背景知识
代码实现
本文实现最简单的例子,利用GAN生成MNIST的数字,代码如下:
导入包
%matplotlib inline
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torchvision
from torchvision import models
from torchvision import transforms
# 如果有gpu就用gpu,如果没有就用cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
导入数据集
batch_size=32
# Compose定义了一系列transform,此操作相当于将多个transform一并执行
transform = transforms.Compose([
transforms.ToTensor(),
# mnist是灰度图,此处只将一个通道标准化
transforms.Normalize(mean=(0.5),
std=(0.5))
])
# 设定数据集
mnist_data = torchvision.datasets.MNIST("./mnist_data", train=True, download=True, transform=transform)
# 加载数据集,按照上述要求,shuffle本意为洗牌,这里指打乱顺序,很形象
dataloader = torch.utils.data.DataLoader(dataset=mnist_data,
batch_size=batch_size,
shuffle=True)
在线下载MNIST时如果下载速度特别慢可以更改源码,改为本地。
定义模型
image_size = 784
hidden_size = 256
# Discriminator
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid() # sigmoid结果为(0,1)
)
# Generator
latent_size = 64 # latent_size,相当于初始噪声的维数
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh() # 转换至(-1,1)
)
# 放到gpu上计算(如果有的话)
D = D.to(device)
G = G.to(device)
# 定义损失函数、优化器、学习率
loss_fn = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)
开始训练
# 先定义一个梯度清零的函数,方便后续使用
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
# 迭代次数与计时
total_step = len(dataloader)
num_epochs = 200
start = time.perf_counter() # 开始时间
# 开始训练
for epoch in range(num_epochs):
for i, (images, _) in enumerate(dataloader): # 当前step
batch_size = images.size(0) # 变成一维向量
images = images.reshape(batch_size, image_size).to(device)
# 定义真假label,用作评分
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 对D进行训练,D的损失函数包含两部分
# 第一部分,D对真图的判断能力
outputs = D(images) # 将真图送入D,输出(0,1),应该是越接近1越好
d_loss_real = loss_fn(outputs, real_labels)
real_score = outputs # 真图的分数,越大越好
# 第二部分,D对假图的判断能力
z = torch.randn(batch_size, latent_size).to(device) # 开始生成一组fake images即32*784的噪声经过G的假图
fake_images = G(z)
outputs = D(fake_images.detach()) # 将假图片给D,detach表示不作用于求grad
d_loss_fake = loss_fn(outputs, fake_labels)
fake_score = outputs # 假图的分数,越小越好
# 开始优化discriminator
d_loss = d_loss_real + d_loss_fake # 总的损失就是以上两部分相加,越小越好
reset_grad()
d_loss.backward()
d_optimizer.step()
# 对G进行训练,G的损失函数包含一部分
# 可以用前面的z,也可以新生成,因为模型没有改变,事实上是一样的
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = loss_fn(outputs, real_labels) # G想骗过D,故让其越接近1越好
# 开始优化generator
reset_grad()
g_loss.backward()
g_optimizer.step()
# 优化完成,下面进行一些反馈,展示学习进度
if i % 100 == 0:
print("Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}"
.format(epoch, num_epochs, i, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))
# 训练结束,跳出循环,检验成果
end = time.perf_counter() # 结束时间
total = end - start
minutes = total//60
seconds = total - minutes*60
print("利用GPU总用时:{:.2f}分钟{:.2f}秒".format(minutes, seconds))
结果
...上面结果省略
Epoch [199/200], Step [1600/1875], d_loss: 0.9140, g_loss: 1.4904, D(x): 0.64, D(G(z)): 0.25
Epoch [199/200], Step [1700/1875], d_loss: 0.7004, g_loss: 1.8600, D(x): 0.72, D(G(z)): 0.23
Epoch [199/200], Step [1800/1875], d_loss: 0.8012, g_loss: 1.5045, D(x): 0.72, D(G(z)): 0.27
利用GPU总用时:102.00分钟6.29秒
我的是自己电脑的GPU(NVIDIA 1050ti),经过102分钟,我们已经训练好了网络,接下来看看输出是否满足需求:
检验成果
# 向G输入一个噪声,观察生成的图片
z = torch.randn(1, latent_size).to(device)
fake_images = G(z).view(28, 28).data.cpu().numpy()
plt.imshow(fake_images, cmap = plt.cm.gray)
我们得到输出:
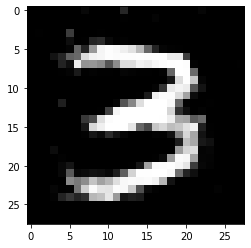
看起来还不错,再对比一下原图:
对比原图
plt.imshow(next(iter(dataloader))[0][0][0], cmap = plt.cm.gray)
原图如下:
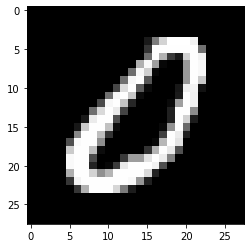
还不错啦!