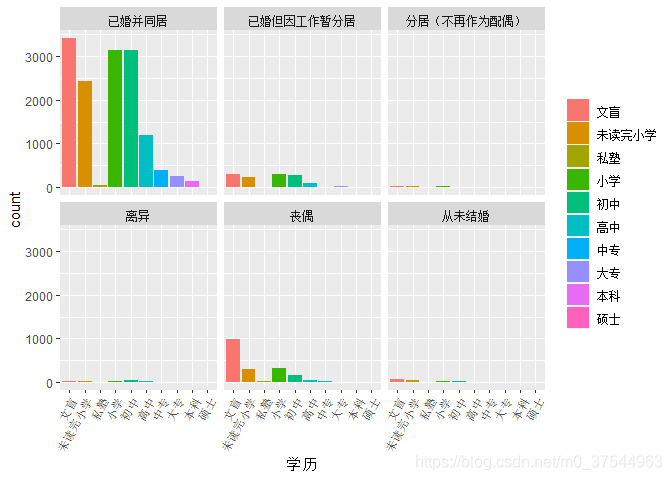
3. 按婚姻状态进行分面绘制最高学历的条形图:
ggplot(db_data,aes(x=edu,fill=edu))+
geom_bar()+
xlab("学历")+facet_wrap(~mrg)+
theme(axis.text.x = element_text(size=8,angle = 60, hjust = 1, vjust = 1))+
guides(fill = guide_legend(title = NULL))
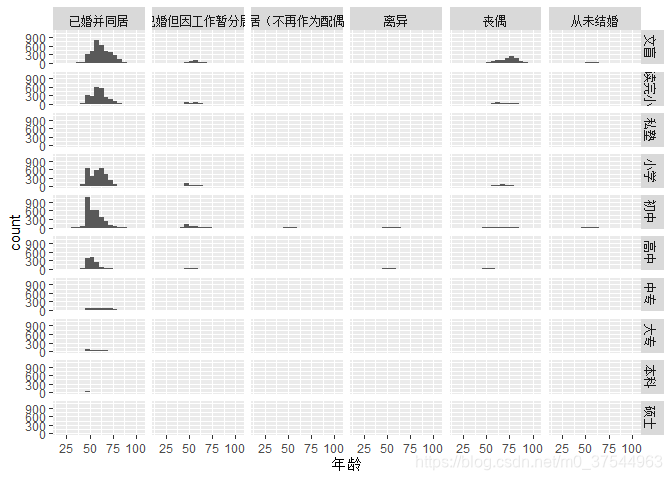
facet_grid 网格分面
可用多个标准(分类变量)进行分面。
ggplot(db_data,aes(age))+
geom_histogram(breaks=seq(15,105,5))+
xlab("年龄")+facet_grid(edu~mrg)
考察两两变量间的关系使用哪种图?
定性变量&定性变量
除了以表格形式呈现的列联表之外,可以采用簇状条形图、堆积条形图以及ggplot2中提供的geom_tile()函数绘制“热图”。
#列联表
ctable<-table(db_data$edu,db_data$mrg)
#簇状条形图
#堆积条形图
ggplot(db_data)+
geom_bar(aes(x=edu,fill=mrg),position = "dodge")+
xlab("学历")+
theme(axis.text.x = element_text(size=8,angle = 60, hjust = 1, vjust = 1))
#热图
library(reshape2)
melted_ctable <- melt(ctable)
ggplot(melted_ctable,aes(x=Var2, y=Var1,fill = value))+
geom_tile()+ylab("最高学历")+xlab("婚姻状况")+
theme(axis.text.x = element_text(size=8,angle = 60, hjust = 1, vjust = 1))
堆积条形图:

热图:

定性变量&定量变量
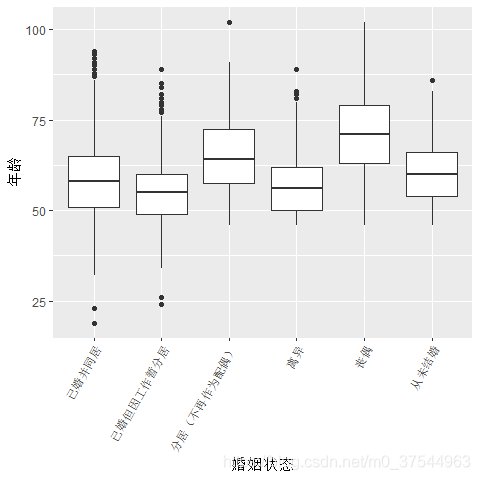
分别为定性变量的不同水平绘制箱线图。以婚姻状况与年龄为例:
ggplot(db_data, aes(x=mrg,y=age))+
geom_boxplot()+
xlab("婚姻状态")+ylab("年龄")+
theme(axis.text.x = element_text(size=8,angle = 60, hjust = 1, vjust = 1))
定量变量&定量变量
可利用散点图初步探究两个定量变量之间的关系,以鸢尾花数据集(iris)中花瓣长度(Petal.Length)与花瓣宽度(Petal.Width)两个定量变量为例:
ggplot(iris, aes(x=Petal.Length,y=Petal.Width))+
geom_point()

