版权声明:相互学习,一起成长,转载请联系博主。 https://blog.csdn.net/sunyaowu315/article/details/88012578
Series 和 Dataframe格式的数据处理工作,有很多常用的也比较巧妙的小方法,现总结下,方便理解应用。
本文会已方法基础格式+代码样例的形式加以讲解说明。
一 基础方法介绍
Series 和 Dataframe
import numpy as np
import pandas as pd
#from pandas import Sereis, DataFrame
df = pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz'))
ser = pd.Series(np.arange(3.))
df = pd.DataFrame(data, columns = ['A', 'B', 'C', 'D'])
行列
多种形式,灵活应用
''' 行 '''
df.loc
df.irow(0) = 1
df.head() #返回df的前几行数据,默认为前五行,需要前十行则df.head(10)
df.tail() #返回df的后几行数据,默认为后五行,需要后十行则df.tail(10)
df.iloc[-1] #选取DataFrame最后一行,返回的是Series
df.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame
df.loc[df['A'] == 'cutoff',]
''' 列 '''
df.columns
#利用字段名进行切片索引
df['A'] = 1 #选择表格中的'A'列,使用类字典属性,返回的是Series类型
df.A = 1 #选择表格中的'A'列,使用点属性,返回的是Series类型
df[['A','B']] #选择表格中的'A','B'列,返回的是DataFrame属性
df['A':'B'] #利用index值进行切片,返回的是*A*前闭后闭*B*的DataFrame #即末端是包含的
#利用字段所在的位置进行切片索引
df.icol(0)
df[0:2] #返回第1列到第2列的所有行,前闭后开,包括前不包括后
df[1:2] #返回第2列,从0计,返回的是单行,通过有前后值的索引形式,#如果采用df[1]则报错
df.ix[1:2] #返回第2列的第三种方法,返回的是DataFrame,跟data[1:2]同
''' 行列综合使用 '''
df.loc['a',['B','C']] #返回'a'行'B'、'C'列,这种用于选取行索引列索引已知
df.iat[1,1] #选取第二行第二列,用于已知行、列位置的选取。
df.ix[1:3,[0,2]] #选择第2-4行第1、3列的值
df.ix[df.a>5,3]
df.ix[1:3,['a','e']]
data.iloc[:,0] # python3调整的方法
索引
df.index
df.set_index('A')# 设置A列为索引列
df.reset_index(drop=True)#drop是否保留原索引
值
df.values
df['A'].values
命名
df.columns = [['A','B','C','D']]
df.rename(columns = {'A':'B'})
新增字段
df['B'] = np.where(df['A'].str.contains('str'),1,0)
合并
df1 = df1.append(df2)
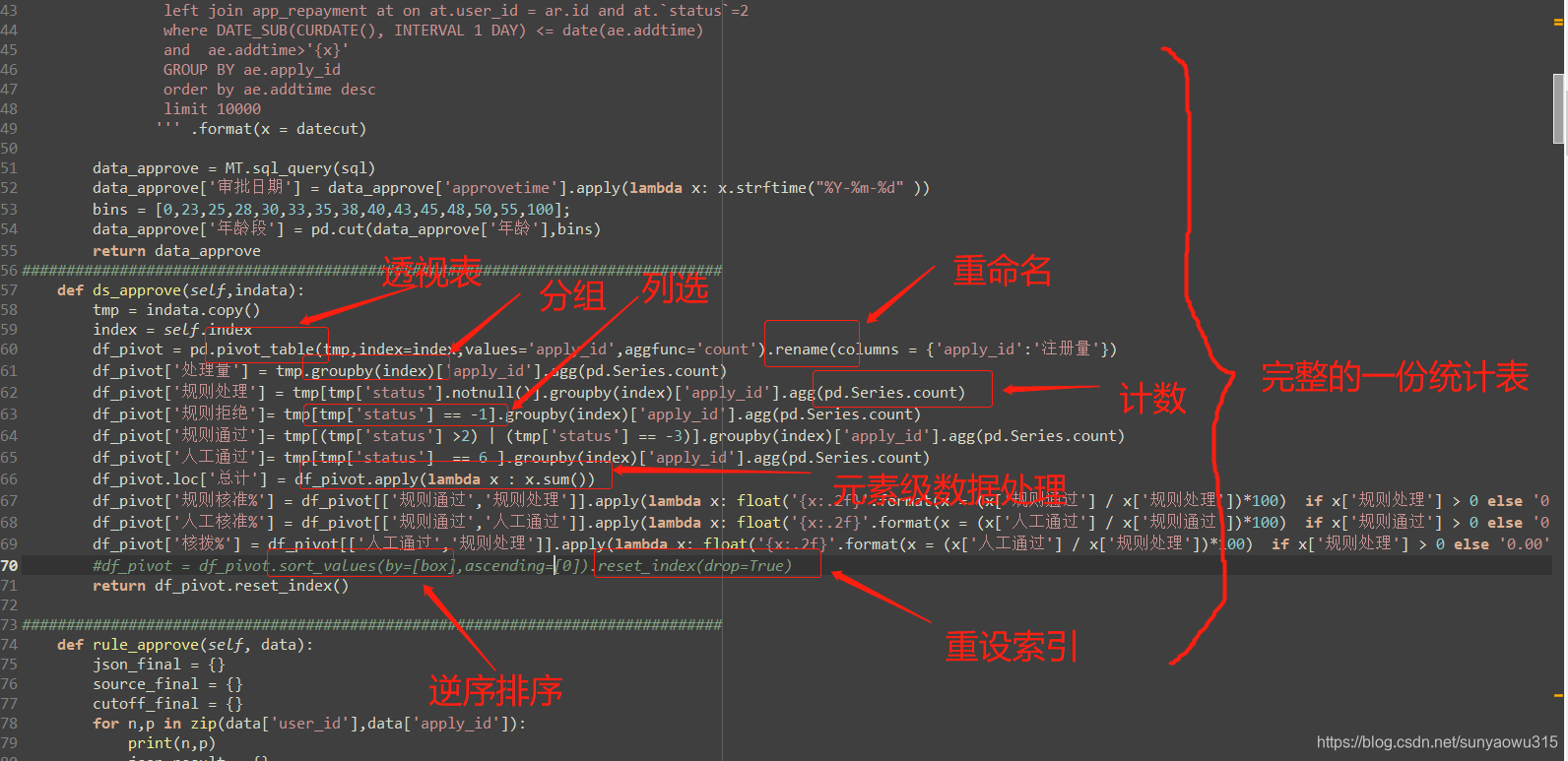
分组
grp1 = df.groupby(['code'])['code'].agg([pd.Series.count]).reset_index().rename(columns={'count':'nameA','code':'nameB'})
匹配
df = pd.merge(df1,df2,left_on = 'id',right_on = 'ID',how = 'left')
排序
df.sort_values(by = 'A',asending = Flase) #True 和Flase做正序逆序选择
行列转置
df = df.T
去重
df.drop_duplicates('id', inplace = False)
删除行列
df = df.drop(df[dfn[target] == 0].index)
del df['A']
df.dropna(axis=0, how='any', inplace=True)
缺失值填充
df.fillna(0)
唯一值
df['A'].unique()
python去除字符串中空格和特殊符号的方法
" xyz ".strip() # returns "xyz"
" xyz ".lstrip() # returns "xyz "
" xyz ".rstrip() # returns " xyz"
" x y z ".replace(' ', '') # returns "xyz"
Dataframe字段元素级数据处理
df['B'] = df['A'].map(lambda x : 'short' if int(x) <5 else 'midle' if int(x)<30 else 'long')
df['C'] = df[['A','B']].apply(lambda x: float('{x:.2f}'.format(x = (x['A'] / x['B'])*100) if x['B'] > 0 else '0.00'),axis = 1)
二 综合应用实例讲解
下面代码较为综合的运用了Dataframe和Series中较为常见的一些数据处理方法: