Part04-DatabaseStorage ii
Log-Structured File Oragnization
不是把所有的tuple都存放在page里面,而是去存储如何创建tuple以及修改tuple 的相关信息。类似于LOG记录,存insert delete update等等。
不但在机械硬盘上同时SSD上:循序写入,循序读取,循序访问的速度要远比随机访问的速度快
“日志结构文件系统或者叫日志结构合并树”
缺陷:读取。如果需要查找某个tuple需要日志重新走一遍,或者建立索引
tuple 就是一个字节序列 字节数组
Data Representation
C/C++:使用int、bigint、smallint、tinyint等表示
浮点数:使用float、real这是IEEE-754规定的标准,或者用numeric/decimal这是fixed-point decimals,float或者real都是CPU或者C++给我们的不精确数字 是“可变精度”,对可变精度数字的执行操作速度要比任意精度数字快得多。
Q:如果是不能够有误差的浮点数要求怎么办呢?
A:使用固定精度数字(fixed point decimals) 。使用varchar来表示,然后使用一些metadata来表示小数点的位置,精度范围,四舍五入信息等。
varchar/varbinary/text/blob 一般都会有一个header存储length后面跟着字节,如果很大后面会跟上checksum。
time/date/timestamp 大多数系统保存从1970年1月1日起的秒数或者毫秒数或者微秒数。
explain sql 然后这个explain语句会告诉你这个查询的查询计划query plan,并不会实际去做,只会告诉你他要怎么做。
如果是 explain analyze sql 则不仅会查询计划也会实际去执行查询。
fixed point decimals的查询速度要远远高于real
Large Values
单个Page放不开,大部分DBMS不允许一个元素超过一个页的大小
解决办法:overflow storage pages,类似于链表索引,可以多链接好几个page
Postgres:TOAST > 2KB
MySQL:Overflow > 1 2 s i z e o f p a g e \frac{1}{2} \, size \, of \, page 21sizeofpage
SQL Sever:overflow > size of page
如果tuple没法放在一个page里面就会把这个tuple拿出来,放在另一个page里面
这么做的原因:当overflow pages 包含了常规数据,你要得到常规下所有你应该具备的保护措施。例如,恢复,slot优化。
External Value Storage
实际不会存这个文件,而是保存指针或者文件路径,他们指向能找到该数据的本地磁盘或者网络存储或者外部存储设备。例如一个tuple的一个属性就这么存,然后再去find。
只能读,不能修改。
注意overflow page算存在数据库内部的,但是外部存储的,like blob,文件是不存在数据库内部的,而是放在外设,相当于只存index,然后DB无法对其文件进行安全保护等~
如果数据库中保存了文件,可以保持文件open,然后使用f.open就打开文件获取数据了,这样就不用根据指针在文件系统中查找文件。
System Catalogs
DBMS存储关于数据库的meta-data在它的internal catalogs,包括:
- tables,columns,indexed,views
- uers,permissions
- internal statistics(内部数据统计,在查询优化会用到)
很多DBMS会存他的catalog 在一张表里面,会通过**STANDARD INFORMATION_SCHEMA ** API暴露catalog出来。
# 每个数据库都应该支持的规范语法 列出所有表
select * from INFORMATION_SCHEMA.TABLES where table_catalog = '<db name>';
# 部分不规范语法
\d; # PG
SHOW TABLES; # MySQL
.tables; # SQLite
获得一个表的schema
select * from INFORMATION_SCHEMA.TABLES where table_name = 'student';
\d student; # \d+ table 会get更详细的信息
DESCRIBE student;
.schema student;
Storage Models
OLTP 联机事务处理
从外面世界拿到新数据之后,把他们放入我们的数据库系统,例如从网上买东西
只会读取一小部分数据或者更新一小部分数据,小部分tuple但是会做很多次
OLAP 联机分析处理
当已经从OLTP应用程序收集了很多数据时,想进行分析,然后推断出新的信息。
这种情况下,不会更新数据,只是分析数据提供新的信息。进行只读查询。会读取大量的数据,然后大量的join等~
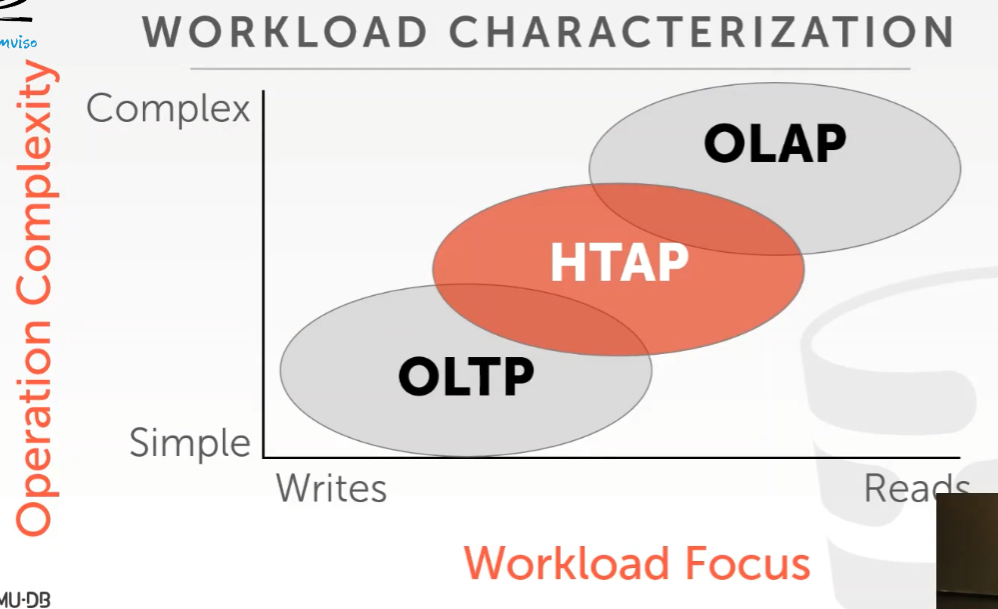
OLAP 查新比较复杂,OLTP进行多次重复简单写。
HTAP 混合事务分析处理
Hyper Transaction Analytical Processing
上面是workload类型,那么什么样的存储模型才能更有效的支持这些workload呢?
NewSQL:在不放弃事务下,拥有快速处理事务的能力和OLTP,或者像NoSQL那样放弃Join
N-ary Storage Model(NSM)
row storage model
基本思路:将单个tuple中的属性取出,并将他们连续地存储在page里面。
适用workload:OLTP,因为访问的数据量在粒度上足够小,一次取出一个tuple,这一个tuple就可以看作一整块连续的存储粒度。
行存储,让一个tuple的数据联系放在一起是读取数据最有效的方式
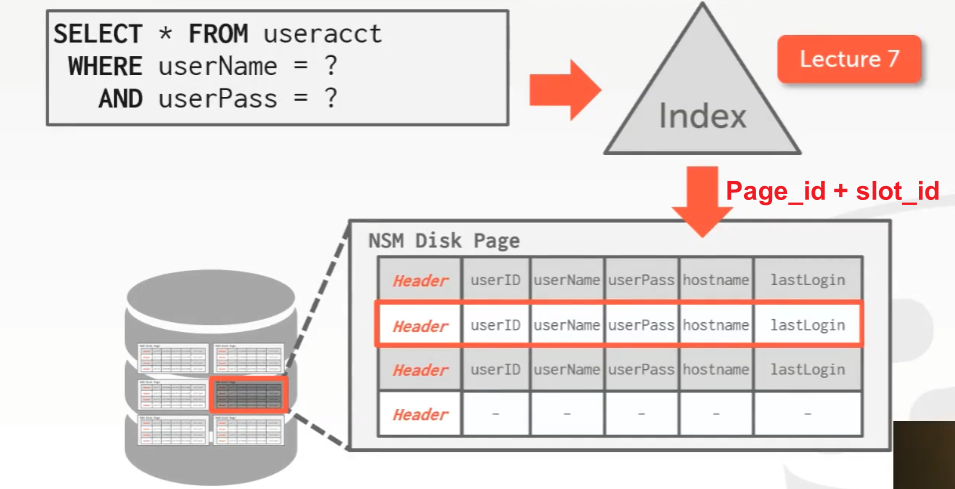
问题/缺点:一次取一个Page,然后如果只需要其中一小部分几个tuple,其余取出的tuples都浪费了,没进行读。这样如果数据量很大,那么开销很大然后速度也会很慢。
优点:访问整个tuple的时候,插入、更新、删除数据速度很快。
Decomposition Storage Model(DSM)
列存储model思路:不会把单个tuple的全部属性放在单个page上面。而是把所有tuple中单个属性的所有值保存在单个page上面。
记录温度,一个作为标准,然后其余记录和该标准的差值?
哦,这个意思是如果存储的属性值比较相近或者重复(例如文本),可以进行压缩的。
首先一点,相同的属性放在一个page,他们是自然对齐(我自己编的词),或者说所占的字节空间一样的。可以使用压缩算法进行压缩。
Tuple Identification
如果有where从句限制,然后筛出了符合的tuple,怎么再去另外page找到对应的tuple的对应的属性值呢?
Fixed-length Offsets
利用固定长度的偏移值。
Embedded Tuple Ids
对于列中的每个值,为每个值都保存一个主键或者标识符。(bad idea)
Advantages
- 进行OLAP查询的时候,可以减少无用IO的次数。
- 更好的查询处理以及数据聚合
Disadvantages
读取一个tuple的时候很慢。
Conclusion
数据库存储的底层表示并不是那种可以放入存储管理器的东西,不暴露给系统段任何其他部分。
OLTP = Row Store
OLAP = Column Store
Mysql 可以在创建表的时候指定使用列存储还是行存储,是两种独立的存储管理器,用两种独立的执行引擎来处理。called Hybrid databases system
人们在前端OLTP系统运行的是Mysql、MongoDB或者其他DBMS,然后把数据传输给后端数据仓库,然后基本就可以把OLTP这块老的数据修剪掉了(不再需要的时候)。