• 数据库概述(★★★)
| 集中式数据库系统 | •数据管理是集中的 者口集中在DBMS所在的计算机。 |
| B/S结构 | •客户端负责数据表示服务 •服务器主要负责数据库服务 |
| 并行数据库 | •共享内存式 •无共享式 |
| 分布式数据库 | • 物理上分布、逻辑上集中 • 物理上分布、逻辑上分布 •特点 - 透明性 |
• 数据库的结构与模式(★★★★)
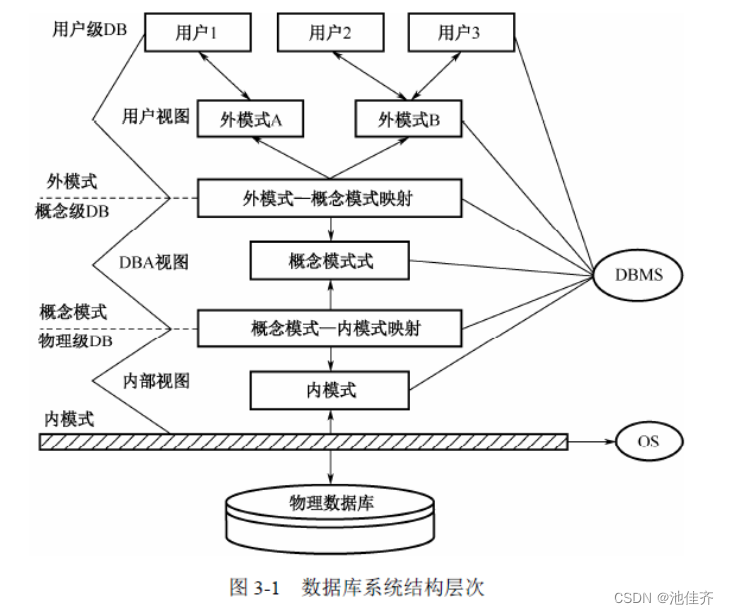
数据库系统的三级模式
| 外模式 |
外模式(子模式、用户模式) 语句或应用程序去操作数据库中的数据。 数据的安全性和完整性约束条件 |
| 概念模式 |
概念模式(模式、逻辑模式) 整个数据库中数据库的逻辑结构,描述现实世界中的实体及其性质与联系, 定义记录、数据项、 数据的完整性约束条件及记录之间的联系,是数据项值的框架。 |
| 内模式 |
内模式是整个数据库的最低层表示,不同于物理层,它假设外存是一个 内模式是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。 一个数据库只有一个内模式。 |
内模式、模式和外模式之间的关系如下:
(1)模式是数据库的中心与关键;
(2)内模式依赖于模式,独立于外模式和存储设备;
(3)外模式面向具体的应用,独立于内模式和存储设备;
(4)应用程序依赖于外模式,独立于模式和内模式。
• 数据库设计阶段(★★)

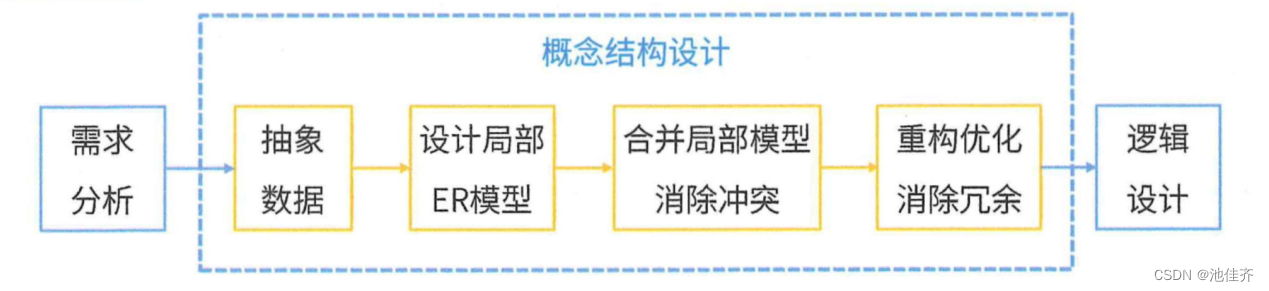
集成的方法:
- 多个局部E-R图一次集成。
- 逐步集成,用累加的方式一次集成两个局部E-R。
集成产生的冲突及解决办法:
- 属性冲突:包括属性域冲突和属性取值冲突。
- 命名冲突:包括同名异义和异名同义。
- 结构冲突:包括同一对象在不同应用中具有不同的抽象,以及同一实体在不同局部E-R图中所包含的属性个数和属性排列次序不完全相同。
• ER模型 (★)
概念数据模型是按照用户的观点来对数据和信息建模,主要用于数据库设计。概念模型
主要用实体—联系方法(Entity-Relationship Approach)表示,所以也称 E-R 模型。
常用的基本数据模型有层次模型、网状模型、关系模型和面向对象模型。
• 关系代数(★★★★)
| 并 |
计算两个关系在集合理论上的并集,即给出关系 R 和 S(两者有相同元/列 |
|
| 交 |
R 和 S(两者有相同元/列数), |
|
| 差 | 计算两个关系的区别的集合,即给出关系 R 和 S( 两者有相同元/列数), R-S |
|
| 笛卡尔积 |
S 为有 n 元的关系,则 R× S 是 m+n 元的元组的集合, 其前 m 个元素来自 R 的一个元组,而后 n 个 |
|
| 选择 | 从一个关系中抽取指明的属性(列)。令 R 为一个包含属性 A 的关系 | |
| 投影 | ||
| 连接 | θ连接从两个关系的笛卡儿积中选取属性之间满足一定条件的元组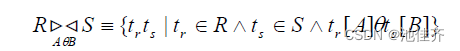 |
|
| 除法 | 设有关系 R(X, Y)与关系 S(Z), Y 和 Z 具有相同的属性个数,且对应属性出 自相同域。关系 R(X, Y)÷S(Z)所得的商关系是关系 R 在属性 X 上投影的一个子集,该子 集和 S(Z)的笛卡尔积必须包含在 R(X, Y)中,记为 R÷S |
• 规范化理论(★★★★★)
第一范式
1NF 是最低的规范化要求。如果关系 R 中所有属性的值域都是简单域,其元素(即属
性)不可再分,是属性项而不是属性组,那么关系模型 R 是第一范式的,记作 RÎ1NF。


第二范式
如果一个关系 R 属于 1NF,且所有的非主属性都完全依赖于主属性,则称之为第二范
式,记作 RÎ2NF
有一个获得专业技术证书的人员情况登记表结构为:
省份、姓名、证书名称、证书编号、核准项目、发证部门、发证日期、有效期。
这个结构符合 1NF,其中“证书名称”和“证书编号”是主码,但是因为“发证部门”
只完全依赖于“证书名称”,即只依赖于主关键字的一部分(即部分依赖),所以它不符合 2NF,
分解成两个表就完全符合 2NF 了
(省份、姓名、证书名称、证书编号、核准项目、发证日期、有效期)
(证书名称、发证部门)
第三范式
如果一个关系 R 属于 2NF,且每个非主属性不传递依赖于主属性,这种关系是 3NF,
记作 RÎ3NF。
有一个表(职工姓名,工资级别,工资额),
其中职工姓名是关键字,此关系符合 2NF,但是因为工资级别决定工资额,也就是说非主
属性“工资额”传递依赖于主属性“职工姓名”,它不符合 3NF,同样可以使用投影分解的
办法分解成两个表:(职工姓名,工资级别),(工资级别,工资额)。
BC 范式
如果关系模型 R∈ 1NF,且 R 中每一个函数依赖关系中的决定因素都
包含码,则 R 是满足 BC 范式的关系,记作 RÎBCNF。
综合 1NF、 2NF 和 3NF、 BCNF 的内涵可概括如下:
(1)非主属性完全函数依赖于码(2NF 的要求);
(2)非主属性不传递依赖于任何一个候选码(3NF 的要求);
(3)主属性对不含它的码完全函数依赖(BCNF 的要求);
(4)没有属性完全函数依赖于一组非主属性(BCNF 的要求)。
• 并发控制(★)
数据库的并发操作带来的问题有:丢失更新问题、不一致分析问题(读过时的数据)、依赖
于未提交更新的问题(读了“脏”数据)。这三个问题需要 DBMS 的并发控制子系统来解决。
处理并发控制的主要方法是采用封锁技术。它有两种类型:排他型封锁(X 封锁)和共
享型封锁(S 封锁)
(1)排他型封锁(简称 X 封锁)。如果事务 T 对数据 A(可以是数据项、记录、数
据集,乃至整个数据库)实现了 X 封锁,那么只允许事务 T 读取和修改数据 A,其他事
务要等事务 T 解除 X 封锁以后,才能对数据 A 实现任何类型的封锁。可见 X 封锁只允
许一个事务独锁某个数据,具有排他性。
(2)共享型封锁(简称 S 封锁)。 X 封锁只允许一个事务独锁和使用数据,要求太严。
需要适当放宽,例如可以允许并发读,但不允许修改,这就产生了 S 封锁概念。 S 封锁的
含义是:如果事务 T 对数据 A 实现了 S 封锁,那么允许事务 T 读取数据 A,但不能修
改数据 A,在所有 S 封锁解除之前绝不允许任何事务对数据 A 实现 X 封锁。
• 分布式数据库(★★)
分布式数据库=是由一组数据组成的,这组数据分布在计算机网络的不同计算机上,网络中的每个结点具有独立处理的能力,成为场地自治,它可以执行局部应用,同时,每个结点也能通过网络通信子系统执行全局应用。
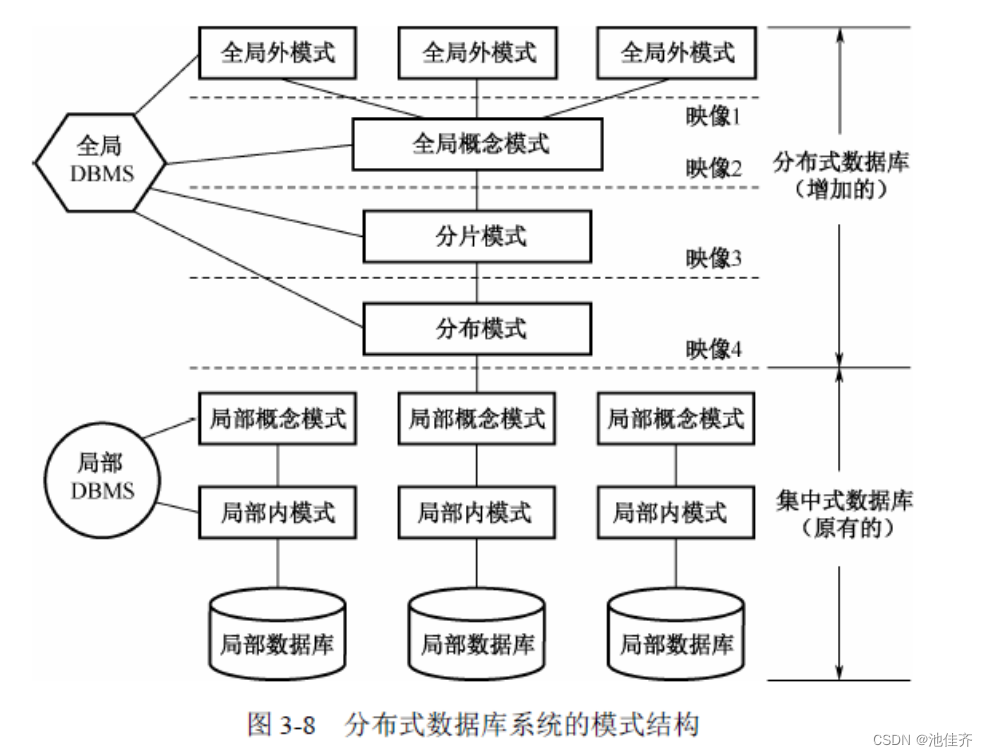
图 3-8 的模式结构从整体上可以分为两大部分:下半部分是集中式数据库的模式结构,
代表了各局部场地上局部数据库系统的基本结构;上半部分是分布式数据库系统增加的模式
级别。
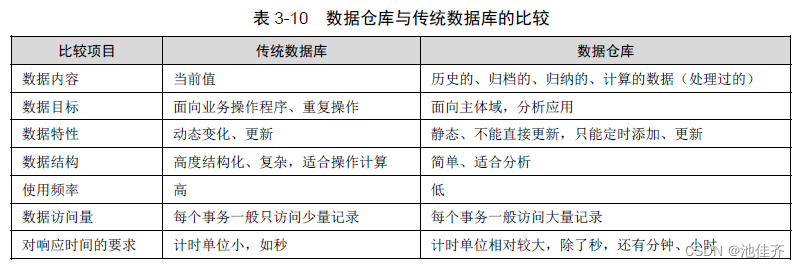
• 数据仓库(★★★)
著名的数据仓库专家 W.H.Inmon 在《Building the Data Warehouse》一书中将数据仓库
定义为:数据仓库( Data Warehouse)是一个面向主题的、集成的、相对稳定的、且随时间
变化的数据集合,用于支持管理决策。
• 数据挖掘(★★★★)
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际
应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
数据挖掘的功能
- 1.自动预测趋势和行为数据挖掘自动在大型数据库中寻找预测性信息,以往需要进行大量手工分析的问题如今可以迅速直接由数据本身得出结论。
- 2.关联分析数据关联是数据库中存在的一类重要的可被发现的知识。
- 3.聚类数据库中的记录可被划分为一系列有意义的子集,即聚类。
- 4.概念描述概念描述就是对某类对象的内涵进行描述,并概括这类对象的有关特征。
- 5.偏差检测数据库中的数据常有一些异常记录,从数据库中检测这些偏差很有意义。
常用的数据挖掘技术包括关联分析、序列分析、分类、预测、聚类分析及时间序列分析
等
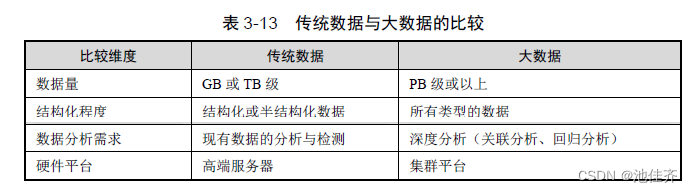
• 大数据(★★★)
业界通常用 4 个 V(即 Volume、 Variety、 Value、 Velocity)来概括大数据的特征
Volume:指的是数据体量巨大,从 TB 级别跃升到 PB 级别(1PB=1024TB)、 EB 级别
(1EB=1024PB),甚至于达到 ZB 级别(1ZB=1024EB)。截至目前,人类生产的所有印刷材
料的数据量是 200PB,而历史上全人类说过的所有话的数据量大约是 5EB。当前,典型个
人计算机硬盘的容量为 TB 量级,而一些大企业的数据量已经接近 EB 量级。
Variety:指的是数据类型繁多。这种类型的多样性也让数据被分为结构化数据和非结构
化数据。相对于以往便于存储的以文本为主的结构化数据,非结构化数据越来越多,包括网
络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了
更高要求。
Value:指的是价值密度低。价值密度的高低与数据总量的大小成反比。以视频为例,
一部 1 小时的视频,在连续不间断的监控中,有用数据可能仅有 1-2 秒。如何通过强大的
机器算法更迅速地完成数据的价值“提纯”成为目前大数据背景下亟待解决的难题。当然把
数据集成在一起,并完成“提纯”是能达到 1+1 大于 2 的效果的,这也正是大数据技术的
核心价值之一。
Velocity:指的是处理速度快。这是大数据区分于传统数据挖掘的最显著特征。根据 IDC
的“数字宇宙”的报告, 预计到 2020 年,全球数据使用量将达到 35.2ZB。在如此海量的
数据面前,处理数据的效率就是企业的生命。
大数据处理关键技术一般包括:大数据采集、大数据预处理、大数据存储及管理、大数
据分析及挖掘、大数据展现和应用(大数据检索、大数据可视化、大数据应用、大数据安全
等)