当前环境:Python3.7 ,Pandas 0.25.3
1.声明
由于前段时间完成了对Pandas的基本学习操作,这里写下的内容是对学习进行复习的,用于本人复习
2.官方的实例(本人修改过的)
# 首先导入当前的pandas这个数据分析的库,简单的使用DataFrame
import numpy as np
import pandas as pd
# 发现当前的np中具有一个nan这个类型的数据
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s)
# 使用pandas的date_range生成以指定时间参数数据和指定跨度的时间日期,这里跨度为6天
dates = pd.date_range('20130101', periods=6)
print(dates) # 当前的数据类型为datetime64[ns]
# 产生一个随机的6行4列的数组
np_array = np.random.randn(6, 4)
print("输出当前产生的数据:\n{}".format(np_array))
# 当前的pd.DateFrame使用日期类型的框架,index表示指定当前的最前列的数据(是索引),columns表示指定当前的每个表头中显示的数据
df = pd.DataFrame(np_array, index=dates, columns=list('ABCD'))
print("输出格式化的数据:\n{}".format(df))
# 输出当前的行索引
print("输出当前行的索引:\n{}".format(df.index))
# 输出当前的列索引值
print("输出当前的列的缩影:\n{}".format(df.columns))
# 输出当前的数据类型
print("输出当前的数据的数据类型:\n{}".format(df.dtypes))
# 使用索引方式取出当前的数据,就是使用当前的columns这个列的数据实现的列索引
print("输出当前的A列的数据:\n{}".format(df.A))
print("输出当前的A列的数据:\n{}".format(df["A"]))
# 使用index的方式实现的行索引
print("输出当前的第一行的数据:\n{}".format(df[:1]))
# 输出指定的日期的数据
print("输出2013-01-04到2013-01-05这一行的数据:\n{}".format(df["20130104":"20130105"]))
# 获取前3行的数据
print("前三行的数据为:\n{}".format(df.head(3)))
# 获取最后3行的数据为
print("前三行的数据为:\n{}".format(df.tail(3)))
# 修改当前的行索引值index
df.index = ["第{}天".format(i) for i in range(6)]
print("输出修改后的行索引值:\n{}".format(df))
# 修改当前的列索引值columns
df.columns = ["商品{}".format(i) for i in range(1, 5)]
print("输出修改列索引后的值:\n{}".format(df))
print("======================")
# 获取第0天商品1的数据
print("第0天商品1的数据:\n %.2f" % (df["商品1"]["第0天"]))
print("商品1的数据:\n {}".format(df["商品1"]))
# print("商品1的数据:\n {}".format(df["第0天"])) 这个出现错误,不能使用index中的数据作为索引,会报错
# 只能使用 :1这种数据才能访问,就是这种切片的方式获取数据,就是使用索引的时需要使用先列后行的方式获取数据
print("商品1的数据:\n {}".format(df[:1]))
由于这里显示的数据太多,所以本人不上传图片了
1.通过官方和自己的发现,当前的Pandas基本上完全兼容当前的numpy的,可以将当前的ndarray数据转换为Pandas中的数据
2.当前的Series创建的是一个一维度的数据,就是一般的一维数组,只能放入一维度的数据,否者报错
3.当前的DataFrame创建的数据就是一个二维度的数据,可以设置行索引和列索引
4.当前的DataFrame中具有index,columns,dtypes这些数据,表示DataFrame就是一个带有表头和行头的矩阵数据,并且可以使用object类型的数据
5.可以重写DataFrame当前的行索引和列索引
6.可以使用切片的方式获取数据,类似当前的python中的数组数据的获取
3.基本的Series操作
# 当前的Series的属性和方法
# 当前的Series
import numpy as np
import pandas as pd
# 使用当前的series创建属性以及索引
indexs = ["index_{}".format(i) for i in range(0, 5)]
randoms_data = np.random.randint(1, 100, (5))
print("创建的索引为:\n{}".format(indexs))
print("当前的数据为:\n{}".format(randoms_data))
# 注意这里的数据必须是一维的数据
pd_series_obj = pd.Series(randoms_data, index=indexs)
print(pd_series_obj)
# 使用字典的方式创建series
print("使用字典的方式创建series")
dict_pd = pd.Series({"one": [1, 2, 3], "two": [4, 5, 6], "three": [7, 8, 9]})
print(dict_pd)
# 发现当前的数据中默认的key就是当前的索引(index),当前的key对应的value就表示当前显示的数据
print("====================")
print(pd.Series({"name": "张三", "age": 18, "pwd": 123}))
这个Series就是一个简单的一维度的数组,所以操作简单
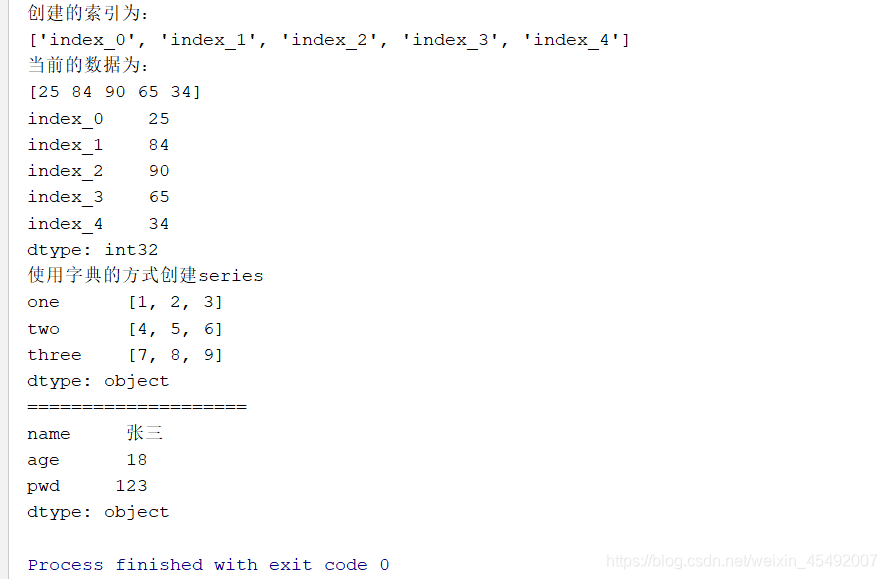
总结:
1.创建Series的时候可以使用当前的dict字典的方式创建数据,key默认就是index数据,value就是当前的值
4.总结
1.使用pandas创建Series和DataFrame实例的时候需要注意创建的使用的形式,一个只能是一维度的数据,一个确实二维度的数据,写错就会报错
2.Pandas中的数据基本具有ndarray中的方法和属性
3.DataFrame在创建的时候可以指定index和columns,如果不指定就默认使用下标方式,从0开始
以上纯属个人见解,如有问题请联系本人!
