文章目录
概述
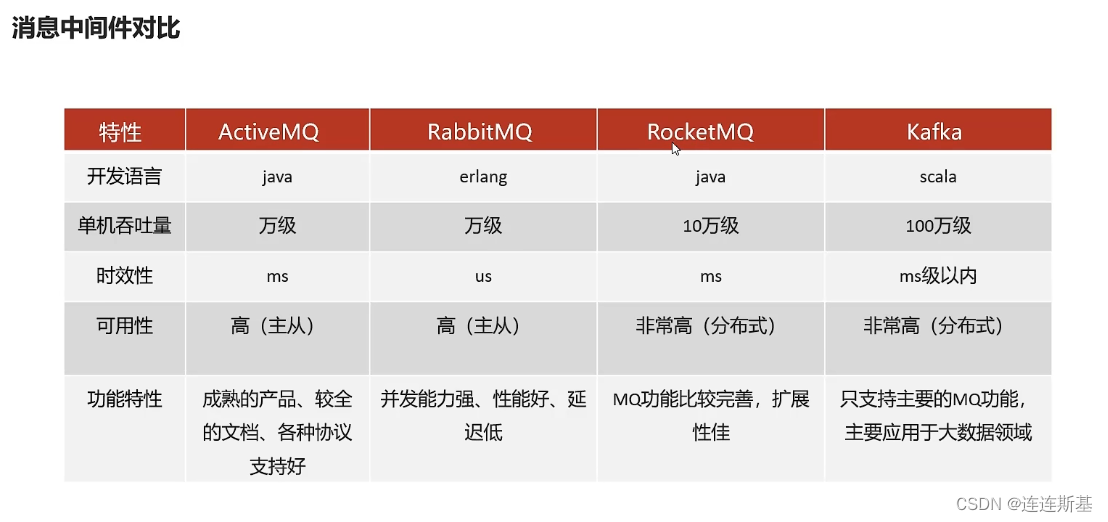

核心概念
Kafka将生产者发布的消息发布到topic中,需要这些消息的消费者可以订阅这些主题。
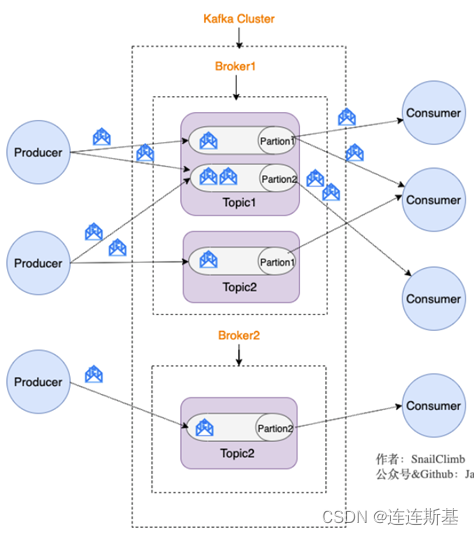
下面这张图也为我们引出了,Kafka 比较重要的几个概念:
-
Producer(生产者) : 产生消息的一方。
-
Consumer(消费者) : 消费消息的一方。
-
Broker(代理 / 单个kafka实例):可以看作是一个独立的Kafka实例。
- 多个Kafka Broker组成一个Kafka Cluster。
- 每个 Broker 中又包含了 Topic 以及 Partition这两个重要的概念
-
Topic(主题) : Producer将消息发送到特定的主题,Consumer通过订阅特定的 Topic(主题) 来消费消息。
-
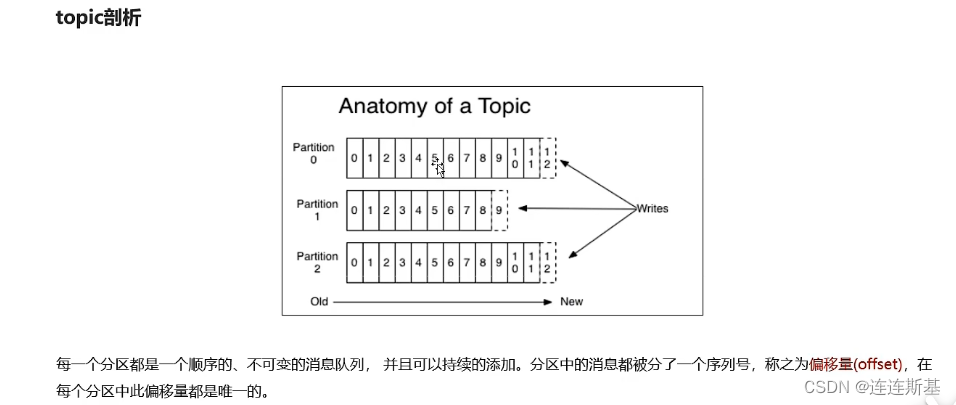
Partition(分区 / 队列) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker
划重点:Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列。 -
消费者组:同一个消费者组中,多个消费者订阅同一个topic,只有一个消费者可以接收到消息。
生产者
示例
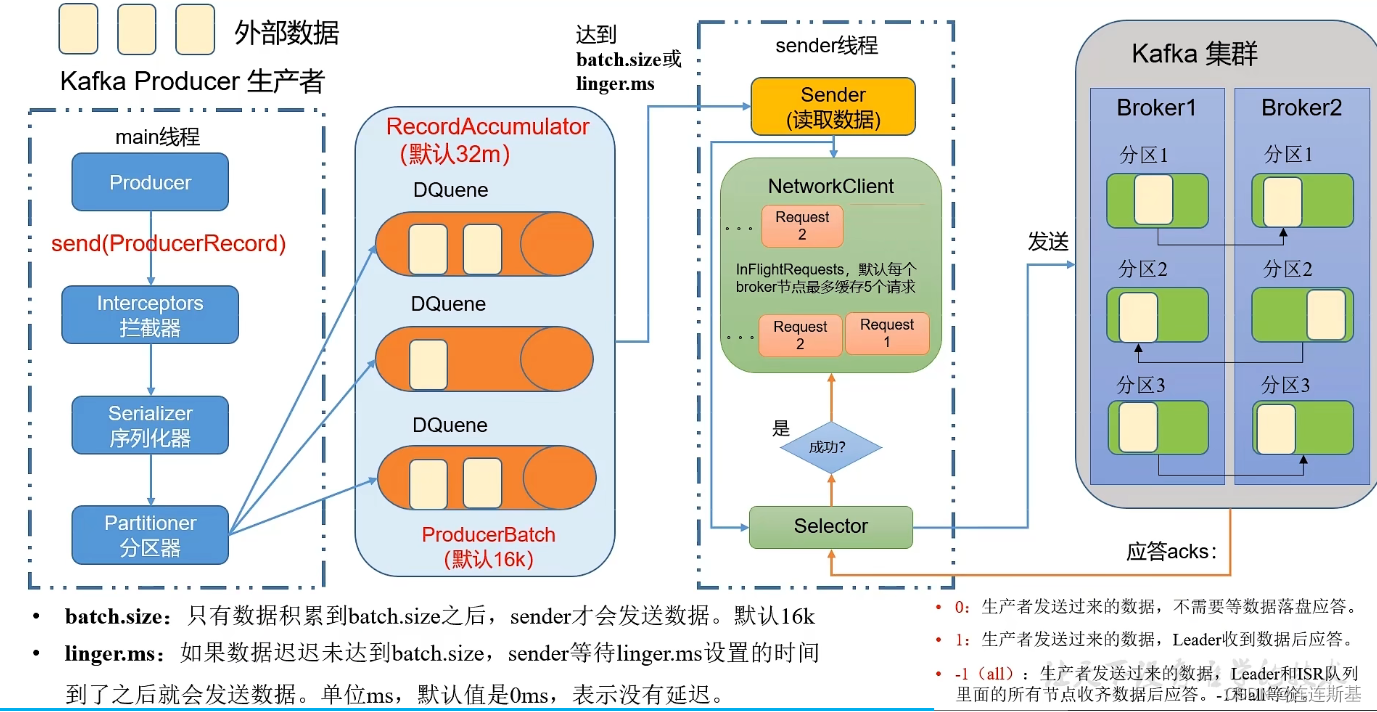
发送流程
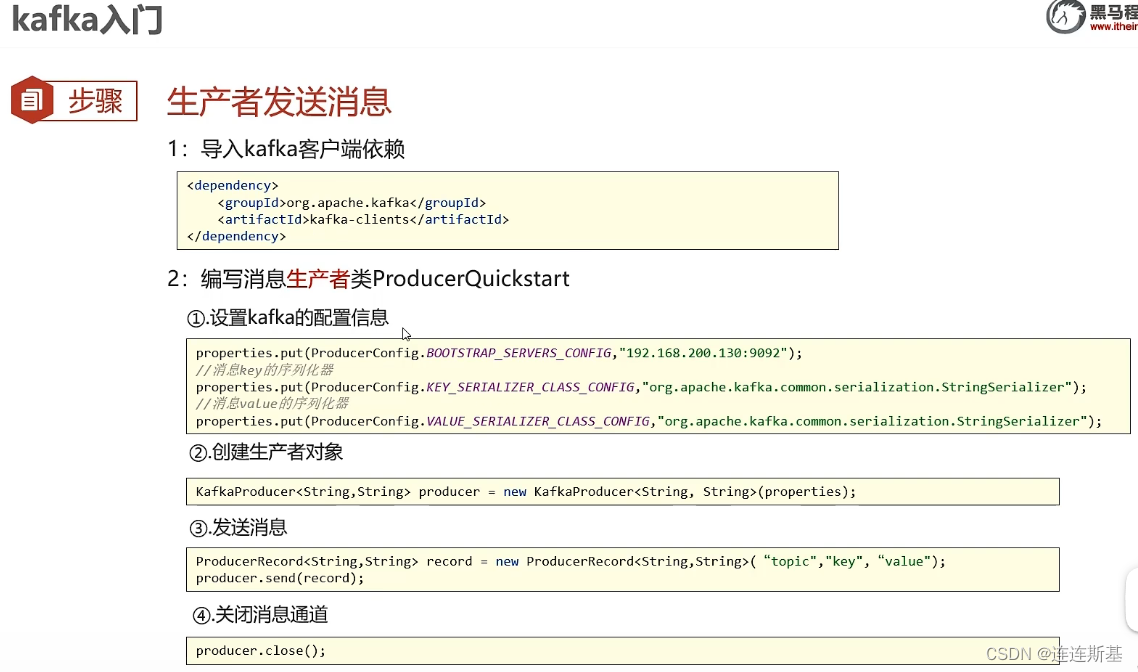
- 生产端使用
kafkaProducer发送消息,消息依次经过:拦截器、序列化器和kafka分区器,被存放在记录累计区Record Accumulator。 - Kafka 生产者并不会立即将每条消息都发送到 Kafka 集群,而是会将一批消息放入
Record Accumulator中的双端队列进行累积,然后一起发送,以减少网络开销和提高性能。Record Accumulator涉及两个参数的配置:- batch.size:只有双端队列中的消息数达到batch size,才会调用sender线程批量发出消息。
- linger.ms:如果数据量迟迟未达到batch.size,当超过linger.ms设置的时间(单位:ms)就会发送数据,默认值为0,表示没有延迟。
- sender线程将发往同一个broke的消息构成发送请求序列,如果broke没有应答的情况下,最多缓存5个请求实例。
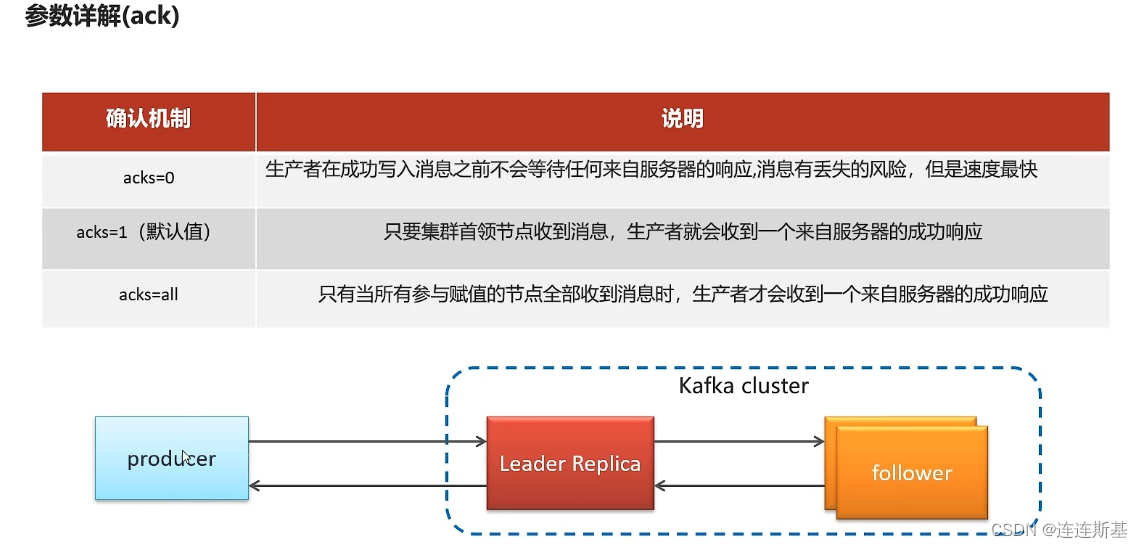
- 发送请求的ack确认机制:
- ack=0:broker接收到消息即应答
- ack=1:broker接收到消息,并且leader备份落盘了应答
- ack=2,:broker接收到消息,并且leader备份和ISR(需要同步备份保存的节点)都落盘后才应答。
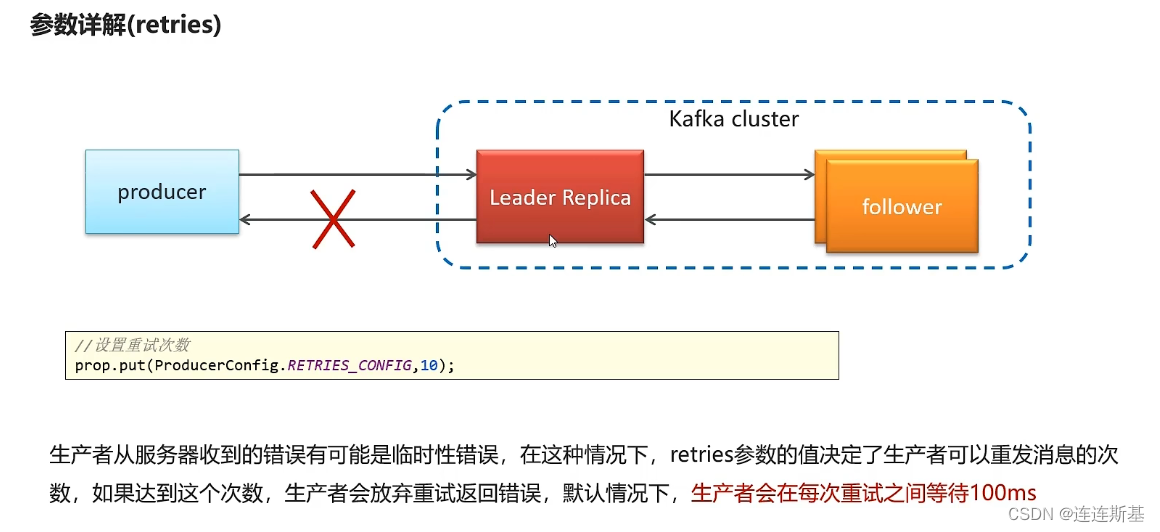
- 如果发送请求失败,会进行重试,如果超出retry设置的次数还未收到broker的ack应答,则放弃重试返回错误。
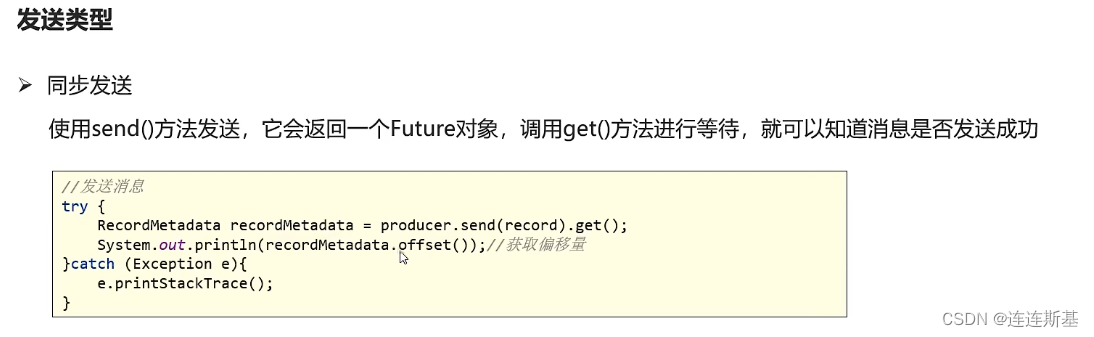
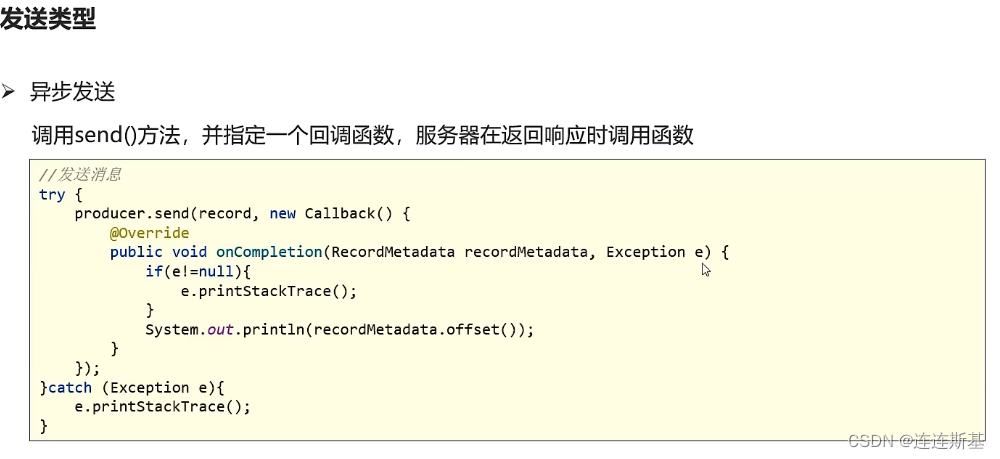
同步 / 异步发送消息
生产者参数配置
ack-确认机制
retries - 重试次数
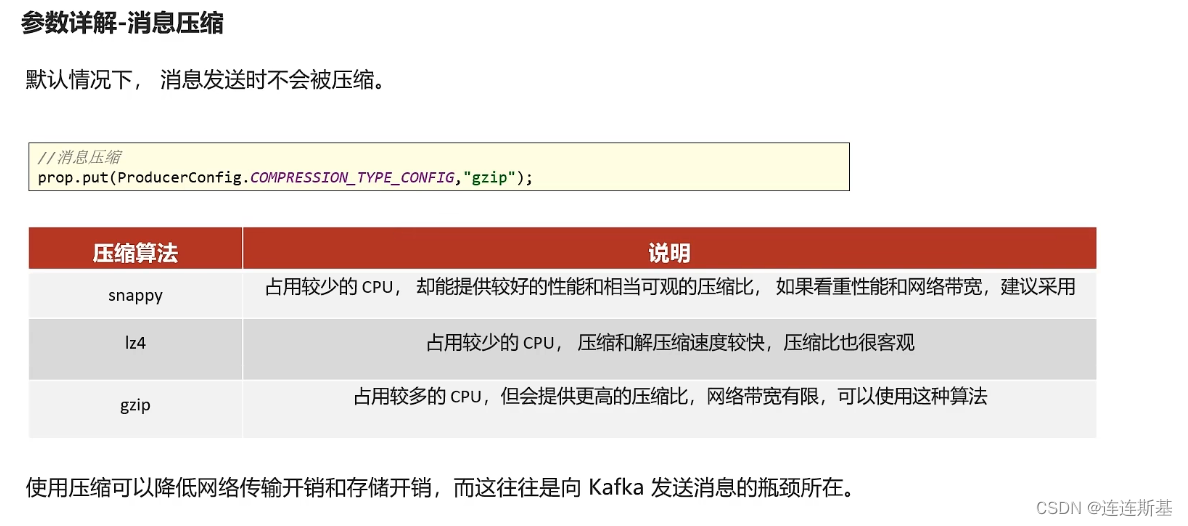
compression_type - 消息压缩类型
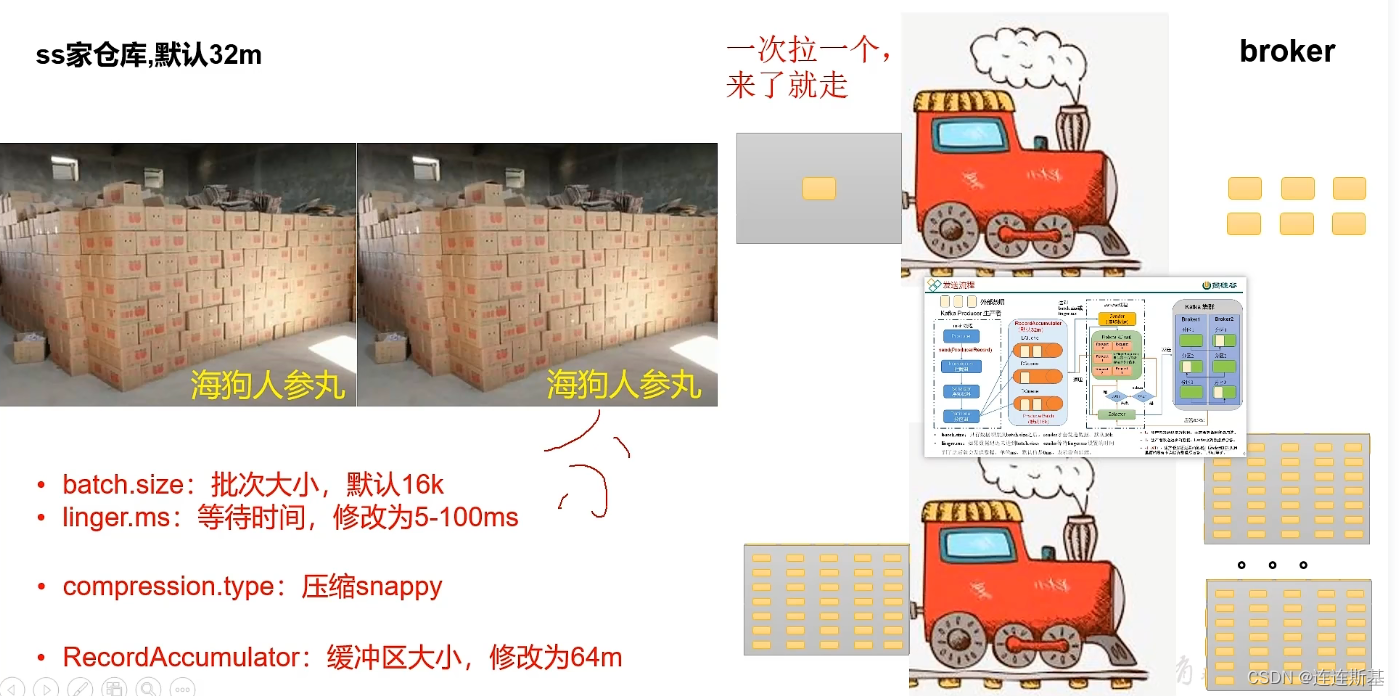
生产经验问题
提高吞吐量
- 增大
batch.size,配合延长一些等待时间linger.ms - 指定
compression.type将消息进行压缩 - 适当增大
RecordAccumulator,积压缓冲区大小。
数据可靠性
数据可靠性由ack应答机制保障:
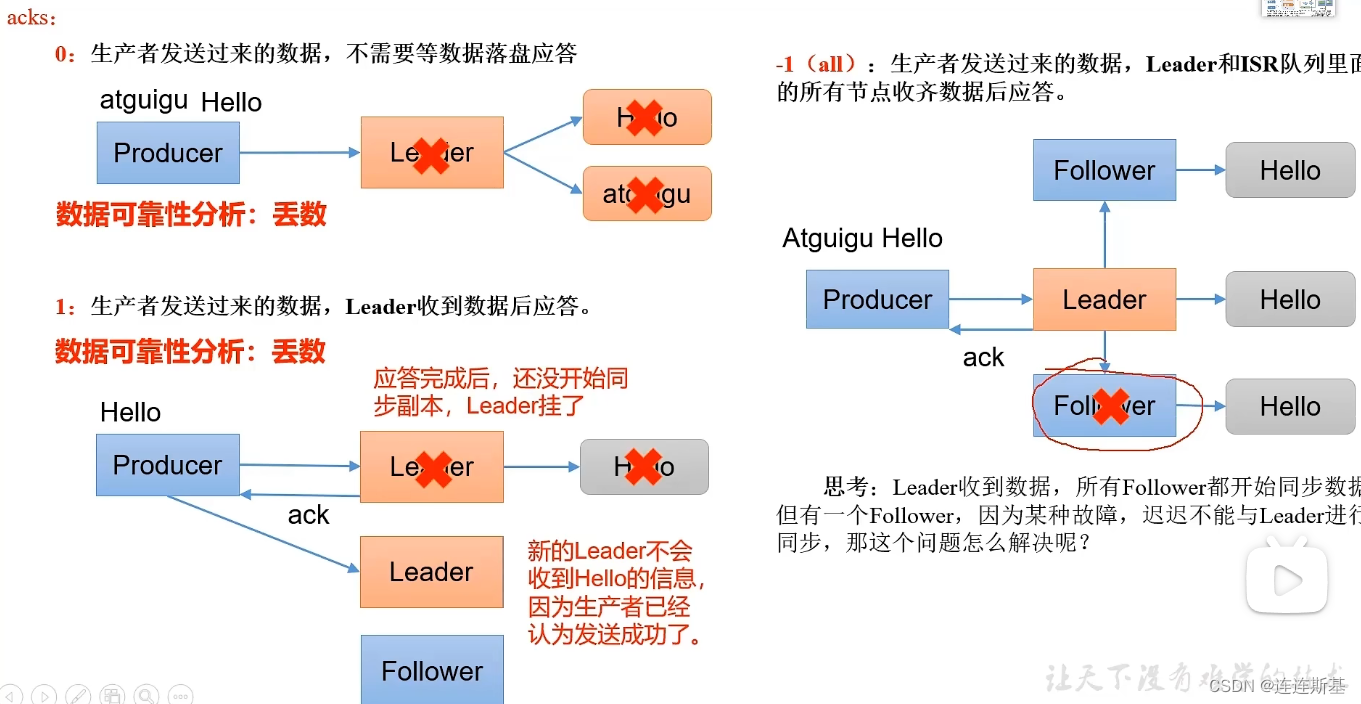
当ACK设置为all时,需要保障leader备份和ISR备份都落盘才应答,如果期间某个ISR节点出现故障呢?
长期未向leader发送同步通信请求或同步数据,将被提出ISR,该时间阈值由replica.lag.time.max.ms参数设定,默认为30s

数据重复-幂等性与事务
幂等性
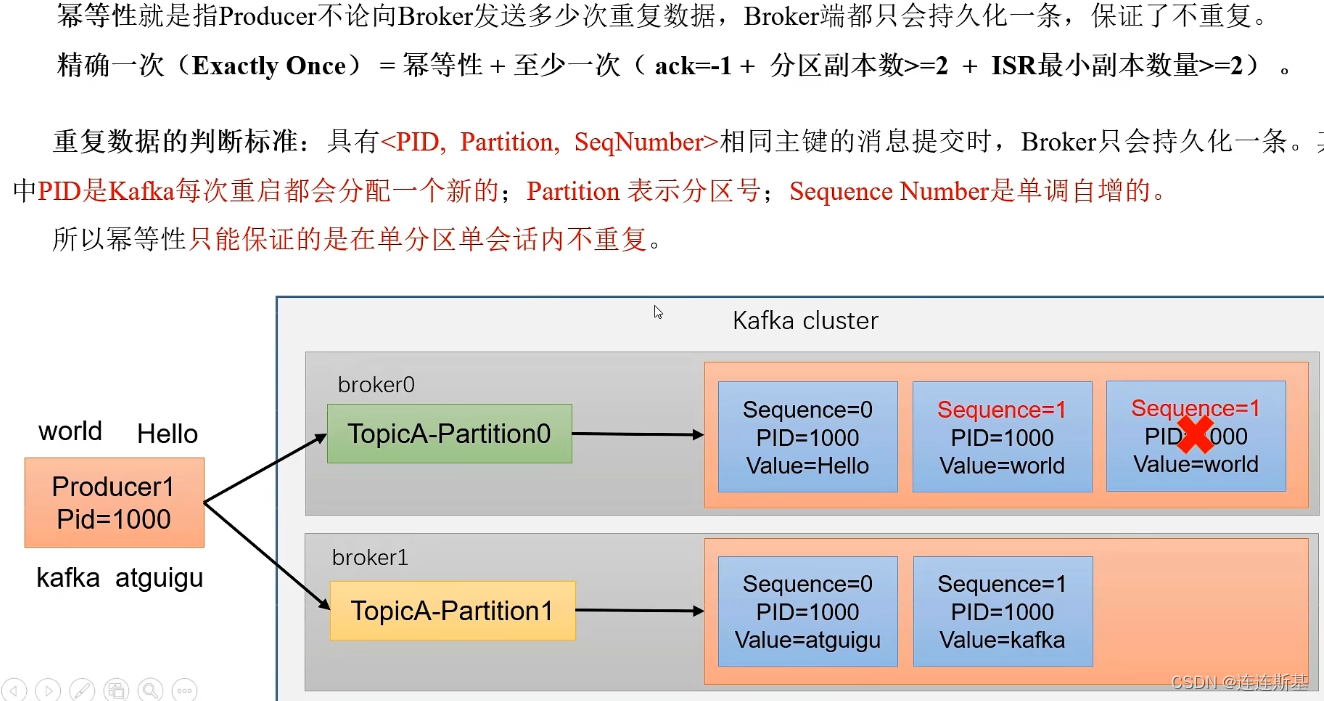
幂等性就是指Producer不论向Broker发送多少重复数据,Broker端都只会持久化一条,保证了不重复。
几个概念:
- PID(producer ID):生产者id,kafka每次重启都会分配一个新的
- Partition:分区号
- Sequence Number:单调递增的序列号
重复数据的判断标准:具有< PID, Partition, SeqNumber > 相同主键的消息提交时,Broker只会持久化一条!幂等性只能保证单分区、单会话内不重复。
如何使用幂等性:开启参数 enable.idempotence 默认为true,false关闭
生产者事务
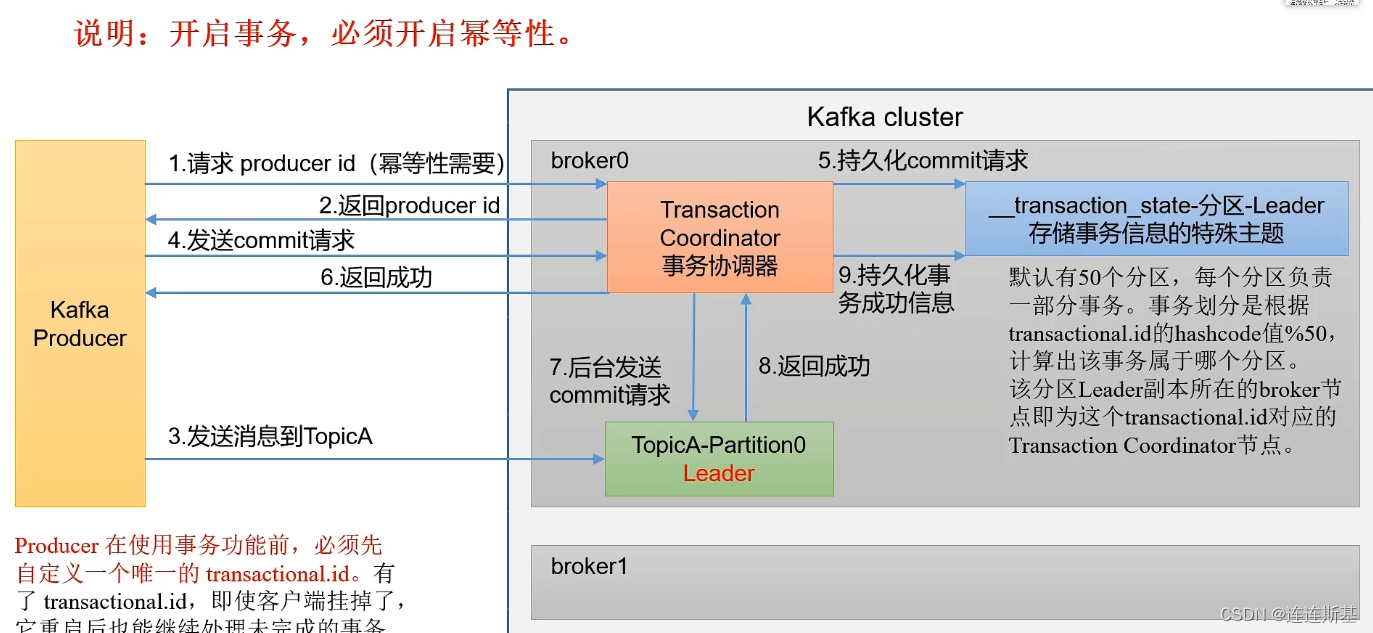
幂等性只能保证单分区单会话时,消息不重复,一旦kafka挂掉,还是有可能产生重复数据,这时就需要用到生产者事务。
开启事务,必须开启幂等性!
数据有序

- 单分区内,因为broker是按序接收的,所有自然保证有序。
- 多分区,分区与分区之间无序,如果要保证有序,需要在消费端维护一个有序的窗口,按序接收,滑动。
分区机制
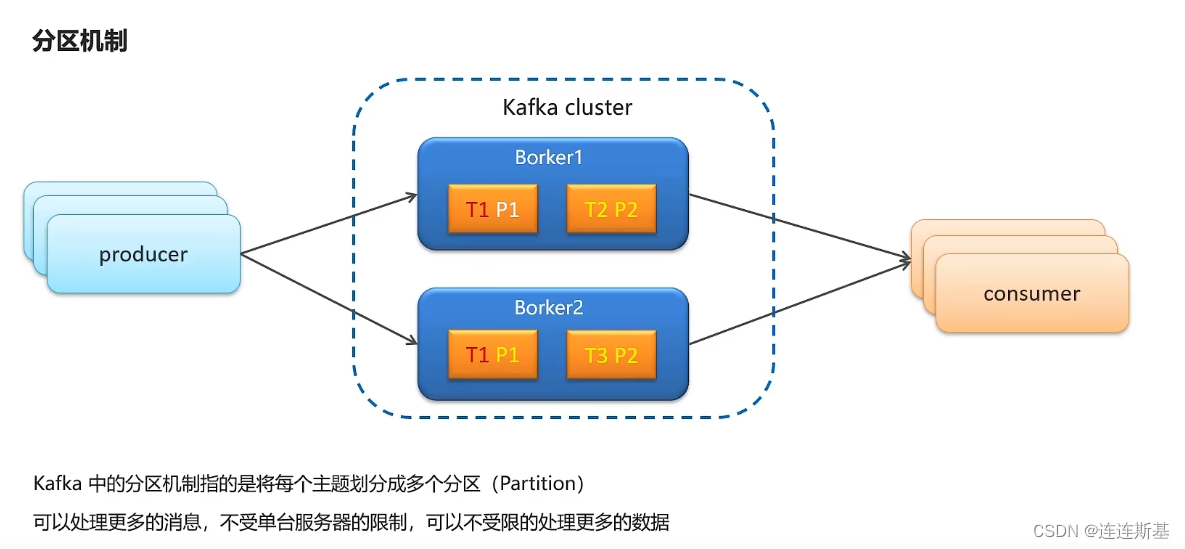
kafka分区机制,允许消息存放在不同broke的不同分区上。
分区策略
默认是轮询。
自定义分区器
第一步:自定义 partitioner实现Partitioner接口。
第二步:重写分区规则函数 partition。
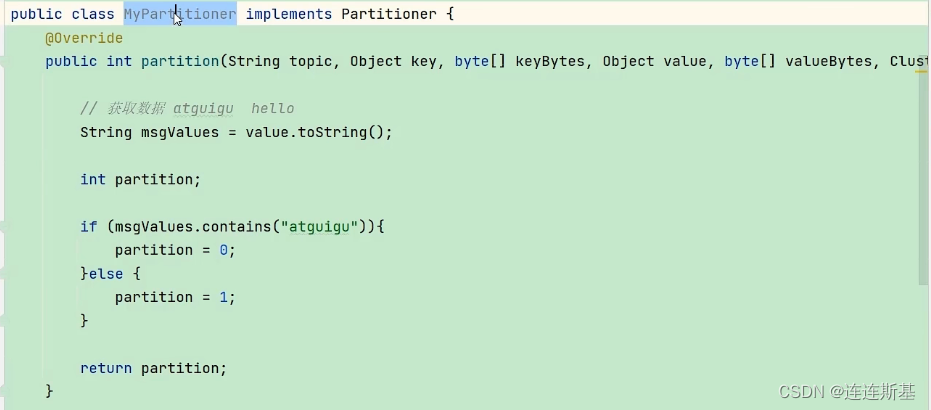
第三步:在设置生产者配置时关联自定义分区器。

Broker
消费者
消费示例
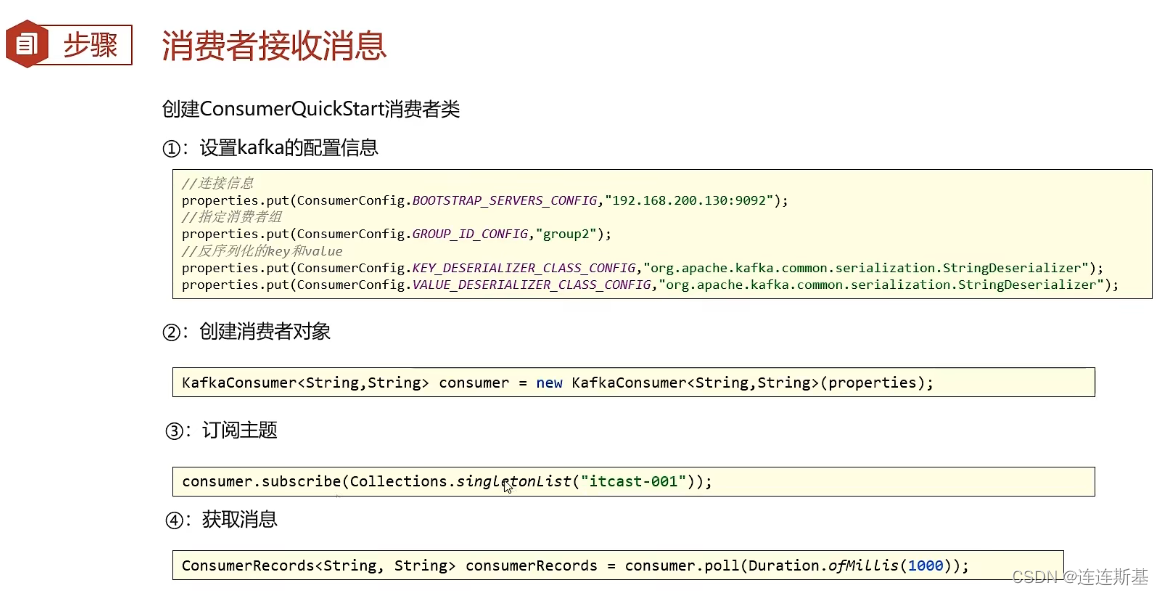
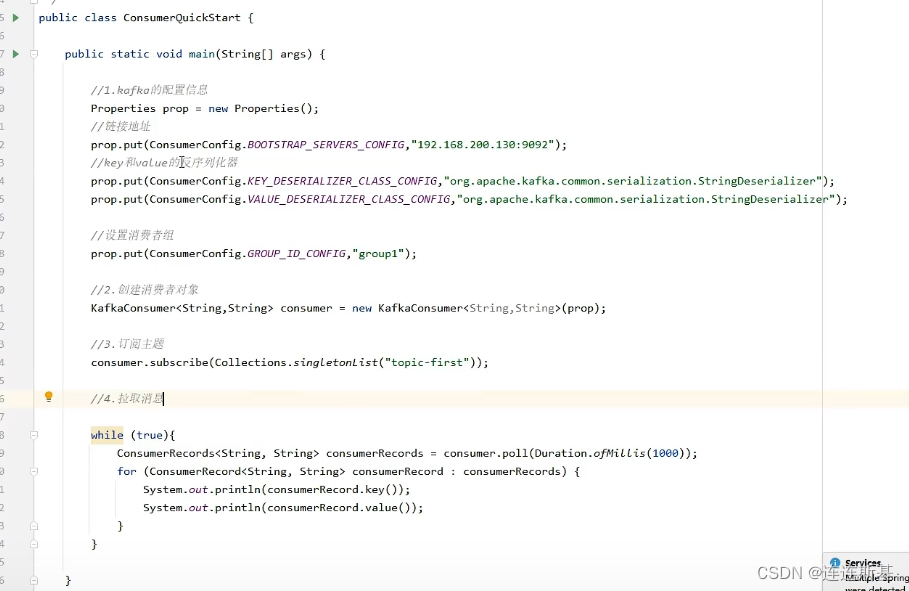
消费者组

消费方式
kafka采用从broke中主动拉取数据。
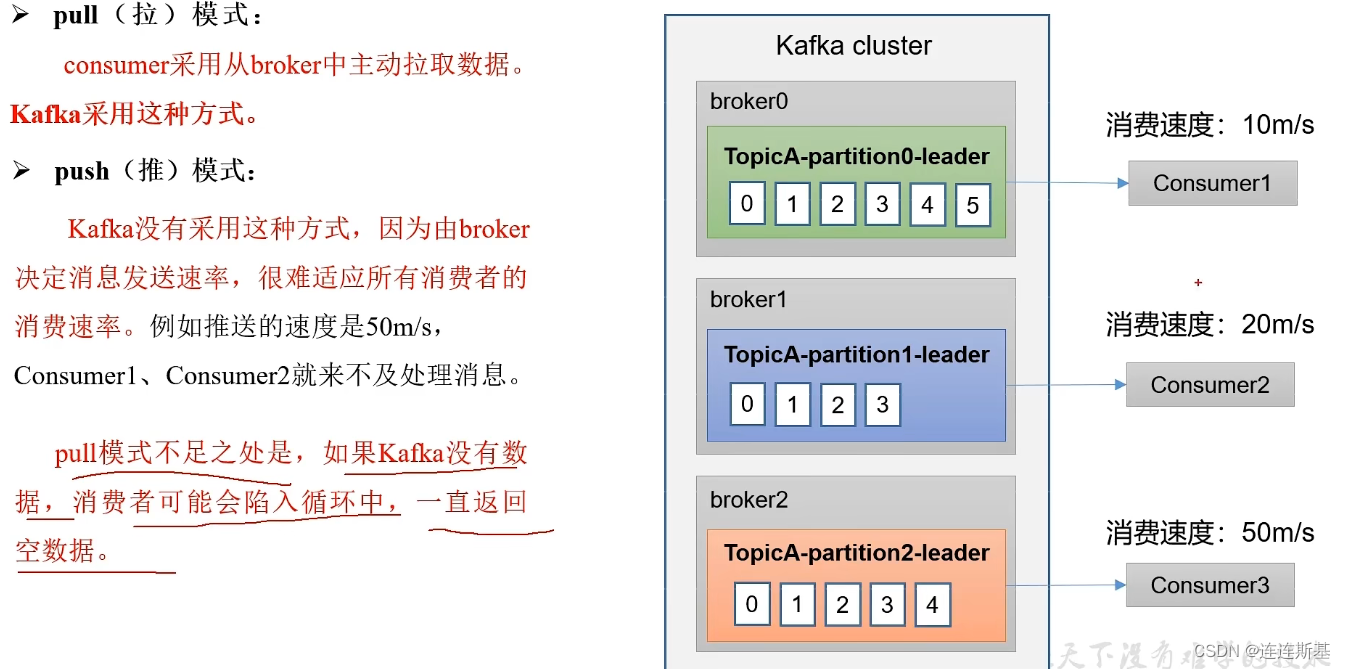
消费流程
- 消费者采用pull(拉)的方式从partition中获取消息,同一个消费者组中的消息只能有一个去拉取同一partition中的消息。
- 消费者消费完毕消息后,会回复一个offset偏移量,到broker的
_consumer_offsets主题,记录消费端消费的位置,便于在消费端宕机重启时恢复。
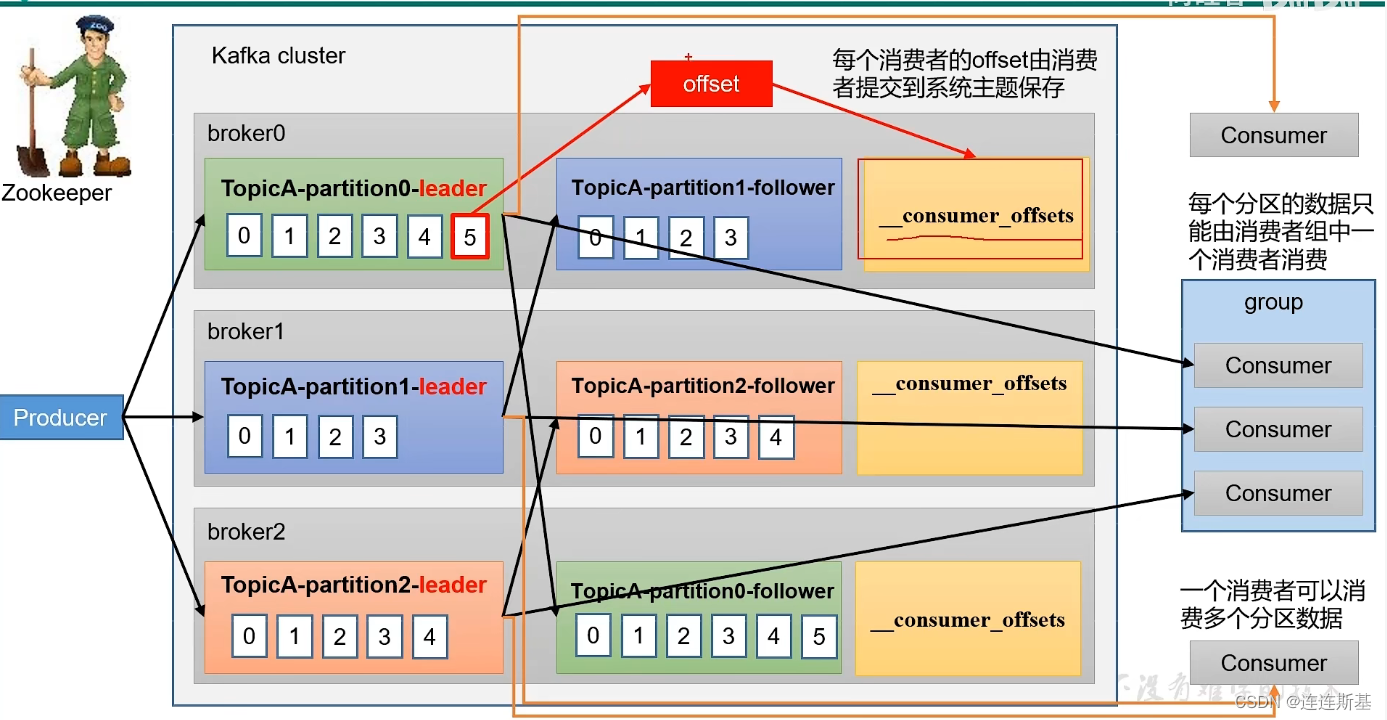
提交和偏移量
消费者在消费消息时,可以追踪消息再分区的位置(偏移量),并自动向一个叫做_consumer_offset的特殊topic发送消息,包含了分区的偏移量。
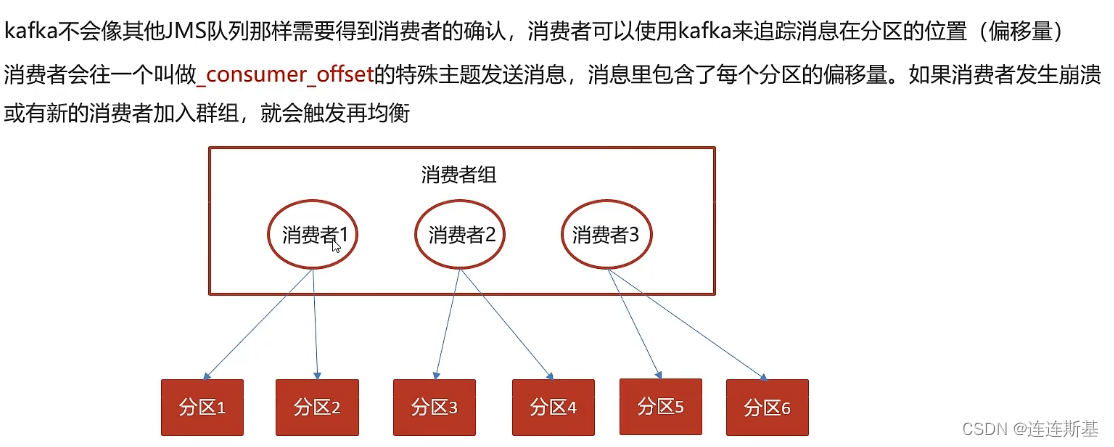
如果消费者发送崩溃或者有新的消费者加入群组,会触发再平衡。例如消费者2挂掉了,那么分区3和分区4将被再平衡机制,指向到其他消费者。
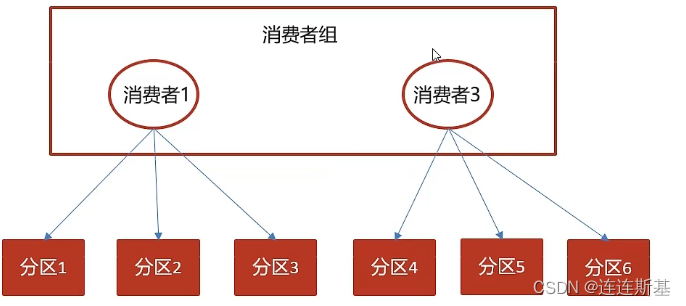
在自动提交偏移量模式下,再平衡机制可能会引发问题,因为挂掉的消费者提交的消息偏移量与新指定的消费者正在处理的消息偏移量是不一致的。
提交偏移量小于正在处理的偏移量:
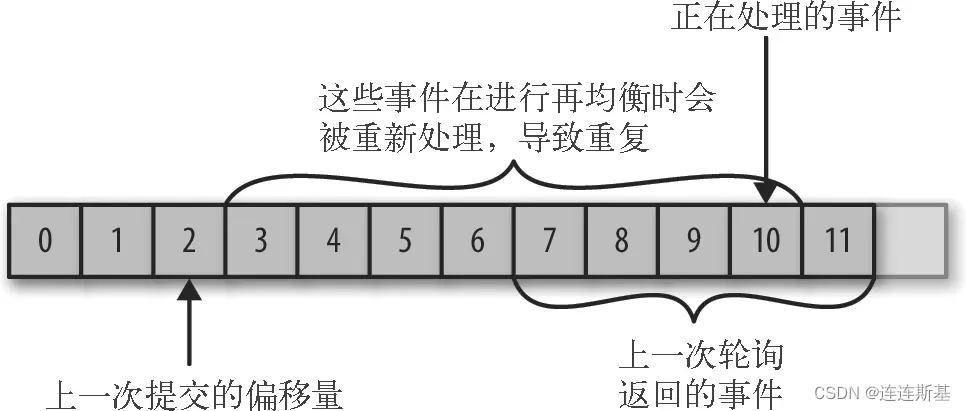
如果提交的偏移量小于正在处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
提交偏移量大于正在处理的偏移量:
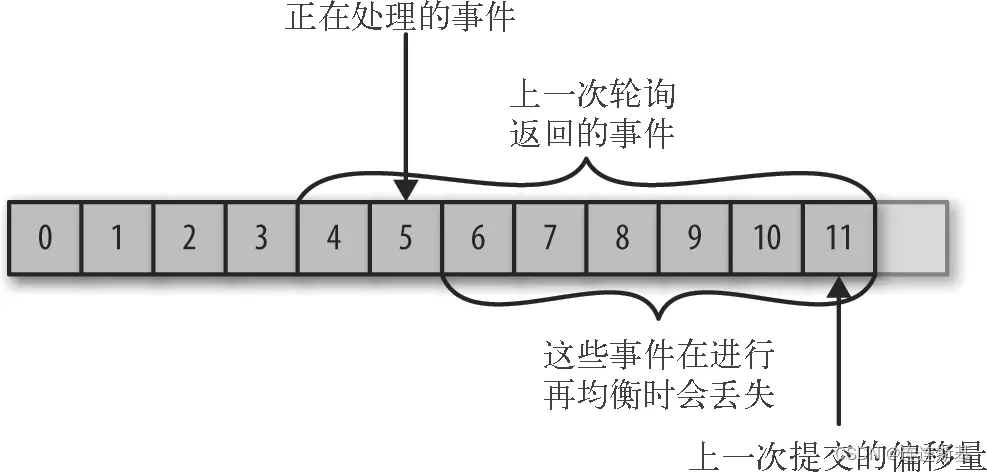
如果提交的偏移量大于正在处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
偏移量提交方式

手动提交
首先将自动提交设置为false:

同步提交
使用 commitSync() 提交偏移量最简单也最可靠。这个 API 会提交由 poll() 方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。
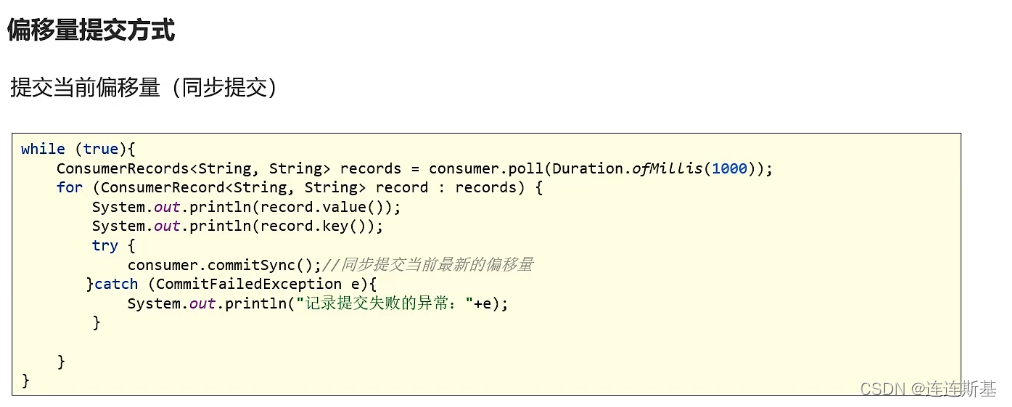
commitSync() 将会提交由 poll() 返回的最新偏移量,所以在处理完所有记录后要确保调用了 commitSync(),否则还是会有丢失消息的风险。
如果发生了再均衡,从最近一批消息到发生再均衡之间的所有消息都将被重复处理。
同时在这个程序中,只要没有发生不可恢复的错误,commitSync() 方法会一直尝试直至提交成功。如果提交失败,我们也只能把异常记录到错误日志里。
异步提交
同步提交有一个不足之处,在 broker 对提交请求作出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。我们可以通过降低提交频率来提升吞吐量,但如果发生了再均衡,会增加重复消息的数量。 这个时候可以使用异步提交 API。我们只管发送提交请求,无需等待 broker 的响应。

在成功提交或碰到无法恢复的错误之前,commitSync() 会一直重试,但是 commitAsync() 不会,这也是 commitAsync() 不好的一个地方。 它之所以不进行重试,是因为在它收到服务器响应的时候,可能有一个更大的偏移量已经提交成功。假设我们发出一个请求用于提交偏移量 2000,这个时候发生了短暂的通信问题,服务器收不到请求,自然也不会作出任何响应。与此同时,我们处理了另外一批消息,并成功提交了偏移量 3000。如果 commitAsync() 重新尝试提交偏移量 2000,它有可能在偏移量 3000 之后提交成功。这个时候如果发生再均衡,就会出现重复消息。 commitAsync() 也支持回调,在 broker 作出响应时会执行回调。回调经常被用于记录提交错误或生成度量指标。如果要用它来进行重试,则一定要注意提交的顺序。
同步和异步混合提交
一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。 但如果这是发生在关闭消费者或再均衡前的最后一次提交,就要确保能够提交成功。因此在这种情况下,我们应该考虑使用混合提交的方法:

高可用设计
集群
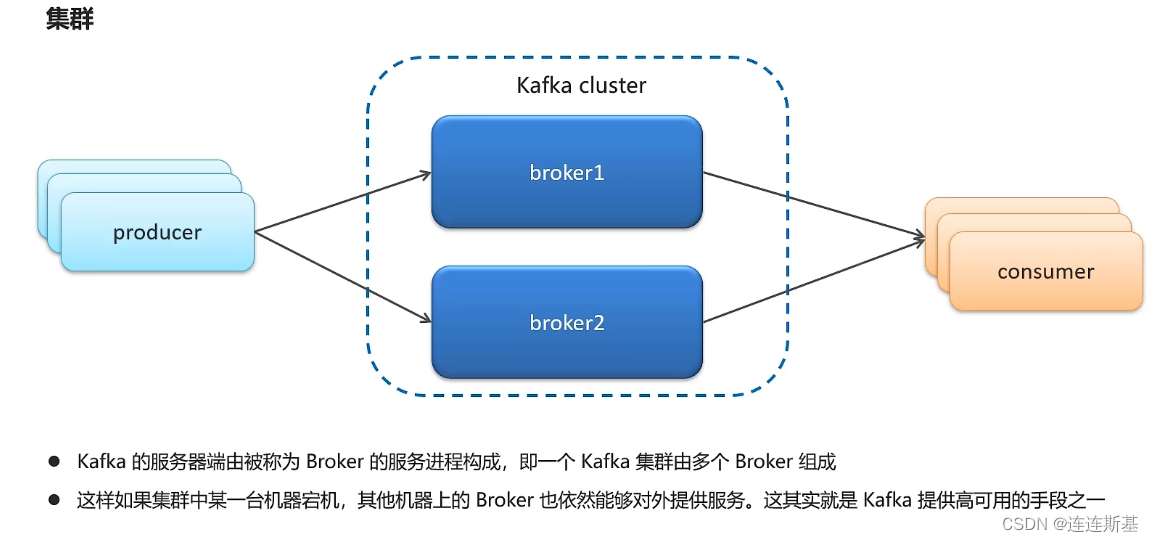
- 集群方式(cluster),一个kafka集群由多个broke组成,一个broke宕机,其他机器上的broke依然可以对外服务。
备份
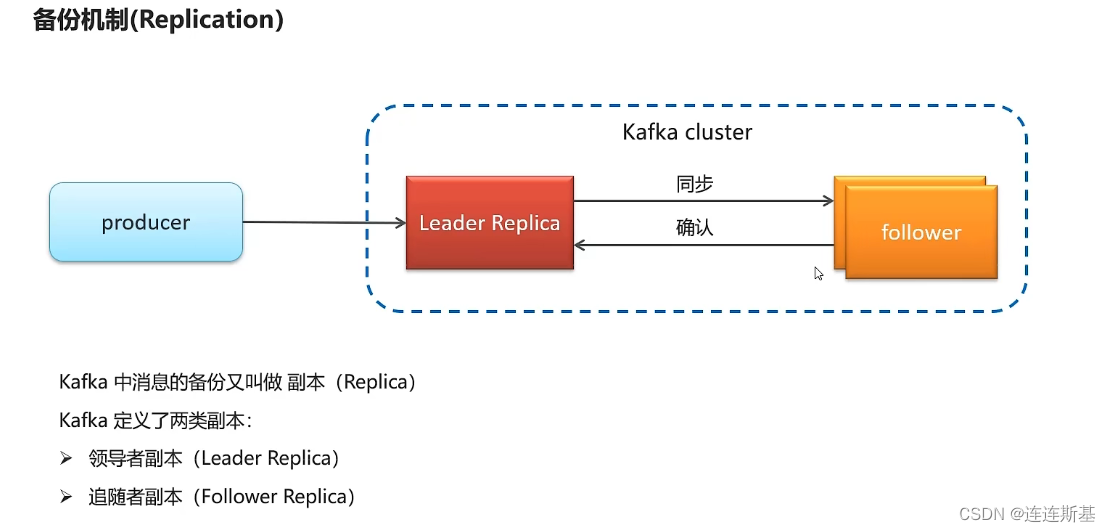
- 备份机制(replication):kafka中为了保证消息的安全性,将信息进行了备份,并且定义了两类副本:
- 领导者副本:生产者首先将消息发送到领导者副本进行备份,领导者副本只有一个。
- 追随者副本 :领导者副本,将自己的消息与追随者副本进行同步。追随者副本可以有多个,且可以分为两类:
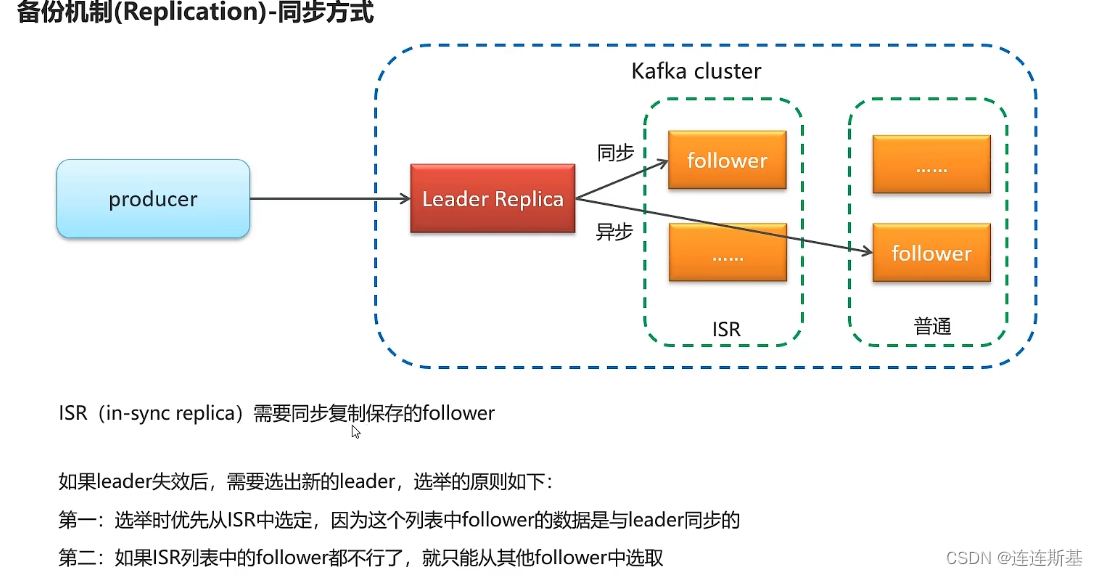
- ISR(in - sync replica):需要同步复制保存的follower。
- 普通: 与领导者副本之间是异步保存。
- 当leader失效后,需要选出新的leader,选举原则如下:
- 优先从ISR中选择,因为ISR中的消息数据是与leader同步的
- 如果ISR列表中的follower都不行了,就只能从其他follow中选取。
- 极端情况:所有副本都失效了,这时有两种方案:
- 等待ISR中的一个活过来,选为leader,数据可靠,但是时间不确定。
- 选择第一个活过来的副本为leader,不一定位ISR中的, 以最快速度恢复可用性,但是数据不一定完整。
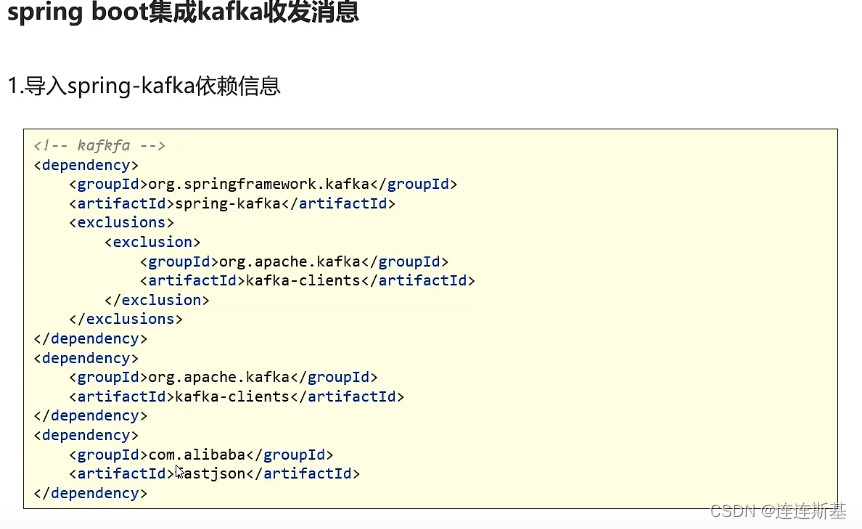
SpringBoot集成Kafka
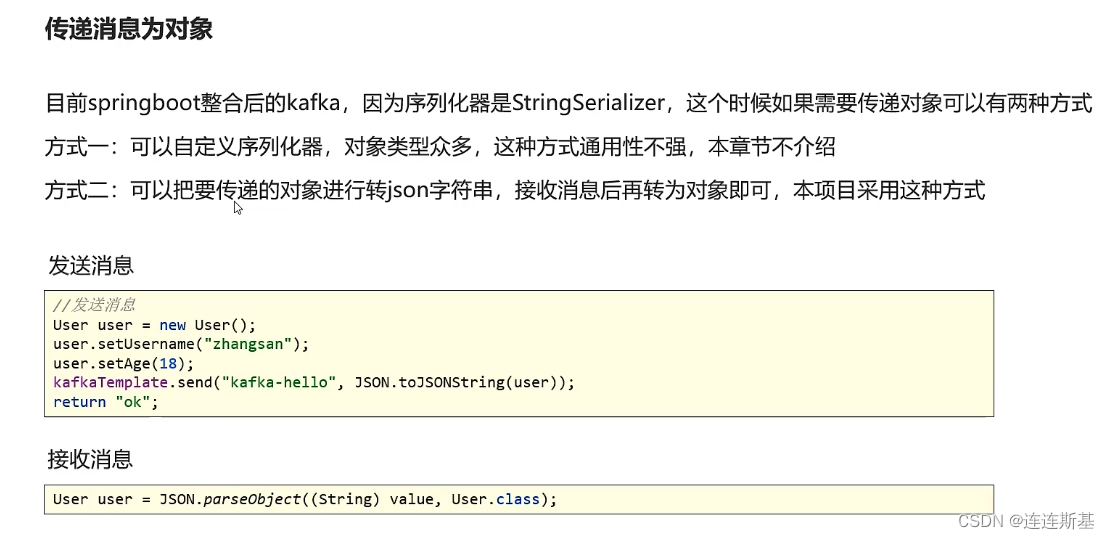
基本使用

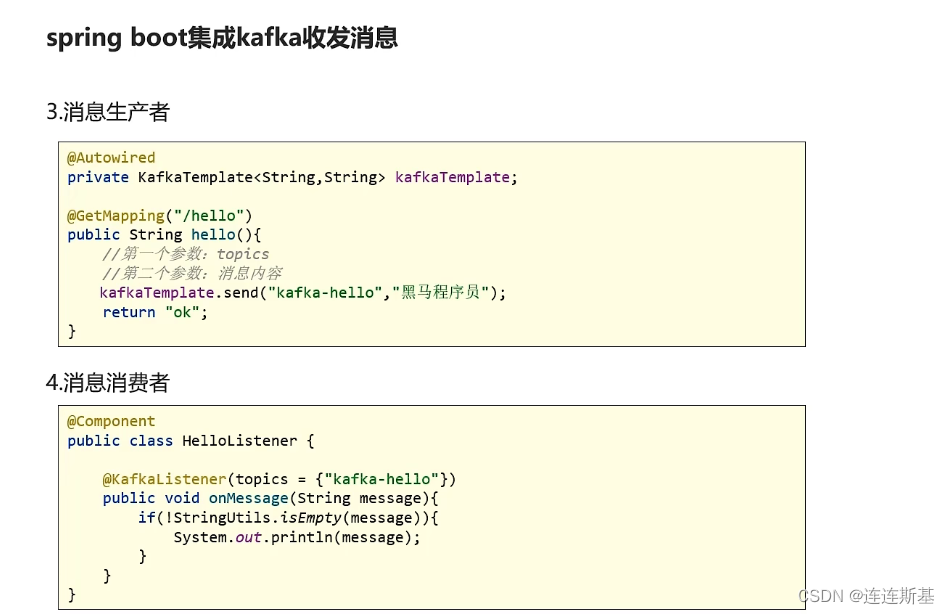
传递对象消息