前言
本文主要是想分享下个人实际工作和学习中使用的优化方法,供大家参考和学习,同时也对自己有一个记录总结,巩固知识。
其实优化无非是从几个大的层面入手,即我们所熟知的三大核心。CPU、内存、GPU。应该是我们接触最多,也最需要去深入了解的。下面我就从这三个方面开始探讨。
文章目录
CPU的优化
1、CPU本身
首先,CPU是由哪些组成的?粗略的概括就是控制器,运算器,寄存器,缓存,总线。不需要特别的了解其中所有的东西,我们主要就是注意下缓存跟寄存器。
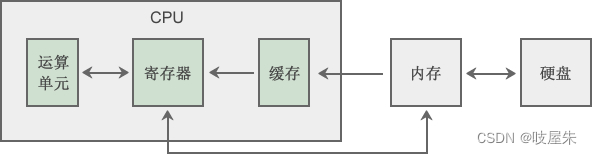
寄存器(Register)是CPU内部非常小、非常快速的存储部件。寄存器 离CPU 更近,速度比内存更快,但是跟小,一般用于存储一些小的临时数据,例如函数的返回值(例如int char bool),数学运算结果等。
那么优化CPU首先就得明白什么地方需要CPU。CPU的工作职责太多太广。我只能尽量将一些遇到的列举出来
2、CPU优化记录
GC优化
GC——垃圾回收机制。按理说GC主要是对内存进行操作,那为什么会放到CPU优化中呢?其实很简单,GC本质上是对托管堆中的对象进行清理,即标记-清除-压缩。具体的实现可以查阅 Boehm GC、S-GenGC 等相关算法。
其实这些算法都是通过遍历查找对象与对象间的引用来标记出对象是否可以清除。那么如果托管堆中的对象越多,则GC回收一次的开销越高。而GC的回收本身也是 CPU来处理的,所以GC 其实是跟CPU紧密相关的。
- 如果一个类比较简单,可以考虑使用结构体替换。效率更高。
- 提高CPU的缓存命中率,尽量保证内存的连续性。
- 高频率地 New Class/Container/Array等,Update 中需要尽可能的避免装箱操作,能缓存尽量都缓存到局部变量中。
- 匿名函数与委托,谨慎使用,将方法作为参数传递时,如果是已经定义的方法,则会有堆内存的分配,如果是匿名函数,只有非闭包才不会有额外的GC产生。
- 多用对象池
- List 的 ToArray 方法不要用,因为是重新拷贝一个数组进行复制,GC较多。
- yield return 0;//会产生垃圾,int变量0被装箱。改成 yield return null
- 在适当的时机主动调用GC.collect。
- Linq和正则表达式在后台有装箱操作而产生垃圾,最好少使用。
- 字符串的处理,要了解字符串本身是个常量,创建出来就不能改变了,如果改变他的值其实是一次拷贝,产生额外的GC。尽量避免在 Update中操作字符串,包括赋值,拼接等。拼接尽量用 StringBuilder 进行拼接。内部是Char数组实现。
代码效率优化
- 缓存:空间换时间,尽量将频繁使用的对象缓存。
- 预处理:把同一时间内的计算提前,避免同一时间处理过多的数据造成CPU占用过高。
- 限帧法:如果有些模块不需要 每帧处理一次刷新,例如Buff模块。可以优化 1秒Tick一次,或者半秒Tick一次。
- 分帧法:例如生成怪物,可以将一次生成分摊到多个帧,减少同一帧的开销。
- 多线程:在网络模块,文件读写模块,可以考虑多线程,优化CPU效率。
- 事件机制:有些需要Tick 来进行判断的逻辑,可以改成事件机制触发。不需要每帧判断一次。
降低DrawCall
DrawCall 其实就是渲染命令,即调用图形渲染的接口。这个过程主要是由CPU去处理。而降低DrawCall,本质上就是更多的去合批,即一次将更多的顶点数据合并在一起提交。
- 静态合批,内存换CPU。准确的说其实不是降低DC,而是合批,即只需要设置一次渲染状态,DC还是不变的。优点很明显,一个是减少Batch,还一个是减少CPU的计算量,如果是在美术生产阶段合并的话,Unity 没法对子模型进行可见性判断。这样CPU的计算量增多。 当然也有缺点:那就是如果一个 GameObject 引用共享的模型,如果静态合批是会复制多份网格数据的,场景中所有引用相同模型的GameObject都必须将模型顶点信息复制,并经过计算变化到最终在世界空间中,存储在最终生成的Vertex buffer中。这就导致了打包的体积及运行时内存的占用增大。
- 动态合批:需要注意的是 是限制900个顶点属性,不是数量,需要将法线向量、UV、切线都得包含进去总共不超过900。并且这个是运行时处理,不可避免的增大CPU消耗。
- GPUInstancing
内存优化记录
我们主要关注的就是 Native内存 跟 Mono内存,简单来说一个是Unity 资源存放的地方,一个是 代码申请的地方。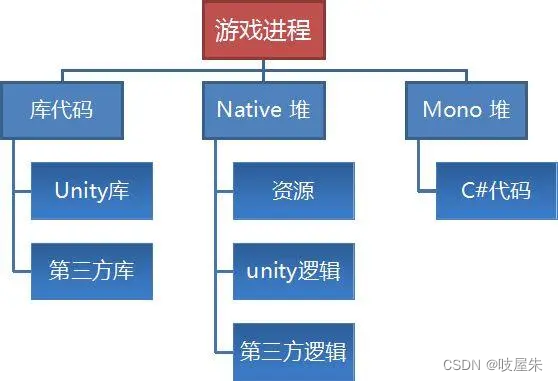
资源优化
1、纹理
- 压缩格式:

- 纹理尺寸尽量小,并且尽量保证是 2的N次幂。
- 根据需求判断是否开启 mipmap。UI不需要开启。
- Read / Write 不需要则不要开启,除非需要动态操作贴图。
- 图集问题:例如图集利用率等,建议拆分成多张小图。
2、网格
-
顶点数不宜过多,尽量不要超过静态合批的上限。
-
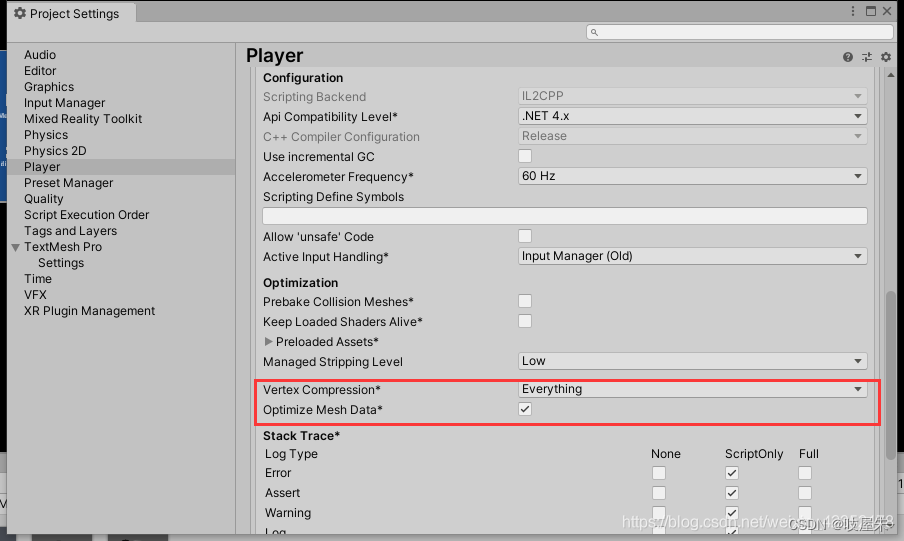
PlayerSetting > OtherSetting > Optimization > Vertex Compression 开启后可将顶点数据精度缩小,32位到16位。同选项还有 Optimize Mesh Data,这个开启后可以剔除一些用不到的顶点数据,例如法线,切线等。目前好像会有bug,测试使用。
-
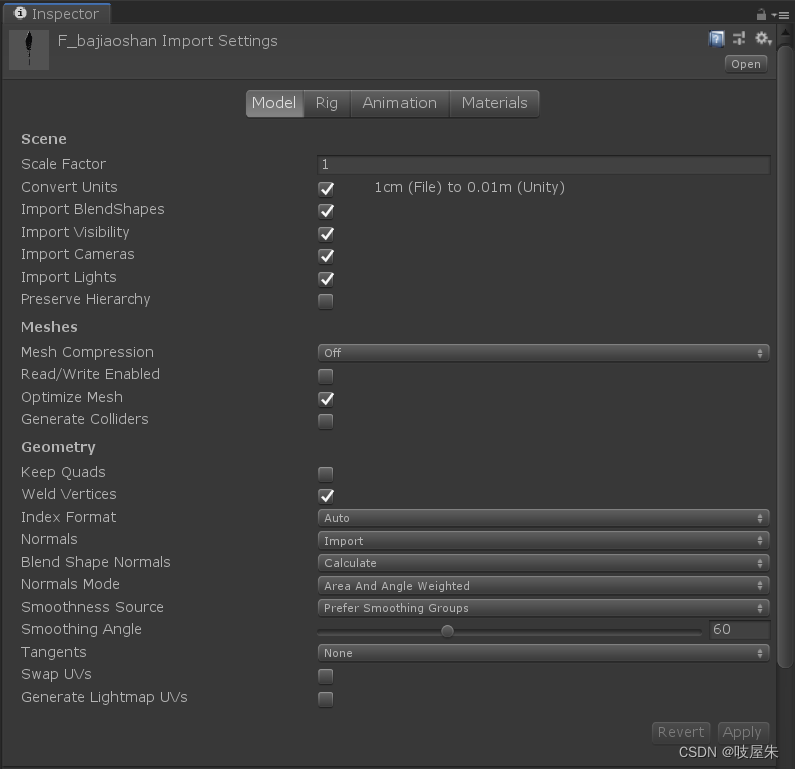
在模型的导入设置中,也有 Optimize Mesh,原理是重新排列顶点索引,优化运行时渲染效率
-
Read/Write Enabled 同纹理一样,非必要不打开。
-
Weld Vertices:焊接顶点,建议打开,可以合并一些同位置的顶点,减少开销。
-
Normals&Tangents :可以选择不导入法线切线,如果模型用不到的话
-
模型的拆分也很重要,颗粒度不宜过大,也不宜过小。过大容易导致视锥体剔除不了。
-
如果模型的顶点,面数美术都无法修改,可以考虑手动合并一些网格,用CombineInstance 类里的 CombineMeshes 方法。当然如果贴图不同也得合并贴图。重新设置UV。
3、动画
- 骨骼导入设置 勾选 OptmizeGameObjects,可以剔除一些只有Transform 的骨骼节点。提高CPU效率
- 控制Animator.Initialize触发频率,建议对于频繁实例化的动画角色,可尝试通过缓冲池的方式进行处理,在需要隐藏动画角色时,不直接Deactive角色的GameObject,而是DisableAnimator组件,并把GameObject移到屏幕外,从而降低Animator.Initialize的调用频率。
- Animator——CullingMode 可以设置成 Cull Update Transforms:当物体不被摄像机可见时,仅计算根节点的位移植入,保证物体位置上的正确,或者 Cull Completely:当物体不被摄像机可见时,完全终止动画的运行。
- 降低动画数据的精度,默认的关键帧数据都是 float 去存储的。大致实现思路就是,通过读取Anim文件本身的数据,修改曲线内部的值,将精度全部缩小到三位。
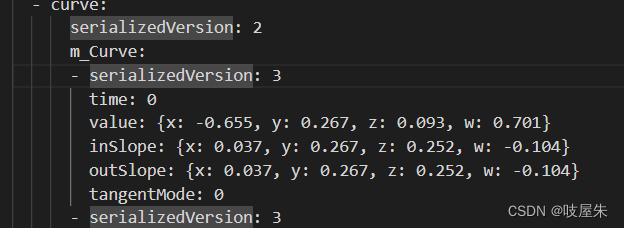
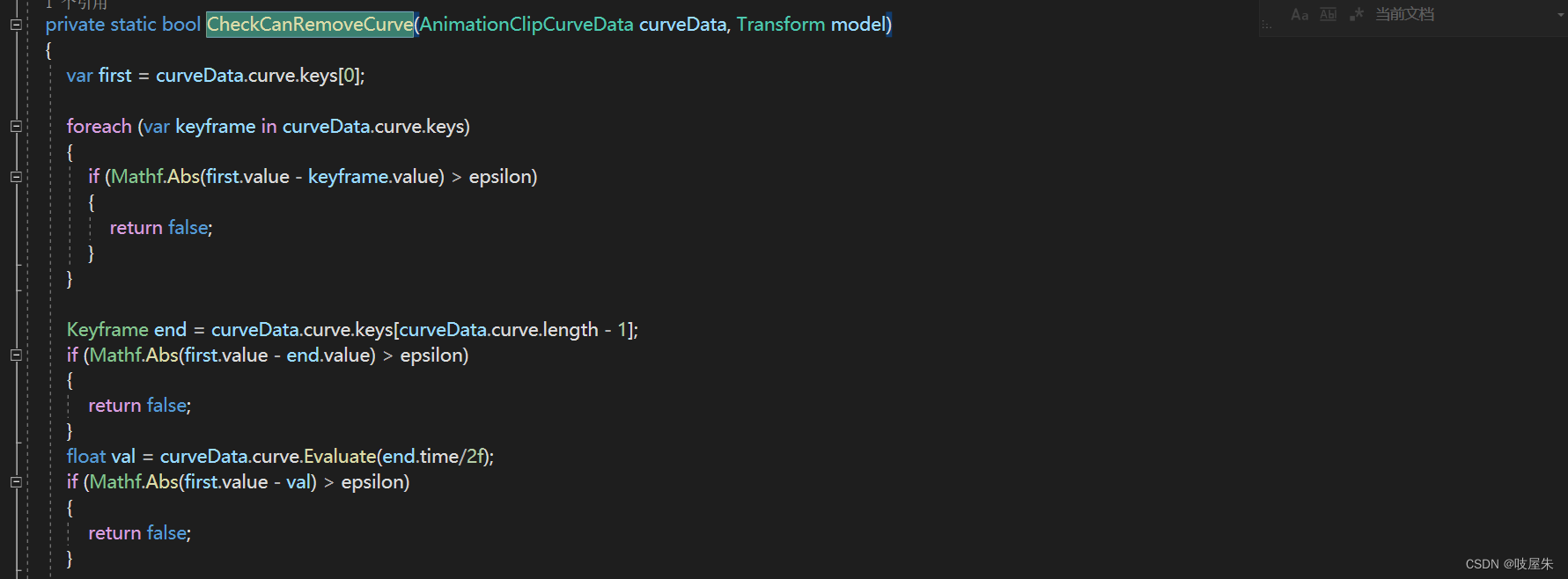
- 还可以剔除多余曲线,例如一些从头到尾没有变化的曲线,例如缩放曲线这种。优化内存占用。
- 如果一次渲染同类物体较多,考虑使用 GPU Skinning+GPU Instancing 。即烘焙动画数据到贴图上,将顶点运动交个GPU处理。
4、字体
可以使用字体裁剪工具,裁减掉一些生僻字等,缩减大小。
5、AssetBundle
这部分主要就是宏观上的资源管理,如果处理好加载的AB包和Asset。
- 引用计数:通过计数的方式记录,AB对Asset 的引用计数。
Mono内存优化
这一块的优化类似上面的GC优化,本质其实类似,减少堆内存的分配,一定程度上就是减少GC触发的频率。
- 对象池:对于高频率实例化和销毁的对象,尽量都用对象池管理。减少实例化的消耗,并且重复利用内存。
- 考虑主动调用GC.Collect,进行主动回收垃圾。
渲染优化
UGUI优化
UGUI的优化比较多而杂,但其实原理都是差不多的。即怎么保证更多的网格合批,以及怎么减少频繁的Rebuild。
- 图集,图集策略很重要,最好能够保证一个大的UI功能中所有的 贴图。都能打到一张图集中,然后通用的一些UI贴图则打进通用的图集中。保证一块大的UI同时只用两张图集。
- 图集利用率问题:如果一张图集空白处较多,考虑裁剪一些贴图的透明区域,或者长条的贴图裁剪成两份。
- 动静分离,防止频繁移动的UI元素频繁造成整个Canvas下的 Rebuild。
- Image组件空的Sprite,如果需要接收点击事件,用EmptyRayCast,去除提交绘制顶点数据。
- 注意UI物体的Z值,如果不为0,是有可能打断合批的。
- 注意材质问题,如果不用UI Default 材质,尽量不要重叠在太多UI下面,导致打断合批。
- Mask 遮罩,尽量用RectMask2D 替代。Mask用了模板缓冲,增加两个drawCall,而RectMask2D,进行了裁剪。
- 尽量精简UI界面的 层级结构,不要太过复杂。Rebatch 是需要计算深度遍历的。
GPU优化
- 同屏面数不宜过高。
- LOD。
- shader 中的变量数据格式缩减, 例如 Float 用 half。
- 相机开启 遮挡剔除,场景物体也记得勾选。
- 光照烘焙
- 警惕透明物体,不透明的物体不要放在透明渲染队列中。
- 贴图分辨率控制,如果是那种俯视角的3D游戏,贴图分辨率可以适当降低一些,节省带宽。
- 阴影如果可以尽量用简单贴图替代。
- Fog {Mode Off } 关闭雾效