Part3-Database Storage i
层次结构
存储Disk Manager => 缓冲池管理 Buffer Pool Manager => Access Methods => Operator Execution => Query Planning
Storage => Execution => Concurrency Control => Recovery => Distributed Databases => Potpourri
需要了解哪些API下层提供给上层

Disk-Oriented Architecture
面向磁盘型的数据库系统:假设数据库的主要存在位置都是放在磁盘上的
所要访问的数据都不在内存,需要到磁盘去读
区分non-volatile 非易失性 和 volatile 易失性存储,DBMS要管理数据between non-volatile and volatile
存储层次
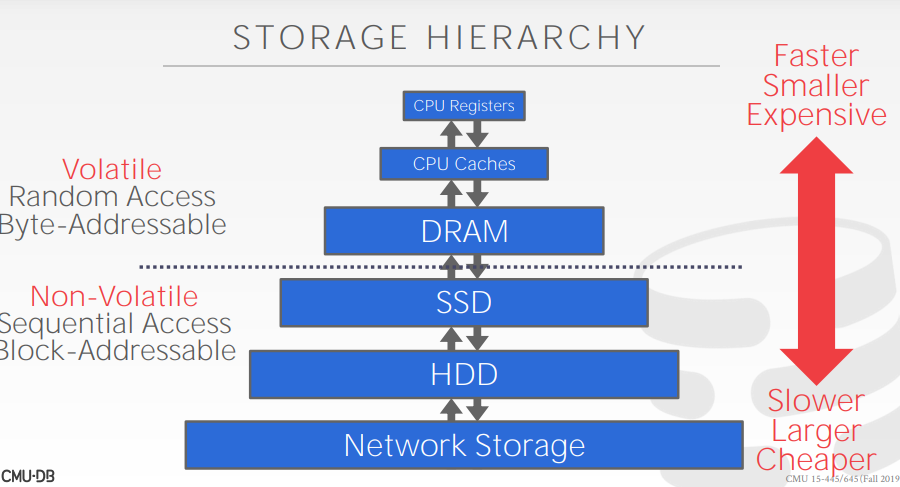
- 如果数据存在易失存储,支持快速访问,随机访问,访问速度大体相同(不管位置和顺序)
- 非易失的存储,具有块寻址能力,没有字节寻址能力。得到block或者page,更快的顺序访问。
DRAM=>Memory, SSD HDD Network Storage => Disk
The goal of what we’re trying to do in our database system is that we wan to provide the illusion to the application,that we have enough memory to store their entire database in memory.
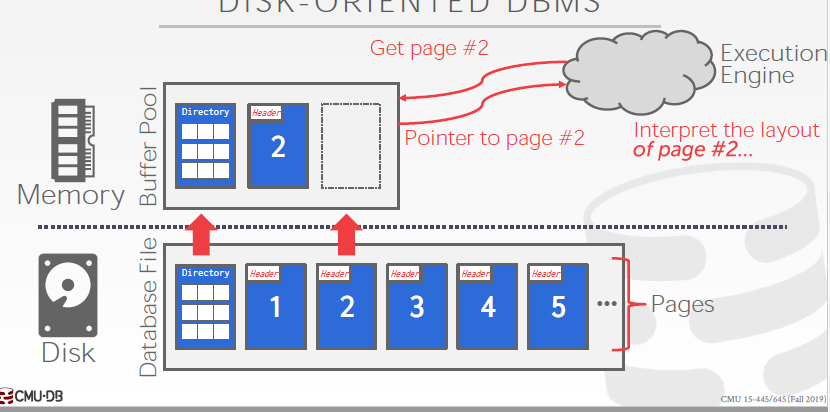
请求page过程
sync:
sync也是一个linux同步命令,含义为迫使缓冲块数据立即写盘并更新超级块。在linux系统中,为了加快数据的读取速度,默认情况下,某些数据将不会直接写入硬盘,而是先暂存内存中,如果一个数据被重复写,这样速度一定快,但存在一个问题,万一重新启动,或者是关机,或者是不正常断电的情况下,由于数据还没来得及存入硬盘,会造成数据更新不正常,这时需要命令sync进行数据的写入,即#sync,在内存中尚未更新的的数据会写入硬盘中。所以在关机或者开机之前最好多执行这个几次,以确保数据写入硬盘。
**用途:**更新 i-node 表,并将缓冲文件写到硬盘中。
OS
os 负责 移动数据
只读数据
可以通过多个线程来获取mmap files to hide page fault stalls,但是仅限于只读数据
Multiple Writers
如何处理多线程写呢? 事务、并发控制
- madvise:告诉OS具体访问哪些页面
- mlock:阻止pages 被回收
- msync:flush to disk
mmap is a bad idea.
q1:如何用磁盘上的文件表示数据库?
File Storage
DBMS存储一个数据库到磁盘上以一个或者多个文件的形式,OS不知道文件内容。放在文件系统里面,ex3ex4。基于OS的FS提供的基本读写API对文件进行读写。
Storage Mangager
负责维护磁盘上的数据库文件.
linux 对单一进程有文件打开数量的夏至,ext3文件系统下单个目录里最大文件数没有限制,仅仅受限于inode数

对磁盘write/flush 通常存储设备只能保证每次写入4KB时是原子的
Page Storage Architecture
page存储架构
Database Heap
heap 无序组织tuple数据,随即顺序。
Represent Heap File
Linked List
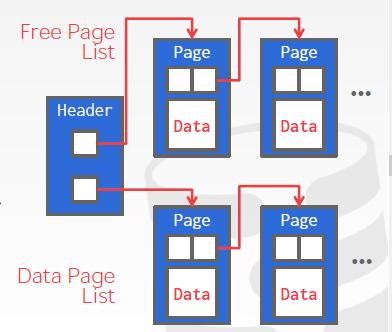
is a bad idea
Page Directory
普遍做法
维护一个特殊的页面,里面记录着数据页的位置;pageid和他们所处位置的映射关系,也可也记录空闲页。
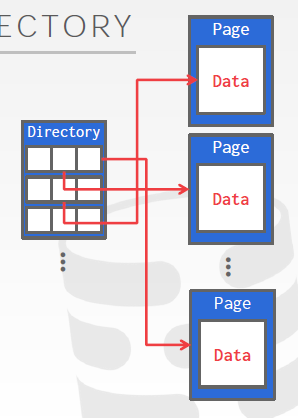
维护日志以及初始元数据。
Page Layout
Page Header
每一页都有一个header,放元数据以及
- pagesize
- checksum
- dbms version
- transcation visibility
- compression information
有一些系统需要页self-contained
Tuple-oriented
在一个页面里面如何组织数据
strawman idea:Keep track of the number of tuples in a page and then just append a new tuple to the end.
使用slotted pages,slot array将特定的slot映射到page上的某个偏移量上面,根据偏移量可以得到tuple
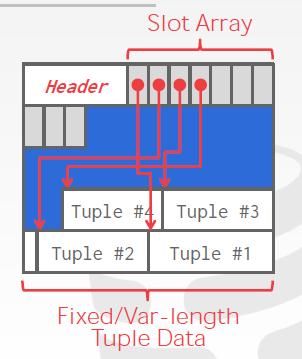
填充方式:数据从后向前填充,slot从前向后

slot存储的是偏移量。上层只需要提供pageid就能够get page
识别tuple:page_id + offset/slot
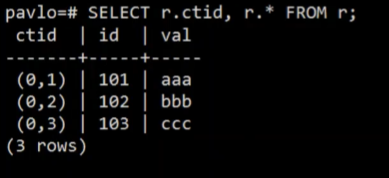
ctid 是 PG里面的 用来表示物理位置的一个pair (page_id,slot)
如果删除一个tuple slot2的,然后插入一个新的tuple,数据库不会立刻整理碎片,而是继续往后插入。
vaccum:PG里面的垃圾回收站,遍历page然后整理。
sql sever 没有ctid,但是有内置函数。
select sys.fn_PhysLocFormatter(%%physloc%%) as [File:Page:Slot],r.8 from r;
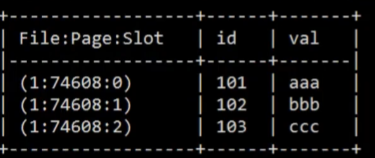
sql sever 当更新page的时候,sql sever如果发现有可用空间,那么将page变得紧凑,然后再将数据写出到page里面,如果是先删除后插入,那么slot不是0 2 3 而是 0 1 2
Oracle 内部维护ROWID
前面这些反应位置的地方,叫做内部虚拟列。数据库系统会把它当时保留字,不能用这个当作列名
Log-structured
Tulpe Layout
tuple 结构:header + attribute Data
header追踪不同的东西例如哪一个事务查询修改了这个tuple
例如一个tuple五个属性
tuple : heaer + a + b + c + d + e
来自不同表的数据保存在同一个Page里面?
Answer:为了保证Page的独立性,不要在一个page保存不同表的额外的元数据
反范式化
俩表有外键依赖,数据库内部会自动内嵌。
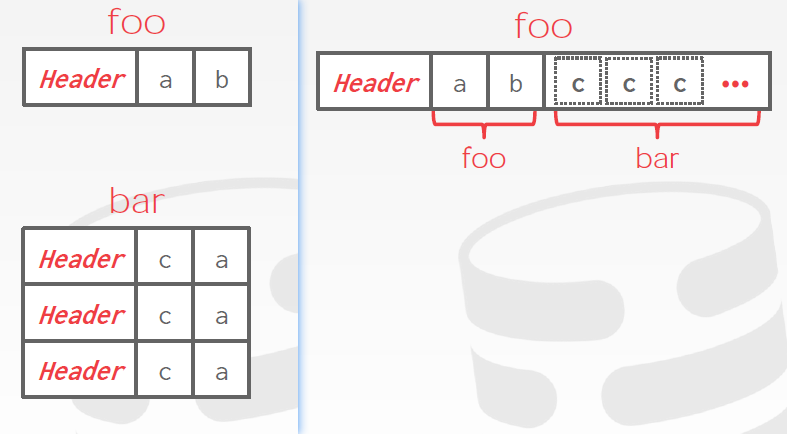
能够减少IO次数,pre join有点。但是可以make updates more expensive
Conclusion
- database is organized in pages
- different ways to track pages
- different ways to store pages
- different ways to store tuples