
1.abstract
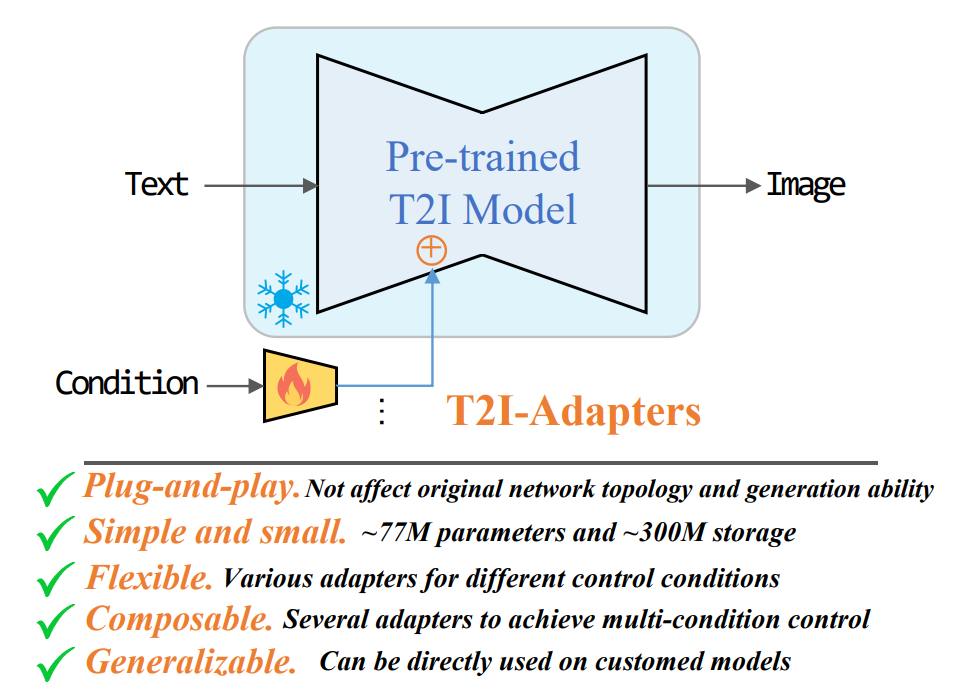
挖掘T2I模型隐式学习的能力,显式的利用他们更细粒度的控制学习的能力,将T2I模型内部知识和外部控制信号对齐,同时冻结原始的T2I模型,微调就容易遗忘。通过这种方式,可以针对不同的条件训练各种adapter,来实现对生成结果颜色和结构的控制和编辑。
2.introduction
T2I模型生成结果通常有丰富的纹理,清晰的边缘,合理的机构和有意义的语义,这表明T2I可以通过一种隐式的方式很好的捕捉不同层次的信息,从低层次(例如纹理),中层次(例如边缘)到高层次(语义)。有多时候并不是T2I没有生成能力,而是文本缺乏提供准确的结构引导。
adapter可以用来挖掘T2I这种能力,学习从控制信息到T2I模型内部知识映射,主要是对齐问题,即内部知识和外部控制信息对齐。T2I-adapter是一个轻量级模型,可以用少量数据学习这种对齐,可以插入现有的T2I模型,在扩散过程中只需要一次推理,有77m参数和300m的大小。并且可以多个adapter组合。
3.related work
3.1 image synthesis and translation
GAN/VAE,多是无条件生成,常用的条件包括素描,语义分割地图和pose等,可以将条件映射转化为自然图像。
3.2 diffusion model
扩撒模型迭代去噪,从高斯噪声中生成图像,在扩散中,通过在T次迭代中添加随机高斯噪声,将图像X0转化为一个高斯分布Xt,反向过程就是通过多次去噪从Xt中恢复X0。广泛采用的策略是在特征空间中进行去噪,并通过交叉注意力模型将文本条件引入去噪过程。
3.3 Adapter
Adapter为每个下游任务对一个大型预训练模型进行微调是低效的,因此提出了使用adapter进行迁移学习的方法,adapter是一种紧凑且可扩展的模型。
4.method
4.1 preliminary:stable diffusion
基于sd来实现,sd是一个两阶段的扩散模型,包括一个自编码器和一个unet去噪器,第一阶段,sd训练了一个自编码器,它可以将图像X0转换为潜空间然后重构它们。在第二阶段,sd训练了一个修改过的unet去噪器,直接在潜空间中去噪。

上面写的这段还是很重要的,Zt是从Z0来,Z0是从高斯分布中采样,经过unet计算loss,Zt是q,经过clip编码的文本是k,v。
4.2 overview of T2I-Adapter

如上所示,不是sd能力不足,而是文本无法提供准备的生成知道,无法充分对齐sd的内部知识和外部控制。
4.3 Adapter design

由4个特征提取块和3个下采样块组成,原始输入512x512,利用像素重排将其下采样到64x64,每个尺度中,利用一个卷积层和2个残差层RB,来提取特征,最终形成了多尺度的特征Fc,如右下角所示,Fc的维度和unet去噪编码器中的中间特征Fenc相同,然后在每个尺度上将Fc和Fenc相加。

结构控制:草图,深度图,语义分割图和pose图
空间色彩调色板:色调和空间分布,设计了一个空间色彩调色版,用于粗略控制生成图像的色调和颜色分布,为了训练空间调色板,需要表示图像的色调和颜色分布,使用降采样来去除图像的语义和结构信息,同时保留足够的颜色信息,然后使用最近邻上采样来恢复图像的原始大小,最后,色调和颜色分布式通过几个空间排列的彩色块完成。
多Adapter适配
4.4 model optimization
在优化过程中,将sd的参数固定,并且仅优化T2I adapter,每个训练样本包括原始图像X0,条件图C和文本提示y组成的三元组,优化过程类似于sd,给定一个图像X0,通过自编码器的编码器将其嵌入到潜空间Z0中,从[0,T]中随机采样一个时间步长t,将相应的噪声添加到Z0中,得到Zt,

训练过程中的非均匀时间步长采样:
在扩散模型中,时间嵌入是一个重要的采样,将时间嵌入到adapter中可以增强其指导能力,但是这种设计要求T2I-adapter参与每一次迭代。如下图所示,将DDIM推断采样均匀的分为3个阶段,即开始,中间和后期阶段,然后将指导信息添加到每个阶段,在中间和后期添加指导信息基本没有什么影响,因此生成结果主要内容是在早期采样阶段确定的,因此,t是从后面的部分采样的,在训练中则忽略,为了加强adapter的训练,采用非均匀采样来增加t落入早期采样的概率。

5.experiment
5.1 implementation details
bs=8,adam,10个epoch,512x512输入,sd 1.4,训练过程在4个v100上,3天完成。