一、kafka简介
Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
二、什么是kafka
1.Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。 能够轻松实现高吞吐、可扩展、高可用,并且部署简单快速、开发接口丰富,各大互联网公司已经在生产环境中广泛使用,目前已经有很多分布式处理系统支持使用Kafka,比如,Spark、Strom、Flume等。
2.kafka是用于构建实时数据管道和流媒体应用。它是水平扩展的,容错的,快速的。
3.在流式计算中,Kafka一般用来缓存数据,spark streaming通过消费Kafka的数据进行计算。
三、简单介绍一下JMS协议
1.JMS是什么:JMS是java提供的一套技术规范
2.JMS干什么用:用来异构系统,集成通信,缓解系统瓶颈,提高系统的伸缩性,增强系统用户体验,使得系统模块化和组件变化得可行并更加灵活。
3.JMS通过什么方式:
生产消费者模式(生产者,服务器,消费者)

4.JMS消息传输模型
1.点对点模式(一对一,消费者主动拉去数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。

这个模型的特点是发送队列的消息被一个且只有一个接收者处理,即使有多个消息监听者也是如此。

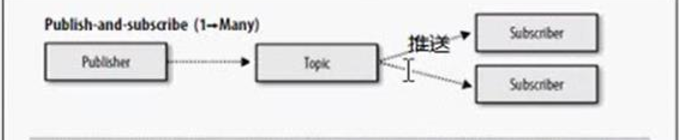
2.发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只是在主动监听主题(topic)时才接受消息,而持久订阅者则监听topic的所有消息,即使当前订阅者不可用,处于离线状态。
四、kafka消息队列
1.可以用来系统解耦、削峰填谷、定时任务、异步通知等等
2.消息队列是在JMS基础上开发出来的,它没有queue队列,和JMS一样有topic,consumer有组。
3.每一个topic可以被每一个consumer group的一个counsermer消费。
举例:即如果有两个组A B ,其中A组中有 a1consumer a2consumer a3consumer,B组中有b1consumer b2consumer b3consumer, 那么A组中任意某一个consumer消费了topic的一个分区,A组的其他consumer不能再消费此topic的分区。B组同理如果想让a1 a2 a3 b1 b2 b3都消费主题,可以分别给它们单独设组。

图中名词解释:
1.Topic:主题,kafka中同一种类型数据集的名称,相当于数据库中的表,productor将同一类型的数据写入同 一个topic下,consumer从同一个topic消费同一类型的数据。逻辑上同一个数据集只有一个topic,如果设置一个topic有多个partition和多个replication,在物理上同一个topic下的数据集会被分成多份 存储到不同的物理机上。
2.Producer:消息生产者,负责向kafka中发布消息。列如图中有Producer1,Producer2都是生产者,生产者不断生产数据(如以flume方式采集的),生产的数据以topic的形式进入Brokers。
3.Broker:启动kafka的一个实例就是一个broker,默认端口号为9092,。一个kafka集群可以启动多个broker同时对外提供服务,broker不保存任何producer和consumer相关的信息。
每一个broker相当于一个节点创建生产的时候 可以创建分区和分区的副本数,如图4个broker分别对应master,slave1,slave2,slave3.
4.Consumer:消息消费者,consumer从kafka指定的主题中拉取消息。
5.Consumer Group:消息者所属组,一个Consumer Group可以包含一个或者多个consumer,当一个topic(分区)被一个Consumer Grop消费的时候,Consumer Group内只能有一个consumer消费同一条消息,不会出现同一个Consumer Group中多个consumer同时消费一条消息造成一个消息被一个Consumer Group消费多次的情况。
如果每一个consumer都要消费这些topic分区,那么将每一个consumer分别设为一个组。
6.Partition:partition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹, 该文件夹下存储该partition的数据和索引文件理论上partition数越多,系统的整体吞吐率就越高,但是在实际应用中并不是partition越多越好,反而过多的partition在broker宕机需要重新对partition选主, 在这个过程中耗时太久会导致partition暂时无法提供服务,造成写入消息失败。
分区命名规则是topcname-inde(eg: testtopic-1 testtopic-2)
扩展性:
为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7.Zookeeper中:Zookeeper在kafka集群中主要用于协调管理,Kafka将元数据信息保存在Zookeeper中,通过Zookeeper的协调管理来实现整个Kafka集群的动态扩展、各个Broker负载均衡、Productor通过Zookeeper感知Partition的Leader、Consumer消费的负载均衡并可以保存Consumer消费的状态信息。
图流程理解:
1.生产者不断的产生数据,列如flume采集的数据。它以topic的形式发送给broker,如果数据量过于庞大,可以采取分区的方式发送给各个节点的broker。在发送的时候,我们可以提前创建分区数和副本数。
创建topic的命令如下:(创建一个名为test的topic,分区数1,副本数为3)
kafka-console-Producer --create --topic test --zookeeper local:2181 --partitions 1 --replication-factor3
2.如图有2个topic,topic1和topic2,topic1有2个分区分别是topic-part1和topic1-part2,两个分区各自有3个复本数,如果将topic分区,那么副本数是针对于每一个分区的。
如果说我要向topic-part1这个分区插入数据,那part1的两个复本怎么办?因为我是在创建topic的时候指定的分区个数啊?
3. kafak依赖于走zookeeper,每一个broker会向zookeeper注册自己,根据zookeeper的选举机制,会通过投票在同一个分区的所有复本中选出一个leader,其他的是follow,leader更新follow也会更新。它的容错性也是非常强的,可以kill一个broker,但即使最初接受写入的领导者已经失败,这些消息仍可供消费。
4.consumer去拉去topic分区,来消费。
注意:在同一个组中的消费者不同消费同一个分区。
