在机器学习中,随机森林是一个包含多个决策树的分类器,是一种集合算法,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林 = Bagging + 决策树
Bagging集成原理
bagging集成过程
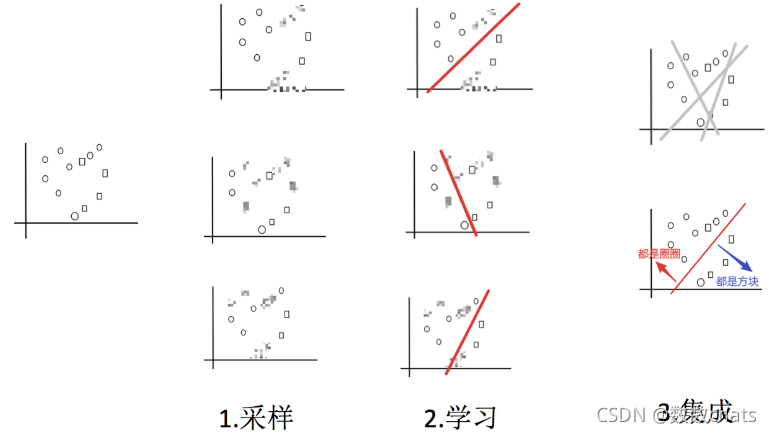
1.采样:从所有样本里面,采样一部分
2.学习:训练弱学习器
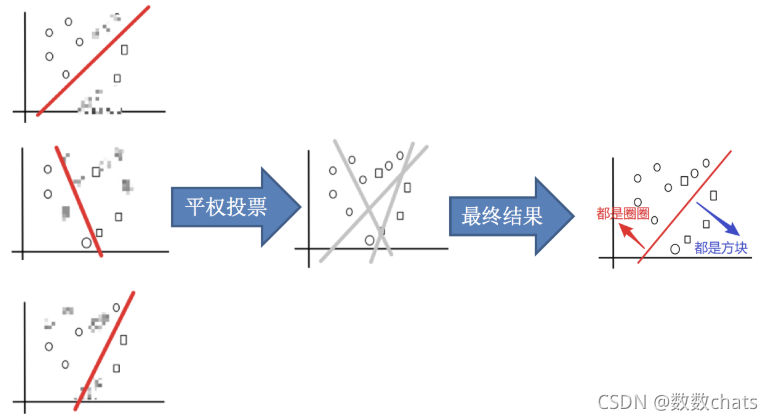
3.集成:使用平权投票
例子:把下面的圈和方块进行分类
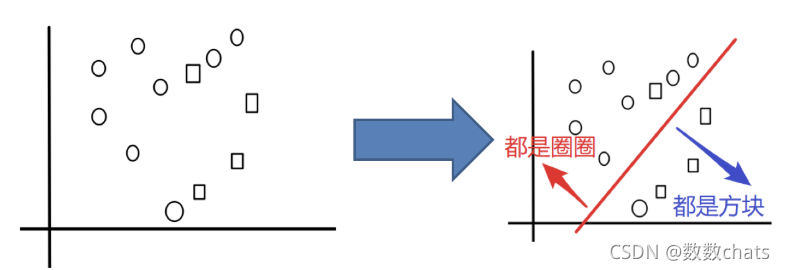
实现过程:
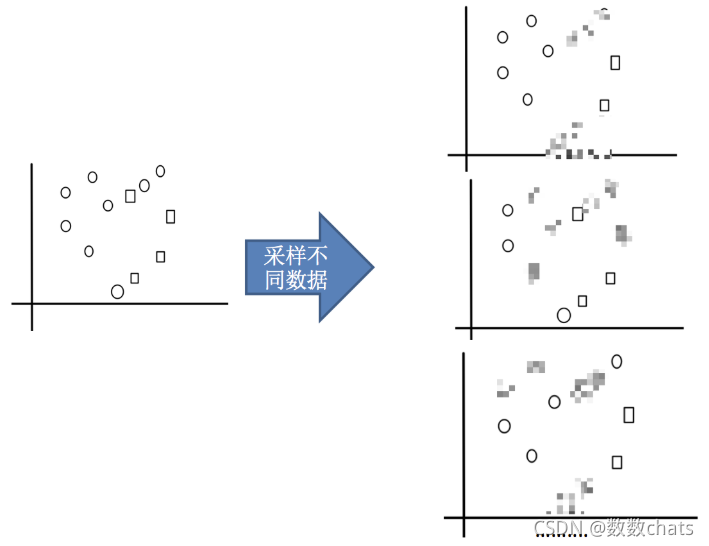
1.采样不同数据集
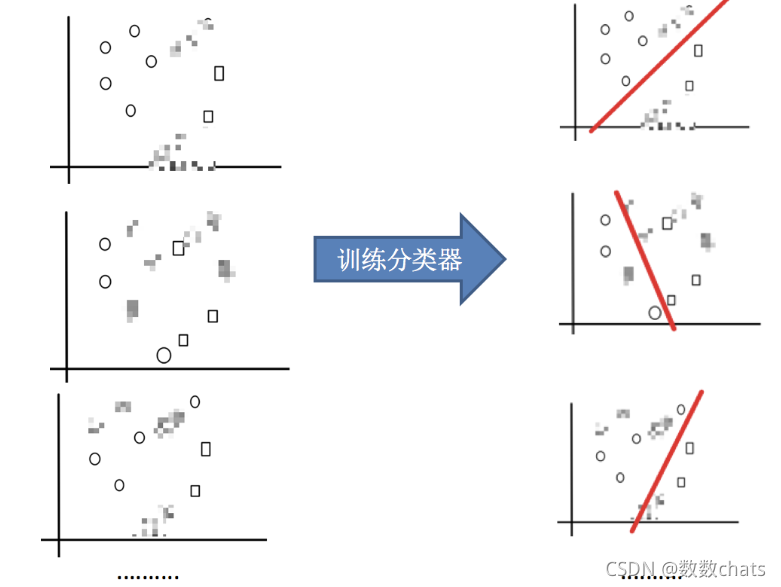
 2.训练分类器
2.训练分类器
3.平权投票,获取最终结果
4.主要实现过程小结
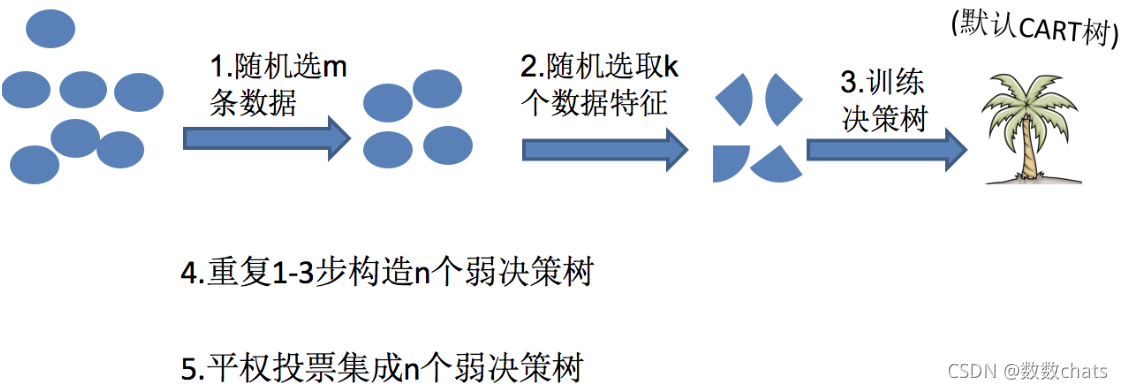
随机森林构造过程
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林够造过程中的关键步骤(用N来表示训练用例(样本)的个数,M表示特征数目):
1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建立决策树
- 思考
-
1.为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的 -
2.为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
-
随机森林api
有DecisionTreeClassifier随机森林分类和DecisionTreeRegressor随机森林回归,这里介绍DecisionTreeClassifier。
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)[source]
-
n_estimators:integer,optional(default = 100)森林里的树木数量;
-
Criterion:string,可选(default =“gini”)不纯度的衡量指标,有基尼系数和信息熵两种选择
-
max_depth:integer或None,可选(默认=无)树的最大深度 ;
-
max_features="auto”,限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃, 默认值为总特征个数开平方取整
- If “auto”, then
max_features=sqrt(n_features). - If “sqrt”, then
max_features=sqrt(n_features)(same as “auto”). - If “log2”, then
max_features=log2(n_features). - If None, then
max_features=n_features.
- If “auto”, then
-
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
-
min_samples_split:节点划分最少样本数
-
min_samples_leaf:叶子节点的最小样本数
-
超参数:n_estimator,max_depth,min_samples_split,min_samples_leaf
例子
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 1、获取泰坦尼克号数据集
titan = pd.read_csv('titanic.csv')
#2、数据基本处理
#2.1 确定特征值,目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
#2.2 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
#2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
#3.特征工程(字典特征抽取)
# 对于x转换成字典数据x.to_dict(orient="records")
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient='records'))
x_test = transfer.fit_transform(x_test.to_dict(orient='records'))
# 4.机器学习(随机森林)
estimator = RandomForestClassifier()
param_grid={
"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
estimator=GridSearchCV(estimator,param_grid=param_grid,cv=3)
estimator.fit(x_train,y_train)
# 5.模型评估
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("调整出来的最佳参数:\n", estimator.best_params_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
随机森林回归填补缺失值
sklearn.impute.SimpleImputer模块中可以轻松地将均值、中值、或者其它常用的数值来对空值进行填补。下面我们将对波士顿房价数据集进行均值、0、随机森林回归来进行缺失值填补,并验证各种情况下的拟合效果,找出最佳的缺失值填补方式。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.datasets import load_boston
from sklearn.impute import SimpleImputer # 对空值进行
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
# 获取数据集 --- 共有 506*13=6578 个数据
boston = load_boston()
x_full = boston.data # 数据集
y_full = boston.target # 标签列
n_samples = x_full.shape[0] # 506行
n_features = x_full.shape[1] # 13列 --- 特征名称
构建缺失值
1.首先确定放入缺失值的比例:50%,也就是共有3289个数据缺失
rng = np.random.RandomState(0) # 随机种子
missing_rate = 0.5 # 缺失值比例
n_missing_samples = int(np.floor(n_samples*n_features*missing_rate)) # np.floor()向下取整,返回.0格式的浮点数
n_missing_samples # 3289
2.缺失值是遍布在506*13的数据表中 ---- 随机位置生成3289个缺失值(行、列组成的网格格数)。类似于DataFrame,我们需要通过索引(行、列)来进行定位,生成缺失值。
missing_samples = rng.randint(0,n_samples,n_missing_samples) # 行中随机取出3289个数据
missing_features= rng.randint(0,n_features,n_missing_samples) # 列中随机取出3289个数据
# 使用上述的方式进行抽样,会使得数据远超样本量506(这里的样本量只按照行来计算)
# 我们还可以使用np.random.choice()来进行抽象,可以抽取不重复的随机数,确保数据不会集中在同一行中,某种程度上也保证了数据的分散度
missing_features
3.生成缺失值
x_missing = x_full.copy() # 对源数据集进行拷贝
x_missing[missing_samples,missing_features] = np.nan # 通过行、列索引随机定位生成缺失值
x_missing = pd.DataFrame(x_missing)
x_missing
缺失值填补
① 均值mean填补
利用sklearn.impute中的SimpleImputer类进行填补,missing_values=np.nan代表当前所需填补值(空值)的类型;strategy='mean’表示填补空值所使用的策略,就是用均值mean来进行填补。
# ①.使用均值进行填补
imp_mean = SimpleImputer(missing_values=np.nan,strategy='mean')
x_missing_mean = imp_mean.fit_transform(x_missing) # 训练fit() + 导出predict() ==> fit_transform()
x_missing_mean = pd.DataFrame(x_missing_mean)
x_missing_mean
② 使用0值填补
strategy=‘constant’,fill_value=0 表示使用常量进行填补,fill_value指明所使用的常数为0。
imp_0 = SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0)
x_missing_0 = imp_mean.fit_transform(x_missing) # 训练fit() + 导出predict() ==> fit_transform()
x_missing_0 = pd.DataFrame(x_missing_0)
x_missing_0
③ 使用随机森林回归填补
任何回归都是从特征矩阵中学习,然后求解连续型标签y的过程,之所以能够实现这个过程,是因为回归算法认为特征矩阵和标签之前存在着某种联系。实际上,标签和特征是可以相互转换的,比如说,在一个“用地区,环境,附近学校数量预测“房价”的问题中,我们既可以用“地区,“环境”,“附近学校数量”的数据来预测“房价”,也可以反过来用“环境”,“附近学校数量”和“房价”来预测“地区”(有点类似"y=kx+b"方程中的知三求一)。而回归填补缺失值,正是利用了这种思想。
对于一个有n个特征的数据来说,其中特征T有缺失值,我们就把特征T当作标签,其他的 n-1 个特征和原本的标签组成新的特征矩阵。那对于T来说,它没有缺失的部分,就是我们的ytrain,这部分数据既有标签也有特征,而它缺失的部分,只有特征没有标签,就是我们需要预测的部分。
特征T不缺失的值对应的其他 n-1个特征+本来的标签:xtrain
特征T不缺失的值:ytrain
特征缺失的值对应的其他 n-1个特征+本来的标签: xtest
特征缺失的值:未知,我们需要预测的ytest
这种做法,对于某一个特征大量缺失,其他特征却很完整的情况,非常适用!
那如果数据中除了特征T之外,其他特征也有缺失值怎么办?
答案是遍历所有的特征,从缺失最少的开始进行填补(因为填补缺失最少的特征所需要的准确信息最少。填补一个特征时,先将其他特征的缺失值用0代替,每完成一次回归预测,就将预测值放到原本的特征矩阵中,再继续填补下一个特征。每一次填补完毕,有缺失值的特征会减少一个,所以每次循环后,需要用0填补的特征就越来越少。当进行到最后一个特征时(这个特征应该是所有特征中缺失值最多的),已经没有任何的其他特征需要用0来进行填补了,而我们已经使用回归为其他特征填补了大量有效信息,可以用来填补缺失最多的特征。
⑴ 缺失值数目排序索引
x_missing_reg = x_missing.copy()
# 找出数据集中,缺失值从小到大排序的特征们的顺序
# np.argsort() --- 返回从小到大排序的顺序所对应的索引
sort_columns_index = np.argsort(x_missing_reg.isnull().sum()).values
sort_columns_index
⑵ 遍历索引填补空值
for i in sort_columns_index:
# 构建新的特征矩阵(没有选中填充的特征 + 原始的标签)和新标签(被选中填充的特种)
df = x_missing_reg
fillc = df.iloc[:,i] # 当前要填值的一列特征 --- 新标签
df = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(y_full)],axis=1) # 其余n-1列和完整标签
# 在新的特征矩阵中对含有缺失值的列进行空值填补
df_0 = SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df)
# 提取出测试集、训练集
ytrain = fillc[fillc.notnull()] # 被选出来要填充的特征列中非空的数据 --- 训练标签
ytest = fillc[fillc.isnull()] # 被选出来要填充的特征列中为空的数据 --- 测试标签
xtrain = df_0[ytrain.index,:] # 在新特征矩阵中,被选出来要填充的特征的非空值所对应的记录
xtest = df_0[ytest.index,:] # 在新特征矩阵中,被选出来要填充的特征空值所对应的记录
# 使用随机森林回归来填补缺失值
rfc = RandomForestRegressor(n_estimators=100).fit(xtrain,ytrain)
y_predict = rfc.predict(xtest)
# 将填补好的特征返回到我们的原始特征矩阵中
x_missing_reg.loc[x_missing_reg.iloc[:,i].isnull(),i] = y_predict
④ 对填补结果进行评估
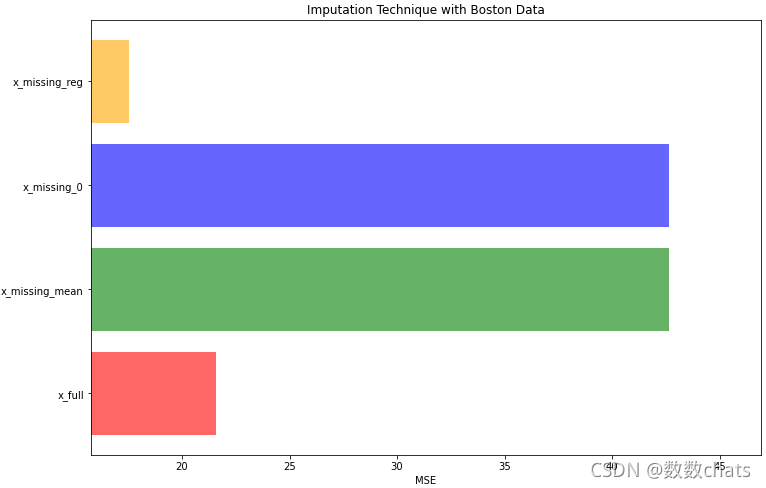
我们接下来使用交叉验证(均方误差),分别对原始数据集、均值填补数据集、0值填补数据集、随机森林回归填补数据集进行打分。
# 对空值填补进行评估
X = [x_full,x_missing_mean,x_missing_0,x_missing_reg]
mse = [] # 使用均方误差进行评估
for x in X:
estimator = RandomForestRegressor(n_estimators=100,random_state=0)
scores = cross_val_score(estimator,x,y_full,scoring='neg_mean_squared_error',cv=5).mean()
mse.append(scores * -1)
mse
[21.571667100368845, 42.62658760318384, 42.62658760318384, 17.52358682764511]
通过评估,可以发现,利用均值、0值进行空值填补均方误差评分达到40以上,而利用随机森林回归填补竟然比原始数据集的拟合效果还要好,均方误差评分低至17.5,当然不排除具有过拟合情况的出现。
# 可视化
plt.figure(figsize=(12,8)) # 画布
colors = ['r','g','b','orange'] # 颜色
x_labels = ["x_full","x_missing_mean","x_missing_0","x_missing_reg"] # 标签
ax = plt.subplot(111) # 添加子图
for i in range(len(mse)):
ax.barh(i,mse[i],color=colors[i],alpha=0.6,align='center')
ax.set_title('Imputation Technique with Boston Data') # 设置标题
ax.set_xlim(left=np.min(mse)*0.9,right=np.max(mse)*1.1) # 设置x轴的范围
ax.set_yticks(range(len(mse)))
ax.set_xlabel("MSE") # 设置x轴标签
ax.set_yticklabels(x_labels) # 设置y轴刻度
plt.show()
调参
对树模型来说,树越茂盛,深度越深,枝叶越多,模型就越复杂。所以树模型是天生位于图的右上角的模型,随机森林是以树模型为基础,所以随机森林也是天生复杂度高的模型。随 机森林的参数,都是向着一个目标去:减少模型的复杂度,把模型往图像的左边移动,防止过拟合。当然了,调参没有绝对。
那具体每个参数,都如何影响我们的复杂度和模型呢?我们一直以来调参,都是在学习曲线上轮流找最优值,盼望 能够将准确率修正到一个比较高的水平。然而我们现在了解了随机森林的调参方向:降低复杂度,我们就可以将那 些对复杂度影响巨大的参数挑选出来,研究他们的单调性,然后专注调整那些能最大限度让复杂度降低的参数。对 于那些不单调的参数,或者反而会让复杂度升高的参数,我们就视情况使用,大多时候甚至可以退避。基于经验, 对各个参数对模型的影响程度做了一个排序。在我们调参的时候,大家可以参考这个顺序。
| 参数 | 对模型在未知数据上的评估性能的影响 | 影响程度 |
|---|---|---|
| n_estimators | 提升至平稳,n_estimators↑,不影响单个模型的复杂度 | ⭐⭐⭐⭐ |
| max_depth | 有增有减,默认最大深度,即最高复杂度,向复杂度降低的方向调参max_depth↓,模型更简单,且向图像的左边移动 | ⭐⭐⭐ |
| min_samples_leaf | 有增有减,默认最小限制1,即最高复杂度,向复杂度降低的方向调参min_samples_leaf↑,模型更简单,且向图像的左边移动 | ⭐⭐ |
| min_samples_split | 有增有减,默认最小限制2,即最高复杂度,向复杂度降低的方向调参min_samples_split↑,模型更简单,且向图像的左边移动 | ⭐⭐ |
| max_features | 有增有减,默认auto,是特征总数的开平方,位于中间复杂度,既可以向复杂度升高的方向,也可以向复杂度降低的方向调参max_features↓, 模 型 更 简 单 , 图 像 左 移 max_features↑,模型更复杂,图像右移max_features是唯一的,既能够让模型更简单,也能够让模型更复杂的参数,所以在调整这个参数的时候,需要考虑我们调参的方向 | ⭐ |
| criterion | 有增有减,一般使用gini | 看具体情况 |