目录
集成学习
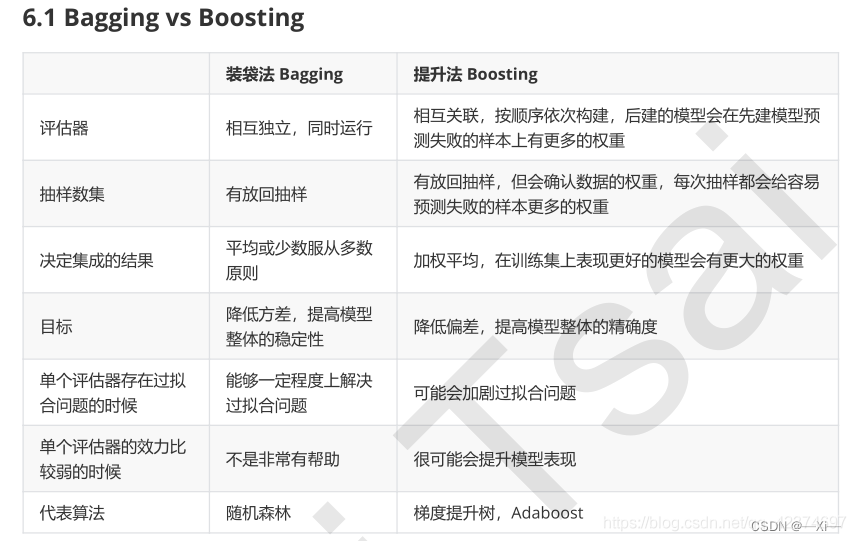
集成学习通过构建多个学习器来完成任务,通过多个弱学习器组成一个强学习器。
Boosting(提升法):
个体学习器之间存在强依赖关系,通过串行生成的序列化方法,通过加法模型将弱分类器(基评估器)进行线性组合。
提高前一轮被弱分类器分错的样本的权重,减少在前一轮被弱分类器分对的样本的权值。

代表算法
- Adaboost
- GBDT
- XGBoost
- LightGBM
Bagging(装袋法):
个体学习器之间不存在强依赖关系,采取并行化

随机森林中,还会随机抽取一定数量的特征。
随机森林
随机森林的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林叫做随机森林回归器。

随机森林参数
随机森林中树的参数

数据集:
链接:https://pan.baidu.com/s/1wUK0-u6pTsMqKy5dqcfQew?pwd=ectd
提取码:ectd
随机森林调参实战:
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV,train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
df = pd.read_csv("creditcard.csv")
data=df.iloc[:,1:31]
data.head()
X = data.loc[:,data.columns != 'Class']
y = data.loc[:,data.columns == 'Class']
num_record_fraud = len(data[data.Class==1])#欺诈的样本数目
fraud_indices = np.array(data[data.Class==1].index)#样本等于1的索引值
normal_indices= np.array(data[data.Class==0].index)#样本等于0的索引值
##随机抽样与正样本同数量的负样本
random_normal_indices = np.random.choice(normal_indices,num_record_fraud,replace = True)
random_normal_indices = np.array(random_normal_indices)
#合并正负样本索引
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
#按索引抽取数据
under_sample_data = data.iloc[under_sample_indices,:]
X_undersample = under_sample_data.loc[:,under_sample_data.columns != 'Class']
y_undersample = under_sample_data.loc[:,under_sample_data.columns == 'Class']
X_train,X_test,y_train,y_test = train_test_split(X_undersample,y_undersample,test_size = 0.3)
rf0 = RandomForestClassifier(oob_score = True,random_state = 666)
rf0.fit(X_train,y_train)
print(rf0.oob_score_)#袋外样本
'''predict返回的是一个预测的值,predict_proba返回的是对于预测为各个类别的概率。
predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 j列的数值是模型预测 第 i 个预测样本为某个标签的概率
并且每一行的概率和为1。'''
y_pred = rf0.predict_proba(X_test)[:,1]#返回模型预测样本标签为1的概率
print('AUC Score(Train): %f' % roc_auc_score(y_test,y_pred))
#0.936046511627907
# AUC Score(Train): 0.976516
#网格搜索
param1 = {'n_estimators':range(10,101,10)}
search1 = GridSearchCV(estimator = RandomForestClassifier(oob_score = True,random_state = 666,n_jobs = 2),
param_grid = param1,scoring = 'roc_auc',cv = 5)
search1.fit(X_train,y_train)
search1.cv_results_,search1.best_params_,search1.best_score_
# {'n_estimators': 70},
# 0.9707089376393281)
#网格搜索
param2 = {'max_depth':range(2,12,2)}
search2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators = 70,oob_score = True,random_state = 666,n_jobs = 2),
param_grid = param2,scoring = 'roc_auc',cv = 5)
search2.fit(X_train,y_train)
search2.cv_results_,search2.best_params_,search2.best_score_
# {'max_depth': 10},
# 0.9710400329003688)
param3 = {'min_samples_split':range(2,8,1)}
search3 = GridSearchCV(estimator = RandomForestClassifier(n_estimators = 70,
max_depth = 10, oob_score = True,
random_state = 666,n_jobs = 2),
param_grid = param3,scoring = 'roc_auc',cv = 5)
search3.fit(X_train,y_train)
search3.cv_results_,search3.best_params_,search3.best_score_
# {'min_samples_split': 4},
# 0.972142760065589)
rf1 = RandomForestClassifier(n_estimators = 70,max_depth = 10, oob_score = True,
min_samples_split = 4,
random_state = 666,n_jobs = 2)
rf1.fit(X_train,y_train)
print(rf1.oob_score_)
y_pred = rf1.predict_proba(X_test)[:,1]#返回模型预测样本标签为1的概率
print('AUC Score(Train): %f' % roc_auc_score(y_test,y_pred))
# 0.9433139534883721
# AUC Score(Train): 0.987851随机森林优缺点总结
RF优点
1.不容易出现过拟合,因为选择训练样本的时候就不是全部样本。
2.可以既可以处理属性为离散值的量,比如ID3算法来构造树,也可以处理属性为连续值的量,比如C4.5算法来构造树。
3.对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出变量的重要性程度,这是一个非常便利的功能。
4.分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法
RF缺点
1.随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
2.对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。