Paper name
TRAINING-FREE STRUCTURED DIFFUSION GUIDANCE FOR COMPOSITIONAL TEXT-TO-IMAGE SYNTHESIS
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2212.05032.pdf
Project URL: https://weixi-feng.github.io/structure-diffusion-guidance/
Code URL: https://github.com/weixi-feng/Structured-Diffusion-Guidance
Openreview URL: https://openreview.net/forum?id=PUIqjT4rzq7
TL;DR
- ICLR 2023 文章,提出 Structured Diffusion Guidance (StructureDiffusion),将语言结构与基于扩散的 T2I 模型中操纵交叉注意层的可控属性的扩散引导过程结合起来,相比于 Stable Diffusion 实现了更好的文本与图像对齐效果
Introduction
背景
-
大规模扩散模型已经在文本到图像合成 (T2I) 任务中取得了 SOTA 结果
-
当前方法尽管能够生成高质量且具有创造性的图像,但我们观察到属性绑定和组合能力仍然被认为是主要的挑战性问题,特别是涉及多个对象时
- 属性绑定要求模型将对象与正确的属性描述相关联
- 组合技能要求模型将多个概念组合并生成到单个图像中
-
当前 stable diffusion 模型在属性绑定和组合技能方面的缺点如下所示,比如第二列的图中 building 和 bench 的颜色与 prompt 中的设定反了,这种情况可能是由于强烈的训练集偏差或不精确的语言理解

本文方案
- 提出 Structured Diffusion Guidance (StructureDiffusion),将语言结构与基于扩散的 T2I 模型中操纵交叉注意层的可控属性的扩散引导过程结合起来
- 观察到交叉注意层中的键和值与对象布局和内容有很强的语义意义
- 通过基于语言 insights 对交叉注意表示进行操作,可以更好地保留生成图像中的组合语义
- 在 Stable Diffusion 基础上,本文设计的结构化交叉注意设计不需要额外训练样本
- 在定性和定量结果方面获得了更好的组合技能,从而在面对面的用户比较研究中获得了5-8%的显著优势
Dataset/Algorithm/Model/Experiment Detail
实现方式
BACKGROUND
-
Stable Diffusion
- 由自编码器和扩散模型组成的两阶段方法
- 自编码器:预训练的自动编码器将图像编码为低分辨率的 latent maps,用于扩散训练。在推理过程中,它将扩散模型生成的输出解码为图像
- 扩散模型:扩散模型基于随机高斯噪声输入 zT 生成低分辨率的 latent maps。给定zT,它在每一步 t 输出一个噪声估计 ,并从 zt 中减去它。最终的无噪声潜在映射预测 z0 被输入到自编码器中生成图像。
- 使用修改后的 UNet 用于 noise estimation,frozen CLIP 作为文本编码器将文本输入编码为嵌入序列。图像空间与文本嵌入之间的交互是通过下采样和上采样块中的多个交叉注意层实现的
-
CLIP Text Encoder
- 给定文本 prompt P,基于 CLIP 生成 Wp
- 本文的关键观察是 CLIP 嵌入的上下文是错误属性绑定的潜在原因。由于因果注意掩码(causal attention masks,),序列后面的标记与前面的标记语义混合在一起。
- 例如,当用户为第二个对象指定一些罕见的颜色时 (例如:“一个黄苹果和红香蕉”),Stable Diffusion 倾向于在“黄色”中产生“香蕉”,因为“黄色”的嵌入伴随着“香蕉”的标记
-
Cross Attention Layers
- 交叉注意层从 CLIP 文本编码器中获取嵌入序列,并将其与隐特征映射融合,以实现无分类器引导
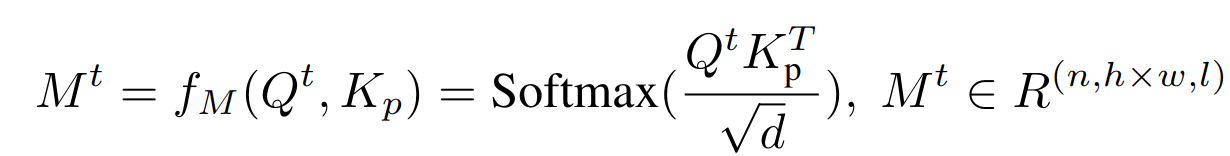
其中 KV 是文本特征,Q 是图像特征
- 交叉注意层从 CLIP 文本编码器中获取嵌入序列,并将其与隐特征映射融合,以实现无分类器引导
-
Cross Attention Controls
- 之前的 image editing 工作观察到 Imagen 中的空间布局依赖于交叉注意映射
- 这些映射控制生成图像的布局和结构,而值包含映射到参与区域的丰富语义。因此,本文假设通过分别控制注意图和值,可以将图像布局和内容分离
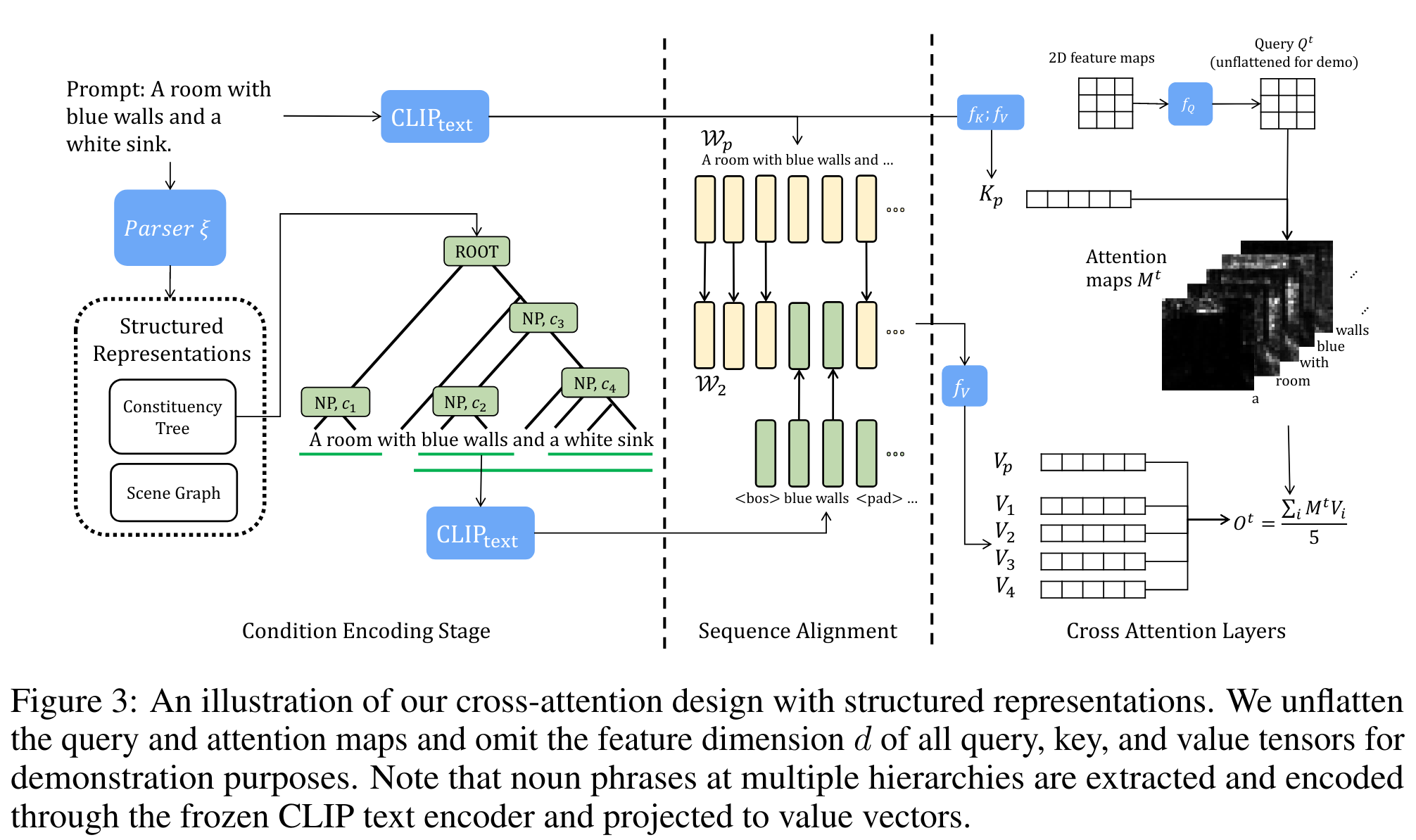
STRUCTURED DIFFUSION GUIDANCE
-
属性-对象对在许多结构化表示中都是免费的(意思是与 stable defusion 计算消耗微不足道),比如选区树 (constituency tree) 或场景图 (scene graph)
-
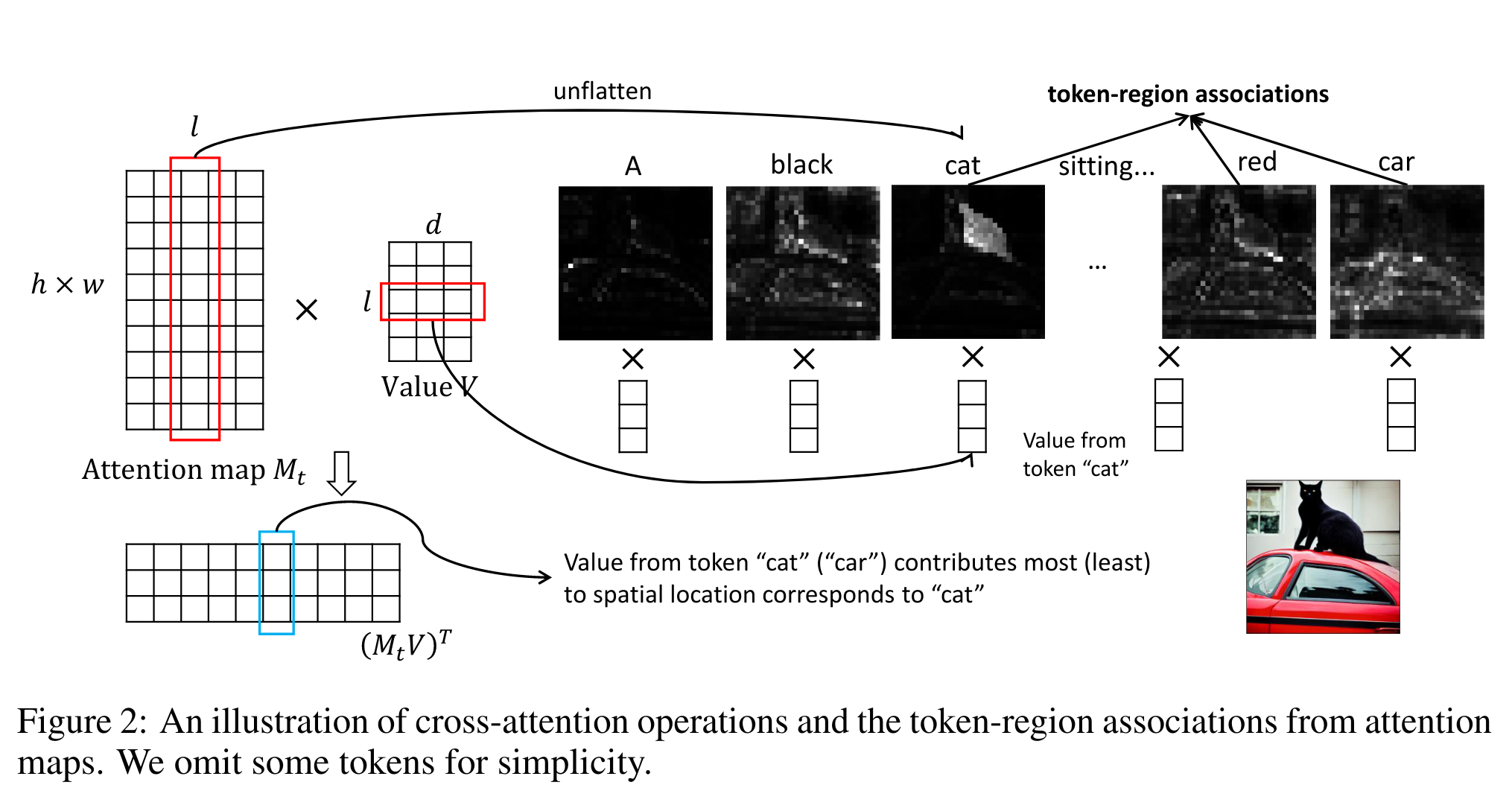
本文寻求一种将语言结构与交叉注意层相结合的隐式方法。提取多个名词短语(NPs),并将其语义映射到相应的区域
-
因为 Mt 提供了自然的 token 区域关联,可以将其应用于不同 NPs 的多个值,以实现区域智能语义引导
-
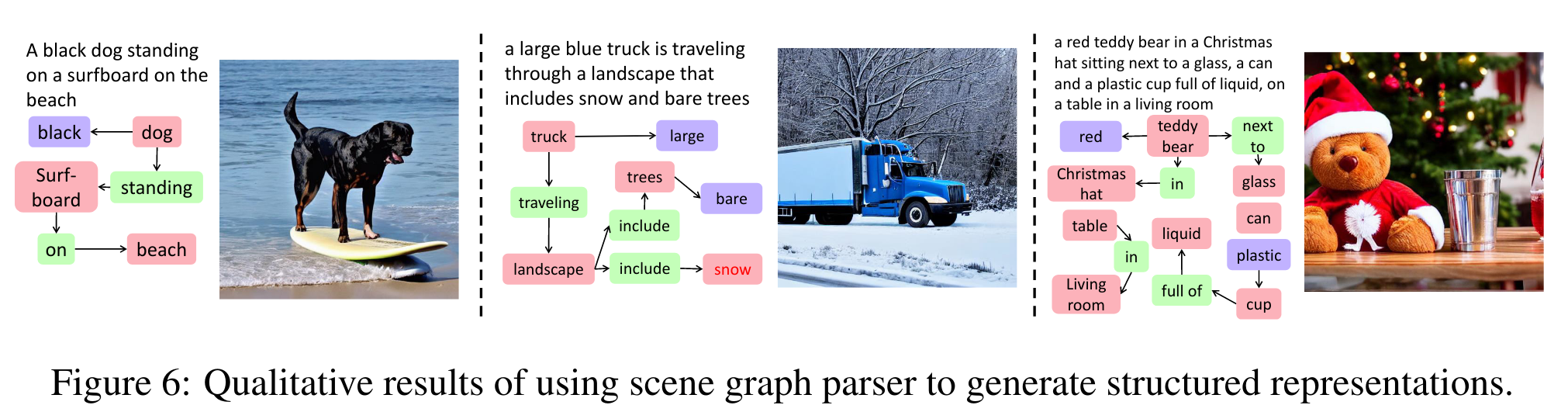
首先基于 parser ξ(·),从所有层次中提取一个概念集合,如 C = {c1, c2,…, ck},对于选区解析,从树结构中提取所有的NPs。对于场景图,提取对象及其与另一个对象的关系作为文本段。对每个 NP 分别基于 CLIP 提取特征
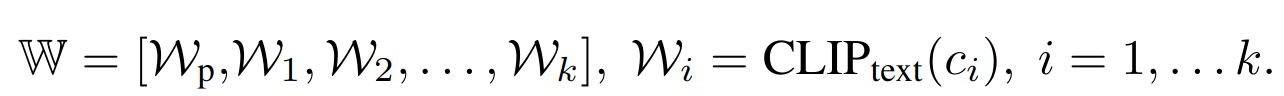
-
每个 Wi 与 Wp 进行 realign 操作:< bos >和< pad >之间的嵌入被插入到 Wp 中以创建一个新的序列 W p ‾ \overline{W_{p}} Wp ,基于 W p ‾ \overline{W_{p}} Wp 来作为 cross attention 中的 V,假设 full-prompt key 能够生成布局而不丢失对象
-
从 W 中获得一组值,并将每个值与 Mt 相乘,以实现 C 中 k 个 NPs 的组合
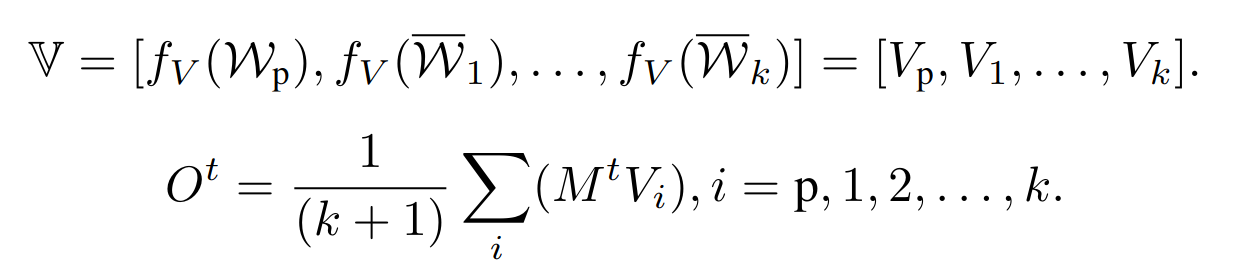
-
与仅使用 fV (Wp) 相比,上式没有修改图像布局或组成,因为 Mt 仍然是从 Qt, Kp 中计算得到,证明该结论的可视化对比实验如下,stable diffusion 的注意图和本文的方法在整个扩散过程中有相似的空间分布和亮点
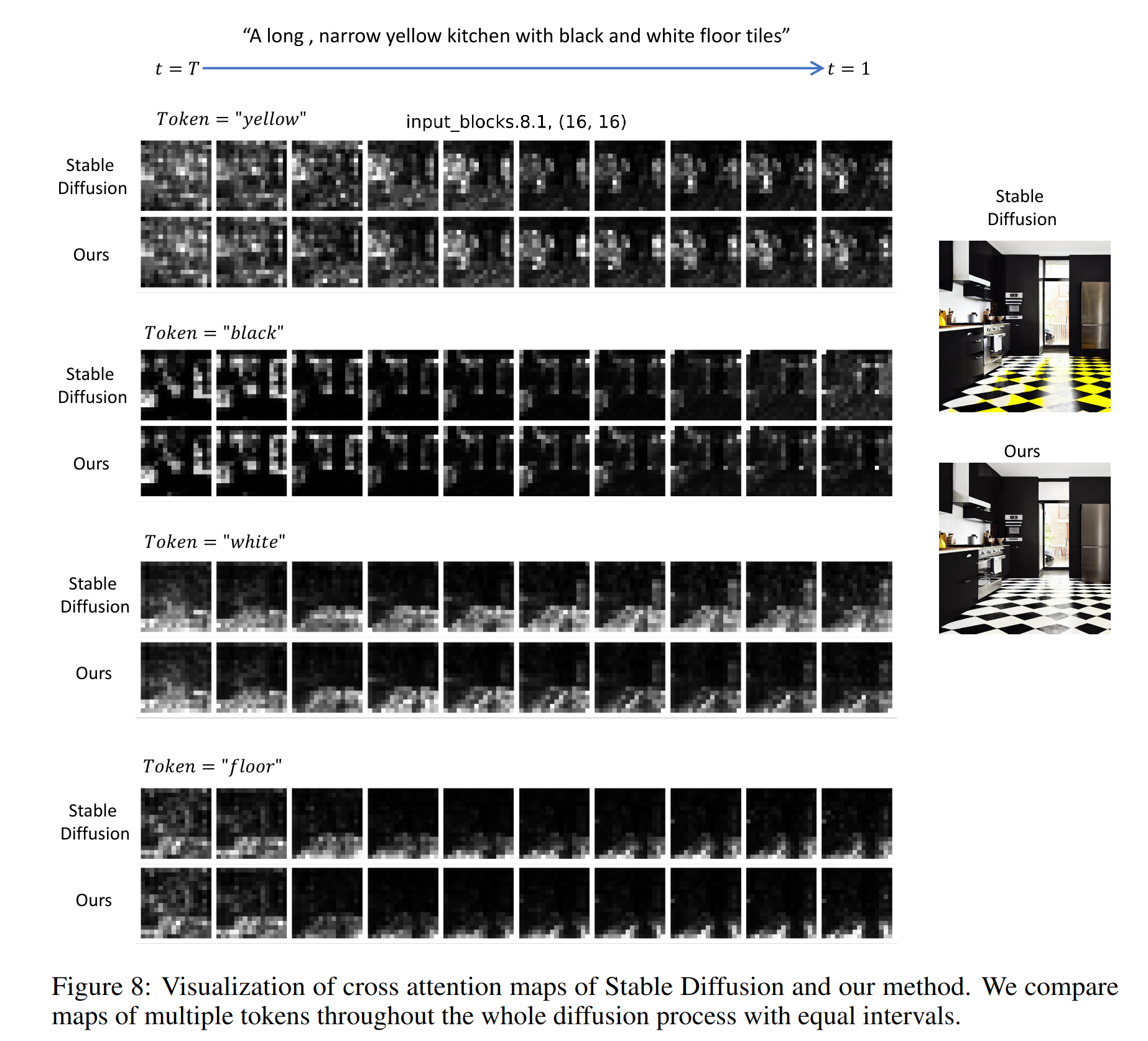
-
然而,stable diffusion 倾向于省略对象生成的图像,特别是对于用单词 “and” 连接两个物体的概念连词。设计了一种方法的变体,从 C 计算一组注意地图 M = {M t p, M t1,…},并将它们乘到 V
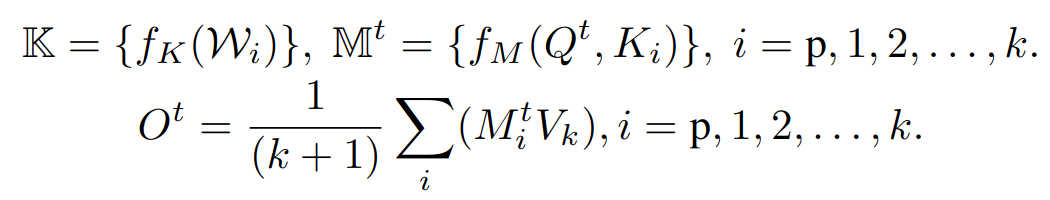
Ot 是某一交叉注意层的输出,输入到下游层生成最终图像 x -
整体算法流程如下

实验结果
数据集
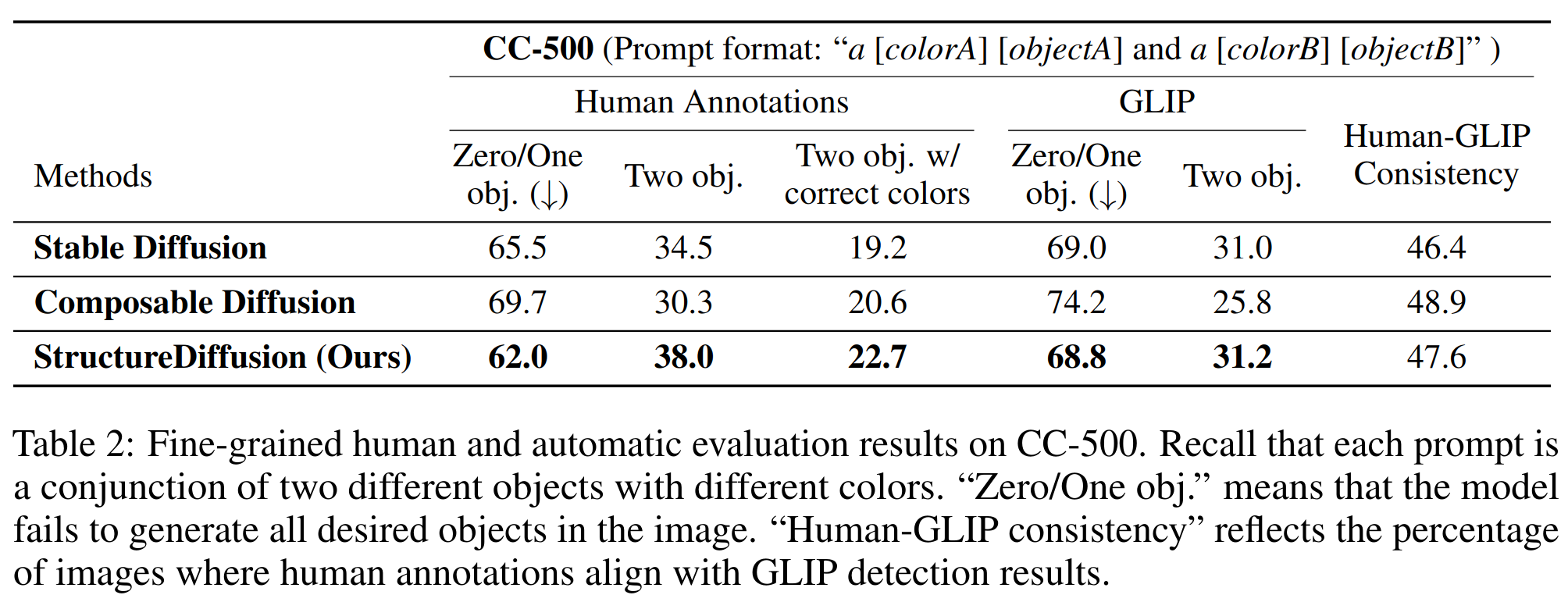
- 提出了 Attribute Binding Contrast set (ABC-6K),它由来自MSCOCO的自然提示组成,每个提示至少包含两个颜色单词修改不同的对象,还切换了两个颜色单词的位置,以创建一个对比标题
- 最终得到了6.4万个标题或3.2万个对比对
- 除了自然的组合提示,还挑战了将两个概念结合在一起的不那么详细的提示。这些提示遵循“一个红苹果和一个黄香蕉”的句型,将两个物体及其属性描述连接起来。将这组提示称为 Concept Conjunction 500 (CC-500)
评价指标
- 主要依靠人工评估
- 要求注释人员比较两张生成的图像,分别来自 stable diffusion 和本文的方法,并指出哪张图像具有更好的图像-文本对齐或图像保真度
- 对于图像保真度,会问注释者“不考虑文本,哪个图像更真实、更自然?”
- 还研究了图像组成的自动评估指标,即使用 SOTA phrase grounding 模型GLIP 来匹配 phrase-object 对
- 系统级评估:遵循之前的工作来利用 Inception Score (IS), Fre ́chet Inception Distance (FID) 与 CLIP R-precision (R-prec.)
- IS 和 FID 主要测量图像库的系统质量和多样性,而 R-prec 测量图像级对齐
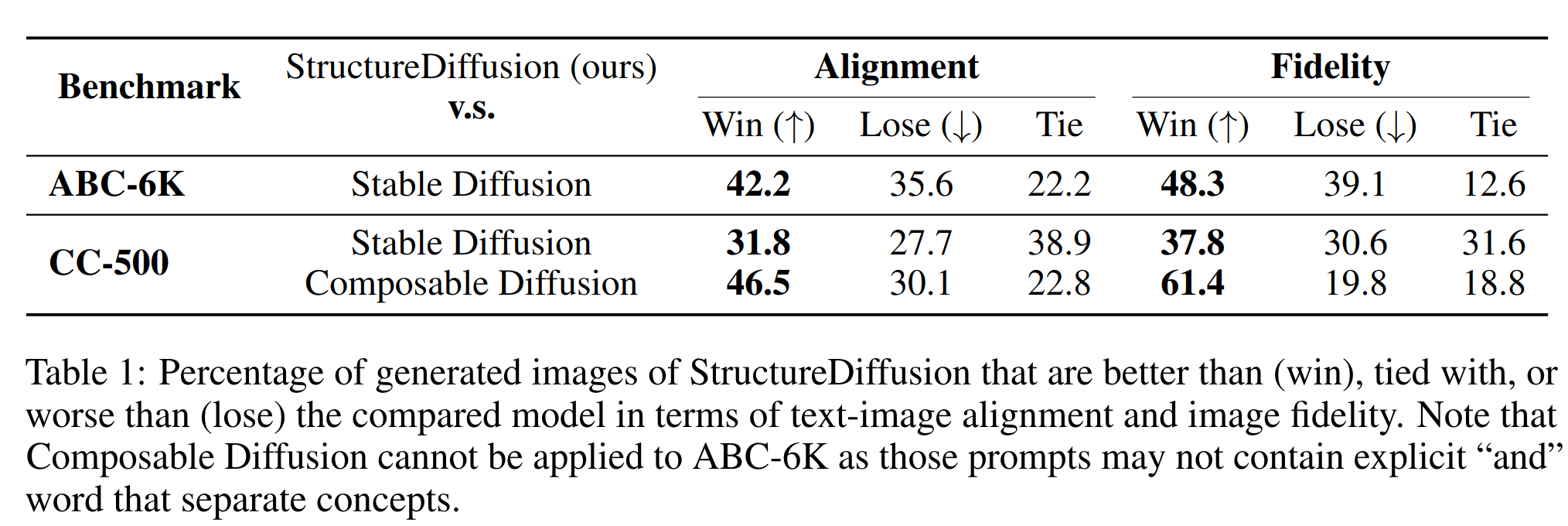
对比实验
- 人工评价结果,StructureDiffusion 在 图像-文本对齐和保真度两方面的评估结果都更好
可视化对比
- StructureDiffusion 在颜色正确性上更优,对于多目标的图片生成更准确

concept conjunction prompts CC-500 数据集上对比

SCENE GRAPH INPUT
- 表明我们的方法不仅限于选区解析(constituency parsing),还可以扩展到其他结构化表示,例如场景图 (scene graphs)
消融实验
-
RE-ALIGNING SEQUENCE
- 由于名词短语文本跨度比完整序列短,因此重新对齐可以确保每个标记的值向量对应于正确的注意力映射。
- 将跨度扩大到整个序列的长度会降低图像质量,大概掉 2 个点的 IS / FID
-
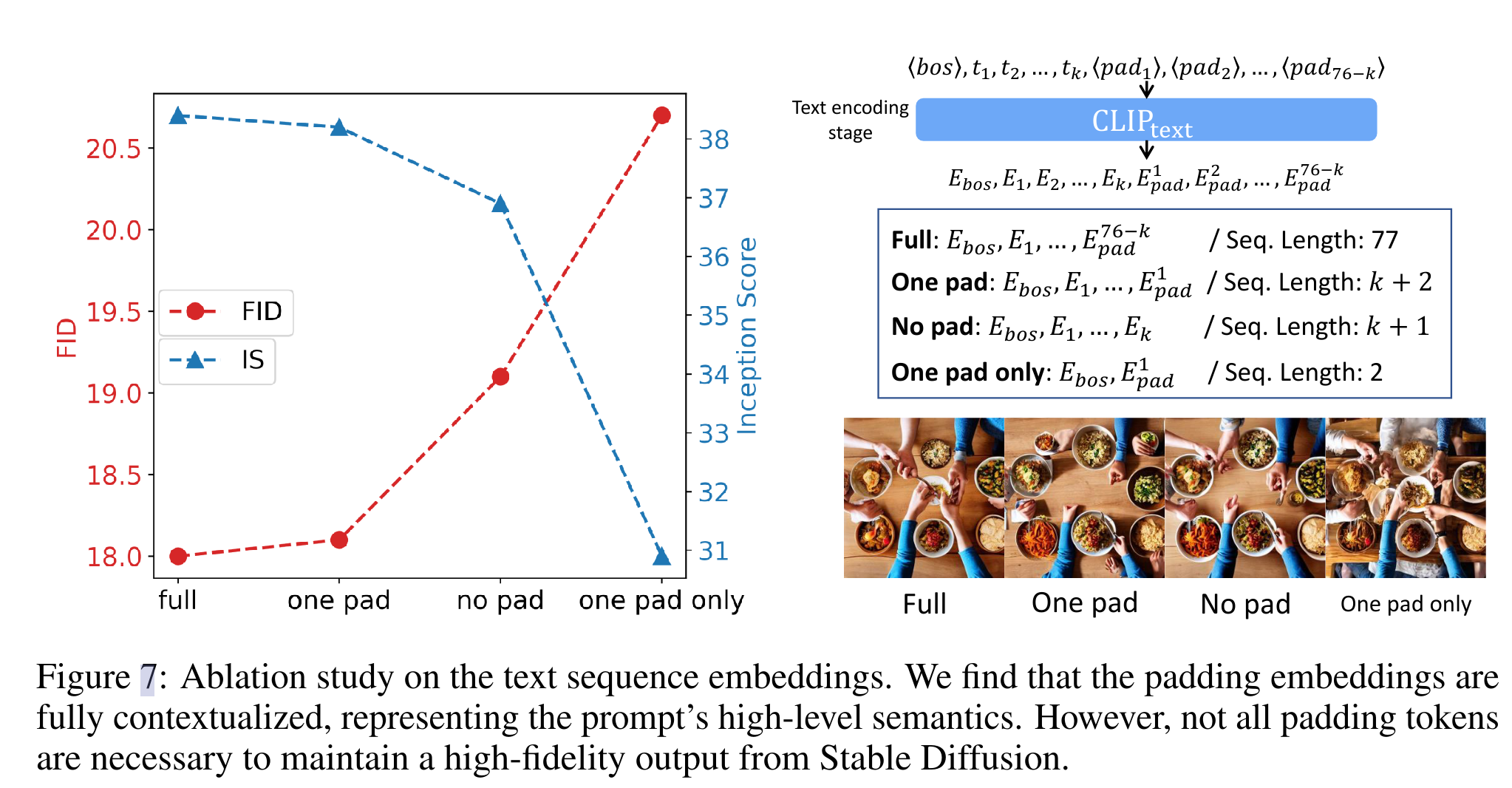
CONTEXTUALIZED TEXT EMBEDDINGS
- StructureDiffusion 带来的一个限制是,交叉注意计算成本会随着名词短语的数量而增加
- 然而,注意到大多数注意力映射是通过填充嵌入计算的,因为 Stable Diffusion 采用CLIP文本编码器,并自动将序列填充为77个标记
- 推测,并非所有的填充标记都是生成高质量图像所必需的。研究了四种不同的 token 嵌入模式后发现,留下最近的填充嵌入保持了与完整序列相似的IS / FID评分。进一步去除这种填充物嵌入会导致明显的掉点。虽然只使用最接近的填充嵌入会导致最差的图像质量,但发现高级图像布局和语义得到了保留。这种现象表明填充嵌入是完全上下文化的,使用的是完整的提示符语义。这也证明了本文的重对齐操作是正确的,它保留了主序列 Wfull 的填充嵌入
Thoughts
- 基于 cross attention 上的操作来实现更准确的文本语义对齐,思路比较简洁