Project 1 共需完成三个任务:可扩展哈希表(Extendible Hash Table)、LRU-K 置换策略(LRU-K Replacement Policy)以及缓冲池管理(Buffer Pool Manager),其中缓冲池的实现会用到前两个,建议就按文档给的顺序实现。
关于代码,首先这里主要就是我个人的一个记录空间,文章也就一两百访问量还是中文,不会真有 CMU 学生来看吧(况且写这篇时也早已过了 DDL)。其二,我比较想展示一些具体实现上比较符合 C++ 的代码风格。另外,我对做这种项目时不知道哪里出 Bug 死活过不去测试特别想要一份参考代码的心情非常理解,所以我决定还是放出关键代码,希望能帮到和博主一样在自学这门课的同学。为了美观,代码会以图片展示为主。(毕竟都来自学了,至少跟着手写一遍,copy paste 就没意义了)
当然,因为我自己写的时候没有参考别人的代码,所以可能有一些地方的理解不对(侥幸过了测试?),欢迎交流指出~
Extendible Hash Table 可扩展哈希表
拉链法实现的哈希表当某个哈希值对应的(即存在于同一个“桶”中,Bucket)元素特别多时,查找的时间复杂度由 O ( 1 ) O(1) O(1) 退化为遍历的 O ( n ) O(n) O(n)。举个极端的例子,如果哈希函数是不管输入是什么都映射为 0,那么就和在第 0 位存储一个链表无异。如何设计散布更加均匀的哈希函数是优化的另一个方向,而另一种方法是当检测到某个桶中的元素过多时对表进行扩展。扩展最简单的做法是直接将哈希表的长度(桶数)翻倍,再将哈希函数的值域由 [ 0 , n ) [0, n) [0,n) 改为 [ 0 , 2 n ) [0, 2n) [0,2n)(这点很容易实现,因为大部分哈希函数本身就是先算出某个值,然后对 n n n 取余数),然后对所有存储的元素重新算一次哈希值分布到不同的桶中。
这种方法的缺点很明显:如果哈希表中已经存储了大量的元素,因为要对所有元素重算哈希值,扩展的过程会有巨大的计算量,导致一次突发的大延迟。实际上,进行扩展时,可能仅仅是某一个桶出现了拉链很长的状况,其它桶的余量还很充足。于是,出现了可扩展哈希表(Extendible Hash Table)的方案,其将哈希得到的下标与桶改为非一对一映射,并引入全局深度(Global Depth)和局部深度(Local Depth)的概念,实现扩展时只需对达到容量的那一个桶进行分裂,解决了以上问题。
网上关于可扩展哈希表的资料已经很多了,自行百度Google,理解原理,然后跟一个模拟插入过程的例子搞懂即可。可以参考 CMU 的课件 & 回放视频(Lecture #07),维基百科 或者这个 B站视频。
代码实现上,Wiki 已经给了 Python 版的例子:

回到我们的代码,项目中已经给出了一个 ExtendibleHashTable 类内联 Bucket 类的结构。Bucket 类用一个 std::list 存储元素键值对,我们主要实现三个函数 Find,Remove 和 Insert:

- 这节开始函数都用了这种
auto+->的后置返回类型声明,这种方式对于需要根据参数来决定返回类型的函数非常有用- 但我个人并不习惯所有函数都这么写,不过没办法不这么写 clang-tidy 检查过不了(摊手)
这里没什么难点,按注释要求处理即可。由于项目上了 C++17 标准,非常建议在遍历键值对时使用 structured binding,避免还要写 pair.first 和 pair.second。



虽然这里可能差距不大,还是建议使用
emplace_back替代push_back,二者区别可以参考我之前这篇博客
ExtendibleHashTable 类存储的成员有:

注意 dir_ 是桶指针的数组,因为可扩展哈希表中会有多个指针指向同一个桶(所以用 shared_ptr)。
主要实现的函数也是 Find,Remove 和 Insert 三个。获取键对应的哈希值下标函数已经写好了:

实现 Find 时,利用该函数找到对应的桶然后让桶查找即可。材料告诉我们 Remove 时不用考虑空桶的合并收缩,因此也是找到桶然后让桶 Remove 即可。
重点在于 Insert。材料告诉我们要先检查插入是否会导致桶溢出,如果是则先进行分裂再插入。首先,如果键已经存在,那么插入肯定不会导致溢出:

注意加锁方式,手动对
mutex加锁解锁有异常退出导致无法解锁风险,用一个std::scoped_lock对象包裹,RAII 特性确保不会泄漏(和智能指针同理)。C++17 可以完全用std::scoped_lock替代 C++11 的std::lock_guard。
否则,判断如果桶会溢出,进行分裂,分 Local Depth < Global Depth 和 Local Depth = Global Depth 两种情况,后者要把指针数翻倍。这里我基本就是对着 Wiki 的 Python 版翻译的,加了注释:

完成后可以先跑一下本地的测试(不过意义不大,本地测试太简单了):
make extendible_hash_table_test -j8
./test/extendible_hash_table_test
(记得把 test/container/hash/extendible_hash_table_test.cpp 两个测试样例的 DISABLED_ 前缀去了)
LRU-K 置换
LRU 置换大家应该都很熟悉了,如果不了解可以刷一下 LeetCode 这道题。其存在的一个问题是,如果突然出现一个很长的一次性顺序访问序列到来,就会把有用的 Cache 全冲掉,也就是缓存污染问题。例如 Cache 容量是 3,存有较常访问的 [A,B,C],此时有一个访问序列 D,E,F 到来,就会把 ABC 全踢掉,即使 DEF 以后可能再也不会出现。
LRU-K 替换策略,一句话总结就是永远优先踢掉没有达到 K 次访问的元素,否则对于已经达到 K 次访问的元素按照 LRU 踢出。原始论文给出了一个 Backward K-distance 的概念如下:

可见对于没有访问至少 K 次的元素,其距离为正无穷,所以会被优先踢出。当存在多个这样的元素时,原论文指出可采用某种二级策略。本实验材料提示此时我们应踢出访问记录最早的元素,也就是采用 FIFO 而非 LRU。
实现上,网上有很多材料给出了方法,即维护一个访问历史队列(记录未达到 K 次访问的元素)和一个缓存队列(记录达到 K 次访问的元素)。当某元素访问达到 K 次时,由历史队列移到缓存队列中。置换时,如果历史队列不为空,就从历史队列踢,否则从缓存队列踢。缓存队列要按 LRU,所以后续再访问某元素时要移到队头;而历史队列采用 FIFO,所以有重复元素访问时不用移动。
注意这里只是概念上为了决定踢出哪个元素而设计了两个队列的结构,实际上每个元素第一次到来时如果 cache 有空位也会放进去。
如果还不理解可以参考这个B站视频,跟着推一下本地测试用例的置换顺序。
实现上,我们需要记录每个元素的访问次数和在队列中的位置(以在 O ( 1 ) O(1) O(1) 时间完成移动删除等操作)。材料还告诉我们一个额外要求:每个元素有一个 evictable 标记,如果为 false,则无论如何不能被踢出。因此,设计一个结构 FrameEntry,记录这些信息。LRUKReplacer 中用到以下成员:

- 存储的元素是
frame_id,实际就是一个int。- 通过以上分析可以看出我们的实现实际上不需要记录每次访问的时间戳,所以类中的
current_timestamp_也不需使用。- 位置的记录是一个
iterator,因为链表不能通过下标索引,而且 C++ 文档 告诉我们std::list的iterator不会因其它元素的插入移动删除操作而失效。这个iterator记录的位置既可能在hist_list_,也可能在cache_list_中(因为它们都是std::list<frame_id_t>,所以iterator类型也是相同的可以通用)。curr_size_表示当前 cache 中元素的数量,存储它是因为我们希望在 O ( 1 ) O(1) O(1) 时间完成 size 的查询,而非把两个队列都扫描一次做计数。curr_size_的维护细节见下面实现。replacer_size_告诉我们frame_id的取值范围(不能超过它),用来判断入参是否合法,而不是表示 cache 的容量。
RecordAccess 函数记录一次访问。

- 如果新来的
frame_id不存在,unordered_map的[]运算符会自动以默认值创建键值对。- 分第一次访问(插入
hist_list_)、不到第 K 次访问(无操作)、第 K 次访问(移至cache_list_)、大于 K 次访问(移至cache_list_队头)四种情况(假设 K >= 2)。
SetEvictable 函数,注意会影响 curr_size_,因为非 evictable 的元素不被记在 size 内。

Evict 函数,优先从 hist_list_ 中踢,如果没有则从 cache_list_ 中踢。因为插入时将元素放在了队头,所以这里要从队尾踢。

Remove 函数,注意注释要求的特殊情况,以及判断元素是在哪个列表中。

寒酸的本地测试x2:
make lru_k_replacer_test -j8
./test/lru_k_replacer_test
Buffer Pool Manager
Buffer Pool 的具体概念可以自行百度,简单来说就是充当数据库上层设施和磁盘文件间的缓冲区,类似于 Cache 在 CPU 和内存间的作用。bustub 中有 Page 和 Frame 的概念,Page 是承载 4K 大小数据的类,可以通过 DiskManager 从磁盘文件中读写,带有 page_id 编号,is_dirty 标识等信息。Frame 不是一个具体的类,而可以理解为 Buffer Pool Manager(以下简称 BPM)中容纳 Page 的槽位,具体来说,BPM 中有一个 Page 数组,frame_id 就是某个 Page 在该数组中的下标。参考下图:
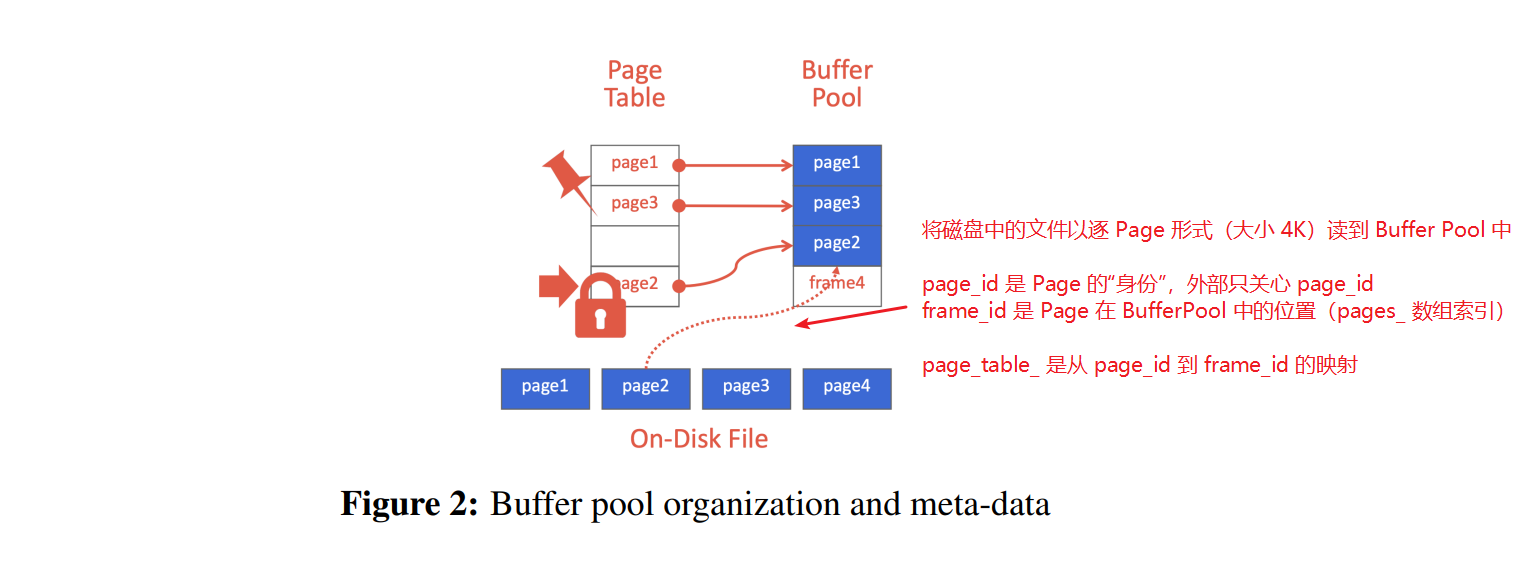
外界只知道 page_id,向 BPM 查询时,BPM 要确定该 Page 是否存在以及其位置,所以要维护一个 page_id 到 frame_id 的映射,其实现就使用我们刚完成的 ExtendibleHashTable。为区分空闲和占用的 Page,维护一个 free_list_,保存空闲的 frame_id。初始状态,所有 Page 都是空闲的。当上层需要取一个 Page 时,如果 Page 已存在于 BP 中,则直接返回;否则需要从磁盘读取到 BP 中。此时优先取空闲的 Page,否则只能从所有已经占用的 Page 中用我们刚完成的 LRUKReplacer 决定踢出某个 Page。

这里要实现的几个函数都没什么难点,主要是重复性的代码,就不贴了,按照注释说明把所有工作做到位即可。其中NewPgImp() 和 FetchPgImp() 都会用到以上说的取 Page 的流程,可以写一个函数:

寒酸的本地测试x3:
make buffer_pool_manager_instance_test
./test/buffer_pool_manager_instance_test
生成提交文件压缩包:
make submit-p1
提交至 AutoGrader,通关~
因为没有做更细粒度的读写锁的优化,Leaderboard 就比较菜了,20多名哈哈