强化学习与监督学习的区别:
(1)训练数据中没有标签,只有奖励函数(Reward Function)。
(2)训练数据不是现成给定,而是由行为(Action)获得。
(3)现在的行为(Action)不仅影响后续训练数据的获得,也影响奖励函数(Reward Function)的取值。
(4)训练的目的是构建一个“状态->行为”的函数,其中状态(State)描述了目前内部和外部的环境,在此情况下,要使一个智能体(Agent)在某个特定的状态下,通过这个函数,决定此时应该采取的行为。希望采取这些行为后,最终获得最大的奖励函数值。
而监督学习是通过训练得到一个从数据到标签的映射。
一些定义

一些假设

Markov decision Process (MDP)

待优化目标函数
增强学习中的待优化目标函数是累积奖励,即一段时间内的奖励函数加权平均值:
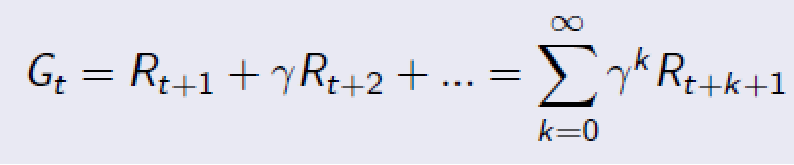
在这里,GAMMA是一个衰减项。
Q-Learning
增强学习中已经知道的的函数是:
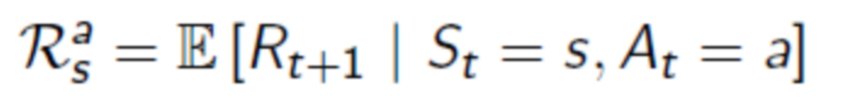
需要学习的函数是:

根据一个决策机制(Policy),我们可以获得一条路径:
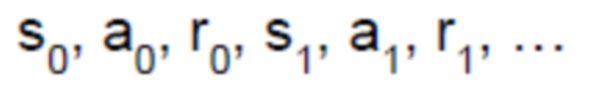
定义1:估值函数(Value Function)是衡量某个状态最终能获得多少累积奖励的函数:
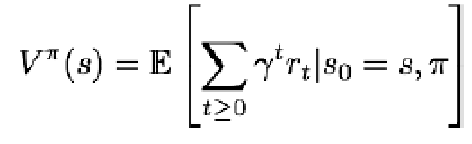
定义2:Q函数是衡量某个状态下采取某个行为后,最终能获得多少累积奖励的函数:

Q与V的关系:
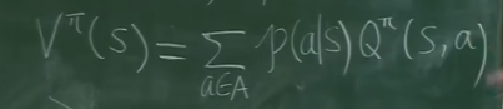
递归:根据s产生a有个概率,根据s,a产生s’还有个概率,双层概率求和,然后,就建立了s的估值函数和s’估值函数的关系

求最佳策略的迭代算法:

这一算法的劣势:
对于状态数和行为数很多时,这种做法不现实。
例如:对一个ATARI游戏,状态数是相邻几帧所有像素的取值组合,这是一个天文数字!
ACTION数量从6到20不等
Q-learning的优化——Deep Q-Network (DQN)
定义
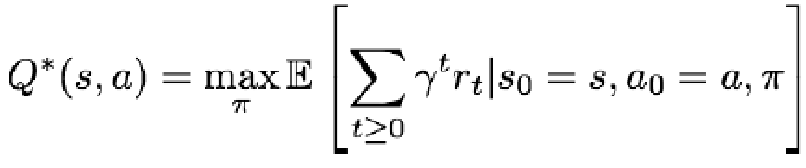
则有 Bellman Equation:
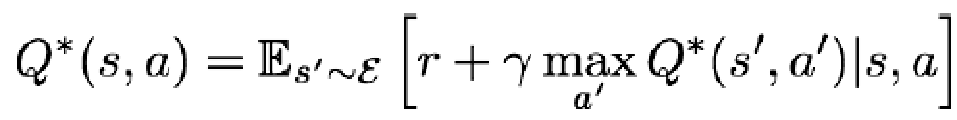


实例
打飞机的Atari游戏的DQN设置

一个更难的Atari游戏的DQN设置:
DQN算法流程

Q-learning的劣势:
(1)在一些应用中,状态数或行为数很多时,会使Q函数非常复杂,难以收敛。例如图像方面的应用,状态数是(像素值取值范围数)^(像素个数)。这样的方法,对图像和任务没有理解,单纯通过大数据来获得收敛。
(2)很多程序,如下棋程序等,REWARD是最后获得(输或赢),不需要对每一个中间步骤都计算REWARD.
Policy gradient


Actor-Critic算法:

总结
(1)目前强化学习的发展状况:在一些特定的任务上达到人的水平或胜过人,但在一些相对复杂的任务上,例如自动驾驶等,和人存在差距。
(2)和真人的差距,可能不完全归咎于算法,传感器、机械的物理限制等,也是决定性因素。
(3)机器和人的另一差距是:人有一些基本的概念,依据这些概念,人能只需要很少的训练就能学会很多,但机器只有通过大规模数据,才能学会。
(4)但是,机器速度快,机器永不疲倦,只要有源源不断的数据,在特定的任务上,机器做得比人好,是可以期待的。