前言
我在初次实现的时候并没有做 三个“选做”的排行榜任务,所以这只是上篇内容,等完成 Pro4 后再完成下篇。
Project 3: Query Execution
做个数据库:2022 CMU15-445 Project3 Query Execution - 知乎 (zhihu.com)
NOTE
-
SQL的执行流程图
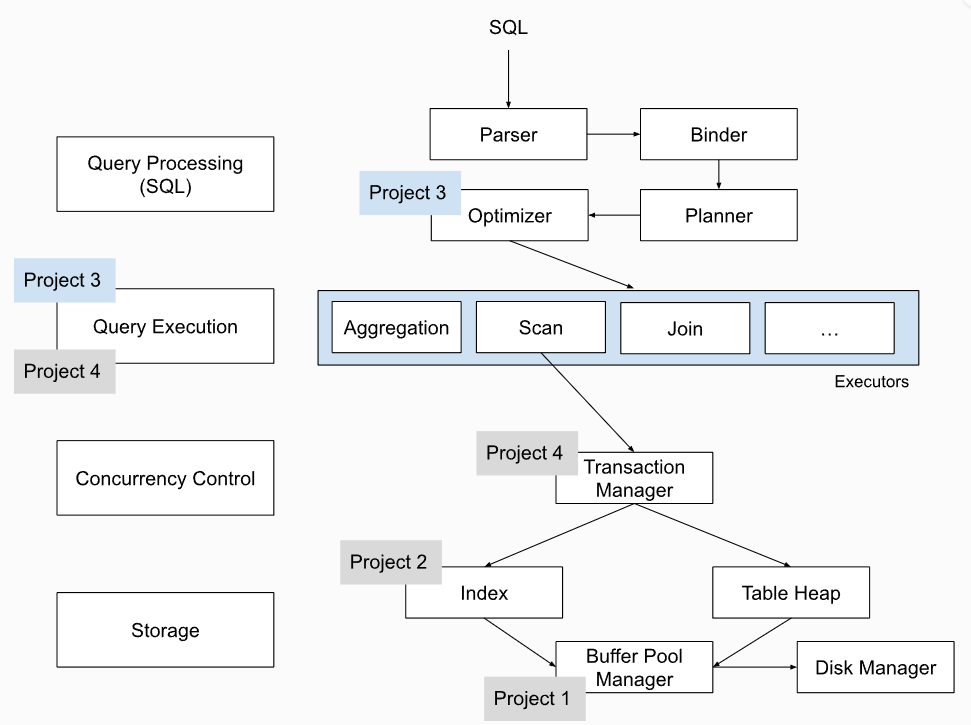
-
Project 3中主要需要实现的内容之一是执行器涉及到的算子,由于在 Planner 中得到了SQL的执行计划树,通过遍历计划树,将树中的 PlanNode 替换成为对应的 Executor 即算子,BusTub中采取的是
Iterator Model,即火山模型/火山模型是数据库中的数据查询执行模型。 它以火山的形状命名,因为它由一个根节点和一系列子节点组成,每个子节点代表数据查询的不同阶段。 根节点是查询的开始,子节点是查询的不同阶段。 火山模型从根节点开始,然后逐级向下执行查询。 每个子节点都处理来自父节点的数据,并生成输出,然后将该输出传递给下一个子节点。 这个过程一直持续到到达叶子节点,叶子节点是查询的结束。
算子的执行方向其实也有两种:
Top to Bottom和Bottom to Top,根据火山模型的思想,自然就是自上而下的 Top-to-Bottom. -
本 Pro 中并不需要实现并发和事务,所以实现相对来说并不困难,但是难点在于理解透 SQL 执行前后涉及到的各个步骤
Task #1: Access Method Executors
需要实现读取和写入存储中的表的执行器
src/include/execution/seq_scan_executor.hsrc/execution/seq_scan_executor.cppsrc/include/execution/insert_executor.hsrc/execution/insert_executor.cppsrc/include/execution/delete_executor.hsrc/execution/delete_executor.cppsrc/include/execution/index_scan_executor.hsrc/execution/index_scan_executor.cpp
即分为四个小的任务,普通的扫描 SeqScan、插入insert、删除delete、索引扫描index_scan
指导书中提到,使用TableIterator来完成,但是需要注意前置++和后置++。
而TableIterator做了什么呢?首先要明确,TableIterator被定义在storage下,即上一个Pro中主要涉及到的内容。
TableIterator enables the sequential scan of a TableHeap.
其中又使用到了另外一个类TableHeap,而该类的实现 bustub已经做好了。这个类的主要作用就是涉及到表中数据的操作,提供了包括插入,删除(标记删除、实施删除、回滚删除),更新等接口。
TableHeap represents a physical table on disk. This is just a doubly-linked list of pages.
查看具体实现的时候,会发现 TableHeap 中引用了另外一个类,即 TablePage,该类继承自 Page 类。
再来回顾一下 B+ Tree 中的说明,每一个叶子结点中的空间结构是如下所示的:

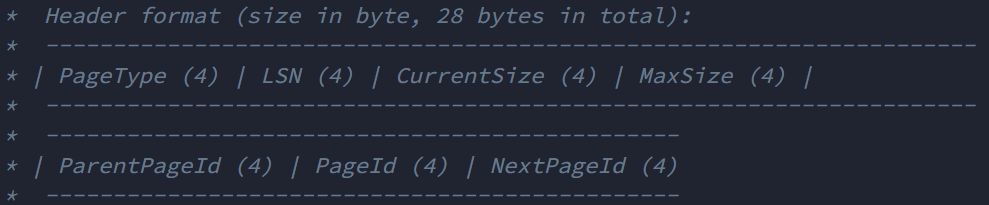
而 Table Page 的结果则是如下所示:
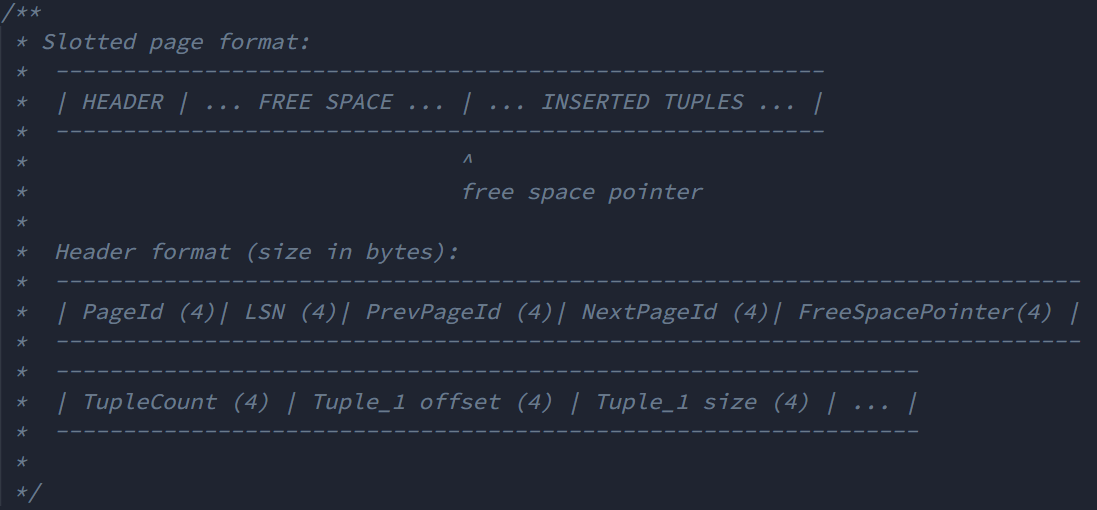
可见其中多了 诸如 PrevPageId 和 NextPageId 这种用于将 Table Page 构成双向链表的指针,也有用于记录 Tuple 个数,以及第一个Tuple 偏移量和大小的 数据。如下偏移量,也是与上述结构对应的上的:
static constexpr size_t SIZE_TABLE_PAGE_HEADER = 24;
static constexpr size_t SIZE_TUPLE = 8;
static constexpr size_t OFFSET_PREV_PAGE_ID = 8;
static constexpr size_t OFFSET_NEXT_PAGE_ID = 12;
static constexpr size_t OFFSET_FREE_SPACE = 16;
static constexpr size_t OFFSET_TUPLE_COUNT = 20;
static constexpr size_t OFFSET_TUPLE_OFFSET = 24; // Naming things is hard.
static constexpr size_t OFFSET_TUPLE_SIZE = 28;
(确实,给变量起名字是相当困难的)
以及对应成员变量的获取与设置函数,同样也包含插入,删除(标记删除、实施删除、回滚删除),更新等接口。
可以理解为,物理内存由 Table Page 来决定,而逻辑结构则由 Table Head 来决定。
所以,如果要实现我们所需的功能,自然需要在 SeqScanExecutor 中引入 TableIntertor 类。
在指导书的附加信息中,提到了 System Catalog ,即数据库并非是通过直接访问数据页来完成数据的增删查改,而是通过维护一个内部目录,来 traces 数据库中的元数据,在本项目中,同样需要通过与 System Catalog 的交互,以查询有关表、索引以及架构的信息。该类的实现在src/include/catalog/catalog.h中,无论是ExecutorContext还是SeqScanPlanNode,都引入了这个类,而Tuple同样也引入了相关的头文件。catalog类的功能则是:
The Catalog is a non-persistent catalog that is designed for use by executors within the DBMS execution engine. It handles table creation, table lookup, index creation, and index lookup
因此,其中包含了 表名与表id之间的map,表id与 TableInfo 之间的map,索引与 IndexInfo 之间的map,表名 与(索引名,索引id)之间的map。
而原本该类中引入的AbstractExecutor,ExecutorContext,SeqScanPlanNode,Tuple,Schema,大概的功能如下:
- AbstractExecutor:火山式元组迭代器模型的实现,也是其余 Executor 的基类
- ExecutorContext:存储了一个 Executor 的过程中所有必要的内容,包括 Transaction、Catalog、Buffer Pool Manager、Log Manager、Lock Manager、Transaction Manager对象和获取对象的接口。算子的很多变量,也就是来自于此。
- SeqScanPlanNode:继承自 AbstractPlanNode,表示 执行计划结点类型,每个节点会接收子节点的输出元组作为输入,且顺序相当重要。接口则主要涉及到执行计划的输出、获取子节点等。
- Tuple:有三个友类,就是刚刚提到的 TablePage、TableHeap、TableIterator,这种设计方法也很值得借鉴。
- Schema:类如其名,主要接口多是关于获取表中的列的相关信息
最后,此处引用本节开头引用到的文章中,绘制的一张图,我觉得相当之好:
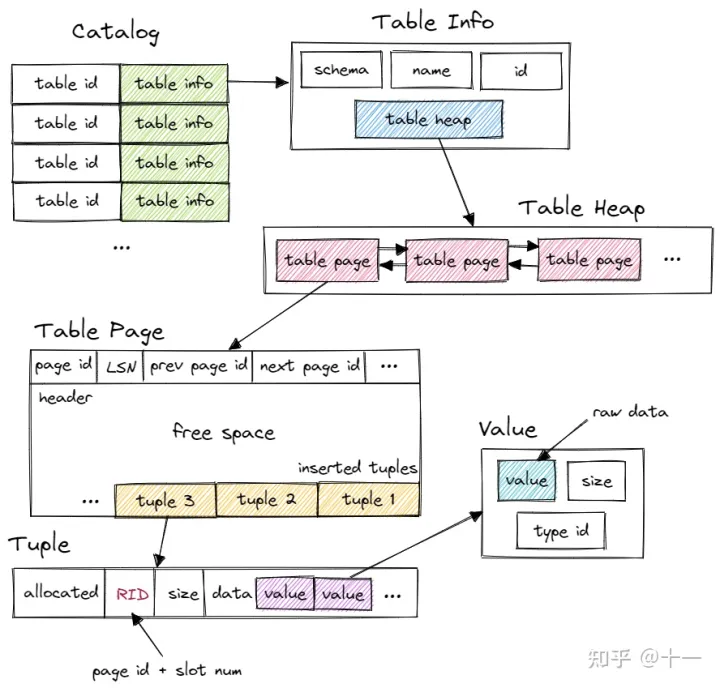
SeqScan
了解完涉及到的类之后,就可以开始实现 Sequence Scan 了。
TableIterator table_iter_ = {nullptr, RID(), nullptr};
const TableInfo *table_info_;
首先在成员变量中引入 TableIterator 和 TableInfo,此处使用到了C++11中的列表初始化。
该算子初始化的时候,必然要得到执行节点中得到的 table info;指导书中也提了 SeqScanExecutor 的目的:
The
SeqScanExecutoriterates over a table and returns its tuples, one-at-a-time.
而输出则是:
The output of sequential scan is a copy of each matched tuple and its original record identifier (
RID).
所以,另外俩接口的目的各自是:
Init:获取 TableIterator 的首个 TupleNext:The output of sequential scan is a copy of each matched tuple and its original record identifier (RID).
Insert
关于InsertExecutor,相关提示在于:
-
初始化时,需要查找到插入目标的表信息。此处和SeqScan一致,使用Catalog即可。
-
插入一条记录后,需要修改该操作修改到表中所有索引,可以借由
Catalog::GetTableIndexes()来实现,该函数的实现也很直接,找到对应表名的map,并返回该表中的所有索引,类型为std::vector<IndexInfo *>。std::vector<IndexInfo *> indexes{}; indexes.reserve(table_indexes->second.size()); for (const auto &index_meta : table_indexes->second) { auto index = indexes_.find(index_meta.second); BUSTUB_ASSERT((index != indexes_.end()), "Broken Invariant"); indexes.push_back(index->second.get()); // 获取unique_ptr的原本指针 }往深了看,IndexInfo是个包含了与索引相关信息的结构体,其是对 Index 类的封装,而Index 类又是对 IndexMetadata类的封装,根据注释,Index起到的是对外提供接口的作用,而隐藏 IndexMetadata 类的细节。IndexMetadata 类中,包含了索引的名,表名,Schema(该变量主要包含的是一个表中与 Colnum 的相关信息),和
key_attrs,关于此变量,其实现的基础如下:假设我们有一个索引,它的索引键由基表的列 0、1 和 3 组成,那么
key_attrs_就会存储这些列在基表中的索引位置。例如,如果索引键包含基表的列id(索引位置为0)、name(索引位置为1)和age(索引位置为3),那么key_attrs_的值将是一个包含{0, 1, 3}的整数向量。这样,当需要使用索引键来查找基表数据时,可以根据
key_attrs_的内容将索引键正确地映射回基表的列。在执行索引查询时,通过索引键来获取基表列的值,然后使用这些值进行数据定位和查询。需要注意的是,
key_attrs_中的索引位置对应于基表的列顺序,因此必须确保索引键的顺序与基表列的顺序相匹配。如果索引键的列顺序与基表列的顺序不匹配,将导致数据查询出现错误或无法定位。然而,我不理解为什么要在 Index 类的基础上再用结构体进行封装,此处存疑。
-
使用
TableHeap类来执行表修改,借由此前那张图可以看出,TableInfo 中就包含 TableHeap 对象。
根据 bustub 的相关执行结果,可以看出,插入执行的结果中,还有一个子执行器 Value,所以 InsertExecutor 需要一个 子执行器。
bustub> EXPLAIN (o,s) INSERT INTO t1 VALUES (1, 'a'), (2, 'b');
=== OPTIMIZER ===
Insert { table_oid=22 } | (__bustub_internal.insert_rows:INTEGER)
Values { rows=2 } | (__values#0.0:INTEGER, __values#0.1:VARCHAR)
但是你会发现,在该类的构造函数中,传入的参数为AbstractExecutor,并非ValueExecutor,之所以这么做,是因为在C++中,使用借由智能指针实现多态,允许将派生类的实例指针赋值给基类指针或者是智能指针,此处就可以传入相关的子类实现更加灵活的功能。
此处多提一句,在我浏览源代码的时候,发现 执行器 是借由工厂模式实现的,此处也提供了一个很好的实际样例。
刚刚才提到使用TableHeap完成插入记录,该类中InsertTuple的实现,大概就是找到 第一个有足够空间的 Page,如果没有,就新建一个 Page 并把记录插入其中。
而为了实现一条记录中所有索引的更新,就需要遍历此前初始化 InsertExecutor 时获取到的表中的所有 IndexInfo,实现如下
// insert tuple success
if (inserted) {
std::for_each(table_indexes_.begin(),
table_indexes_.end(),
[&insert_tuple, &rid, &table_info = table_info_, &exec_ctx = exec_ctx_]
(IndexInfo *index) {
index->index_->InsertEntry(
insert_tuple.KeyFromTuple(table_info->schema_,
index->key_schema_,
index->index_->GetKeyAttrs()),
*rid,
exec_ctx->GetTransaction());
});
insert_count++;
}
此处即可以发现,通过调用 Index 类的 InsertEntry 函数,即可实现索引值在B+树中的更新。回顾一下,Pro2 中实现了 index iterator,而 另有一个类BPlusTreeIndex,其继承自 Index 类,而其中包含了一个变量,BPlusTree<KeyType, ValueType, KeyComparator> container_,就建立起了与 Pro2 中主要实现的 B+树之间的关联。
void BPLUSTREE_INDEX_TYPE::InsertEntry(const Tuple &key, RID rid, Transaction *transaction) {
// construct insert index key
KeyType index_key;
index_key.SetFromKey(key);
container_.Insert(index_key, rid, transaction); // Insert 函数就是我们在 Pro2 中实现的
}
总而言之,就是通过KeyFromTuple函数,从表结构中获取到由值类型和 key scheme组成的 Tuple,传入InsertEntry,继而插入到相应的索引树中。也通过这个小任务,可以建立起与 Pro2 的关联。
delete
关于 DeleteExecutor,需要注意的是,此处只是做标记记录待删除,而真正的删除操作,是在事务提交的时候。
这个实现就没什么难度了,有了前车之鉴(Insert),把 Insert 的操作,更换成 Delete 相关的即可。
IndexScan
指导书中说到了,本项目中,执行计划的索引对象始终为BPlusTreeIndexForOneIntegerColumn,可以安全地将其转化并存储在执行器对象中,例如:
tree_ = dynamic_cast<BPlusTreeIndexForOneIntegerColumn *>(index_info_->index_.get())
然后,可以从索引对象构造索引迭代器,扫描所有键和元组 ID,从表堆中查找元组,并按索引键的顺序发出所有元组作为执行器的输出。 BusTub 仅支持具有单个唯一整数列的索引。测试用例中不会有重复的键。
索引迭代器是如何构造的呢?理所应当的想到 Pro2 中实现的内容,当引入BPlusTreeIndexForOneIntegerColumn时,可以发现:

实现起来也很简单,首先暂时不用考虑需要初始化,而Next函数就根据 迭代器,获取下一个 Tuple即可。
测试
测试文件在test/sql下,
make -j$(nproc) sqllogictest
每次测试前需要重新编译 sqllogictest,而 Task#1 中涉及到的测试语句则包括:
./bin/bustub-sqllogictest ../test/sql/p3.01-seqscan.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.01-seqscan.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.02-insert.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.03-delete.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.04-index-scan.slt --verbose
Task #2: Aggregation and Join Executors
Aggregatiion
聚合的作用在于将一组值按照给定的结果进行合并。
根据指导书,AggregationPlanNode用于:
- GROUP BY(分组)
- COUNT/COUNT(*)、MIN、MAX(规则)
下面是指导书中的说明:
AggregationExecutor 不需要考虑处理 “HAVING” 过滤条件。原本 HAVING 的作用是对分组后的结果进行条件筛选,也可以用于在聚合计算后对聚合结果进行条件筛选。而在本实验中,planner 会将
having处理成为FilterPlanNode。因此,聚合执行器只需要对每组输入执行聚合,也就只有一个子节点(见执行计划输出结果,为MockScan) => 原本 “HAVING” 关键字也有聚合效果,但是本实验把它当作了 Filter 算子,因此 Aggregate 算子只需要考虑把“扫描”得到的结果做聚合即可。本实验中可以假设所有的聚合结果(即从数据表中得到的数据)都保存在内存中的哈希表里,即无需按照课程中提到的两阶段哈希实现 => 无需考虑使用BPM管理内存
本实验中需要填写的是
SimpleAggregationHashTable类中的CombineAggregateValues函数。
当你通过执行计划,观察到下面这四条语句的结果时:
EXPLAIN SELECT colA, MIN(colB) FROM __mock_table_1 GROUP BY colA;
EXPLAIN SELECT COUNT(colA), min(colB) FROM __mock_table_1;
EXPLAIN SELECT colA, MIN(colB) FROM __mock_table_1 GROUP BY colA HAVING MAX(colB) > 10;
EXPLAIN SELECT DISTINCT colA, colB FROM __mock_table_1;
再联合AbstractPlanNode中的 ToString 函数可以看出,Agg 的子节点为 MockScan:
EXPLAIN SELECT colA, MIN(colB) FROM __mock_table_1 GROUP BY colA;
=== PLANNER ===
Projection {
exprs=[#0.0, #0.1] } | (__mock_table_1.colA:INTEGER, <unnamed>:INTEGER)
Agg {
types=[min], aggregates=[#0.1], group_by=[#0.0] } | (__mock_table_1.colA:INTEGER, agg#0:INTEGER)
MockScan {
table=__mock_table_1 } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
/** @return the string representation of the plan node and its children */
auto ToString(bool with_schema = true) const -> std::string {
if (with_schema) {
return fmt::format("{} | {}{}", PlanNodeToString(), output_schema_, ChildrenToString(2, with_schema));
}
return fmt::format("{}{}", PlanNodeToString(), ChildrenToString(2, with_schema));
}
指导书中提到了在查询计划执行阶段,Aggregation 是 pipeline breaker,意思是在整个查询计划的执行过程(即Pipeline)中,其他的算子,例如SeqSacn,一步一步往下执行并不会影响最终的遍历结果,但是由于聚合操作需要遍历完成整张表,不能遍历到一半就输出聚合结果,万一后面还有与当前字段重复的值呢?再新增到此前得到的结果里去,会极大地增大查询计划的执行难度。
因此,在 Init Aggregation 时,就需要把分组的结果都算出来,而不是像 Task#1 中,可以一条又一条tuple地去 Next 执行。以下面这条语句为例:
SELECT t.x, max(t.y) FROM t GROUP BY t.x;
假设表中数据为:
x | y
-----
1 | 5
1 | 8
2 | 3
2 | 6
3 | 10
结果为:
x | max(t.y)
-----------
1 | 8
2 | 6
3 | 10
在遍历完整张表后,把相同的t.x聚合在一起,每个 tuple 都是一个 t.x的聚合,根据聚合规则选出max(t.y)。保存中间结果的地方,就是SimpleAggregationHashTable,其关键的成员变量就是一张哈希表:
std::unordered_map<AggregateKey, AggregateValue> ht_{};
key 和 value 分别如上所示,但两者本质上都是一个std::vector<Value>类型的数组。key 保存 GROUP BY 字段中涉及到的字段,而 value 则是需要执行聚合规则的字段。
以下面这句为例:
SELECT min(t.z), max(t.z), sum(t.z) FROM t GROUP BY t.x, t.y;
group by(AggregateKey)为 {t.x, t.y},即按照这两个字段分组;
aggregate(AggregateValue)为 {t.z, t.z, t.z},规则为 {min, max, sum},即找出这两组中 z 值中最小、最大以及和。
当下层的算子传来一个tuple的时候(比如SeqScan),就根据 GROUP BY 字段和 Aggregate 把对应的字段提取到 key 和 value 中。调用 InsertCombine() 将 group by 和 aggregate 的映射关系,通过CombineAggregateValues传入的参数,最终存入 SimpleAggregationHashTable的成员变量 ht_中。
若当前哈希表中没有 group by 的记录,则创建初值;若已有记录,则按 aggregate 规则逐一更新所有的 aggregate 字段,例如取 max/min,求 sum 等等。
void InsertCombine(const AggregateKey &agg_key, const AggregateValue &agg_val) {
if (ht_.count(agg_key) == 0) {
ht_.insert({agg_key, GenerateInitialAggregateValue()});
}
// key为哈希表中已有的 agg_key 项,即分组字段
// 而agg_val则是 聚合字段
CombineAggregateValues(&ht_[agg_key], agg_val);
}
private:
/** The hash table is just a map from aggregate keys to aggregate values */
std::unordered_map<AggregateKey, AggregateValue> ht_{};
可以见得,除了 COUNT(*)这种聚合规则之外,其余的都设初值为GetNullValueByType,即设“NULL”值,即所有的聚合规则此时都已初始化好,就看语句中到底是什么了。
/** @return The initial aggregrate value for this aggregation executor */
auto GenerateInitialAggregateValue() -> AggregateValue {
std::vector<Value> values{};
for (const auto &agg_type : agg_types_) {
switch (agg_type) {
case AggregationType::CountStarAggregate:
// Count start starts at zero.
values.emplace_back(ValueFactory::GetIntegerValue(0));
break;
case AggregationType::CountAggregate:
case AggregationType::SumAggregate:
case AggregationType::MinAggregate:
case AggregationType::MaxAggregate:
// Others starts at null.
values.emplace_back(ValueFactory::GetNullValueByType(TypeId::INTEGER));
break;
}
}
return {values};
}
而 CombineAggregateValues 函数,就需要根据传入的 Key,对 Value 做判断,此处以 COUNT() 为例,当传入的Key为 NULL 时,就表示此前还没有对应的 key 传入。
case AggregationType::CountAggregate:
// init
if (result->aggregates_[i].IsNull()) {
result->aggregates_ = ValueFactory::GetIntegerValue(0);
}
// add
if (!input->aggregates_[i].IsNull()) {
result->aggregates_[i] = result->aggregates_[i].Add(ValueFactory::GetIntegerValue(1));
}
break;
static inline auto GetIntegerValue(int32_t value) -> Value { return {TypeId::INTEGER, value}; }
struct AggregateValue {
/** The aggregate values */
std::vector<Value> aggregates_;
};
而Value类是什么呢?根据代码中的注释
A value is an abstract class that represents a view over SQL data stored in some materialized state. All values have a type and comparison functions, but subclasses implement other type-specific functionality.
可以得知,Value就是物化状态下SQL数据的视图。PPT中关于这一点也有说明:
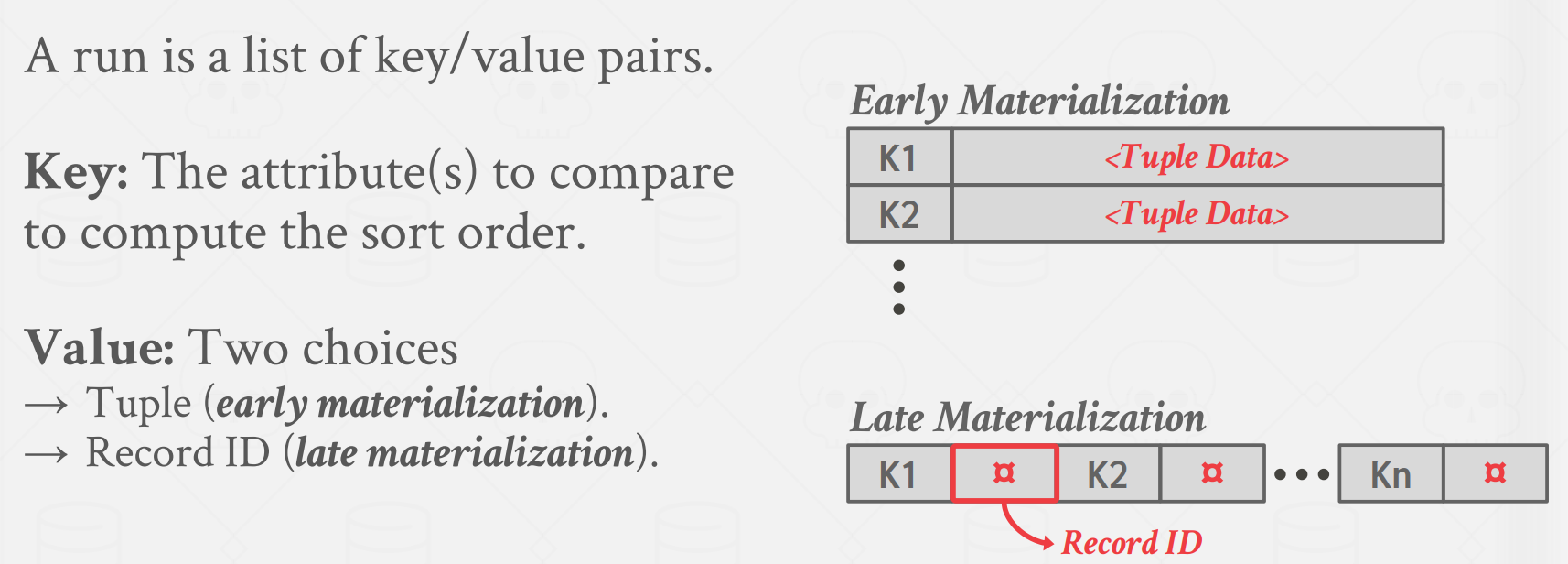
物化状态可以理解为 具有某种具体的状态 而非抽象,所有继承自 Value 类的对象都具有明确的类型和比较函数,便于 Sort。
图中提到了两种物化方式,分别为:
-
Early Materialization(早期物化):
数据在查询执行的早期阶段就被转换为实际的物理存储形式,通常是在查询计划的初始阶段。这意味着查询的结果会立即生成并存储在某种临时表或中间结果中,即使在实际需要时还没有被其他查询使用。
早期物化的优点是它可以加速后续查询的执行,因为结果已经预先计算并存储,不需要再重新计算。然而,它的缺点是可能会导致存储和计算资源的浪费,特别是当中间结果很大或者某些中间结果最终未被使用时。
-
Late Materialization(延迟物化):
在延迟物化中,查询执行引擎尽可能推迟数据的实际计算和存储,直到实际需要结果时才执行。这意味着在查询计划中,可能存在一系列的转换和操作,并且只有在必要时才会进行实际计算。
延迟物化的优点是最大程度地减少了资源的浪费。中间结果只有在需要时才会被计算,这在某些情况下可以大大节省存储和计算开销。然而,延迟物化可能导致查询的执行时间较长,因为每次查询都需要重新计算结果。
而实验中采取的就是早期物化的方式,即在聚合的初始化阶段就得到结果后就把数据存到物理媒介中,一开始的时候说过不需要考虑内存充不充分的问题,也就是为这里做的铺垫。
到这里为止,大概就可以理解 Aggregate Executor类中需要做什么了。而在 Aggregate Executor 类中,则需要添加以下两个成员变量:
/** Simple aggregation hash table */
SimpleAggregationHashTable aht_;
/** Simple aggregation hash table iterator */
SimpleAggregationHashTable::Iterator aht_iterator_;
具体实现如下:
// 初始化时就应当通过子执行器,处理好所有待聚合的字段
void AggregationExecutor::Init() {
child_->Init();
Tuple tuple{};
Rid rid{};
// get tuple from child executor
while (child_->Next(&tuple, &rid)) {
aht_.InsertCombine(MakeAggregateKey(&tuple), MakeAggregateValue(&tuple));
}
aht_iterator_ = aht_.Begin();
}
auto AggregationExecutor::Next(Tuple *tuple, RID *rid) -> bool {
if (aht_iterator_ == aht_.End()) {
return false;
}
std::vector<Value> values;
values.insert(values.end(), aht_iterator_.Key().group_bys_.begin(), aht_iterator_.Key().group_bys_.end());
values.insert(values.end(), aht_iterator_.Val().aggregates_.begin(), aht_iterator_.Val().aggregates_.end());
*tuple = Tuple{values, &GetOutputSchema()};
++aht_iterator_;
return true;
}
Nested Loop Join
Nest 本意为“鸟巢”,此处整个单词翻译为嵌套循环连接,通过执行如下示例可以了解一些 JOIN 的 Plan:
EXPLAIN SELECT * FROM __mock_table_1, __mock_table_3 WHERE colA = colE;
EXPLAIN SELECT * FROM __mock_table_1 INNER JOIN __mock_table_3 ON colA = colE;
EXPLAIN SELECT * FROM __mock_table_1 LEFT OUTER JOIN __mock_table_3 ON colA = colE;
在做本小节内容的时候,我根据指导书中的建议,看了看课。
本节主要实现的就是课程中所讲的 嵌套循环连接算法,
for each tuple in the join’s outer table, you should consider each tuple in the join’s inner table, and emit an output tuple if the join predicate is satisfied.
其核心思想也是非常简单,伪代码如下:
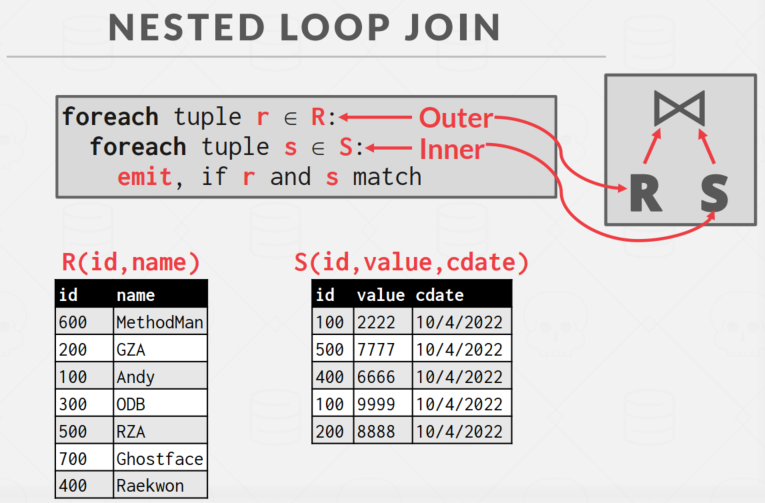
就是循环读 R 表中的每个页 r, 再嵌套一次循环读 S 表的每个页 s,再判断是否应该 emit Join。
此处需要知道的是,外层循环往往是 Page 小的那张表,而并非说是 tuple 小的,如果表够宽,一个 Page 中存不下几条 tuple,那么对于这种持久化的数据库而言,读取 Page 到磁盘中的IO开销就会更大一些。
这种算法也被称为 Stupid/Simple Nested Loop Join,原因在于,如果 Buffer Pool 的大小不足以保留 S 表的每一个 Page,那么当遍历第二个 r 的时候,就需要重新从磁盘把第一个 s 读到 Buffer Pool 中,导致整体的 IO 效率很大。同时,需要注意,
课中还举了一个例子计算这种 Join 方法的开销,可见

而之后的 Index Nested Loop Join,不同之处在于此时遍历的是表中的索引。
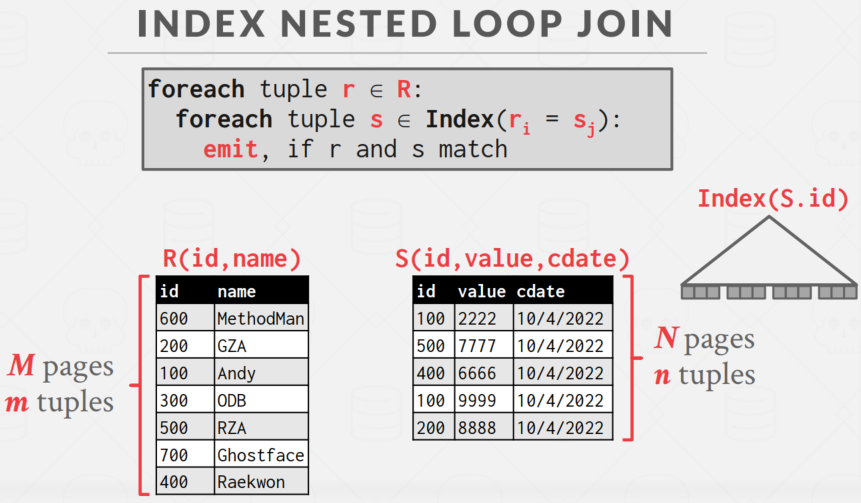
另还有一种优化的方法,Block Nested Loop Join,由于 Pro 中不涉及,此处就不再赘述。
接下来就是实现过程,从 NestedLoopJoinExecutor 的构造函数可见,两个孩子结点,Join 语句通常将在查询语句中出现在"JOIN"关键字之前的表称为"左表",而出现在"JOIN"关键字之后的表称为"右表",此处我们也照猫画虎,left 就是外层循环遍历表后 emit 的结果,而 right 就是内层需要与外层结果一一匹配的遍历结果。
NestedLoopJoinExecutor(ExecutorContext *exec_ctx, const NestedLoopJoinPlanNode *plan,
std::unique_ptr<AbstractExecutor> &&left_executor,
std::unique_ptr<AbstractExecutor> &&right_executor);
此处需要注意的是,由于正常的匹配过程中,right_executor 的遍历结果需要不断地从头开始与 left_executor 的 tupe进行匹配,如果通过 Next 方法,遍历一遍就到头了,此后再 right_executor->Next() 的结果都会是 false,因此我们可以考虑在初始化阶段,把 right_excutor 的结果记录到 tuple 数组中,这样就可以避免每次都遍历一遍 right_excutor 了。
指导书中提到需要考虑 NestedLoopJoinPlanNode 中获取谓词,即要匹配的条件是什么,该类中有如下定义:
/** @return The predicate to be used in the nested loop join */
auto Predicate() const -> const AbstractExpression & { return *predicate_; }
/** The join predicate */
AbstractExpressionRef predicate_;
AbstractExpressionRef 是对 AbstractExpression 的一个 shared_ptr 封装,其中的关键成员函数为:
virtual auto EvaluateJoin(const Tuple *left_tuple, const Schema &left_schema, const Tuple *right_tuple,
const Schema &right_schema) const -> Value = 0;
即用来处理 左、右 tuple 和各自的 schemas,其返回一个 Value,关键又要看 FilterExecutor,我们可以看一下其实现:
auto FilterExecutor::Next(Tuple *tuple, RID *rid) -> bool {
auto filter_expr = plan_->GetPredicate(); // 从 plan 中获取谓词
while (true) {
// Get the next tuple
const auto status = child_executor_->Next(tuple, rid);
if (!status) {
return false;
}
// 关键在这!
auto value = filter_expr->Evaluate(tuple, child_executor_->GetOutputSchema());
if (!value.IsNull() && value.GetAs<bool>()) {
return true;
}
}
}
即通过 Evaluate ,输入 tuple 以及子节点的Scheme,就可以得到 value。
所以在 NestedLoopJoin Executor 中,我们也可以按照这种方式,通过 NestedLoopJoinPlanNode 中的 Predicate()->EvaluateJoin() ,得到左、右 tuple 的 value。检测是否匹配的函数如下:
auto NestedLoopJoinExecutor::Matched(Tuple *left_tuple, Tuple *right_tuple) const -> bool {
auto value = plan_->Predicate()->EvaluateJoin(left_tuple, left_executor_->GetOutputSchema(),
right_tuple, right_executor_->GetOutputSchema())
return !value.IsNull() && value.GetAs<bool>();
}
在完成 Nested Loop Join 时,我们需要考虑 Join Type 是什么,好在构造函数中告诉我们,本实验中只需要考虑 left join 和 inner join,而实际上实验中一共有如下几种 Join:
- INVALID:
- 无效的连接类型,通常表示连接类型未指定或不正确。
- LEFT JOIN:
- 左连接:也称为左外连接。左表中的所有行都会被包含在结果集中,而右表中没有匹配的行将会用NULL填充。
- 如果左表的某行在右表中没有匹配项,那么右表的相关列将显示为NULL值。
- RIGHT JOIN:
- 右连接:也称为右外连接。右表中的所有行都会被包含在结果集中,而左表中没有匹配的行将会用NULL填充。
- 如果右表的某行在左表中没有匹配项,那么左表的相关列将显示为NULL值。
- INNER JOIN:
- 内连接:只返回左表和右表中相互匹配的行,即满足连接条件的行。
- 只有当左表和右表的连接条件匹配时,才会将它们的数据组合在一起,否则不会包含在结果集中。
- OUTER JOIN:
- 外连接:也称为全外连接。返回左表和右表中相互匹配的行,以及左表和右表中没有匹配的行。没有匹配的行将用NULL填充。
- 外连接是左连接和右连接的合并。
换言之,如果 Join 方式为 Inner,就需要考虑是否匹配的问题,而如果是 Left Join,则就需要考虑赋空值的情况。
另外需要注意的一点是,并非使用当前的 left tuple 和 right tuple 匹配完,就直接各自取下一个 tuple,因为有可能 left tuple 对应多个 right tuple,如果直接取下一个,就有可能发生遗漏的情况,以下面这个例子说明:
t1 t2
--------- ---------
| x | | x |
--------- ---------
| 1 | | 1 |
| 2 | | 1 |
| 3 | | 2 |
--------- ---------
SELECT * FROM t1 INNER JOIN t2 ON t1.x = t2.x;
可以看出,当 t1 中的 x = 1 与 t2 中第一个 x = 1 匹配后,如果 t1 直接取 x = 2,t2 取 x = 1,就会漏掉 t1.x = 1 与 t2 中第二个 x = 2 也匹配的情况,即在此时还不能直接假设所有的值都是 not duplicate 的。要避免这种情况,就需要在 Next 时,找到下一个与当前 left tuple 不匹配的 right tuple,并保留其所在位置。
Nested Index Join
如果查询包含具有 equal 条件的 Join,而且连接的外表在查询条件上具有索引,则 DBMS 就会使用 NestedIndexJoinPlanNode.
此处的实现近似于 Task#1 中的 Index Scan Executor,我们需要从 Catalog 中拿到 Index Info 和 Table Info,同时使用 Pro2 中构造的 B+树,将 Index Info 中的索引转换成为 BPlusTreeIndexForOneIntegerColumn类型(后者继承自前者)。
根据指导书中的说明,Nested Index Join 的 Schema 中只有一个 child,用于传输 Join 中与外表对应的tuples,而非像 Nested Loop Join 中的有两个子节点,Next 的逻辑与其也是近似的,只是不需要再做 right tuples 的保存了,而是直接使用 Index tree 查找期望的 Index Node 即可。
测试
make -j$(nproc) sqllogictest
./bin/bustub-sqllogictest ../test/sql/p3.05-empty-table.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.06-simple-agg.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.07-group-agg-1.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.08-group-agg-2.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.09-simple-join.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.10-multi-way-join.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.11-repeat-execute.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.12-nested-index-join.slt --verbose
注意,如果你发现你的 group agg结果和期待的值不同,其实也正常,因为只要 GROUP BY的分组结果是一致的,就可以通过测试。

Task #3: Sort + Limit Executors and Top-N Optimization
Sort
除非 ORDER BY 属性与索引的键匹配,否则 BusTub 中将对所有的 ORDER BY 运算符使用 SortPlanNode。
SortPlanNode 并不会改变 Schema,通过从 order_bys 提取需要排序的 keys,通过自定义的比较器进行 sort 即可。
如果查询并不包含排序方向,就默认按照 ASC 执行。
所以实现也没什么可说的,在初始化阶段,通过子节点得到所有需要排序的 tuple,然后对此进行排序即可,类似于此前实现的 Aggregate Executor。
Limit
与 SeqScan 类似,只不过 LimitPlanNode 中多了一个成员变量,用以限制 emit 的 tuple 数量。
/** The limit */
std::size_t limit_;
所以我们要在执行器中,用一个数记录当前已经 emit 多少 tuple,当这个值大于等于 limit_ 的时候,就应该返回 false 了。
Top-N
如果要获取到 Top-N 的数据,先排序再选出 N 个,效率有些低下,不如动态的跟踪查询到当前为止满足条件的 N 个值,这就是 TopNExecutor。
带有 Limit 的 Order by 语句,都应该将查询执行器更改为 TopNExecutor。
而如果实现 Top N个值,单调栈保存最终结果,初始化阶段使用优先级队列,是不错的选择。
但是你会发现,如果只是实现 TopNExecutor 的话,是无法通过 p3.14 的测试的,原因也很简单:
You will need to modify the optimizer to support converting a query with
ORDER BY+LIMITclauses to use theTopNExecutor. SeeOptimizeSortLimitAsTopNfor more information.
关键就在 src/optimizer/sort_limit_as_topn.cpp 的 OptimizeSortLimitAsTopN 里。
auto Optimizer::OptimizeSortLimitAsTopN(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
// TODO(student): implement sort + limit -> top N optimizer rule
return plan;
}
关于优化如何写,可以参考一些 src/include/optimizer/optimizer.h 中已有的实现,总览一遍,发现只有 OptimizeNLJAsIndexJoin 这个把 NestedLoopJoin 优化为 Index Join 的优化方法我们接触过,其代码实现看似复杂,实际上殊途同归,做的事儿都是先把参数中的 plan 中的子节点依序转化成当前的 AbstractPlanNodeRef ,构成一个数组。
auto Optimizer::OptimizeNLJAsIndexJoin(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
std::vector<AbstractPlanNodeRef> children;
for (const auto &child : plan->GetChildren()) {
children.emplace_back(OptimizeNLJAsIndexJoin(child));
}
auto optimized_plan = plan->CloneWithChildren(std::move(children));
// above is same
if (optimized_plan->GetType() == PlanType::NestedLoopJoin) {
// ...
}
return optimized_plan;
}
对于 Limit 和 Sort 而言,就要清楚是哪个结点在上,哪个在下。一开始我是不清楚的,于是两种都试了试,最后发现在实现是,需要先判断是否为Limit,再判断 Sort,之后我想明白,一定得是对排完序后的结果再施加 Limit,因此 Limit 一定在 Sort的上层。
参考代码如下:
auto Optimizer::OptimizeSortLimitAsTopN(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
// TODO(student): implement sort + limit -> top N optimizer rule
std::vector<AbstractPlanNodeRef> children;
for (const auto &child : plan->GetChildren()) {
children.emplace_back(OptimizeSortLimitAsTopN(child));
}
auto optimized_plan = plan->CloneWithChildren(std::move(children));
if (optimized_plan->GetType() == PlanType::Limit) {
const auto &limit_plan = dynamic_cast<const LimitPlanNode &>(*optimized_plan);
const auto &limit = limit_plan.GetLimit();
BUSTUB_ENSURE(limit_plan.children_.size() == 1, "Limit Plan should have exactly 1 child.");
if (limit_plan.GetChildAt(0)->GetType() == PlanType::Sort) {
const auto &sort_plan = dynamic_cast<const SortPlanNode &>(*limit_plan.GetChildAt(0));
const auto &order_bys = sort_plan.GetOrderBy();
BUSTUB_ENSURE(sort_plan.children_.size() == 1, "Sort Plan should have exactly 1 child.");
return std::make_shared<TopNPlanNode>(limit_plan.output_schema_, sort_plan.GetChildAt(0), order_bys, limit);
}
}
return optimized_plan;
}
测试
make -j$(nproc) sqllogictest
./bin/bustub-sqllogictest ../test/sql/p3.13-sort-limit.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.14-topn.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.15-integration-1.slt --verbose
./bin/bustub-sqllogictest ../test/sql/p3.16-integration-2.slt --verbose
make submit-p3