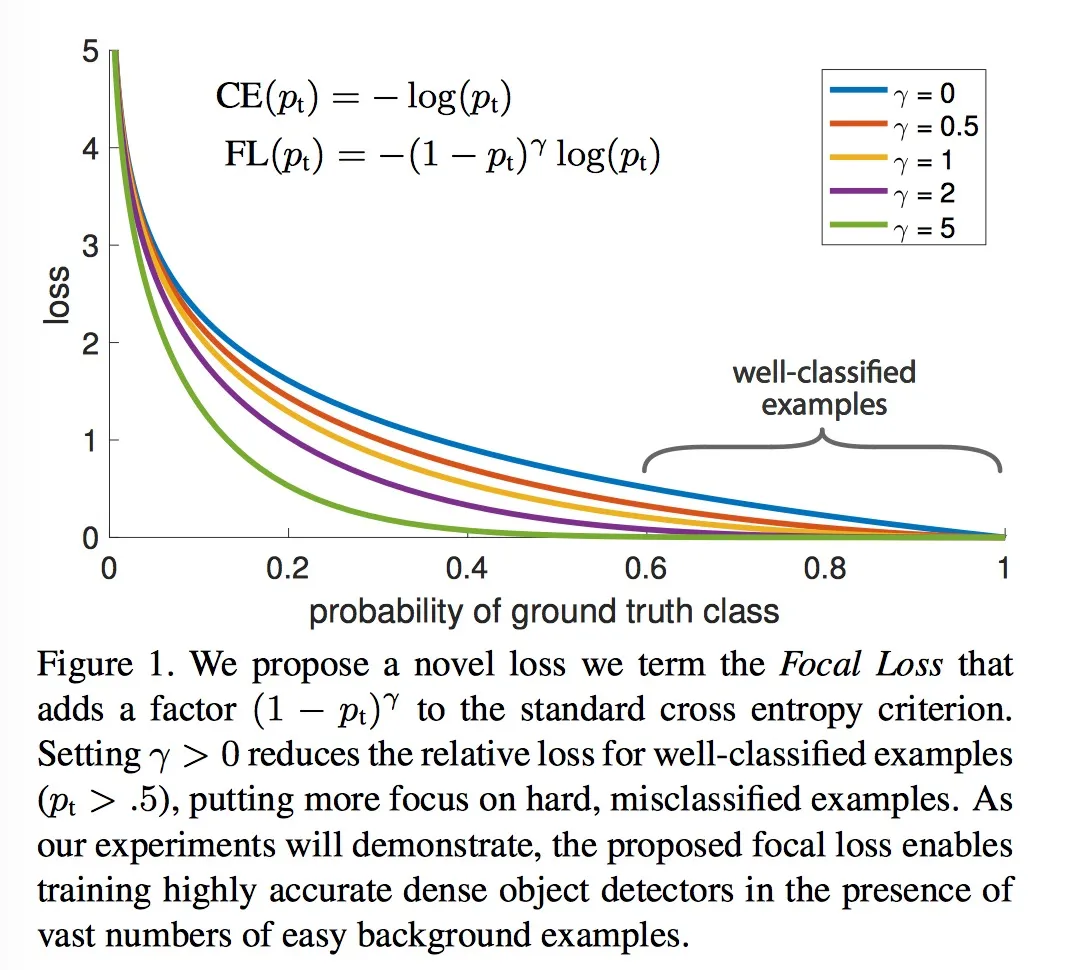
Focal loss 是 文章 Focal Loss for Dense Object Detection 中提出对简单样本的进行decay的一种损失函数。是对标准的Cross Entropy Loss 的一种改进。 FL对于简单样本(p比较大)回应较小的loss。 如论文中的图1, 在p=0.6时, 标准的CE然后又较大的loss, 但是对于FL就有相对较小的loss回应。这样就是对简单样本的一种decay。其中alpha 是对每个类别在训练数据中的频率有关, 但是下面的实现我们是基于alpha=1进行实验的。
在PyTorch中使用Focal Loss,你可以按照以下步骤进行操作
方法一:
1、创建FocalLoss.py文件,添加一下代码

代码修改处:
classnum处改为你分类的数量- P = F.softmax(inputs) 改为 P = F.softmax(inputs,dim=1)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class FocalLoss(nn.Module):
r"""
This criterion is a implemenation of Focal Loss, which is proposed in
Focal Loss for Dense Object Detection.
Loss(x, class) = - \alpha (1-softmax(x)[class])^gamma \log(softmax(x)[class])
The losses are averaged across observations for each minibatch.
Args:
alpha(1D Tensor, Variable) : the scalar factor for this criterion
gamma(float, double) : gamma > 0; reduces the relative loss for well-classified examples (p > .5),
putting more focus on hard, misclassified examples
size_average(bool): By default, the losses are averaged over observations for each minibatch.
However, if the field size_average is set to False, the losses are
instead summed for each minibatch.
"""
def __init__(self, class_num=5, alpha=None, gamma=2, size_average=True):
super(FocalLoss, self).__init__()
if alpha is None:
self.alpha = Variable(torch.ones(class_num, 1))
else:
if isinstance(alpha, Variable):
self.alpha = alpha
else:
self.alpha = Variable(alpha)
self.gamma = gamma
self.class_num = class_num
self.size_average = size_average
def forward(self, inputs, targets):
N = inputs.size(0)
C = inputs.size(1)
P = F.softmax(inputs)
class_mask = inputs.data.new(N, C).fill_(0)
class_mask = Variable(class_mask)
ids = targets.view(-1, 1)
class_mask.scatter_(1, ids.data, 1.)
#print(class_mask)
if inputs.is_cuda and not self.alpha.is_cuda:
self.alpha = self.alpha.cuda()
alpha = self.alpha[ids.data.view(-1)]
probs = (P*class_mask).sum(1).view(-1,1)
log_p = probs.log()
#print('probs size= {}'.format(probs.size()))
#print(probs)
batch_loss = -alpha*(torch.pow((1-probs), self.gamma))*log_p
#print('-----bacth_loss------')
#print(batch_loss)
if self.size_average:
loss = batch_loss.mean()
else:
loss = batch_loss.sum()
return loss
2、在你的训练函数里加入模块
from FocalLoss import FocalLoss
loss = FocalLoss()
方法二:
首先,确保你已经导入了torch和torch.nn模块,其中torch.nn提供了各种常见的损失函数。
import torch
import torch.nn as nn
然后,定义一个自定义的Focal Loss类,继承自torch.nn.Module。在类的构造函数中,可以指定Focal Loss所需的参数,例如γ(调节因子)和权重。
class FocalLoss(nn.Module):
def __init__(self, gamma=2, weight=None):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.weight = weight
def forward(self, inputs, targets):
ce_loss = nn.CrossEntropyLoss(weight=self.weight)(inputs, targets) # 使用交叉熵损失函数计算基础损失
pt = torch.exp(-ce_loss) # 计算预测的概率
focal_loss = (1 - pt) ** self.gamma * ce_loss # 根据Focal Loss公式计算Focal Loss
return focal_loss
接下来,在模型训练时,使用自定义的Focal Loss替代交叉熵损失函数即可。
# 定义模型
model = YourModel()
# 定义损失函数(使用自定义的Focal Loss)
criterion = FocalLoss(gamma=2, weight=None)
# 初始化优化器等
# 开始训练循环
for epoch in range(num_epochs):
# 前向传播、计算损失
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播、更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 其他操作(如打印训练日志等)
通过以上步骤,就可以在PyTorch中将损失函数由交叉熵损失函数换为Focal Loss。请注意,上述代码示例中的一些细节(例如模型、输入、优化器等)可能需要根据你的实际情况进行修改和补充。