1.集成学习:将若干个弱分类器通过一定的策略组合之后产生一个强分类器。
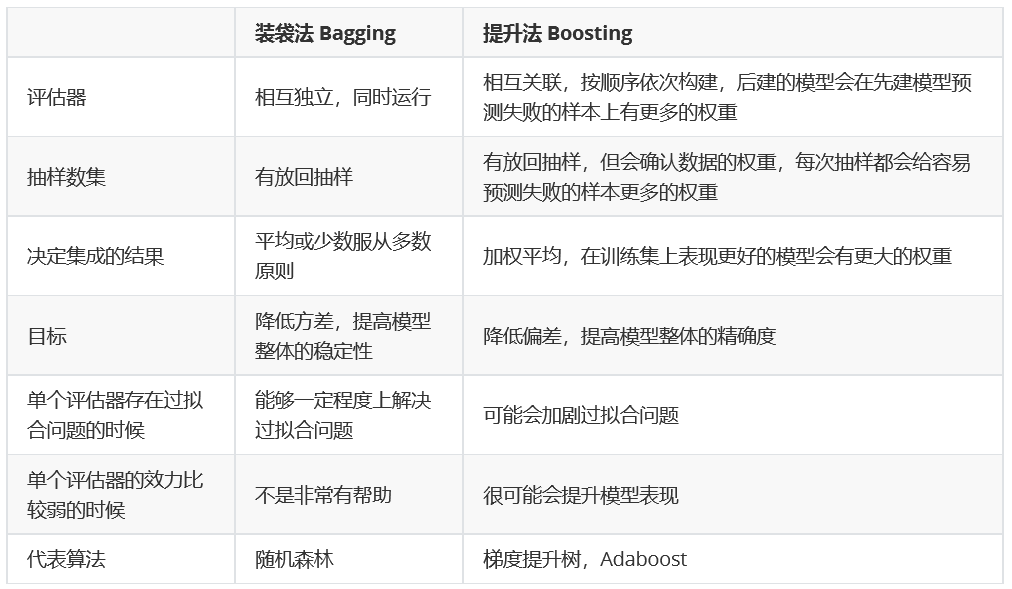
装袋法bagging:多个相互独立的评估器,有放回的随机抽样。代表:随机森林
提升法boosting:赋予权重,每一轮结束时自动调整权重。
stacking
2.组合策略:平均法(数值类回归常用)、投票法、学习法(stacking)
3.集成算法模块ensemble
随机森林分类器
4.重要参数:a.和决策树相同,控制基评估器
criterion、max_depth、min_samples_leaf、min_samples_split、max_features、min_impurity_decrease
b.n_estimators 森林中树木数量,即基评估器的数量 一般越大效果越好
c.random_state 控制生成森林的模式
d.bootstrap 控制抽样技术,默认true,代表采用有放回的随机抽样
n足够大时会有约37%训练数据没有参与建模,可用袋外数据来测试,实例化时将oob_score设为true
5.重要属性:estimators_查看森林中树的状况
oob_score_查看袋外数据测试结果
feature_importances_
6.接口:apply、fit、predict、score
predict_proba返回每个测试样本对应被分到每一类标签的概率
7.用来组成随机森林的分类树们要超过50%的预测正确率。
随机森林回归器
8.重要参数:criterion
9.重要属性:estimators_、oob_score_、feature_importances_
10.接口:apply、fit、predict、score(没有predict_proba)