[阅读论文] RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining
摘要
大规模的预训练语言模型在NLP任务上取得了很好的成果。但是,它们已被证明容易受到对抗性攻击,尤其是对于中文等字形语言而言。针对于以上问题,本文提出了ROCBERT: 一种经过训练的中文Bert,对各种形式的对抗性攻击 (例如单词扰动,同义词,错别字等) 具有鲁棒性。它是通过对比学习目标进行预训练的,该目标在不同的综合对抗示例下最大程度地提高了标签的一致性。该模型将包括语义,语音和视觉特征在内的多模态信息作为输入。在5个中文NLU任务中,ROCBERT在三种对抗算法下的性能优于强基线,且不会牺牲干净测试集上的性能。在人为攻击下,它在不良内容检测任务中也表现最佳。
引言
在大规模的预训练模型中,通过对充分的注释数据进行微调,已经能够在许多基准测试集中接近甚至超过人类的表现。然而,即使预先训练了大量的文本,模型仍然容易受到对抗性攻击,如同义词、单词删除/交换、拼写错误等。这些对抗性的例子经常出现在现实场景中,可以是自然的(例如,拼写错误),也可以是恶意的(例如,避免自动检测不良内容)。
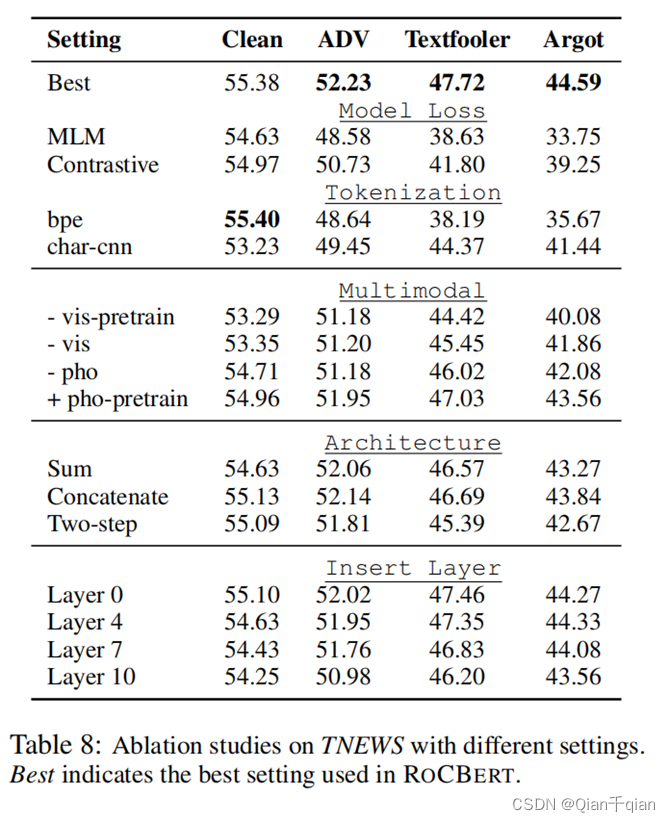
攻击方式
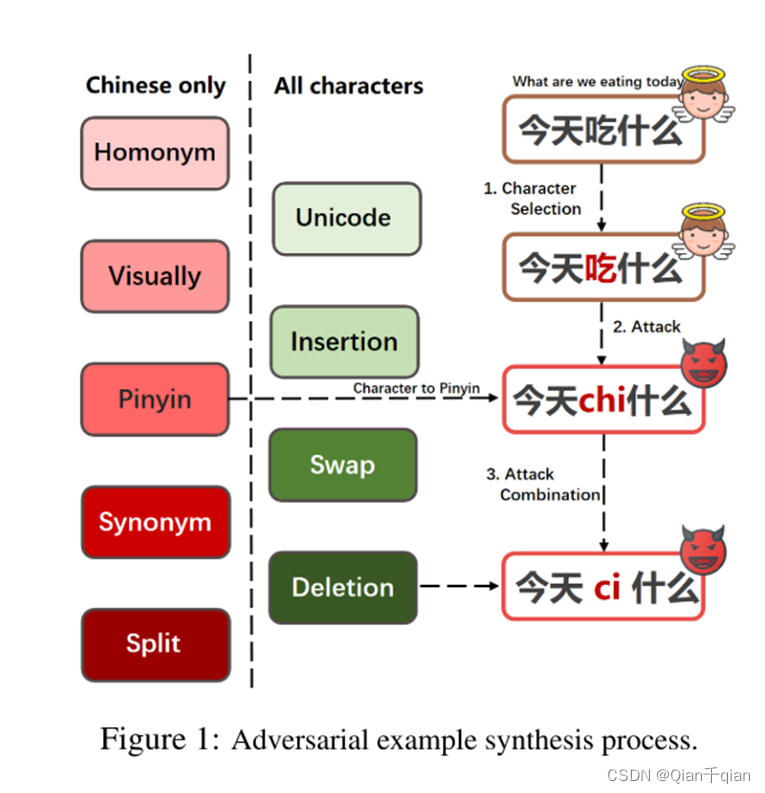
在表1中给出了一些示例“科比(Kobe)”可以替换为同义词、语音或视觉上相似的单词。攻击者还可以用拼音替换字符,然后继续字母级别的攻击(表中的“keb1”)。语义和语音的隔离以及汉语书面语中丰富的字形字符使得攻击形式比英语等字母语言中的攻击形式更加多样化。
本文贡献:
- 提出用对比学习预训练一个健壮的中文Bert,这样该模型不仅可以在干净的测试集上表现良好,而且可以在对抗例子上表现良好。
- 用算法合成的对抗例子对模型进行预训练,包括语义、语音和视觉攻击的组合。它将多模态特征作为输入来处理所有级别的可能攻击。
- 在各种对抗攻击者的情况下,预训练模型在5个NLU任务和1个不良内容检测任务上优于强基线。
- 文章对训练前选项进行了广泛的消融研究,并与流行的防御方法进行了广泛的比较。
相关工作
对抗防御
对抗性防御最常见的方式是对抗性训练,它只是将合成的对抗性示例附加到训练数据中。尽管如此,它只依赖有限的标记训练数据。相比之下,本文提出的RoCBert预先处理了数十亿文本,能够更好地适应不同的对抗变体。(我们的数据量更大)
另一种流行的方法是先用现成的拼写检查器去除噪声,然后将纠正后的文本输入模型。
问题1:不仅需要检测,而且需要还原,难度更大!
问题2:如若还原错误,很有可能会造成更大的偏差。
对抗例子合成(数据准备)
对比学习是一个二分类,需要有正例和反例,我们的目的是提升模型的鲁棒性,换句话说,需要让模型知道:“我是一个学生”和“我是一个子生”表达的是同一个意思,只不过是写了一个错别字。那么正例就有了,就是攻击算法以上面说的攻击方式生成的句子,就是原句子的正例,反例更容易,就是一个batch中的所有的其他句子。那么问题来了,如何生成正例?
第一个问题:在一个句子中选择哪些字符进行攻击?
在这句话中我们选择了字符“吃”,攻击的字符并非随机选择,而是根据一个字符在句子当中的信息量来进行选择。句子中某个字符ci被选中的概率为:
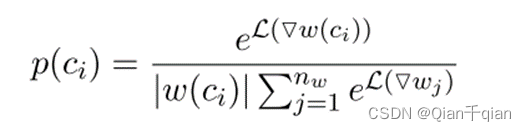
可以理解为,语言模型实际上是预测一个句子出现的概率,例如
“我是一个学生”这句话就比“我是一个”这句话出现的概率更高。
这意味着,学生这个词语所包含的信息量较大,只不过这里使用的是概率,上面使用的是损失。
第二个问题:一句话中选择多少字符进行攻击?
文中定义了“攻击比γ”这个概念,从其数学的定义上来看,一句话里平均会攻击15%的字符。如果句子很短的话,也至少会选择攻击一个字符。对于攻击比例也加入了高斯噪声,带来了一定的随机性,实验证明带来了一定的积极影响。
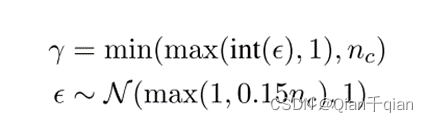
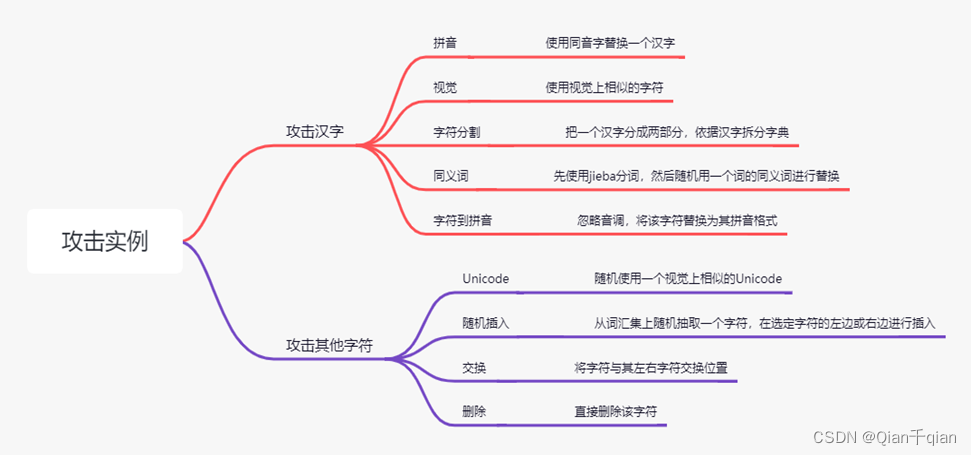
还可能进行组合攻击
字符攻击是一个连续的过程,把它抽象成下面的这种数学形式:
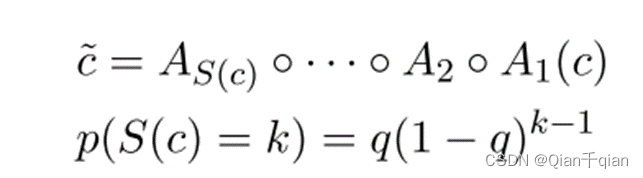
意味着对最后一步的输出应用新的攻击算法A。
每个步骤i,从适用于步骤i-1输出的所有算法中随机选择攻击算法Ai。从第一步开始。S©是应用于c的攻击步数,遵循指数衰减函数。根据经验设定q = 0.7。
对于“今天吃什么”,我们可以把选择的字符“吃”转换为拼音之后,再在字母表的层次上使用上述提到的攻击算法,这里的例子是将“chi”变成"ci”。
多模态对比预训练(数据准备好了,开始谈模型结构和训练方法)
Backbone:基于标准的Bert架构输入文本,并在第k层整合了语音和视觉特征。
特征表示
多模态!
特征一:语义特征。将一句话的每个字符,先按照Bert模型的输入形式,进行语义嵌入(也包括位置信息和句子片段信息),得到第一个特征Se©。
特征二:语音特征。对字符的语音进行编码,使用汉语拼音的形式,记作Ph©。
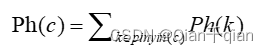
特征三:视觉特征。从其生成的中文宋体32 × \times × 32的图像中,使用ResNet18进行特征提取,定义为Vi©。

注:ResNet18也进行了一个对比学习的预训练。同样需要正样本和负样本!字符c的正样本是其视觉上的对抗性形式c˜= A ©. 这意味着从(visual, character split, unicode)三种视觉攻击算法中进行选择攻击方式。负样本是同一批处理中的所有其他字符。经过对比训练,ResNet模型就能够从图像中提取到有关相似性的信息。
思考:为什么要使用这种对比学习的方式进行训练?而不使用标准的训练方式?个人认为,标准的训练方式是为了提取图片本身的信息,也就是这个字的信息,而字的信息可以使用Se©进行表达,并且经过Bert训练,可以得到非常强大的词向量。因此,这里应该以相似性信息为主要提取目的进行提取,所以采用了对比学习的训练方式。
特征集成
最直接的方法是直接将三种特征进行拼接或者相加。问题:被给予相同的权重。另一种方法是双步编码,首先使用一个编码器决定权重,然后再输入到零一个编码器提取特征。问题:但这将减缓该系统的运行速度。
本文提出了一种轻量级融合层插入方法,它只在编码器的一个层中插入多模态特征。设Hk (i) 表示第k层中第i个单词的表示,我们插入:
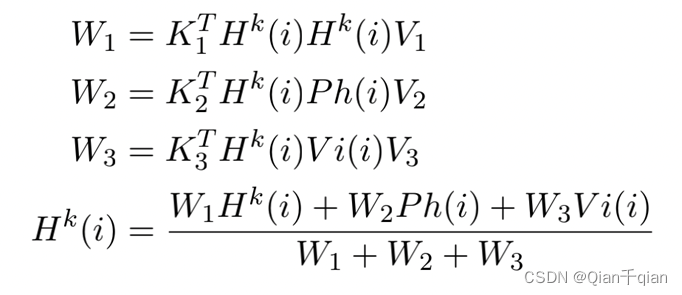
其中,Ph (i)和Vi (i)是语音和视觉表示形式,Kj/Vj是可学习的矩阵。直观地说,使用了第0到k-1层学到了一定的上下文语义,并用该上下文语义去确定权重。并使用其余层进行进一步的句子表示学习。
损失函数(训练方法)
模型损失有两个组成部分:对比学习损失和标准掩码语言模型(MLM)损失。
对比学习:对于相似的(正)样本,表示空间应该更近,而对于不同的(负)样本,表示空间应该更近。对于每个句子,我们将它的对抗性形式视为正样本,而将同一批句子中的所有其他句子视为负。给定一批有N个句子,第i个句子的损失si 是 :
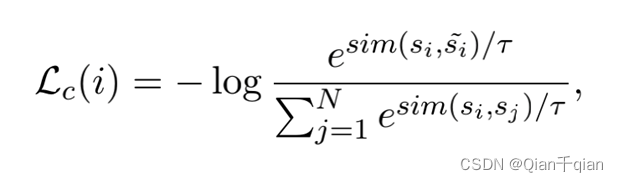
其中,τ是一个超参数,而s˜i是从si中合成的对抗性样例。我们根据试点实验设置了τ = 0.01(这里设置一个超参数,个人认为是为了加大这种差距。)。将sim(si,s~i)定义为:hi 和hi~空间的余弦相似度.
整个的结构图
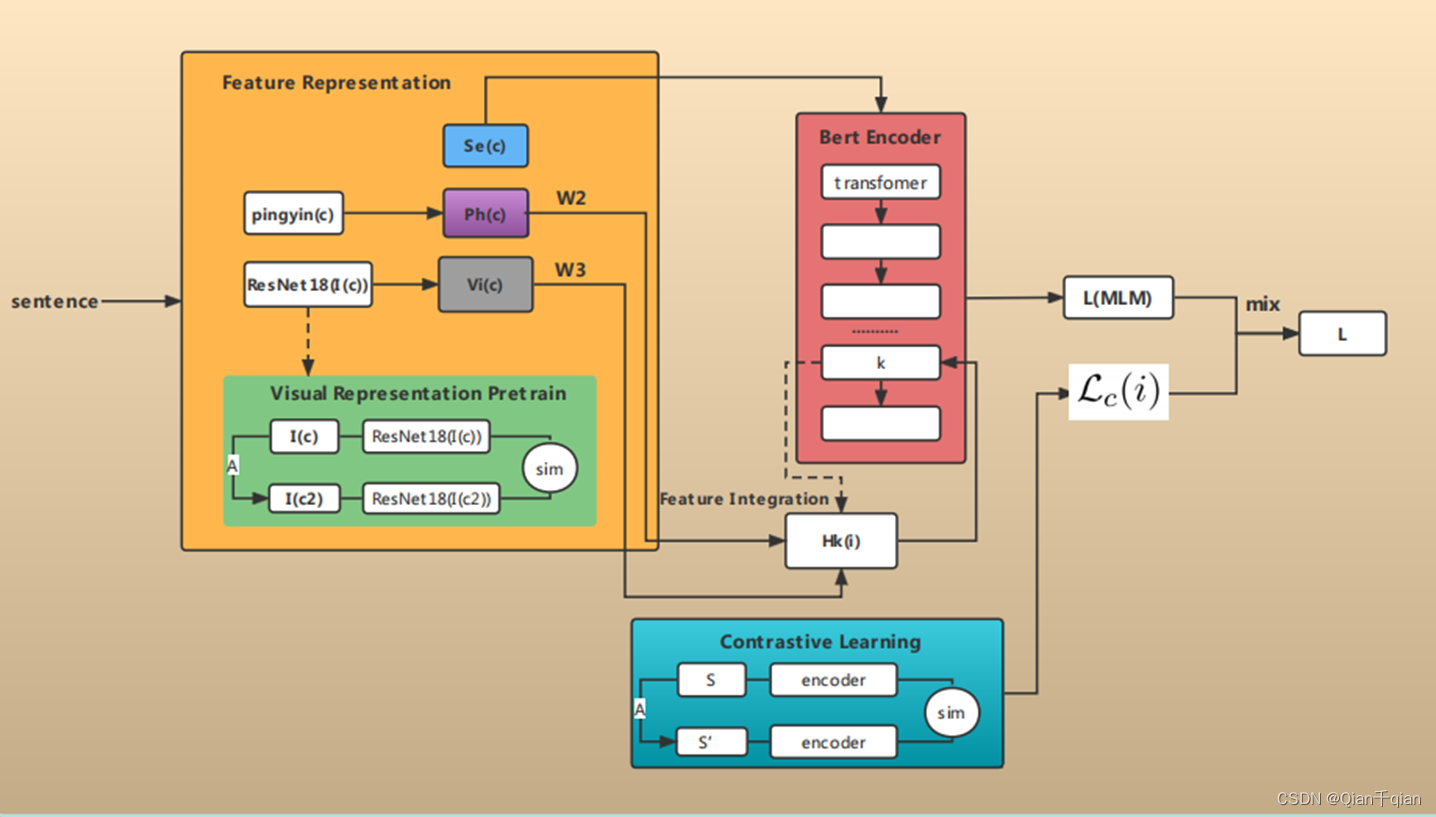
注:该图是我根据对论文的理解,自己画的一张图,仅供参考。
实验和结论
实验
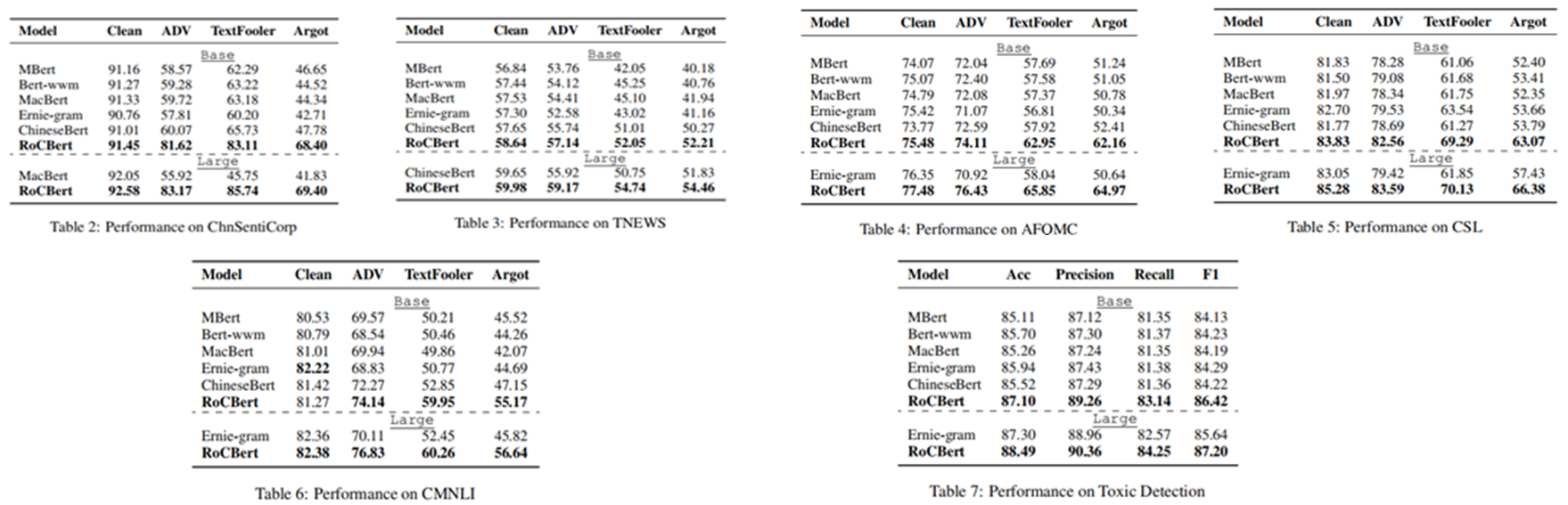
基线模型包括MBert-Chinese、Bert-wwm、MacBert、Ernie-gram和ChineseBert。测试阶段的NLU任务包括中文情绪分类、新闻标题分类、问题匹配、论文关键词识别和中文多类型自然语言推理;不良内容检测任务的数据收集于在线对话平台,是用户针对垃圾广告、色情和滥用信息进行人为攻击的文本。模型性能的测试包括三种对抗性算法:ADV、TextFooler和Argot。
在六种任务上的表现见表2-7。可以看出RoCBERT在所有使用攻击算法的NLU任务上表现最好,且在未使用攻击算法的4中NLU任务上由于基线模型。此外,ChineseBert的表现次之,作者认为原因是其预训练过程中也考虑了多模态特征,这进一步证明了多模态特征在中文预训练中的重要性。在有毒内容检测任务上,RoCBERT在所有指标上表现最佳,说明了模型能够不受对抗形式的干扰,有效地捕获了真正语义。
结论
通过结合对比学习和MLM任务,RoCBert模型可以在对抗性攻击下具有鲁棒性,而不影响在干净数据上的表现。此外,基于字符的分词在对抗性攻击下也会更健壮。
关于多模态特征,对视觉特征的预训练是必要的,可以学习到有意义的视觉特征。语音特征不如视觉特征重要,但也带来了积极的改善。这些多模态特性更早的插入有助于模型深入整合这些特性。然而,在第0层插入它们也更糟糕,因为模型只能从词袋中学习多模态特征之间的权重。
在攻击算法上,15%的攻击比率是预训练的最佳点。并且在攻击比率的计算中(公式1)添加的高斯噪声也带来了一致的积极影响,表明不应该在预训练阶段使用固定的攻击比率。