Part2-Advanced SQL
SQL => Structure Query Language
范围
包括DML(Data Manipulation Language) DDL(Data Definition Language) DCL(Data Control Language) ,还有视图定义、integrity完整性、referential Constraints参照约束,Transcations
SQL is based on bags,bags没有固定位置和顺序允许重复,而不是basedon sets(no duplicates).
如果想要元素有序,或者保证没有重复元素,本质上数据库需要多做一些额外的工作
Aggregations + Group By
聚合函数
AVG,MIN,MAX,SUM,COUNT
equal as below:

Distinct
去重

where首先过滤tuple,过滤完然后再聚合,顺序注意。所以我们无法再where里面使用聚合函数的结果去过滤tuple
解决:使用having子句
改成
select AVG(s.gpa) AS avg_gpa, e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid
HAVING avg_gpa > 3.9;
处理字符串
MYSQL 不区分大小写,其余的区分大小写
然后Mysql,sqlite 支持单引号以及双引号,但是其他的,pg db2 oracle 必须单引号
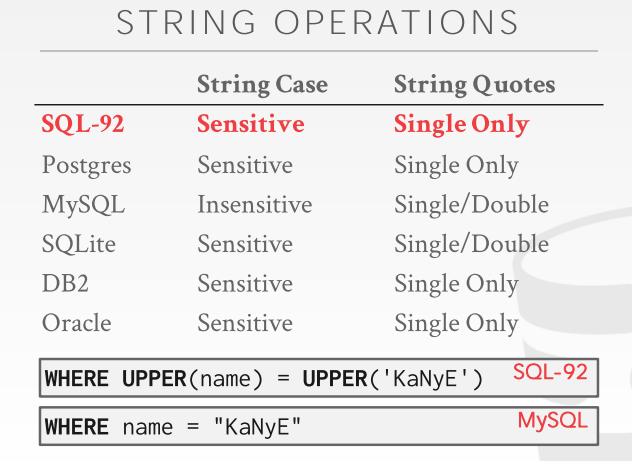
LIKE
like 匹配 通配符,%指一个或者多个字符,_指的是一个字符。
SELECT * FROM enrolled AS e WHERE e.cid LIKE '15-%';
SELECT * FROM student AS s WHERE s.login LIKE '%@c_';
String Functions
SUBSTRING,upper,lower…
字符串函数、数学函数、日期函数可以出现在查询语言的任意地方不需要必须having子句。
sql标准下,可以使用‘||’ 连接字符串,或者使用+,CONCAT(Mysql)
Date/Time Operations
Demo:获得从今年开始到现在的天数
PG:
SELECT DATE('2018-08-29') - DATE('2018-01-01) AS days;
MySql:用unix时间
SELECT ROUND((UNIX_TIMESTAMP(DATE('2018-08-29')) - UNIX_TIMESTAMP(DATE('2018-01-01'))) / (60*60*24),0) AS days;
Sqlite:从公元前4000+开始计时
SELECT CAST((julianday(CURRENT_TIMESTAMP) - julianday('2018-01-01')) AS INT) AS days;
Output Control + Redirection
INTO/Redirection
将查询结果写入到一个表里面。
select distinct cid INTO couresids from enrolled;
create table courseIds(
select distinct cid from enrolled);
insert into courseids(select ...); # 写入已经存在的表
Control
order by子句
ORDER BY <COLUMN*> [ASC|DESC] 默认升序
order by grade desc,sid asc.
LIMITs <count> [offset]
limit 10
限制返回结果的记录,只返回10个
limit 20 offset 10 # 一般结合order by 使用
Nested Queries
嵌套查询
得到注册了一门课程的学生名字
select name from students where sid in (select sid from enrolled);
outer query & inner query 大部分查询优化器会对这种in操作优化为join操作,in操作需要两个for循环,对student每个tuple遍历一遍。 每次比较的时候inner query 都要重新执行一遍 很蠢
其他操作符
ALL、ANY、IN、EXISTS、NOT EXISTS
# 找出id最大的学生 并且在enroll表中至少选了一门课程
select sid,name from stduent
where sid >= ALL(
selet sid from enrolled
)
Common Table Expressions
cte 公共表表达式
with cteName AS (
select 1
)
select * from cteName
# as 后面 结果 映射到前面的表名
# 如果ctename已经存在 那么下方的select就可以直接引用
将一个查询结果当作另外一个查询输入
demo: find 最大的学生id 再enrolled表
with cteSource(maxId) AS (
select MAX(sid) from enrolled
)
select name from student,cteSource
where student.sid = ctesource.maxId
cte & nests query 区别
CTE 可以进行递归,嵌套查询不可以

RECURSIVE 关键字 否则db是默认不允许递归查询的
将上一个结果作为参数传递到下一个查询里面,注意设置递归终点!
Window Fuctions
像聚合函数,会对一堆tuple进行某些函数的计算,对tuple子集计算,可以以增量方式或者移动方式进行操作。但是仍然以tuple输出结果,即输出每一行的数据并且在后面追加一个聚合字段所表示的数据。
SELECT ... FUNC-NAME(...) OVER (...)
FROM tablename
# 函数名可以是聚合函数或者其他window函数
# over 子句 用来表示如何切分数据 像group by
例子:
select cid,sid
ROW_NUMBER() OVER (PARTITION BY cid)
FROM enrolled
ORDER BY cid;
# 选出cid sid 行号,按照cid分区 排序
结果
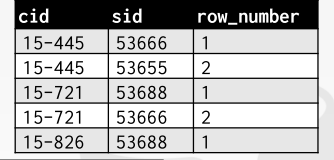
可以看到row number是组内编号
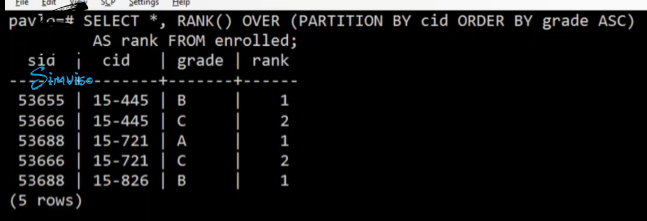
按照cid分区按照成绩 排序,然后根据RANK区内按照升序给予rank属性
rank()按照出现的先后给排名,注意这里 行号函数是按照输出的给与行号,rank函数是按照分组排序后的组内顺序给与值的
如果没有排序,那么所有记录的rank值都是1
Q: RANK() 相比 group by的rank 的优势
A: 用聚合只能看到聚合结果,用window functions 可以看到整个tuple
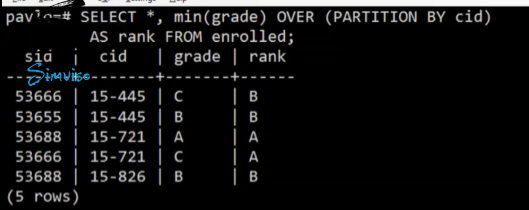
没有 lose tuples
如果没有排序,那么所有记录的rank值都是1
SQL is not a dead language
You should(almost) always strive to compute your answer as a single SQL statement without storing data in local or move back and forth