https://www.bilibili.com/video/BV13Y4y1r7CH/?spm_id_from=333.1007.top_right_bar_window_dynamic.content.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
https://www.bilibili.com/video/BV13Y4y1r7CH/?spm_id_from=333.1007.top_right_bar_window_dynamic.content.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
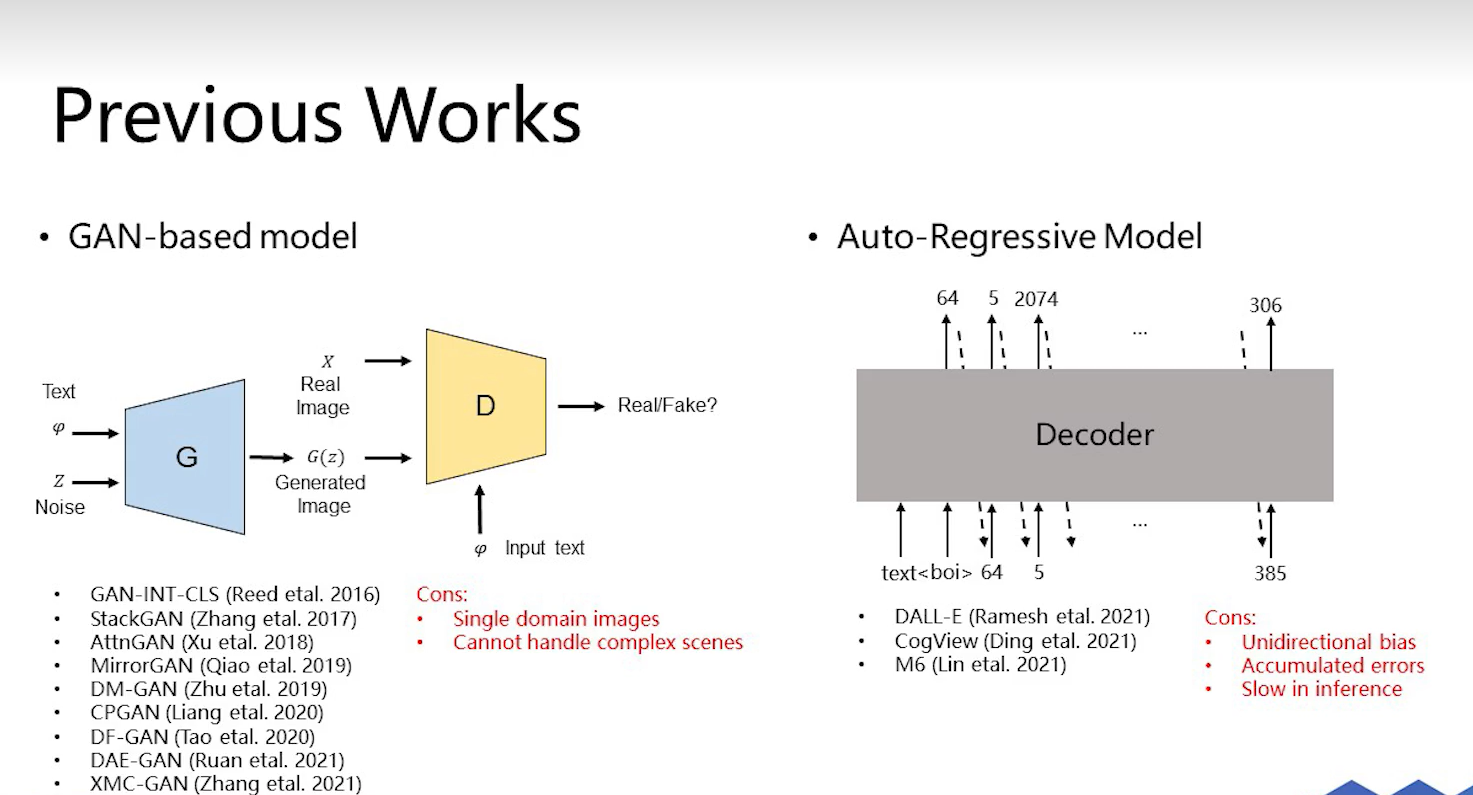
2021年前的方法都是基于GAN的,一般把文本和noise放入一个生成网络中,然后生成一个图像之后,通过判别器判定其和文本是否match,然后同时判real和fake,这种方法有两个缺点,1只能建模单一场景,比如只能去生成人脸相关的,gan模型就只能是在人脸这个场景上训练的;2.无法对场景中存在的多个物体进行建模。右边是基于GPT的方法,如果dalle,对于一个给定的文本,从图像的最左上角开始生成,依次从左上往右下,逐块生成这个图,但对于一些复杂的多样性图片,前一个token错误,后面的生成就都有问题了,并且非常的慢。

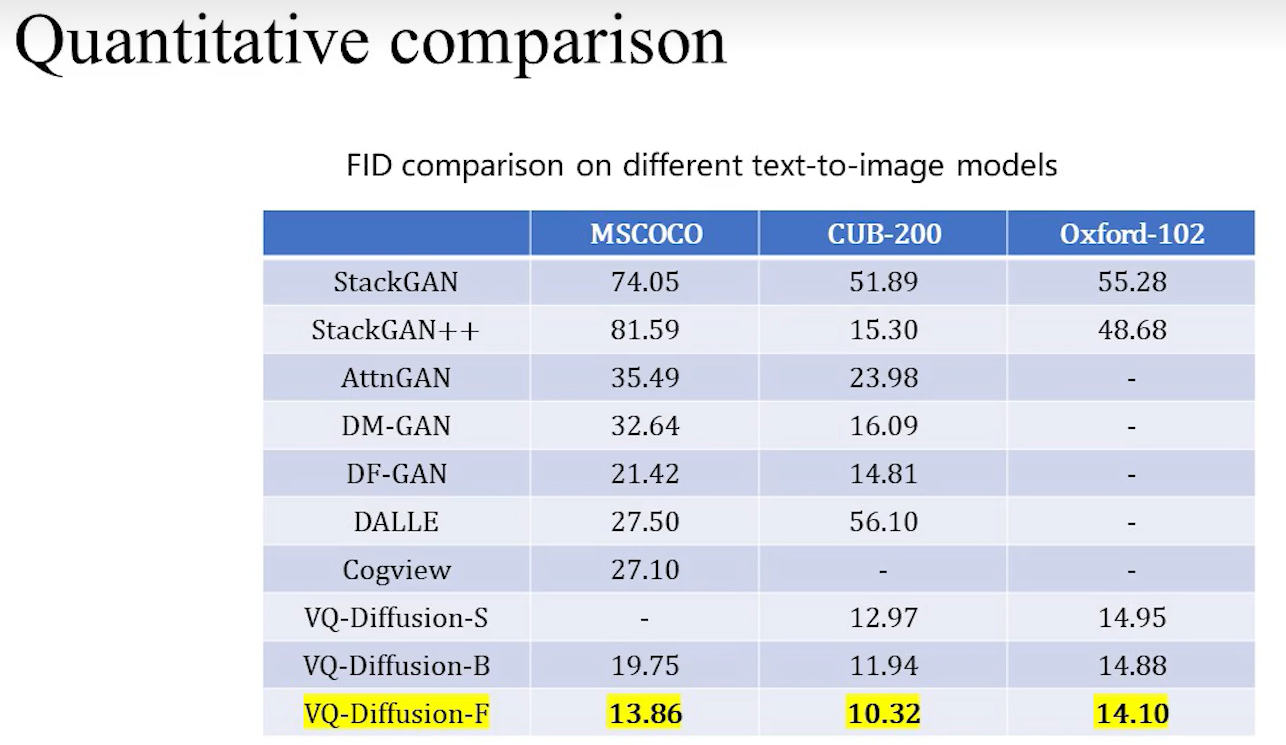
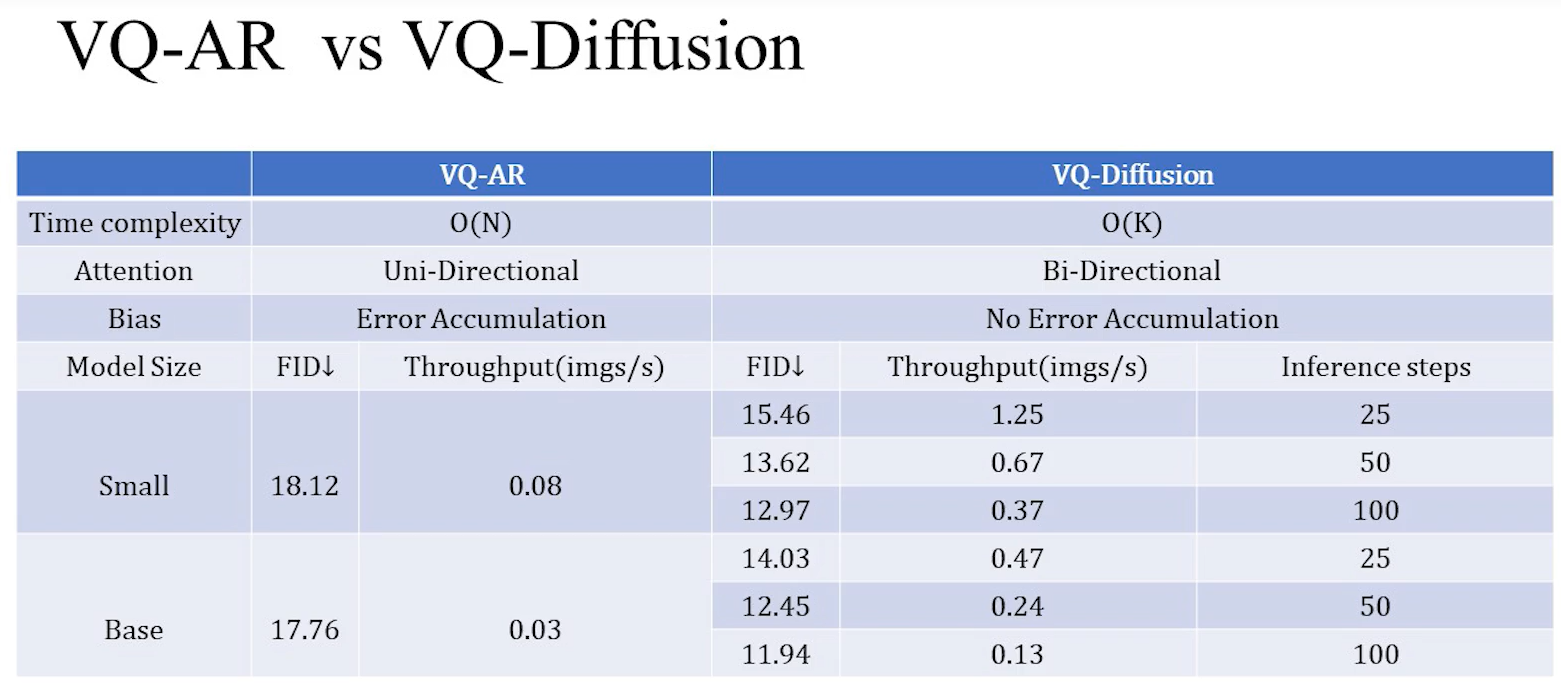
1.把denoise diffusion引入到文生图领域;2.提出了VQ diffusion算法;3.比自回归要快15倍。

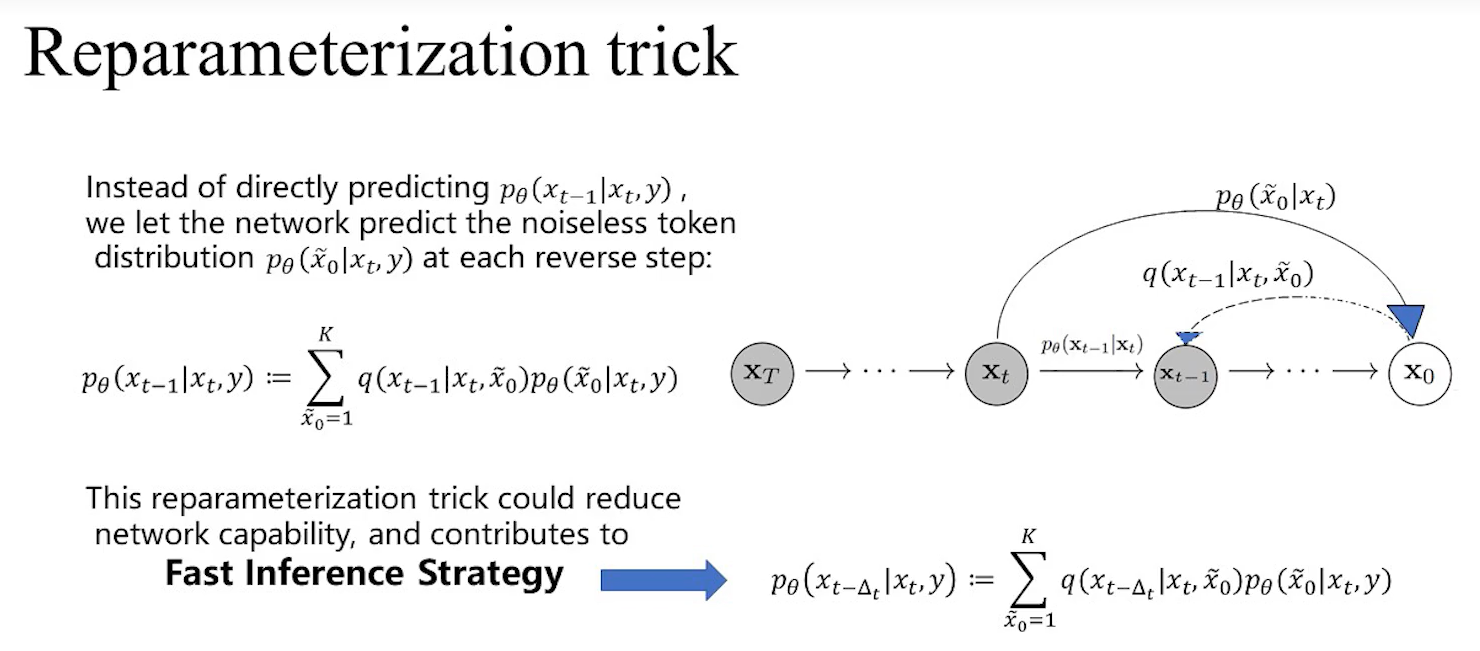
diffusion model有两个步骤,forward step,从右往左看,加噪,马尔可夫过程,当一张图像不断加噪声,最终会成为一个纯噪声图,reverse step, 去噪,使用网络对噪声图像进行消除噪声,最终的到图片。
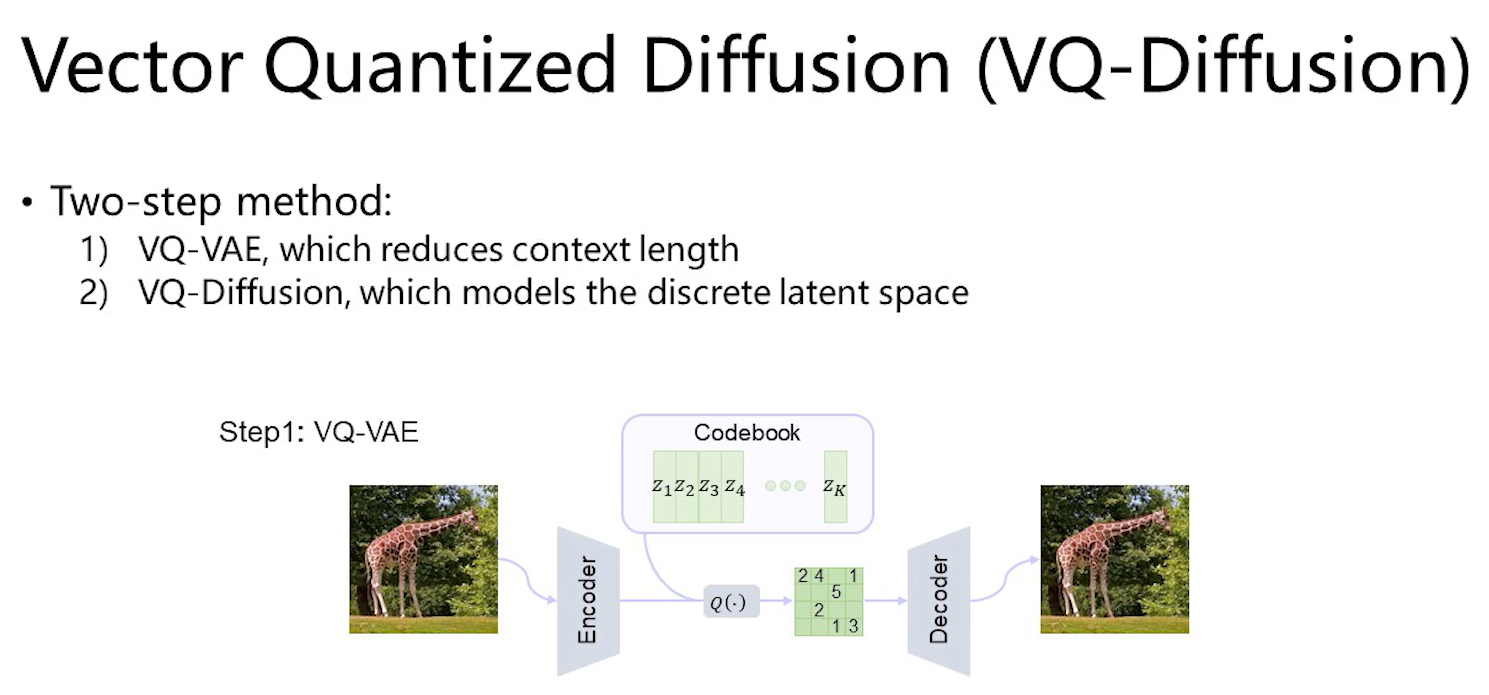
VQ diffusion不是在纯像素空间去做,而是在一个量化的像素空间去做,pixel空间图像分辨率很高,用transformer对每一个像素进行建模的话,sequence长度会很长,不利于建模。因此对图像空间的分辨率进行压缩,用到了VQVAE,把图片变成一个分辨率较低的离散的code,如上图分辨率是256x256,压缩后变成32x32。
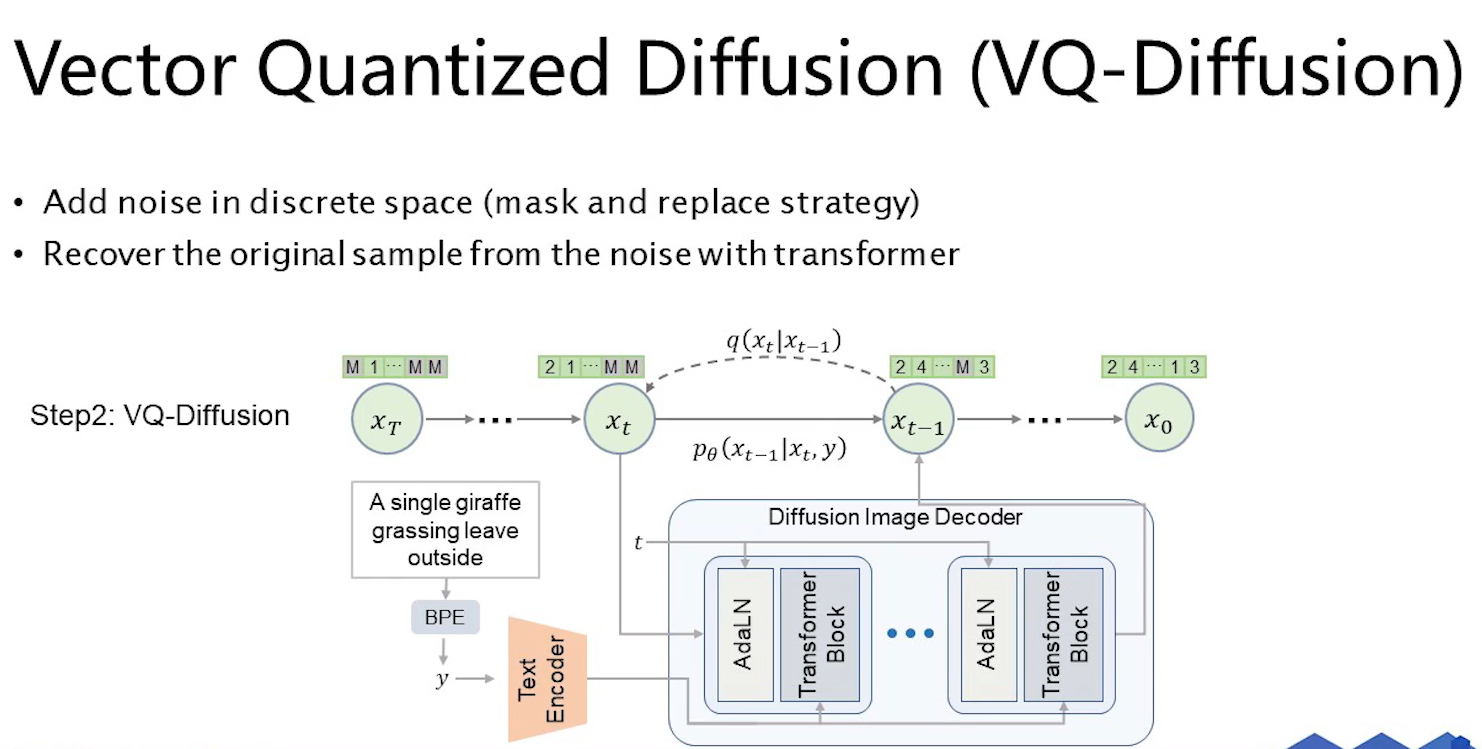
在第二步,引入了mask和replace的策略,加噪全部在一个离散空间中进行,有两种加噪方式,第一种是随机的把某一个code给去掉,mask掉,第二种是replace,随机的把code替换成其他code,这样在加噪中我就会得到一个随机code和mask code组成的一个向量,通过带噪声的一串code以及文本信息可以恢复出原来的图像。