数据库系统
-
数据库管理系统(DBMS)
a. 类型:关系型DBMS,文档型DBMS,键值型DBMS,对象型DBMS -
数据库的结构&模式
a. 用户级 =》外模式 :数据库用户能够看得见和使用的局部数据的逻辑结构和特征描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。(用户使用)
b. 概念级 =》概念模式:描述整个数据库中逻辑结构,描述现实世界中实体及其性质和联系。概念模式是数据库中全体数据的逻辑结构和特性描述,所有用户的公共数据视图。一个数据库只有一个概念模式。(DBA使用)
c. 物理级 =》 内模式:数据库的最底层表示。是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。
d. 三种模式之间的关系
i. 模式是数据库的中心与关键
ii. 内模式依赖于模式,独立于外模式和存储设备
iii. 外模式面向具体的应用,独立于内模式和存储设备。
iv. 应用程序依赖于外模式,独立于模式和内模式。
e. 数据库的两级独立性
i. 物理独立性
1. 用户的应用程序与存储在磁盘上的数据库中数据相互独立,数据的物理存储改变时候,应用程序不需要改变。(概念模式~内模式转换)
ii. 逻辑独立性
1. 用户的应用程序与数据库中逻辑结构相互独立,数据逻辑结构改变,应用程序不需要改变。(外模式~概念模式转换) -
数据模型
a. 概念数据模型(实体-联系模型)
i. 概念:按照用户的观点来对数据和信息建模,用于数据库设计,E-R模型
b. 基本数据模型 (结构数据模型)
i. 概念:按照计算机系统的观点来对数据和信息建模,主要用于DBMS的实现。
ii. 组成
1. 数据结构:系统静态特性的描述
2. 数据操作:系统的动态特性的描述
3. 完整性约束:一组完整性规则集合
iii. 常用的基本数据模型
1. 层次模型:用树形结构表示实体类型及实体间的联系。记录数据之间的联系使用指针来实现,查询效率高,但是只能表示1:n
2. 网状模型:有向图表示实体类型及实体间的联系。
3. 关系模型:用表格结构表达实体集,用外键表示实体间的联系。建立在严格的数学概念基础之上;概念关系单一,结构简单,清晰,用户易懂易用
4. 面向对象模型 -
关系代数
a. 并、交、差、笛卡儿积、选择、投影、连接、除法运算。 -
数据的规范化
a. 范式 :关系模型满足的确定约束条件称为范式,逐步消除不合适的函数依赖
b. 1NF:键不可再分割 ;2NF:1NF基础之上消除传递依赖,一张表描述一个对象;3NF :2NF基础上消除引用依赖,所有非主键和主键有关联;BC NF :主属性对不含它的码完全函数依赖 -
反规范化:提高某些查询或者应用的性能而破坏规范规则。
a. 增加冗余列
b. 增加派生列
c. 重新组表
d. 分割表 -
数据库设计:将数据库系统与现实世界密切的,有机的,协调一致的结合起来。
a. 数据库设计方法:
i. 直观设计法
ii. 规范设计法
iii. 计算机辅助设计法
iv. 自动化设计法
b. 设计阶段
i. 设计企业模式
ii. 设计数据库逻辑模式
iii. 设计数据库物理模式
iv. 评价物理模式
v. 数据库实现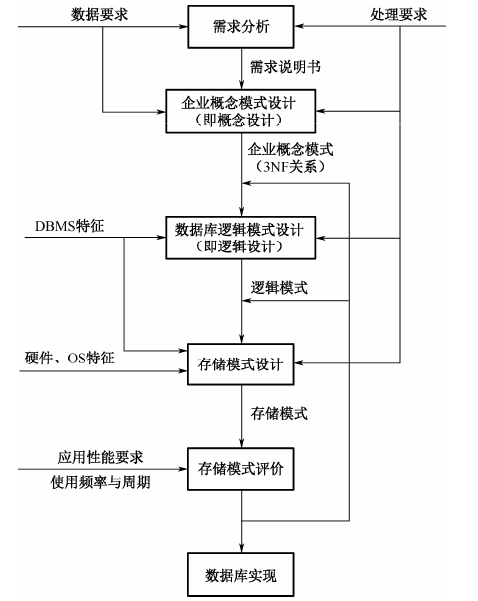
c. 设计的基本步骤
i. 需求分析:收集分析用户对系统的信息需求和处理需求,得到设计系统所必须的需求信息,建立系统说明文档。
1. 确认需求,确认设计目标
2. 分析和收集数据
3. 整理文档
ii. 概念结构设计:根据系统说明文档,抽象和综合处理,按照一定的方法构造反应用户环境的数据以及相互联系的概念模型。
1. 视图设计:根据所属范围,对应用户组以及相关信息形成完整的局部视图。
a. 确定局部视图的范围
b. 识别实体及其标识
c. 确定实体间的联系
2. 视图集成:反应用户组数据的局部数据模式综合成某个确定范围内的单一数据视图,全局数据模式。
iii. 逻辑结构设计:概念模型转换为DBMS所接受的逻辑模型,逻辑模型应满足数据村居,一致性,运算等方面的问题。
1. 概念结构转化为一般关系模型
2. 将一般关系模型向特定的DBMS支持下的数据模型转换
3. 根据应用需求和虚体的DBMS特征做调整和完善
iv. 物理设计:逻辑设计阶段得到的满足用户需求的已确定的逻辑模型在物理上加以实现。
1. 了解应用要求
2. 了解DBMS性能
3. 了解存放数据的外存设备特性 -
事务管理
a. 概念:事务时数据库系统运行的基本工作单位,相当于操作系统中的进程,是用户定义的一个数据库操作序列,这些操作要么全都做,要么全都不做,是一个不可分割的工作单位。
b. 特性
i. 原子性:数据库的逻辑工作单位
ii. 一致性:使数据库从一个一执行状态变到另外一个一致性状态
iii. 隔离性:不能被其他事务干扰
iv. 持续性:一旦提交,改变就是永远的
c. 并发控制:在多用户共享系统中,许多事务可能同时对同一数据进行操作,这个过程称之为并发操作,由数据库的并发子系统负责协调并发事务执行。
i. 并发带来的问题:
1. 丢失更新数据
2. 读到过时的数据
3. 读到了脏数据
ii. 并发控制的处理方式:锁机制
1. 排他锁(X封锁):只允许一个事务独锁数据。
2. 共享锁(S封锁):允许一个事务去修改数据,其他事务读取数据。
iii. 针对并行操作处理方式:封锁协议
1. 一级封锁协议:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。一级封锁协议防止丢失修改,保证事务T是可恢复的,但是不能保证可重复读和不读”脏“数据。
2. 二级封锁协议:一级封锁协议加上事务T在读取数据R之前先对其加S锁,读完后即释放S锁。二级封锁协议防止读”脏“数据,不能保证重复读。
3. 三级封锁协议:一级封锁协议加上事务T在读取数据R之前对其加S锁,直至事务结束才释放。三级封锁协议可防止丢失修改、防止读“脏”数据与防止数据重复读
4. 两端锁协议:所有事务必须分两个阶段对数据项加锁&解锁。扩展阶段在对任何数据读写操作之前,首先申请并获得对该数据的封锁,收缩阶段实在释放一个封锁后,事务不能再申请和获得任何其他封锁。
d. 故障恢复:
i. 事务故障:恢复子系统对事务做撤销处理,反向扫描文件日志,查找事物的更新操作;对事务更新操作进行逆操作;
ii. 系统故障:未完成事务对数据库的更新已写入数据库,已提交事务对数据库的更新还留在缓冲区未写入数据库。恢复在系统重新启动自动完成,正向扫描日志文件,找出故障发生前提交的事务,标识为重做(Redo)队列,找出故障发生时尚未完成的事务,标识记入撤销(Undo)队列。
iii.
iv. 介质故障:恢复最近一次备份;反向读取日志,已提交事务标识记入重做队列,从起点正向读日志文件,根据重做队列中的记录,重做所有已完成事务,将数据库恢复至故障前某一时刻一致状态。正向阅读日志文件,根据重做队列中的数据,重做已完成事务,将数据库恢复至故障前某一刻。
v. 计算机病毒 -
备份与恢复
a. 原则:
i. 保证丢失数据的情况尽量少或者完全不丢失。
ii. 备份和恢复时间尽量短,保证系统最大可用性
b. 冷备份
i. 数据库正常关闭,停止状态下利用操作系统的copy,cp,tar,cpio等命令将数据库文件全部备份下来。
c. 热备份
i. 数据库中需要备份的数据文件依次置于备份状态,相对保持静止,再利用操作系统的copy,cp,tar,cpio等命令将数据库文件全部备份下来。
ii. 备份软件再数据库正常运行情况下将数据文件备份出来。
d. 备份方式
i. 完全备份
ii. 增量备份:上次完全,增量,积累备份以来修改的数据
iii. 积累备份:上次完全或者积累备份以来修改过的数据 -
分布式数据库系统(Distributed DataBase)
a. 概念:分布式数据库由一组数据组成,这组数据分布在计算机网络的不同计算机上,网络中每个节点具有独立处理的能力,成为场地自治,它可以执行局部应用,同时,每个节点也能通过网络通信子系统执行全局应用。
b. 分布式数据库管理系统(DDBMS)负责分布式数据库的建立,查询,更新,复制,管理,维护的软件。
c. 分布式数据库系统(DDBS):一个配置了分布式数据库管理系统的计算机网络组成的计算机系统。
i. 数据的分布性
ii. 统一性
iii. 透明性
iv. 具有坚固性好,可扩充性好,可改善性能,自治性好。
d. DDBS的分类
i. 软件同构度,当所有服务器软件和客户软件相同时称为同构型分布式数据库,不同称为异构行分布式数据库
ii. 局部自治度来分,DDBMS存取必须通过客户端软件,称为无局部自治;若局部事务允许对服务器软件进行直接存储,称为有一定的局部自治。
iii. 按照分布透明度来分(模式集成度):根据用户对集成模式操作设计的片段,重复,分布等信息是否需要涉及分为高度分布式透明/无分布透明
e. 分布式式数据库目标:
i. 局部节点自治性:每个节点都是独立的数据库系统,有自己的数据库,运行他的局部DBMS,执行局部应用,具有高度自治性
ii. 不依赖中心节点:每个节点具有全局字典管理,查询处理,并发控制和恢复控制
iii. 能连续操作:目标使中断分布式数据库服务情况减至最少,当一个新场地合并到现有的分布式系统或从分布式系统中撤离一个 场地不会导致任何不必要的服务中断。
iv. 具有位置独立性:用户不必知道数据的物理存储地,像数据全部存储在局部场地一样。
v. 分片独立性:分布式系统如果可将给定的关系分成若干片,可提高系统的处理性能。
vi. 数据复制独立性:将给定关系可在物理级用许多不同存储副本或复制品在许多不同场地上存储。
vii. 支持分布式查询:局部,远程,全局查询。
viii. 支持分布式事务管理:恢复控制和并发控制。
ix. 具有硬件独立性:不同硬件系统可运行同样的DBMS
x. 具有操作系统独立性
xi. 须有网络独立性
xii. 具有DBMS独立性 -
分布式数据库架构:
a. 分布式模式数据库系统的模式结构层次
i. 全局外模式:全局应用的用户视图,模具概念模式子集
ii. 全局概念模式:分布式数据库中数据的整体逻辑结构。
iii. 分片模式:每一个全局关系可以划分为若干不相交的部分,每一个部分称为一个片段,即一个“数据分片”。
iv. 分布模式:定义分片模式的存放节点
v. 局部概念模式:全局关系逻辑划分成一个或者多个逻辑片段,每个逻辑片段被分配在一个或者多个场地,称为该逻辑片段在某场地上的物理映像或者物理片段。该场地上所有全局概念模式在该场地上物理映像的集合。
vi. 局部内模式:局部内模式是 DDB 中关于物理数据库的描述
b. 分布式模式数据库系统的模式分层特征
i. 数据分片和数据分配概念的分离,形成了"数据分部独立型"概念
ii. 数据冗余的显示控制,数据在各个场地分配情况在分配模式中一目了然,便于系统管理
iii. 局部DBMS的独立性 -
数据仓库(Data Warehouse)(为了处理历史数据为未来决策服务的一种技术)
a. 概念:数据仓库是一个面向主题的,集成的,相对稳定的,且随时间变化的数据集合,用于支持管理决策。
b. 特点
i. 按照一定主题域进行组织的。
ii. 数据仓库是集成的,在对原有分散的数据库数据抽取,清理的基础上,经过系统加工,汇总,整理得到的,消除元数据的不一致性。
iii. 数据仓库中的数据供企业决策分析使用,会被长期保存。数据仓库会有大量查询操作,很少的删除,修改操作。
iv. 数据仓库反映历史的变化属性。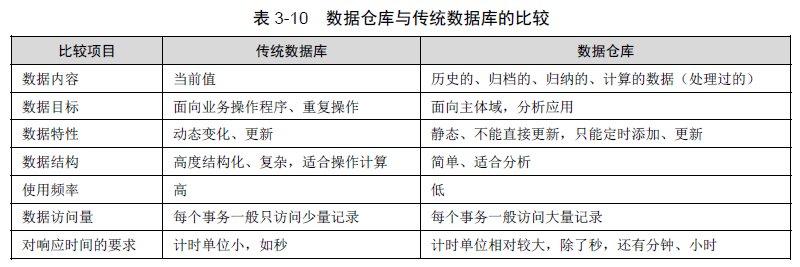
c. 数据仓库的结构:
i. 数据源
ii. 数据准备区
iii. 数据仓库数据库
iv. 数据集市/知识挖掘库
d. 数据仓库的框架结构
i. 基本功能层:包含数据源,数据准备区,数据仓库结构,数据集市/知识挖掘库,用于数据源抽取数据,对数据进行筛选,清洗,根据用户需求设置数据集市,完成数据仓库的复杂查询,决策分析,知识挖掘等。
ii. 数据仓库管理层:数据仓库的数据管理和数据仓库的元数据管理组成,用于数据抽取,新数据需求和查询管理,数据加载,存储,刷新,更新,安全性与用户授权管理系统以及数据归档,恢复净化系统
iii. 数据仓库的环境支持层:由数据仓库数据传输层和数据仓库基础层组成,数据仓库中不同结构之间的数据传输需要数据仓库的传输层来完成。
1. 数据仓库的传输层包含数据传输和传送网络,客户/服务器代理和中间件,复制系统及数据传输层的安全保障系统。
e. 数据仓库架构
i. 数据源:数据仓库系统的基础,系统的数据源泉。包括企业内部信息&外部信息。
ii. 数据的存储与管理:数据仓库系系统核心
iii. OLAP服务器:对分析需要的数据进行有效集成,按多维模型予以组织,以便进行多角度,多层次的分析,并发现趋势。
1. ROLAP
2. MOLAP
3. HOLAP
iv. 前段共聚:包括报表工具,查询工具,数据分析工具,数据挖掘工具以及基于数据仓库或者数据集市的应用开发工具。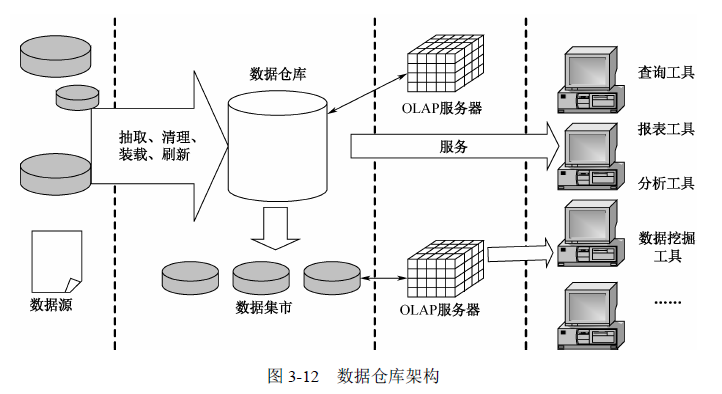
f. 数据仓库实现方法
i. 自顶向下
ii. 自底向上
iii. 联合方法 -
数据挖掘
a. 概念:从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程
b. 功能:
i. 自动预测趋势和行为
ii. 数据关联分析:数据关联是数据库中存在一类重要可被发现的知识
iii. 聚类,即数据库记录划分为一系列有意义的子集
iv. 概念描述,对某类对象的内涵进行描述,并概况这类对象的有关特征。
v. 偏差检测,寻找观测结果与参照值之间有意义的差别
c. 常用技术
i. 关联分析:用于发现不同事件之间的关联性,主要依据是事件发生的概率和条件概率应该符合一定的统计意义。
ii. 序列分析:用于发现一定时间间隔内接连发生的事件。
iii. 分类分析:通过分析具有类别的样本的特点,得到决定样本属于各种类别的规则或方法。利用这些规则和方法对未知类别的样本分类时应该具有一定的准确度。(例如叶贝叶斯方法,神经网络方法,决策树方法以及支持向量机)
iv. 聚类分析:将没有类别的样本聚集成不同的组,并且对每一个这样的组进行描述的过程。
v. 预测:根据样本的已知特征估算某个连续类型的变量的取值过程,预测常用常用回归分析技术。
vi. 时间序列:根据时间分析序列分析的随时间变化的事件序列,以预测未来发展趋势,或寻找相似的反战模式或者周期性发展规律。
d. 数据挖掘流程:
i. 问题定义(熟悉目标的定义,熟悉背景知识)
ii. 建立数据挖掘库(收集要挖掘的数据源)
iii. 分析数据(对数据深入调查的过程,发现其因素之间的关系)
iv. 调整数据(对问题的解决要求能进一步明确化,量化,针对问题需求对数据进一步处理,基于对整个数据挖掘过程的新认识组成一个新的变量,建立形成知识模型。数据挖掘的核心环节,运用神经网络,决策树,数据统计,时间序列分析等方法建立模型)
v. 评价和解释 -
NoSQL
a. 优点
i. 易扩展(数据之间无关系)
ii. 大数据量,高性能(Nosql的Cache是记录级的)
iii. 灵活的数据模型
iv. 高可用性 -
大数据
a. 概念:在一定时间内,无法用常规软件工具进行捕捉,管理和处理的数据集合。
b. 特点
i. Volume 体量巨大
ii. Variety 数据类型繁多
iii. Value 价值密度低
iv. Velocity 处理速度快
c. 处理技术
i. 大数据采集
ii. 大数据预处理
iii. 大数据存储及管理
iv. 大数据分析及挖掘
v. 大数据展现和应用
d. 应用场景。。