简单学习一下GAN,主要是为了扩增数据集,目前手上数据太少,一个类别30张图片进行数据增强(旋转,反转等)后的数据量也远远不够,因此试图采用GAN来进行生成数据,添加生成的数据再进行检测和分类不知道能否有很好的效果。如下图我的数据集,想批量生成裂纹,再加上电路板背景复杂,不知道能不能行得通。

调研一些paper和博客得出:使用GANs进行简单的数据增强有时可以提高分类器的性能,特别是在非常小或有限的数据集的情况下,但使用GANs进行增强的最有希望的情况似乎包括迁移学习或少量学习。
GAN原理
GAN概念:通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布。

交替迭代训练不断优化调参,使假不断变真。
数学公式:

拆分成优化D和优化G:
优化D:
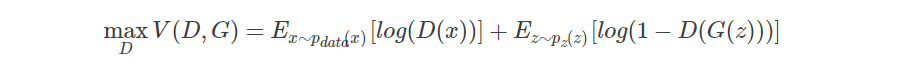
优化G:
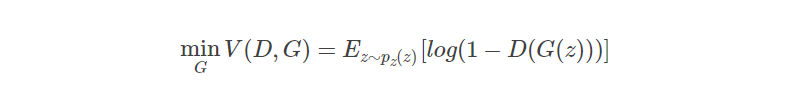
优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好嘛。对于假样本,需要优化是的其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是呢第一项是越大,第二项是越小,这不矛盾了,所以呢把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。 那么同样在优化G的时候,这个时候没有真样本什么事,所以把第一项直接却掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成了最开始的那个最大最小目标函数了。
训练技巧
-
最后一层的激活函数使用tanh(BEGAN除外)
-
使用wassertein GAN的损失函数,
-
如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
-
使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
-
避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
-
优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率
-
给D的网络层增加高斯噪声,相当于是一种正则
主流GAN
对主流GAN模型进行了一系列阅读与分析:
- StyleGAN :适用于人脸合成,效果十分好,但没看到用于其他数据生成,因此不打算用;
- CycleGAN和pix2pix GAN :主要适用于风格迁移,我只打算生成高质量图片,也懒得将background与object分离做配对,与风格变换无关,因此不打算用,后期效果不行在考虑使用这种方法;
- SMOTE :有人用smote算法做对少数类样本进行数据扩增,但只是利用其中的K近邻算法看数据分布,最终是利用GAN进行的数据扩展,在实际应用中,数据集还可能面临的问题不仅是数据不平衡,还有每类样本规模均较小,难以对模型进行有效训练的问题,不打算试。
- SGAN(Semi-Supervised GAN) :在半监督GAN中,Discriminator有N+1个输出,其中N是样本的分类数。该方法可以训练出一个更有效的分类器,同时也能生成具有更高质量的样本,在MNIST实验来看SGAN是否比一般GAN得到更好的生成样本,如图3所示,SGAN(左)的输出要比GAN(右)的输出更为清晰,这看起来对于不同的初始化和网络架构都是正确的,但很难对不同的超参进行样本质量的系统评估。打算试一下

- DCGAN:效果不太行。。。也有可能我的数据集是电路板的,生成出来的图片很虚,可能简单背景的图片可以使用,下图是我生成的图。。。

GAN部分代码实现(mnist为例28x28)
Discriminator Network
#定义判别器 #####Discriminator######使用多层网络来作为判别器
#将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
# 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类。
class discriminator(nn.Module):
def __init__(self):
super(discriminator,self).__init__()
self.dis=nn.Sequential(
nn.Linear(784,256),#输入特征数为784,输出为256
nn.LeakyReLU(0.2),#进行非线性映射
nn.Linear(256,256),#进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256,1),
nn.Sigmoid()
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x=self.dis(x)
return x
Generative Network
####### 定义生成器 Generator #####
#输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
# 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
# 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布
# 能够在-1~1之间。
class generator(nn.Module):
def __init__(self):
super(generator,self).__init__()
self.gen=nn.Sequential(
nn.Linear(100,256),#用线性变换将输入映射到256维
nn.ReLU(True),#relu激活
nn.Linear(256,256),#线性变换
nn.ReLU(True),#relu激活
nn.Linear(256,784),#线性变换
nn.Tanh()#Tanh激活使得生成数据分布在【-1,1】之间
)
def forward(self, x):
x=self.gen(x)
return x
#创建对象
D=discriminator()
G=generator()
if torch.cuda.is_available():
D=D.cuda()
G=G.cuda()
Discriminator Train
判别器的训练由两部分组成,第一部分是真的图像判别为真,第二部分是假的图片判别为假,在这两个过程中,生成器的参数不参与更新。
criterion = nn.BCELoss() #定义loss的度量方式是单目标二分类交叉熵函数
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
进入Training
由于生成器的训练需要用到判别器的输出,首先对判别器进行训练。
img = img.view(num_img, -1) # 将图片展开乘28x28=784
real_img = Variable(img).cuda() # 将tensor变成Variable放入计算图中
real_label = Variable(torch.ones(num_img)).cuda() # 定义真实label为1
fake_label = Variable(torch.zeros(num_img)).cuda() # 定义假的label为0
# 计算真实图片的损失
real_out = D(real_img) # 将真实图片放入判别器中
d_loss_real = criterion(real_out, real_label) # 得到真实图片的loss
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
# 计算假图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 随机生成一些噪声
fake_img = G(z) # 放入生成网络生成一张假的图片
fake_out = D(fake_img) # 判别器判断假的图片
d_loss_fake = criterion(fake_out, fake_label) # 得到假的图片的loss
fake_scores = fake_out # 假的图片放入判别器越接近0越好
# 损失函数和优化
d_loss = d_loss_real + d_loss_fake # 将真假图片的loss加起来
d_optimizer.zero_grad() # 归0梯度
d_loss.backward() # 反向传播
d_optimizer.step() # 更新参数
Generative Train
原理:目的是希望生成的假的图片被判别器判断为真的图片
将D固定,将假的图片传入判别器的结果与真实label对应,反向传播更新的参数是生成网络里面的参数,这样我们就可以通过跟新生成网络里面的参数来使得判别器判断生成的假的图片为真,这样就达到了生成对抗的作用。
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声
fake_img = G(z) # 生成假的图片
output = D(fake_img) # 经过判别器得到结果
g_loss = criterion(output, real_label) # 得到假的图片与真实图片label的loss
# bp and optimize
g_optimizer.zero_grad() # 归0梯度
g_loss.backward() # 反向传播
g_optimizer.step() # 更新生成网络的参数
完整代码(简单)
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
from torch.autograd import Variable
import os
if not os.path.exists('./img'):
os.mkdir('./img')
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1)
out = out.view(-1, 1, 28, 28)
return out
batch_size = 128
num_epoch = 100
z_dimension = 100
# Image processing
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
# MNIST dataset
mnist = datasets.MNIST(
root='./data/', train=True, transform=img_transform, download=True)
# Data loader
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True)
# Discriminator
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid())
def forward(self, x):
x = self.dis(x)
return x
# Generator
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(True),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Linear(256, 784),
nn.Tanh())
def forward(self, x):
x = self.gen(x)
return x
D = discriminator()
G = generator()
if torch.cuda.is_available():
D = D.cuda()
G = G.cuda()
# Binary cross entropy loss and optimizer
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
# Start training
for epoch in range(num_epoch):
for i, (img, _) in enumerate(dataloader):
num_img = img.size(0)
# =================train discriminator
img = img.view(num_img, -1)
real_img = Variable(img).cuda()
real_label = Variable(torch.ones(num_img)).cuda()
fake_label = Variable(torch.zeros(num_img)).cuda()
# compute loss of real_img
real_out = D(real_img)
d_loss_real = criterion(real_out, real_label)
real_scores = real_out # closer to 1 means better
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension)).cuda()
fake_img = G(z)
fake_out = D(fake_img)
d_loss_fake = criterion(fake_out, fake_label)
fake_scores = fake_out # closer to 0 means better
# bp and optimize
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# ===============train generator
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension)).cuda()
fake_img = G(z)
output = D(fake_img)
g_loss = criterion(output, real_label)
# bp and optimize
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], d_loss: {:.6f}, g_loss: {:.6f} '
'D real: {:.6f}, D fake: {:.6f}'.format(
epoch, num_epoch, d_loss.item(), g_loss.item(),
real_scores.data.mean(), fake_scores.data.mean()))
if epoch == 0:
real_images = to_img(real_img.cpu().data)
save_image(real_images, './img/real_images.png')
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1))
torch.save(G.state_dict(), './generator.pth')
torch.save(D.state_dict(), './discriminator.pth')
本次用的pytorch0.5以上版本,因此写成train_loss+=loss.item(),若0.3版本,改为train_loss+=loss.data[0],否则会报错
实验结果:
左图为第100生成图,右边为真实图


完整代码(带卷积)
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
from torch.autograd import Variable
from matplotlib import pyplot as plt
import os
if not os.path.exists('./cnn_img'):
os.mkdir('./cnn_img')
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1)
out = out.view(-1, 1, 28, 28)
return out
batch_size = 128
num_epoch = 100
z_dimension = 100 #噪声维度
# Image processing
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
# MNIST dataset
mnist = datasets.MNIST(
root='./data/', train=True, transform=img_transform, download=True)
# Data loader
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True)
# Discriminator
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, 5, padding=2), # batch,32,28,28
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, stride=2) # batch,32,14,14
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5, padding=2), # batch, 64, 14, 14
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, stride=2) # batch, 64, 7, 7
)
self.fc = nn.Sequential(
nn.Linear(64 * 7 * 7, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# Generator
class generator(nn.Module):
def __init__(self, input_size, num_feature):
super(generator, self).__init__()
# 1.第一层线性变换
self.fc = nn.Linear(input_size, num_feature) # batch, 3136=1x56x56
self.br = nn.Sequential(
nn.BatchNorm2d(1),
nn.ReLU(True)
)
self.conv1_g = nn.Sequential(
nn.Conv2d(1, 50, 3, stride=1, padding=1), # batch, 50, 56, 56
nn.BatchNorm2d(50),
nn.ReLU(True)
)
self.conv2_g = nn.Sequential(
nn.Conv2d(50, 25, 3, stride=1, padding=1), # batch, 25, 56, 56
nn.BatchNorm2d(25),
nn.ReLU(True)
)
self.conv3_g = nn.Sequential(
nn.Conv2d(25, 1, 2, stride=2), # batch, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.fc(x)
x = x.view(x.size(0), 1, 56, 56)
x = self.br(x)
x = self.conv1_g(x)
x = self.conv2_g(x)
x = self.conv3_g(x)
return x
D = discriminator()
G = generator(z_dimension, 3136)
if torch.cuda.is_available():
D = D.cuda()
G = G.cuda()
# Binary cross entropy loss and optimizer
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0001)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0001)
# Start training
for epoch in range(num_epoch):
for i, (img, _) in enumerate(dataloader):
num_img = img.size(0)
#print(img.shape) # inputs:img=[128,1,28,28]
# =================train discriminator
#img = img.view(num_img, -1) # img.shape: [128, 784]
real_img = Variable(img).cuda()
#print(real_img.shape)
real_label = Variable(torch.ones(num_img)).cuda()
fake_label = Variable(torch.zeros(num_img)).cuda()
# compute loss of real_img
real_out = D(real_img)
d_loss_real = criterion(real_out, real_label)
real_scores = real_out # closer to 1 means better
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension)).cuda()
fake_img = G(z)
fake_out = D(fake_img)
d_loss_fake = criterion(fake_out, fake_label)
fake_scores = fake_out # closer to 0 means better
# bp and optimize
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# ===============train generator
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension)).cuda()
fake_img = G(z)
output = D(fake_img)
g_loss = criterion(output, real_label)
# bp and optimize
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], d_loss: {:.6f}, g_loss: {:.6f} '
'D real: {:.6f}, D fake: {:.6f}'.format(
epoch, num_epoch, d_loss.item(), g_loss.item(),
real_scores.data.mean(), fake_scores.data.mean()))
if epoch == 0:
real_images = to_img(real_img.cpu().data)
save_image(real_images, './cnn_img/real_images.png')
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './cnn_img/fake_images-{}.png'.format(epoch + 1))
torch.save(G.state_dict(), './cnn_img/generator.pth')
torch.save(D.state_dict(), './cnn_img/discriminator.pth')
实验结果

左边是真实图片,右边是100epoch生成的图片,我用自己电脑NVIDIA-MX450跑没问题,效果还是可以的
Reference
1.简单理解与实验生成对抗网络GAN
2.GAN以及小样本扩增的论文笔记
3.GAN(生成对抗神经网络)原理解析
4.用GAN生成MNIST数据集之pytorch实现