一、为什么不用Redis做消息队列
经常听到很多人讨论,关于把 Redis 当作队列来用是否合适的问题。
有些人表示赞成,他们认为 Redis 很轻量,用作队列很方便。
也些人则反对,认为 Redis 会丢数据,最好还是用专业的队列中间件更稳妥。
究竟哪种方案更好呢?
1、Redis中List队列
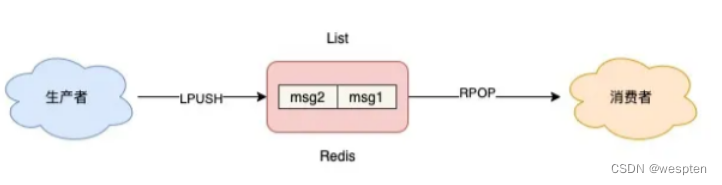
从最简单的开始:List 队列。首先,我们先从最简单的场景开始讲起,如果你的业务需求足够简单,想把 Redis 当作队列来使用,肯定最先想到的就是使用 List 这个数据类型。因为List底层的实现就是一个链表,在头部和尾部操作元素,时间复杂度都是 O(1),这意味着它非常符合消息队列的模型。
如果把 List 当作队列,你可以这么来用。
生产者使用 LPUSH 发布消息:
127.0.0.1:6379> LPUSH queue msg1
(integer) 1
127.0.0.1:6379> LPUSH queue msg2
(integer) 2消费者这一侧,使用 RPOP 拉取消息:
127.0.0.1:6379> RPOP queue
"msg1"
127.0.0.1:6379> RPOP queue
"msg2"这个模型非常简单,也很容易理解:
但这里有个小问题,当队列中已经没有消息了,消费者在执行 RPOP 时,会返回 NULL。
127.0.0.1:6379> RPOP queue
(nil) // 没消息了而我们在编写消费者逻辑时,一般是一个死循环,这个逻辑需要不断地从队列中拉取消息进行处理,伪代码一般会这么写:
while true:
msg = redis.rpop("queue")
// 没有消息,继续循环
if msg == null:
continue
// 处理消息
handle(msg)如果此时队列为空,那消费者依旧会频繁拉取消息,这会造成CPU 空转,不仅浪费 CPU 资源,还会对 Redis造成压力。
1)解决cpu空转问题
怎么解决这个问题呢?也很简单,当队列为空时,我们可以休眠一会,再去尝试拉取消息。代码可以修改成这样:
while true:
msg = redis.rpop("queue")
// 没有消息,休眠2s
if msg == null:
sleep(2)
continue
// 处理消息
handle(msg)这就解决了 CPU 空转问题。这个问题虽然解决了,但又带来另外一个问题:当消费者在休眠等待时,有新消息来了,那消费者处理新消息就会存在延迟。
假设设置的休眠时间是 2s,那新消息最多存在 2s 的延迟。
2)Redis阻塞式拉取
要想缩短这个延迟,只能减小休眠的时间。但休眠时间越小,又有可能引发 CPU 空转问题。
鱼和熊掌不可兼得。那如何做,既能及时处理新消息,还能避免 CPU 空转呢?
Redis 是否存在这样一种机制:如果队列为空,消费者在拉取消息时就阻塞等待,一旦有新消息过来,就通知我的消费者立即处理新消息呢?
幸运的是,Redis 确实提供了「阻塞式」拉取消息的命令:BRPOP / BLPOP,这里的 B 指的是阻塞Block:

现在,你可以这样来拉取消息了:
while true:
// 没消息阻塞等待,0表示不设置超时时间
msg = redis.brpop("queue", 0)
if msg == null:
continue
// 处理消息
handle(msg)
使用 BRPOP 这种阻塞式方式拉取消息时,还支持传入一个超时时间,如果设置为 0,则表示不设置超时,直到有新消息才返回,否则会在指定的超时时间后返回 NULL
这个方案不错,既兼顾了效率,还避免了 CPU 空转问题,一举两得
注意:如果设置的超时时间太长,这个连接太久没有活跃过,可能会被 Redis Server 判定为无效连接,之后 Redis Server 会强制把这个客户端踢下线。所以,采用这种方案,客户端要有重连机制。
解决了消息处理不及时的问题,你可以再思考一下,这种队列模型,有什么缺点?
- 不支持重复消费:消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费,即不支持多个消费者消费同一批数据。
- 消息丢失:消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了。
第一个问题是功能上的,使用 List 做消息队列,它仅仅支持最简单的,一组生产者对应一组消费者,不能满足多组生产者和消费者的业务场景。
第二个问题就比较棘手了,因为从 List 中 POP 一条消息出来后,这条消息就会立即从链表中删除了。也就是说,无论消费者是否处理成功,这条消息都没办法再次消费了。这也意味着,如果消费者在处理消息时异常宕机,那这条消息就相当于丢失了。
2、Redis发布订阅
发布/订阅模型:Pub/Sub。
从名字就能看出来,这个模块是 Redis 专门是针对发布/订阅这种队列模型设计的。它正好可以解决前面提到的第一个问题:重复消费。即多组生产者、消费者的场景,我们来看它是如何做的。
Redis 提供了 PUBLISH / SUBSCRIBE 命令,来完成发布、订阅的操作。
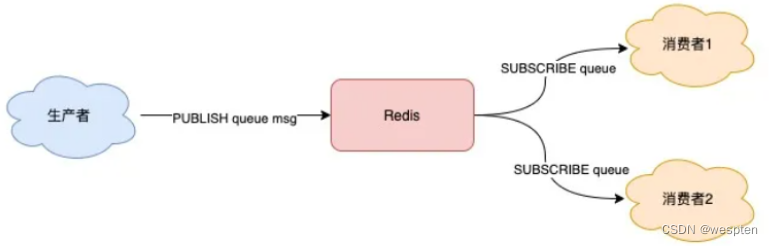
1)简单应用
假设你想开启 2 个消费者,同时消费同一批数据,就可以按照以下方式来实现。
首先,使用 SUBSCRIBE 命令,启动 2 个消费者,并订阅同一个队列。
// 2个消费者 都订阅一个队列
127.0.0.1:6379> SUBSCRIBE queue
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "queue"
3) (integer) 1此时,2 个消费者都会被阻塞住,等待新消息的到来。之后,再启动一个生产者,发布一条消息。
127.0.0.1:6379> PUBLISH queue msg1
(integer) 1这时,2 个消费者就会解除阻塞,收到生产者发来的新消息。
127.0.0.1:6379> SUBSCRIBE queue
// 收到新消息
1) "message"
2) "queue"
3) "msg1"看到了么,使用 Pub/Sub 这种方案,既支持阻塞式拉取消息,还很好地满足了多组消费者,消费同一批数据的业务需求。
除此之外,Pub/Sub 还提供了匹配订阅模式,允许消费者根据一定规则,订阅多个自己感兴趣的队列:
// 订阅符合规则的队列
127.0.0.1:6379> PSUBSCRIBE queue.*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "queue.*"
3) (integer) 1这里的消费者,订阅了 queue.* 相关的队列消息。之后,生产者分别向 queue.p1 和 queue.p2 发布消息:
127.0.0.1:6379> PUBLISH queue.p1 msg1
(integer) 1
127.0.0.1:6379> PUBLISH queue.p2 msg2
(integer) 1这时再看消费者,它就可以接收到这 2 个生产者的消息了:
127.0.0.1:6379> PSUBSCRIBE queue.*
Reading messages... (press Ctrl-C to quit)
...
// 来自queue.p1的消息
1) "pmessage"
2) "queue.*"
3) "queue.p1"
4) "msg1"
// 来自queue.p2的消息
1) "pmessage"
2) "queue.*"
3) "queue.p2"
4) "msg2"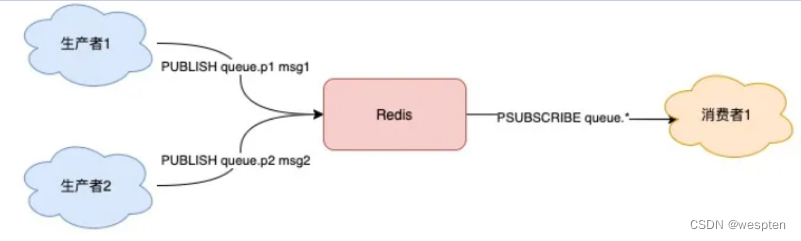
我们可以看到,Pub/Sub 最大的优势就是,支持多组生产者、消费者处理消息。
2)发布订阅的缺点
讲完了它的优点,那它有什么缺点呢?其实,Pub/Sub 最大问题是:丢数据。
如果发生以下场景,就有可能导致数据丢失:
- 消费者下线
- Redis 宕机
- 消息堆积
究竟是怎么回事?
这其实与 Pub/Sub 的实现方式有很大关系。
Pub/Sub 在实现时非常简单,它没有基于任何数据类型,也没有做任何的数据存储,它只是单纯地为生产者、消费者建立数据转发通道,把符合规则的数据,从一端转发到另一端。
一个完整的发布、订阅消息处理流程是这样的:
- 消费者订阅指定队列,Redis 就会记录一个映射关系:队列->消费者
- 生产者向这个队列发布消息,那 Redis 就从映射关系中找出对应的消费者,把消息转发给它
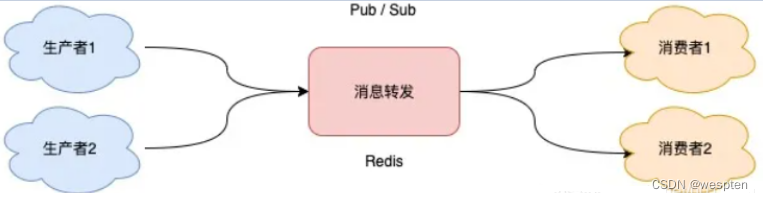
看到了么,整个过程中,没有任何的数据存储,一切都是实时转发的。
这种设计方案,就导致了上面提到的那些问题。
例如,如果一个消费者异常挂掉了,它再重新上线后,只能接收新的消息,在下线期间生产者发布的消息,因为找不到消费者,都会被丢弃掉。如果所有消费者都下线了,那生产者发布的消息,因为找不到任何一个消费者,也会全部丢弃。所以,当你在使用 Pub/Sub 时,一定要注意:消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。
这也是前面讲例子时,我们让消费者先订阅队列,之后才让生产者发布消息的原因。
另外,因为 Pub/Sub 没有基于任何数据类型实现,所以它也不具备数据持久化的能力。也就是说,Pub/Sub 的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,Pub/Sub 的数据也会全部丢失。
最后,我们来看 Pub/Sub 在处理消息积压时,为什么也会丢数据?
当消费者的速度,跟不上生产者时,就会导致数据积压的情况发生。如果采用 List 当作队列,消息积压时,会导致这个链表很长,最直接的影响就是,Redis 内存会持续增长,直到消费者把所有数据都从链表中取出。但 Pub/Sub 的处理方式却不一样,当消息积压时,有可能会导致消费失败和消息丢失!
这是怎么回事?
还是回到 Pub/Sub 的实现细节上来说。每个消费者订阅一个队列时,Redis 都会在 Server 上给这个消费者在分配一个缓冲区,这个缓冲区其实就是一块内存。当生产者发布消息时,Redis 先把消息写到对应消费者的缓冲区中。
之后,消费者不断地从缓冲区读取消息,处理消息。

但是,问题就出在这个缓冲区上,因为这个缓冲区其实是有上限的(可配置),如果消费者拉取消息很慢,就会造成生产者发布到缓冲区的消息开始积压,缓冲区内存持续增长。
如果超过了缓冲区配置的上限,此时,Redis 就会强制把这个消费者踢下线,这时消费者就会消费失败,也会丢失数据。
如果你有看过 Redis 的配置文件,可以看到这个缓冲区的默认配置:
client-output-buffer-limit pubsub 32mb 8mb 60它的参数含义如下:
- 32mb:缓冲区一旦超过 32MB,Redis 直接强制把消费者踢下线
- 8mb + 60:缓冲区超过 8MB,并且持续 60 秒,Redis 也会把消费者踢下线
Pub/Sub 的这一点特点,是与 List 作队列差异比较大的,从这里你应该可以看出,List 其实是属于拉模型,而 Pub/Sub 其实属于推模型。
List 中的数据可以一直积压在内存中,消费者什么时候来拉都可以。
但 Pub/Sub 是把消息先推到消费者在 Redis Server 上的缓冲区中,然后等消费者再来取。当生产、消费速度不匹配时,就会导致缓冲区的内存开始膨胀,Redis 为了控制缓冲区的上限,所以就有了上面讲到的,强制把消费者踢下线的机制。
好了,现在我们总结一下 Pub/Sub 的优缺点:
- 支持发布 / 订阅,支持多组生产者、消费者处理消息
- 消费者下线,数据会丢失
- 不支持数据持久化,
Redis宕机,数据也会丢失 - 消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失
有没有发现,除了第一个是优点之外,剩下的都是缺点。
所以,很多人看到 Pub/Sub 的特点后,觉得这个功能很鸡肋。也正是以上原因,Pub/Sub 在实际的应用场景中用得并不多,目前只有哨兵集群和Redis 实例通信时,采用了 Pub/Sub 的方案,因为哨兵正好符合即时通讯的业务场景。
我们再来看一下,Pub/Sub 有没有解决,消息处理时异常宕机,无法再次消费的问题呢?
其实也不行,Pub/Sub 从缓冲区取走数据之后,数据就从 Redis 缓冲区删除了,消费者发生异常,自然也无法再次重新消费。
好,现在我们重新梳理一下,我们在使用消息队列时的需求。
当我们在使用一个消息队列时,希望它的功能如下:
- 支持阻塞等待拉取消息
- 支持发布 / 订阅模式
- 消费失败,可重新消费,消息不丢失
- 实例宕机,消息不丢失,数据可持久化
- 消息可堆积
Redis 除了 List 和 Pub/Sub 之外,还有符合这些要求的数据类型吗?
其实,Redis 的作者也看到了以上这些问题,也一直在朝着这些方向努力着。Redis 作者在开发 Redis 期间,还另外开发了一个开源项目 disque,这个项目的定位,就是一个基于内存的分布式消息队列中间件。
但由于种种原因,这个项目一直不温不火。
终于,在 Redis 5.0 版本,作者把 disque 功能移植到了 Redis 中,并给它定义了一个新的数据类型:Stream,它能符合上面提到的这些要求吗?
3、Redis中的Stream
趋于成熟的队列:Stream,我们来看 Stream 是如何解决上面这些问题的。我们依旧从简单到复杂,依次来看 Stream 在做消息队列时,是如何处理的?
1)简单应用
首先,Stream 通过 XADD 和 XREAD 完成最简单的生产、消费模型:
- XADD:发布消息
- XREAD:读取消息
生产者发布 2 条消息:
// *表示让Redis自动生成消息ID
127.0.0.1:6379> XADD queue * name zhangsan
"1618469123380-0"
127.0.0.1:6379> XADD queue * name lisi
"1618469127777-0"使用 XADD 命令发布消息,其中的*表示让 Redis 自动生成唯一的消息 ID,这个消息 ID 的格式是时间戳-自增序号。
消费者拉取消息:
// 从开头读取5条消息,0-0表示从开头读取
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 0-0
1) 1) "queue"
2) 1) 1) "1618469123380-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618469127777-0"
2) 1) "name"
2) "lisi"如果想继续拉取消息,需要传入上一条消息的 ID:
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 1618469127777-0
(nil)没有消息,Redis 会返回 NULL。

以上就是 Stream 最简单的生产、消费。这里不再重点介绍 Stream 命令的各种参数,我在例子中演示时,凡是大写的单词都是固定参数,凡是小写的单词,都是可以自己定义的,例如队列名、消息长度等等,下面的例子规则也是一样,为了方便你理解,这里有必要提醒一下。
下面我们来看,针对前面提到的消息队列要求,Stream 都是如何解决的?
2) stream阻塞拉取
Stream 是否支持阻塞式拉取消息?
可以的,在读取消息时,只需要增加 BLOCK 参数即可:
// BLOCK 0 表示阻塞等待,不设置超时时间
127.0.0.1:6379> XREAD COUNT 5 BLOCK 0 STREAMS queue 1618469127777-0这时,消费者就会阻塞等待,直到生产者发布新的消息才会返回。
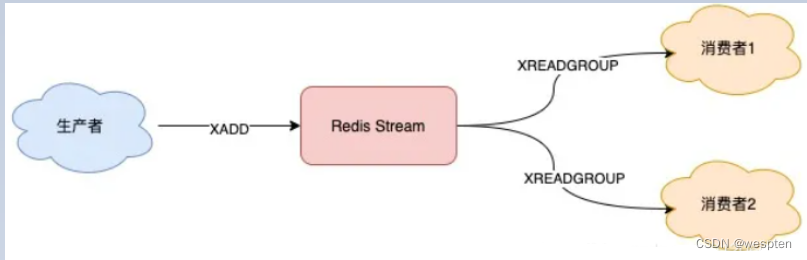
3)Stream支持发布 / 订阅模式
也没问题,Stream 通过以下命令完成发布订阅:
- XGROUP:创建消费者组
- XREADGROUP:在指定消费组下,开启消费者拉取消息
下面我们来看具体如何做?
首先,生产者依旧发布 2 条消息:
127.0.0.1:6379> XADD queue * name zhangsan
"1618470740565-0"
127.0.0.1:6379> XADD queue * name lisi
"1618470743793-0"之后,我们想要开启 2 组消费者处理同一批数据,就需要创建 2 个消费者组:
// 创建消费者组1,0-0表示从头拉取消息
127.0.0.1:6379> XGROUP CREATE queue group1 0-0
OK
// 创建消费者组2,0-0表示从头拉取消息
127.0.0.1:6379> XGROUP CREATE queue group2 0-0
OK消费者组创建好之后,我们可以给每个消费者组下面挂一个消费者,让它们分别处理同一批数据。
第一个消费组开始消费:
// group1的consumer开始消费,>表示拉取最新数据
127.0.0.1:6379> XREADGROUP GROUP group1 consumer COUNT 5 STREAMS queue >
1) 1) "queue"
2) 1) 1) "1618470740565-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618470743793-0"
2) 1) "name"
2) "lisi"同样地,第二个消费组开始消费:
// group2的consumer开始消费,>表示拉取最新数据
127.0.0.1:6379> XREADGROUP GROUP group2 consumer COUNT 5 STREAMS queue >
1) 1) "queue"
2) 1) 1) "1618470740565-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618470743793-0"
2) 1) "name"
2) "lisi"我们可以看到,这 2 组消费者,都可以获取同一批数据进行处理了。这样一来,就达到了多组消费者「订阅」消费的目的。
4)stream不丢消息
消息处理时异常,Stream 能否保证消息不丢失,重新消费?
除了上面拉取消息时用到了消息 ID,这里为了保证重新消费,也要用到这个消息 ID。
当一组消费者处理完消息后,需要执行 XACK 命令告知 Redis,这时 Redis 就会把这条消息标记为处理完成:
// group1下的 1618472043089-0 消息已处理完成
127.0.0.1:6379> XACK queue group1 1618472043089-0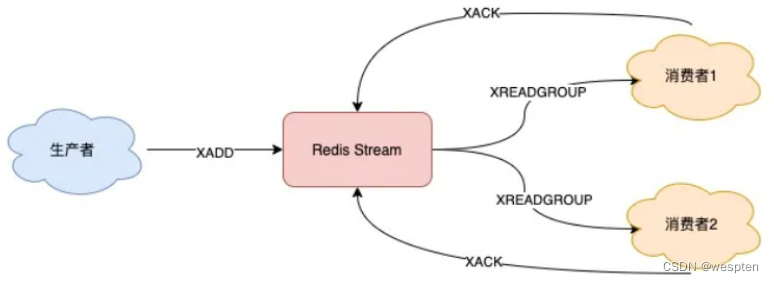
如果消费者异常宕机,肯定不会发送 XACK,那么 Redis 就会依旧保留这条消息。
待这组消费者重新上线后,Redis 就会把之前没有处理成功的数据,重新发给这个消费者。这样一来,即使消费者异常,也不会丢失数据了。
// 消费者重新上线,0-0表示重新拉取未ACK的消息
127.0.0.1:6379> XREADGROUP GROUP group1 consumer1 COUNT 5 STREAMS queue 0-0
// 之前没消费成功的数据,依旧可以重新消费
1) 1) "queue"
2) 1) 1) "1618472043089-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618472045158-0"
2) 1) "name"
2) "lisi"5)stream持久化处理
Stream 是新增加的数据类型,它与其它数据类型一样,每个写操作,也都会写入到 RDB 和 AOF中。我们只需要配置好持久化策略,这样的话,就算 Redis 宕机重启,Stream 中的数据也可以从 RDB 或 AOF 中恢复回来。
6)stream消息堆积
消息堆积时,Stream 是怎么处理的?
其实,当消息队列发生消息堆积时,一般只有 2 个解决方案:
- 生产者限流:避免消费者处理不及时,导致持续积压
- 丢弃消息:中间件丢弃旧消息,只保留固定长度的新消息
而 Redis 在实现 Stream 时,采用了第 2 个方案。
在发布消息时,你可以指定队列的最大长度,防止队列积压导致内存爆炸。
// 队列长度最大10000
127.0.0.1:6379> XADD queue MAXLEN 10000 * name zhangsan
"1618473015018-0"当队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。
除了以上介绍到的命令,Stream 还支持查看消息长度XLEN、查看消费者状态XINFO等命令,使用也比较简单,你可以查询官方文档了解一下,这里就不过多介绍了。
好了,通过以上介绍,我们可以看到,Redis 的 Stream 几乎覆盖到了消息队列的各种场景,是不是觉得很完美?
既然它的功能这么强大,这是不是意味着,Redis 真的可以作为专业的消息队列中间件来使用呢?
但是还差一点,就算 Redis 能做到以上这些,也只是趋近于专业的消息队列。原因在于 Redis 本身的一些问题,如果把其定位成消息队列,还是有些欠缺的。
到这里,就不得不把 Redis 与专业的队列中间件做对比了。
4、与专业消息对比
与专业的消息队列对比。其实,一个专业的消息队列,必须要做到两大块:
- 消息不丢
- 消息可堆积
前面我们讨论的重点,很大篇幅围绕的是第一点展开的。
这里我们换个角度,从一个消息队列的「使用模型」来分析一下,怎么做,才能保证数据不丢?
使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者:

消息是否会发生丢失,其重点也就在于以下 3 个环节:
- 生产者会不会丢消息?
- 消费者会不会丢消息?
- 队列中间件会不会丢消息?
1)生产者会不会丢消息
当生产者在发布消息时,可能发生以下异常情况:
- 消息没发出去:网络故障或其它问题导致发布失败,中间件直接返回失败
- 不确定是否发布成功:网络问题导致发布超时,可能数据已发送成功,但读取响应结果超时了
如果是情况 1,消息根本没发出去,那么重新发一次就好了。
如果是情况 2,生产者没办法知道消息到底有没有发成功?所以,为了避免消息丢失,它也只能继续重试,直到发布成功为止。
生产者一般会设定一个最大重试次数,超过上限依旧失败,需要记录日志报警处理。也就是说,生产者为了避免消息丢失,只能采用失败重试的方式来处理。
但发现没有?这也意味着消息可能会重复发送。是的,在使用消息队列时,要保证消息不丢,宁可重发,也不能丢弃,那消费者这边,就需要多做一些逻辑了。
对于敏感业务,当消费者收到重复数据数据时,要设计幂等逻辑,保证业务的正确性。
从这个角度来看,生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。所以,无论是 Redis 还是专业的队列中间件,生产者在这一点上都是可以保证消息不丢的。
2)消费者会不会丢消息
这种情况就是我们前面提到的,消费者拿到消息后,还没处理完成,就异常宕机了,那消费者还能否重新消费失败的消息?
要解决这个问题,消费者在处理完消息后,必须「告知」队列中间件,队列中间件才会把标记已处理,否则仍旧把这些数据发给消费者。
这种方案需要消费者和中间件互相配合,才能保证消费者这一侧的消息不丢。无论是 Redis 的 Stream,还是专业的队列中间件,例如 RabbitMQ、Kafka,其实都是这么做的。
所以,从这个角度来看,Redis 也是合格的。
3)队列中间件会不会丢消息
前面 2 个问题都比较好处理,只要客户端和服务端配合好,就能保证生产端、消费端都不丢消息。
但是,如果队列中间件本身就不可靠呢?
毕竟生产者和消费这都依赖它,如果它不可靠,那么生产者和消费者无论怎么做,都无法保证数据不丢。在这个方面,Redis 其实没有达到要求。
Redis 在以下 2 个场景下,都会导致数据丢失:
AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
主从复制也是异步的,主从切换时,也存在丢失数据的可能(从库还未同步完成主库发来的数据,就被提成主库)
基于以上原因我们可以看到,Redis 本身的无法保证严格的数据完整性。所以,如果把 Redis 当做消息队列,在这方面是有可能导致数据丢失的。
再来看那些专业的消息队列中间件是如何解决这个问题的?
像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时,一般是部署一个集群,生产者在发布消息时,队列中间件通常会写多个节点,以此保证消息的完整性。这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
也正因为如此,RabbitMQ、Kafka在设计时也更复杂。毕竟,它们是专门针对队列场景设计的。
但 Redis 的定位则不同,它的定位更多是当作缓存来用,它们两者在这个方面肯定是存在差异的。
4)消息积压怎么办
因为 Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。所以,Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生
但 Kafka、RabbitMQ 这类消息队列就不一样了,它们的数据都会存储在磁盘上,磁盘的成本要比内存小得多,当消息积压时,无非就是多占用一些磁盘空间,相比于内存,在面对积压时也会更加坦然。
综上,我们可以看到,把 Redis 当作队列来使用时,始终面临的 2 个问题:
- Redis 本身可能会丢数据
- 面对消息积压,Redis 内存资源紧张
到这里,Redis 是否可以用作队列,我想这个答案你应该会比较清晰了。如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
而且,Redis 相比于 Kafka、RabbitMQ,部署和运维也更加轻量。
如果你的业务场景对于数据丢失非常敏感,而且写入量非常大,消息积压时会占用很多的机器资源,那么我建议你使用专业的消息队列中间件。

二、Kafka、ActiveMQ、RabbitMQ、RocketMQ对比
1、为什么要使用消息队列
其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么?
面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用 MQ 可能会很麻烦,但是现在用了 MQ 之后带给了你很多的好处。
先说一下消息队列常见的使用场景吧,其实场景有很多,但是比较核心的有 3 个:解耦、异步、削峰。
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。

看这么个场景。A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃……
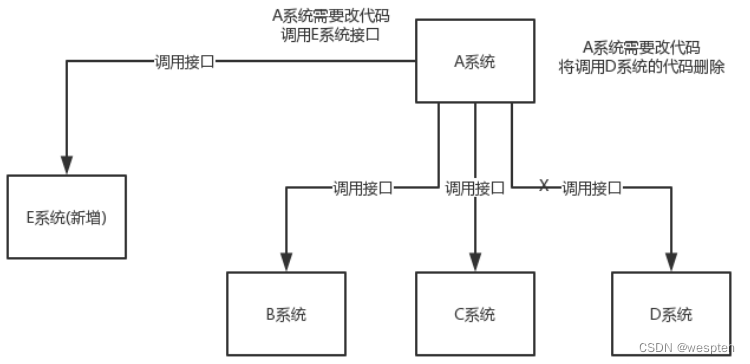
在这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了该咋办?要不要重发,要不要把消息存起来?
如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。

总结:通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
面试技巧:需要去考虑一下你负责的系统中是否有类似的场景,就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用 MQ 给它异步化解耦,也是可以的,你就需要去考虑在你的项目里,是不是可以运用这个 MQ 去进行系统的解耦。
2)异步
允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。

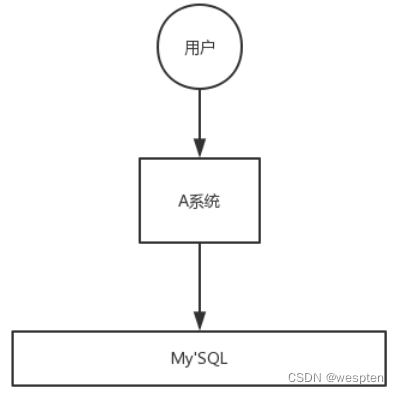
再来看一个场景,A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求,等待个 1s,这几乎是不可接受的。
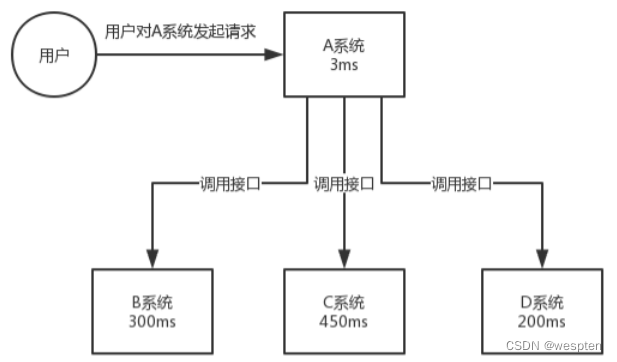
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的。
如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了。

3)缓冲/削峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
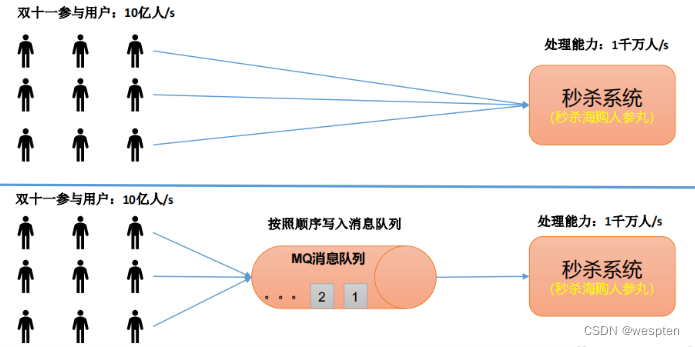
每天 0:00 到 12:00,A 系统风平浪静,每秒并发请求数量就 50 个。结果每次一到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL的,大量的请求涌入 MySQL,每秒钟对 MySQL 执行约 5k 条 SQL。
一般的 MySQL,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,可能就直接把 MySQL 给打死了,导致系统崩溃,用户也就没法再使用系统了。
但是高峰期一过,到了下午的时候,就成了低峰期,可能也就 1w 的用户同时在网站上操作,每秒中的请求数量可能也就 50 个请求,对整个系统几乎没有任何的压力。
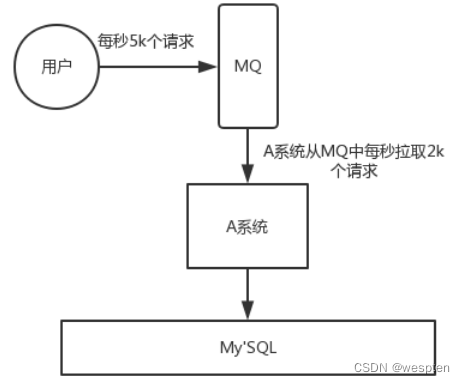
如果使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。而 MQ 每秒钟 5k 个请求进来,就 2k 个请求出去,结果就导致在中午高峰期(1 个小时),可能有几十万甚至几百万的请求积压在 MQ 中。
这个短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是 A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给解决掉。
2、消息队列有什么优缺点
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
- 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,不就完了? - 系统复杂度提高
硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性? - 一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,会发现,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。
3、消息队列的两种模式
1)点对点模式
消费者主动拉取数据,消息收到后清除消息:

2)发布/订阅模式
1. 可以有多个topic主题(浏览、点赞、收藏、评论等)。
2. 消费者消费数据之后,不删除数据;每个消费者相互独立,都可以消费到数据。

4、Kafka、ActiveMQ、RabbitMQ、RocketMQ有什么优缺点
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ | |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 |
MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
综上,各种对比之后,有如下建议:
一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了。
后来大家开始用 RabbitMQ,但是确实erlang 语言阻止了大量的 Java 工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高。
不过现在确实越来越多的公司,会去用 RocketMQ,确实很不错(阿里出品),但社区可能有突然黄掉的风险,对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝对不会黄。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
在JavaEE开发中主要采用 ActiveMQ、RabbitMQ、RocketMQ。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
三、Kafka架构与原理
1、event streaming
1)实时流式计算
近几年来实时流式计算发展迅速,主要原因是实时数据的价值和对于数据处理架构体系的影响。实时流式计算包含了 无界数据 近实时 一致性 可重复结果 等等特征。a type of data processing engine that is designed with infinite data sets in mind 一种考虑了无线数据集的数据处理引擎。
1. 无限数据:一种不断增长的,基本上无限的数据集。这些通常被称为“流式数据”。无限的流式数据集可以称为无界数据,相对而言有限的批量数据就是有界数据。
2. 无界数据处理:一种持续的数据处理模式,应用于上面的无界数据。批量处理数据(离线计算)也可以重复运行来处理数据,但是会有性能的瓶颈。
3. 低延迟,近实时的结果:相对于离线计算而言,离线计算并没有考虑延迟的问题。
解决了两个问题,流处理可以提代批处理系统:
1. 正确性:有了这个,就和批量计算等价了。
Streaming需要能随着时间的推移依然能计算一定时间窗口的数据。Spark Streaming通过微批的思想解决了这个问题,实时与离线系统进行了一致性的存储,这一点在未来的实时计算系统中都应该满足。
2. 推理时间的工具:这可以让我们超越批量计算。
好的时间推理工具对于处理不同事件的无界无序数据至关重要。
而时间又分为事件时间和处理时间。
还有很多实时流式计算的相关概念,这里不做赘述。
2)event streaming
event streaming 是一个动态的概念,它描述了一个个 event ( "something happened" in the world ) 在不同主体间连续地、正确地流动的状态。

event source 产生 event,event source 可以是数据库、传感器、移动设备、应用程序,等等。
event broker 持久化 event,以备 event sink 可以随时获取它们。
event sink 实时或回顾性地从 broker 中获取 event 进行处理。
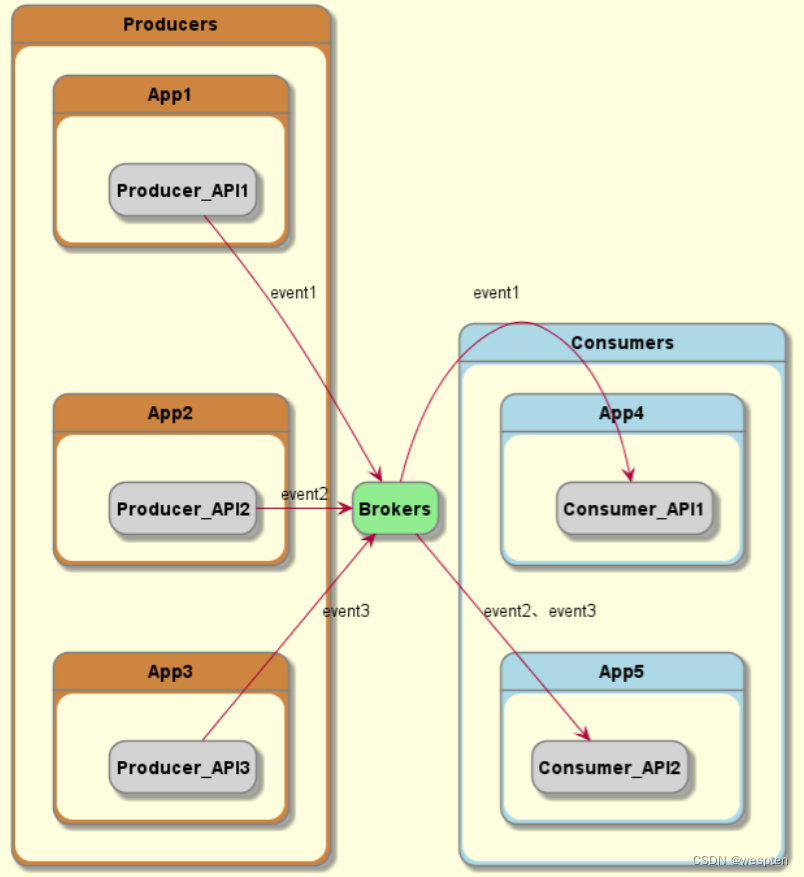
有的人可能会问,为什么需要 broker,event 从 source 直接流到 sink 不行吗?当然可以,但是不够解耦,要么 event source 需要事先知道谁需要这些 event,要么 event sink 需要知道 event 从哪里来。
现在,我们可以在脑子里想象出 event streaming 的样子:event 由 source 产生,然后流向 broker,在 broker 被持久化,再流到 sink。并不复杂对吧?
3)event streaming用来干嘛
我们可以在很多的应用场景中找到 event streaming 的身影,例如:
-
实时处理支付、金融交易、客户订单等等;
-
实时跟踪和监控物流进度;
-
持续捕获和分析来自物联网设备或其他设备的传感器数据;
-
不同数据源的数据连接;
-
作为数据平台、事件驱动架构和微服务等的技术基础;
等等。
如果说 event streaming 是一种规范的话,那么 kafka 就是 event streaming 的一种具体实现。
2、Kafka简介
Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务。而kafka在这之前也没有提供数据处理的顾服务。大家的流处理计算主要是还是依赖于Storm,Spark Streaming,Flink等流式处理框架。
Storm,Spark Streaming,Flink流处理的三驾马车各有各的优势.
Storm低延迟,并且在市场中占有一定的地位,目前很多公司仍在使用。
Spark Streaming借助Spark的体系优势,活跃的社区,也占有一定的份额。
而Flink在设计上更贴近流处理,并且有便捷的API,未来一定很有发展。
但是他们都离不开Kafka的消息中转,所以Kafka于0.10.0.0版本推出了自己的流处理框架,Kafka Streams。Kafka的定位也正式成为Apache Kafka® is *a distributed streaming platform,*分布式流处理平台。
Kafka官网:Apache Kafka
Kafka 是一个高吞吐量、分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景。最初由 LinkedIn 公司开发,使用Scala 语言编写,目前是Apache 的开源项目。
比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
流媒体平台有三个关键功能:
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以容错的持久方式存储记录流。
- 记录发生时处理流。
Kafka通常用于两大类应用:
- 构建可在系统或应用程序之间可靠获取数据的实时流数据管道
- 构建转换或响应数据流的实时流应用程序
Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(MessageQueue),主要应用于大数据实时处理领域。
Kafka最新定义:Kafka是 一个开源的分布式事件流平台 (Event StreamingPlatform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
发布订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
前端埋点记录用户购买商品的行为数据(浏览、点赞、收藏、评论等)

日常:Flume采集速度,小于100m/s。 11.11 活动:Flume采集速度,大于200m/s。
3、Kafka架构
1)Kafka基础架构
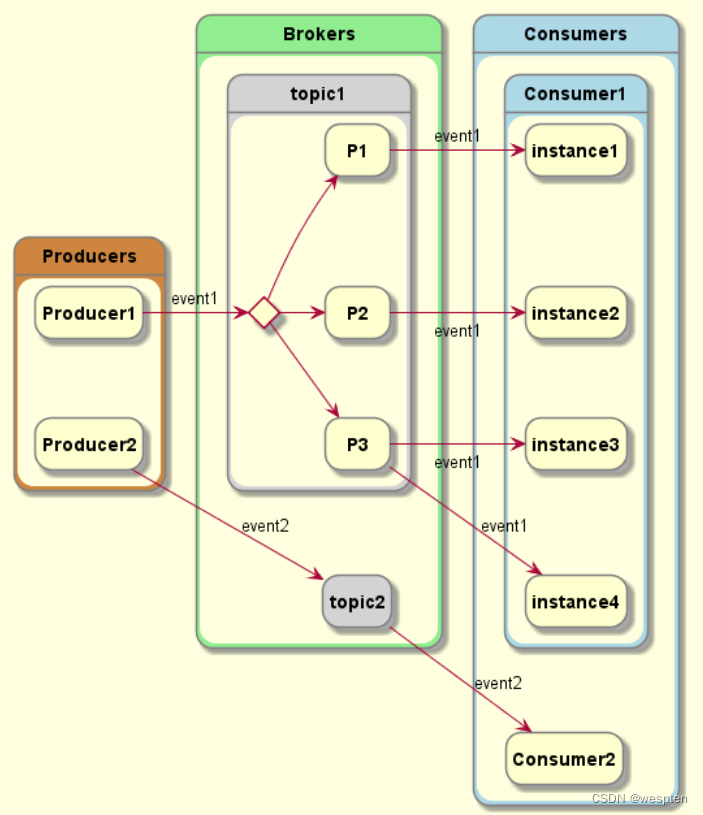
1. 为方便扩展,并提高吞吐量,一个topic分为多个partition。配合分区的设计,提出消费者组的概念,组内每个消费者并行消费。
2. 为提高可用性,为每个partition增加若干副本,类似NameNode HA;ZK中记录谁是leader,Kafka2.8.0 以后也可以配置不采用ZK。

producer发布event,broker持久化even,consumer订阅event。其中,producer 和 consumer 完全解耦,互不知晓。
2)Kafka详细架构
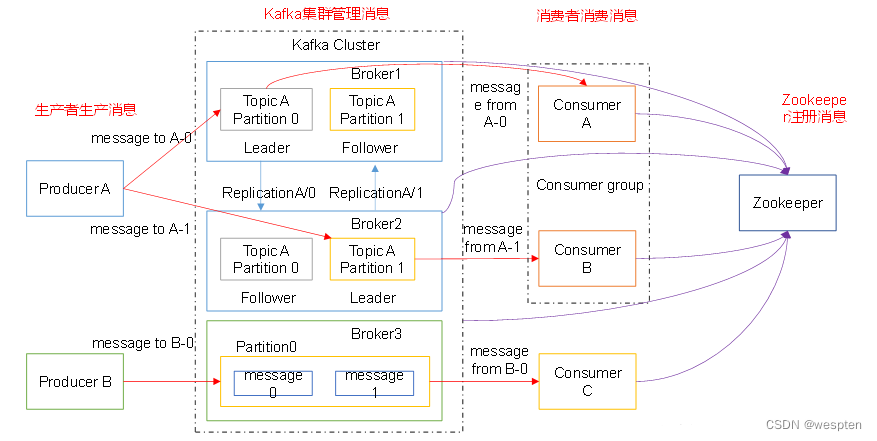
4、Kafka相关组件
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
下面是Kafka中涉及到的相关概念:
- broker(服务):就是kafka服务,一个Broker可以创建多个topic,负责消息存储和转发。一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。
- topic(主题):可以理解为一个队列,生产者和消费者面向的都是一个 topic。一个kafka集群里面可以有多个Topic,Kafka 按照topic 来区分业务和模块(即使如此,kafka仍然有点对点和广播发布类型)
- partition(分区):topic 的分区,为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 消息可以分为多个 partition,保存在各个partition 上,每个 partition 是一个有序的队列。就是把一个topic的信息分成几个区,利用多个节点把多个分区,放在不同节点上面,实现负载均衡,kafka内部实现的。partition中的每条消息都会被分配一个有序的id(offset),kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
- offset(偏移量):消息在日志中的位置,代表该消息的唯一序号,也就是消息的主键。生产者写入数据后返回的偏移量,消费者消费数据知道数据消费的位置,防止重复消费。kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
- Producer(消息生产者): 生产数据对应客户端,就是向 Kafka broker 发消息的客户端。
- Consumer(消息消费者):向 Kafka broker 取消息的客户端,负责处理kafka服务里面消息。
- Consumer Group(消费者分组 CG):由多个 consumer 组成,每个Consumer 必须属于一个 group。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。每个Consumer属于一个特定的Consumer Group,并且每个消费者Consumer都有一个group id,group id相同的多个消费者自动成为一个消费者组,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息。kafka处理方式轮询还是广播, 轮询:消费者每一个处理一条。 广播:一条信息,多个消费者同时处理。CG是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG,topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
- Zookeeper:保存着集群 broker、topic、partition 等 meta 数据;另外,还负责 broker 故障发现,partition leader 选举,负载均衡等功能
- Replica(副本):一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower;Leader 副本才能向外提供服务, Follower副本只有Leader副本挂了,通过某些规则进行选举之后,某个Follower变成了Leader之后才能才能向外提供服务
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
KafKa核心组件:
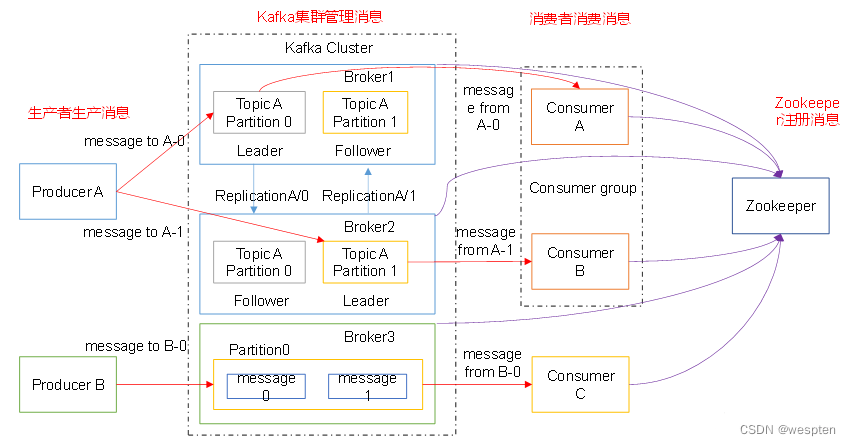
① Topic
Topic 是生产者发送消息的目标地址,是消费者的监听目标。

一个服务可以监听、发送多个 Topics:
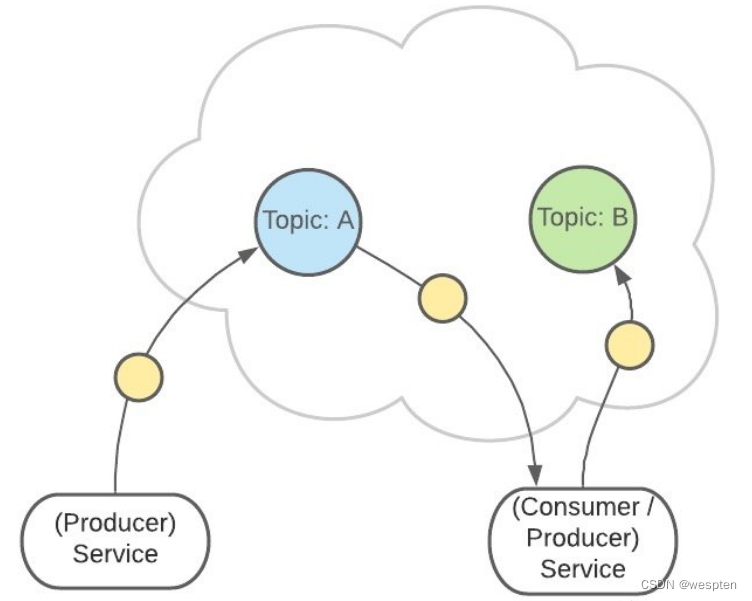
Kafka 中有一个consumer-group(消费者组)的概念。
这是一组服务,扮演一个消费者 :

如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务:
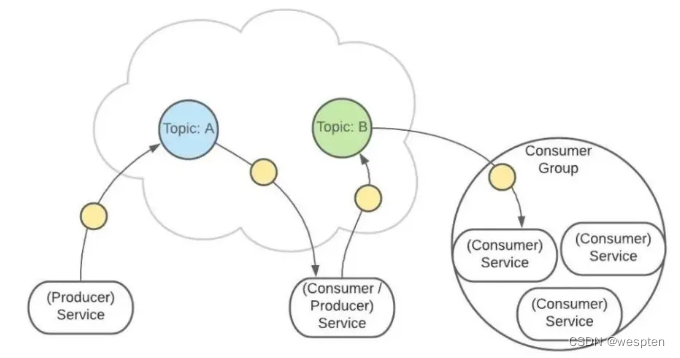
这样有助于消息的负载均衡,也方便扩展消费者。
Topic 扮演一个消息的队列,首先,一条消息发送了 :
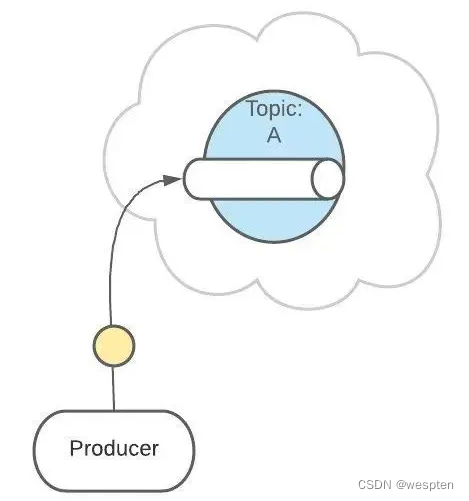
然后,这条消息被记录和存储在这个队列中,不允许被修改:
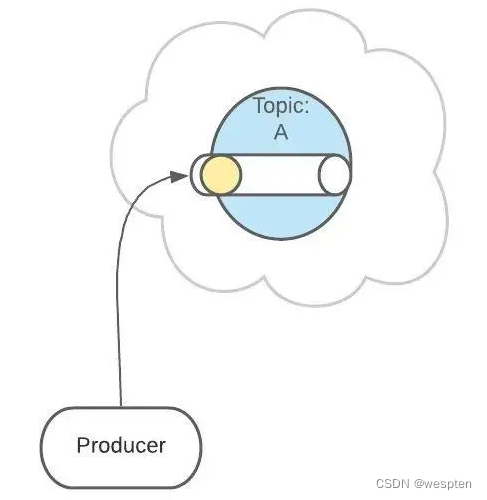
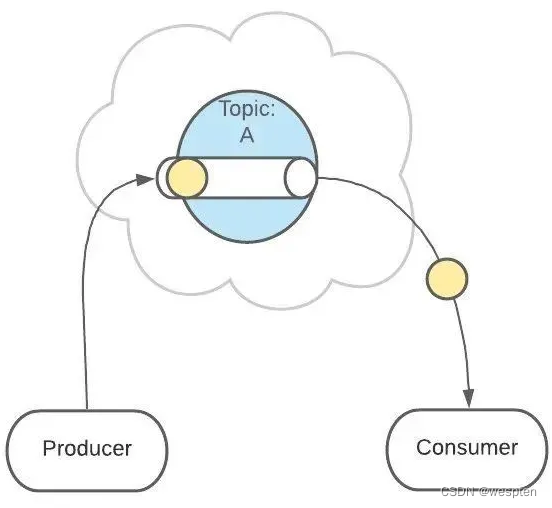
接下来,消息会被发送给此 Topic 的消费者。
但是,这条消息并不会被删除,会继续保留在队列中:
继续发送消息:
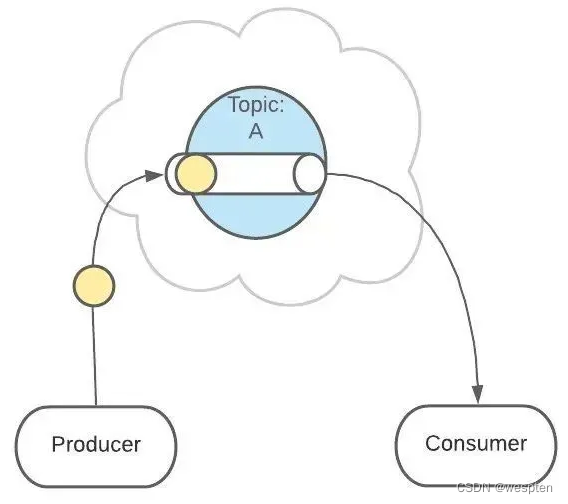
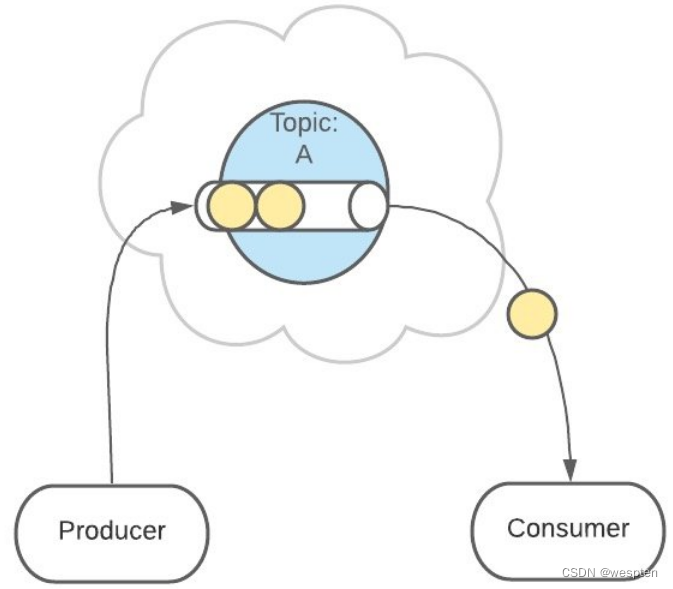
像之前一样,这条消息会发送给消费者、不允许被改动、一直呆在队列中。
(消息在队列中能呆多久,可以修改 Kafka 的配置)

② Partitions 分区
上面 Topic 的描述中,把 Topic 看做了一个队列,实际上,一个 Topic 是由多个队列组成的,被称为【Partition(分区)】。
这样可以便于 Topic 的扩展。

生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition。
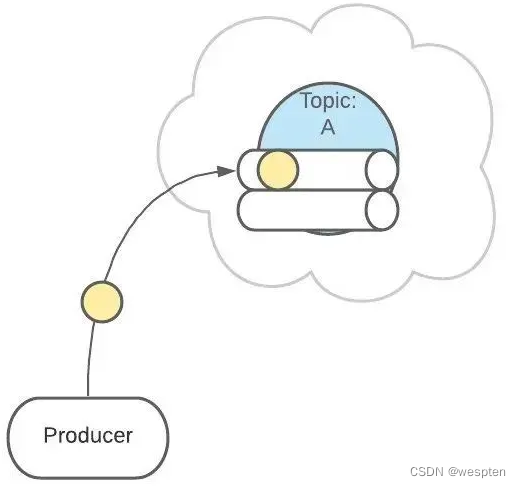
消费者监听的是所有分区。

生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略。
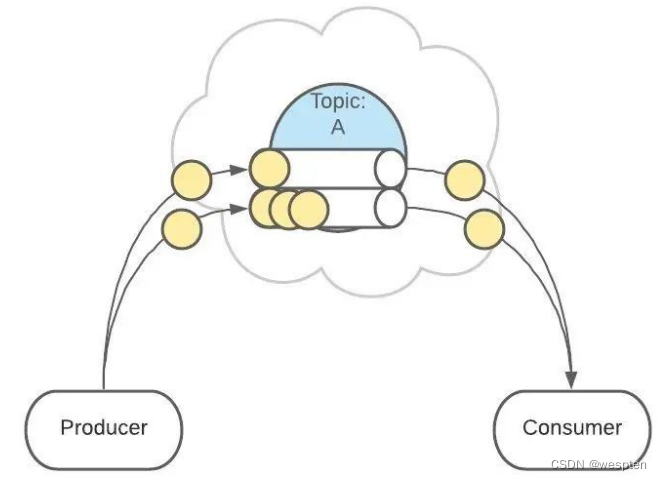
也可以配置 Topic,让同类型的消息都在同一个 Partition。
例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。
例如,用户1发送了3条消息:A、B、C,默认情况下,这3条消息是在不同的 Partition 中(如 P1、P2、P3)。
在配置之后,可以确保用户1的所有消息都发到同一个分区中(如 P1)。
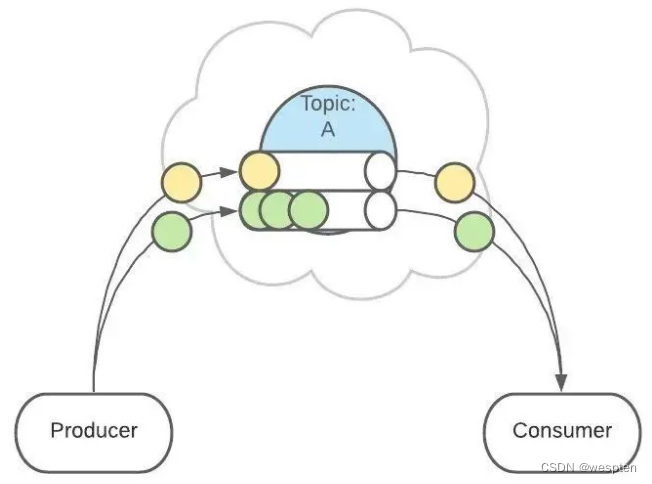
这个功能有什么用呢?
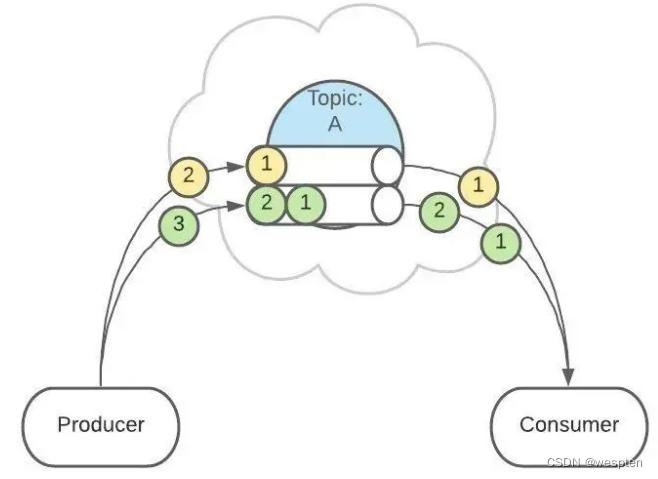
这是为了提供消息的【有序性】。
消息在不同的 Partition 是不能保证有序的,只有一个 Partition 内的消息是有序的。

③ Topics主题和partitions分区关系
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件,主题是发布记录的类别或订阅源名称。Kafka的主题总是多用户; 也就是说,一个主题可以有零个,一个或多个消费者订阅写入它的数据。
可以理解Topic是一个类别的名称,所有的message发送到Topic下面。对于每一个Topic,kafka集群按照如下方式维护一个分区(Partition,可以将消息就理解为一个队列Queue)日志文件。
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
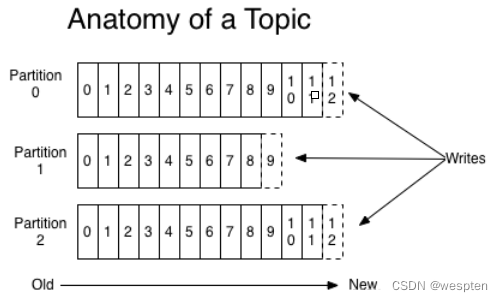
partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
提示:每个partition,都对应一个commit-log。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
kafka集群,在配置的时间范围内,维护所有的由producer生成的消息,而不管这些消息有没有被消费。例如日志保留( log retention )时间被设置为2天。kafka会维护最近2天生产的所有消息,而2天前的消息会被丢弃。kafka的性能与保留的数据量的大小没有关系,因此保存大量的数据(日志信息)不会有什么影响。
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,offset由consumer来维护:一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer来说,都是没有影响的,因此每个consumer维护各自的offset。
对log进行分区(partitioned),有以下目的,当log文件大小超过系统文件系统的限制时,可以自动拆分。每个partition对应的log都受到所在机器的文件系统大小的限制,但是一个Topic中是可以有很多分区的,因此可以处理任意数量的数据。另一个方面,是为了提高并行度。
因而Kafka的性能在数据大小方面实际上是恒定的,因此长时间存储数据不是问题。

实际上,基于每个消费者保留的唯一元数据是该消费者在日志中的偏移或位置。这种偏移由消费者控制:通常消费者在读取记录时会线性地提高其偏移量,但事实上,由于该位置由消费者控制,因此它可以按照自己喜欢的任何顺序消费记录。例如,消费者可以重置为较旧的偏移量来重新处理过去的数据,或者跳到最近的记录并从“现在”开始消费。
这些功能组合意味着Kafka 消费者consumers 非常cheap - 他们可以来来往往对集群或其他消费者没有太大影响。例如,可以使用我们的命令行工具“tail”任何主题的内容,而无需更改任何现有使用者所消耗的内容。
日志中的分区有多种用途。首先,它们允许日志扩展到超出适合单个服务器的大小。每个单独的分区必须适合托管它的服务器,但主题可能有许多分区,因此它可以处理任意数量的数据。其次,它们充当了并行性的单位 - 更多的是它
④ Distribution分配
log的partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。每个server(kafka实例)负责partitions中消息的读写操作,此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性。
基于replicated方案,那么就意味着需要对多个备份进行调度。针对每个partition,都有一个broker起到“leader”的作用,0个多个其他的broker作为“follwers”的作用。leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。每个broker都是自己所管理的partition的leader,同时又是其他broker所管理partitions的followers,kafka通过这种方式来达到负载均衡。
由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定。
⑤ Producers生产者 和 Consumers消费者
Producers生产者
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
Consumers消费者
传统的消息传递模式有2种:队列( queuing)和( publish-subscribe)。
在queuing模式中,多个consumer从服务器中读取数据,消息只会到达一个consumer。在 publish-subscribe 模型中,消息会被广播给所有的consumer。Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
每个consumer都要标记自己属于哪一个consumer group。发布到topic中的message中message会被传递到consumer group中的一个consumer 实例。consumer实例可以运行在不同的进程上,也可以在不同的物理机器上。
如果所有的consumer都位于同一个consumer group 下,这就类似于传统的queue模式,并在众多的consumer instance之间进行负载均衡。
如果所有的consumer都有着自己唯一的consumer group,这就类似于传统的publish-subscribe模型。
更一般的情况是,通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。这并没有什么特殊的地方,仅仅是将publish-subscribe模型中的运行在单个进程上的consumers中的consumer替换成一个consumer group。如下图所示:
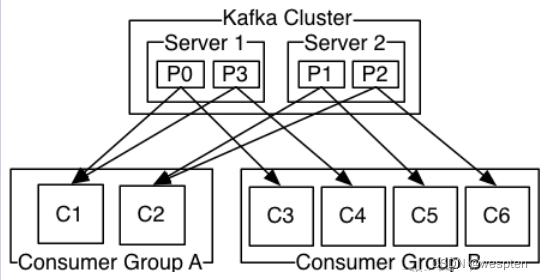
分析:由2个broker组成Kafka群集,托管四个Parition(P0-P3),包含两个使用者组(Consumer Group)。消费者组A有两个消费者实例(Consumer instances ),B组有四个消费者实例。
在Kafka中实现消费consumption 的方式是通过在消费者实例上划分日志中的分区,以便每个实例在任何时间点都是分配的“公平份额”的独占消费者。维护组中成员资格的过程由Kafka协议动态处理。如果新实例加入该组,他们将从该组的其他成员接管一些分区; 如果实例死亡,其分区将分发给其余实例。
Kafka仅提供分区内记录的总订单,而不是主题中不同分区之间的记录。对于大多数应用程序而言,按分区排序与按键分区数据的能力相结合就足够了。但是,如果您需要对记录进行总订单,则可以使用仅包含一个分区的主题来实现,但这将意味着每个使用者组只有一个使用者进程。
Consumers kafka确保
发送到partitions中的消息将会按照它接收的顺序追加到日志中。也就是说,如果记录M1由与记录M2相同的生成者发送,并且首先发送M1,则M1将具有比M2更低的偏移并且在日志中更早出现。
消费者实例按照它们存储在日志中的顺序查看记录。对于消费者而言,它们消费消息的顺序和日志中消息顺序一致。
如果Topic的replicationfactor为N,那么允许N-1个kafka实例失效,我们将容忍最多N-1个服务器故障,而不会丢失任何提交到日志的记录。
⑥ 架构和zookeeper关系
Kafka 是集群架构的,ZooKeeper是重要组件。
ZooKeeper 管理者所有的 Topic 和 Partition。
Topic 和 Partition 存储在 Node 物理节点中,ZooKeeper负责维护这些 Node。
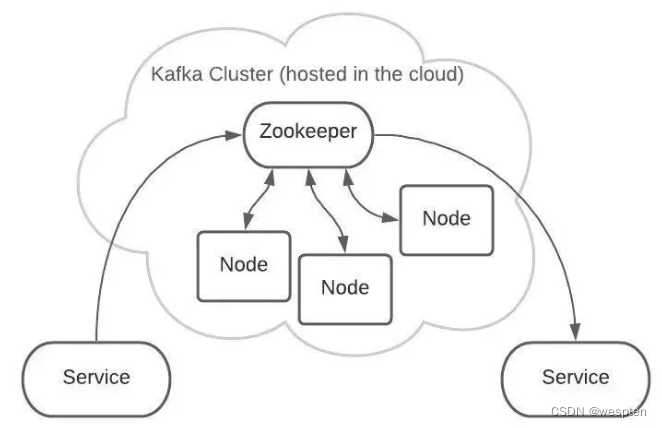
例如,有2个Topic,各自有2个Partition。
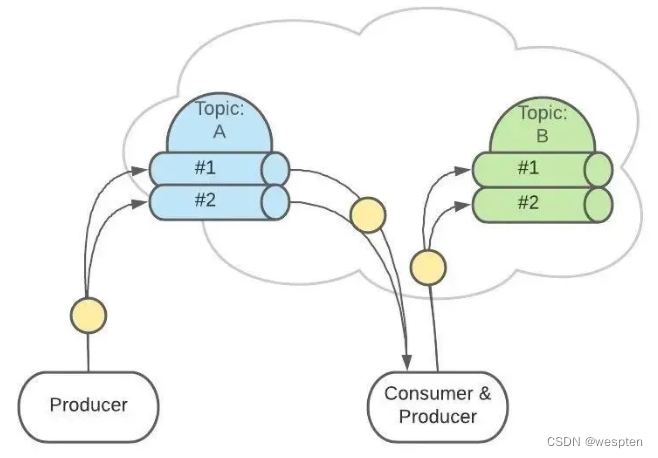
这是逻辑上的形式,但在 Kafka 集群中的实际存储可能是这样的:
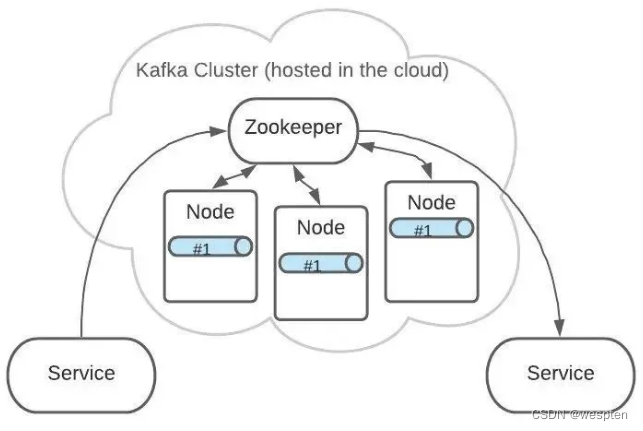
Topic A 的 Partition #1 有3份,分布在各个 Node 上。
这样可以增加 Kafka 的可靠性和系统弹性。
3个 Partition #1 中,ZooKeeper 会指定一个 Leader,负责接收生产者发来的消息。
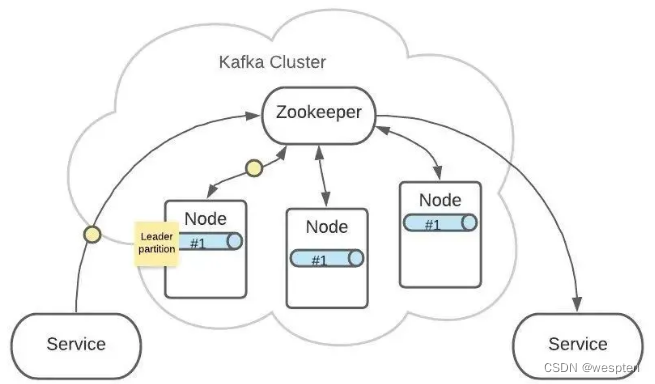
其他2个 Partition #1 会作为 Follower,Leader 接收到的消息会复制给 Follower。

这样,每个 Partition 都含有了全量消息数据。

即使某个 Node 节点出现了故障,也不用担心消息的损坏。
Topic A 和 Topic B 的所有 Partition 分布可能就是这样的:

⑦ ISR(同步副本集)
ISR:同步的副本集合,维护当前还在存活办事的副本,由于数据可靠性的选择,解决防止当一个副本出现问题时候,不能正常的返回ack。
维护ISR的原理:维护是由ZK 完成的,一般的判断断线是:心跳与数据备份量。
如果是根据数据的备份量:leader和副本数据相差一定条数,则就认为副本节点断开,然后从isr移除,当数据备份跟的上来,然后又重新加入到ISR集合。
心跳:一定的时间没有进行心跳。 超过配置时间,则认为断开连接,从ISR中移除当心跳跟的上,在进入ISR集合。
kafka是个高吞吐的消息队列, 发送数据的时候,有批量发送的功能,每次发数据的可以发送大量的数据,这个是可配的。 所以如果根据条数,则副本节点会经常性的从ISR移除和加入。 因为这种考虑,kafka的开发者,选择使用根据时间来判断。
其中控制批量发送的条数就是: BatchNumMessages(可通过生产者代码对接中找到):当内存的数据条数达到了,立刻马上发送到Broker
5、kafka是如何保证消息的有序性
Kafka比传统的消息系统有着更强的顺序保证。在传统的情况下,服务器按照顺序保留消息到队列,如果有多个consumer来消费队列中的消息,服务器 会接受消息的顺序向外提供消息。但是,尽管服务器是按照顺序提供消息,但是消息传递到每一个consumer是异步的,这可能会导致先消费的 consumer获取到消息时间可能比后消费的consumer获取到消息的时间长,导致不能保证顺序性。这表明,当进行并行的消费的时候,消息在多个 consumer之间可能会失去顺序性。消息系统通常会采取一种“ exclusive consumer”的概念,来确保同一时间内只有一个consumer能够从队列中进行消费,但是这实际上意味着在消息处理的过程中是不支持并行的。
Kafka在这方面做的更好。通过Topic中并行度的概念,即partition,Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡。实现的原理是通过将一个topic中的partition分配给一个consumer group中的不同consumer instance。通过这种方式,我们可以保证一个partition在同一个时刻只有一个consumer instance在消息,从而保证顺序。虽然一个topic中有多个partition,但是一个consumer group中同时也有多个consumer instance,通过合理的分配依然能够保证负载均衡。需要注意的是,一个consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。通常来说,这已经可以满足大部分应用的需求。但是,如果的确有在总体上保证消费的顺序的需求的话,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1。
kafka这样保证消息有序性的:一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个(全局有序性)。
写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
大家可以看下消息队列的有序性是怎么推导的:
消息的有序性,就是指可以按照消息的发送顺序来消费。有些业务对消息的顺序是有要求的,比如先下单再付款,最后再完成订单,这样等。假设生产者先后产生了两条消息,分别是下单消息(M1),付款消息(M2),M1比M2先产生,如何保证M1比M2先被消费呢。
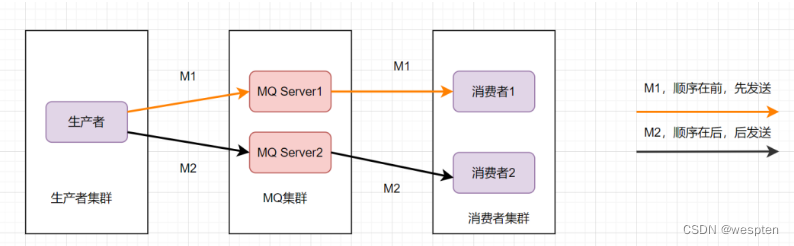
为了保证消息的顺序性,可以将将M1、M2发送到同一个Server上,当M1发送完收到ack后,M2再发送。如图:
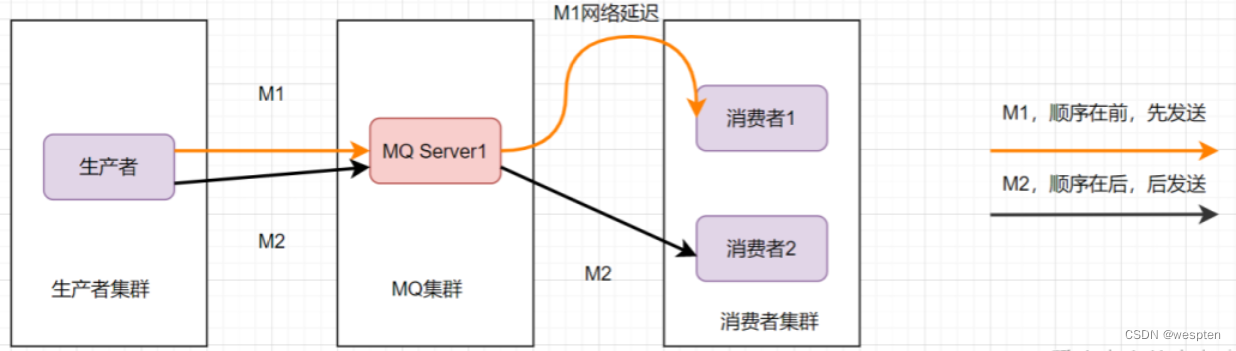
这样还是可能会有问题,因为从MQ服务器到服务端,可能存在网络延迟,虽然M1先发送,但是它比M2晚到。
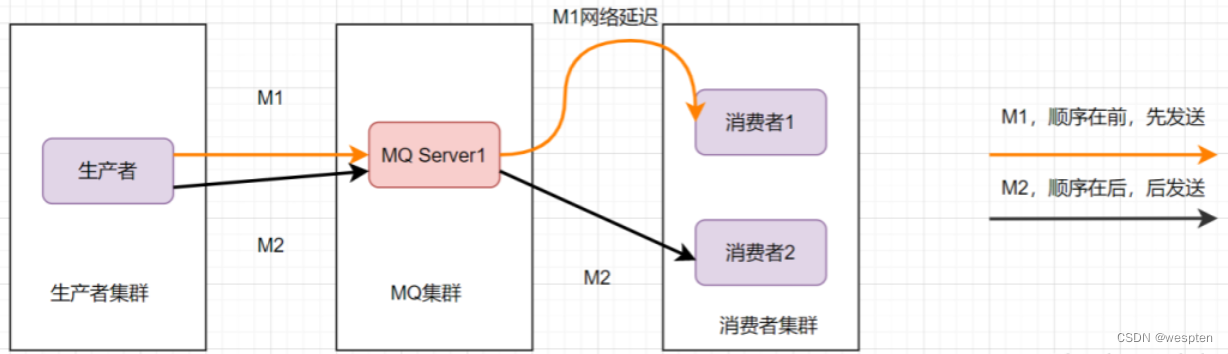
那还能怎么办才能保证消息的顺序性呢?将M1和M2发往同一个消费者,且发送M1后,等到消费端ACK成功后,才发送M2就得了。

消息队列保证顺序性整体思路就是这样啦。比如Kafka的全局有序消息,就是这种思想的体现: 就是生产者发消息时,1个Topic只能对应1个Partition,一个 Consumer,内部单线程消费。
但是这样吞吐量太低,一般保证消息局部有序即可。在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。然后多消费者单线程消费指定的Partition
6、Kafka数据的可靠性
数据的可靠性就是保证数据能写入Broker,并且在Broker宕机后重新选举出来的Leader也不会导致数据的丢失,这样就关系到了ACK的返回机制。
以下是Kafka的数据写入流程:
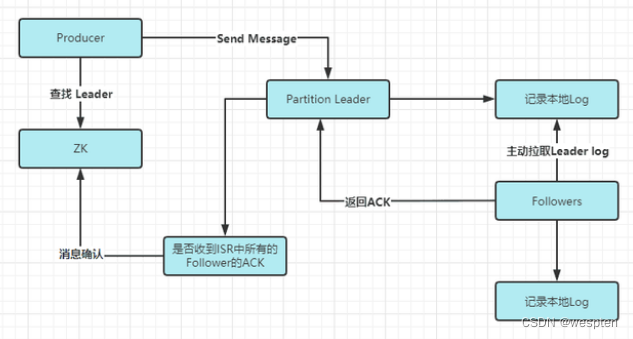
对于ACK的返回策略有两种:1. 半数以上的Follower完成同步返回ACK ,2. 全部的Follower完成同步返回ACK。
以下是ACK的优缺点对比:
系统提供的ACK 设置有三种:-1,0, 1。默认设置是0。
① ACKS为0
Broker接收到数据立刻返回到生产者ACK,并且在数据做持久化之前。如下图:

优点:性能最高。
缺点:丢失数据概率也最大。当Leader接收到数据,但是还没有持久化时宕机,会导致数据的丢失。
使用场景:日志系统,IOT设备状态信息上传。
② ACKS为1
Broker接收到数据并且做完持久化落盘后返回到生产者ACK。如下图:
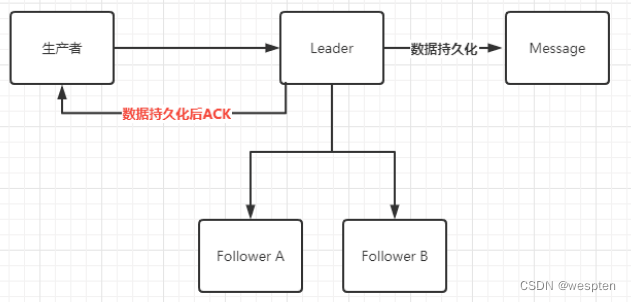
优点:性能中等。
缺点:有丢失数据概率也最大。当Leader接收到数据,。持久化后,没有做Follower Leader宕机。新的Follower 没有更新下Leader最新数据,然后选举成了Leader。只有通过人工介入找回数据。
使用场景:暂没发现。
③ ACKS为-1
Leader和所有的Follower全部落盘成功后返回ACK。
优点:数据不会丢失。
缺点:
-
导致新的问题爆出,幂等性问题。导致幂等性问题的原因为:当数据都备份完成,要返回ACK时候leader宕机,新的副本替代成为Leader,生产者因为没有收到ACK,所以补偿重试,再次发送信息导致数据重复。
-
性能比较低下,原因为:1. 数据的备份。2. 如果加入幂等性,服务端会验证数据的唯一性。
-
使用场景:使用不多。
最后Kafka选用了全部完成发送ACK。
从较高的层面上来说的话,Kafka提供了以下的可靠性保证:
发送到一个Topic中的message会按照发送的顺序添加到commit log中。意思是,如果消息 M1,M2由同一个producer发送,M1比M2发送的早的话,那么在commit log中,M1的offset就会commit 2的offset小。
一个consumer在commit log中可以按照发送顺序来消费message,如果一个topic的备份因子( replication factor )设置为N,那么Kafka可以容忍N-1一个服务器的失败,而存储在commit log中的消息不会丢失。
7、Kafka高效的原理
1)批量发送
生产者发送数据是批量的。
生产者在进行数据的写入的时候,会有两个线程在维护,a.写数据的线程,b.后台线程。a.线程负责把数据写入到生产者维护的缓存区中。b.线程负责把缓存区的数据写入到Kafka 中。

而控制b线程进入Kafka的变量就是: LingerMs = 10000, 时间以毫秒为单位 BatchNumMessages = 2, 字节数,以上条件有一个就满足则立马写入Kafka节点中。
消费端消费数据的时候是批量的。
2)顺序读写
大数据处理一般都是做的顺序读写:
增:顺序写入就可以。
修改:也是顺序的写入,后台线程会去处理,合并修改的数据。
删除:也是顺序的写入,后台线程会去处理,合并删除的数据。
所以,这类数据处理适合处理大量写入的数据,少了修改和删除的数据,因为这样会降低数据处理性能,并且修改,删除的数据处理也会有延时。
3)零拷贝
传统的数据处理是:三次数据的拷贝:磁盘->内核->用户进程->内核 ,目的就是为了保证资源的安全性。以下是示意图:
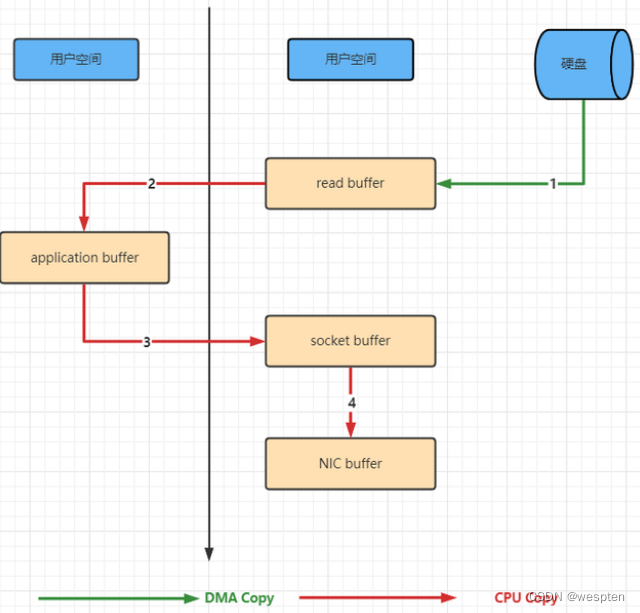
是由Linux 系统实现的一 种快捷的方式。减少了内核到用户,用户到内核的两次拷贝。如下图:
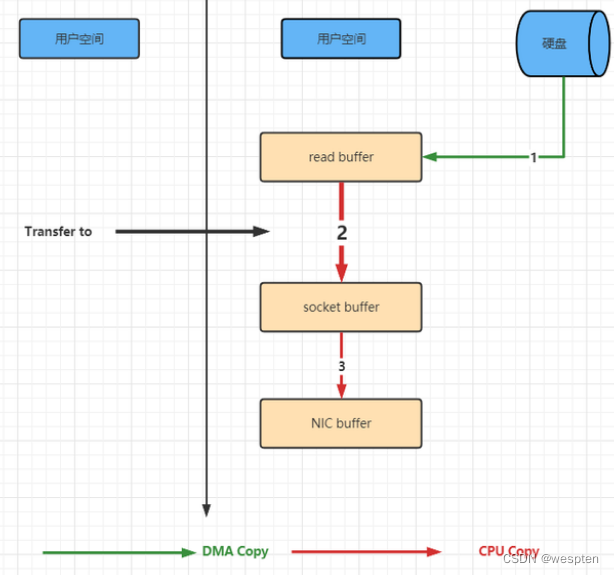
8、Kafka核心API
Kafka有四个核心API:
-
Producer API(生产者API)允许应用程序发布记录流至一个或多个kafka的topics(主题)。
-
Consumer API(消费者API)允许应用程序订阅一个或多个topics(主题),并处理所产生的对他们记录的数据流。
-
Streams API(流API)允许应用程序充当流处理器,从一个或多个topics(主题)消耗的输入流,并产生一个输出流至一个或多个输出的topics(主题),有效地变换所述输入流,以输出流。
-
Connector API(连接器API)允许构建和运行kafka topics(主题)连接到现有的应用程序或数据系统中重用生产者或消费者。例如,关系数据库的连接器可能捕获对表的每个更改。
在Kafka中,客户端和服务器之间的通信是通过简单,高性能,语言无关的TCP协议完成的。此协议已版本化并保持与旧版本的向后兼容性。Kafka提供Java客户端,但客户端有多种语言版本。
1)Producer/Consumer API
当 event source 为普通应用程序时,可以在程序中引入 Producer API 和 Consumer API 来完成与 broker 的交互。这些 API 涵盖了大部分主流语言,例如 Java、Scala、Go、Python、C/C++,除此之外,我们也可以直接使用 REST API 调用。
生产者对接代码
public static async Task Produce(string brokerlist, string topicname, string content)
{
string brokerList = brokerlist;
string topicName = topicname;
var config = new ProducerConfig
{
BootstrapServers = brokerList,
Acks = Acks.All,
// 幂等性,保证不会丢数据。
EnableIdempotence = true,
//信息发送完,多久数据发送到broker里面。
LingerMs = 10000,
BatchNumMessages = 2,//字节数
// 只要上面的两个要求符合一个,则后台线程立刻马上把数据推送给broker
// 可以看到发送的偏移量,如果没有偏移量,则就是没有写成功
MessageSendMaxRetries = 3,//补偿重试,发送失败了则重试
// Partitioner = Partitioner.Random
};
using (var producer = new ProducerBuilder<string, string>(config).Build())
{
try
{
var deliveryReport = await producer.
ProduceAsync(
topicName, new Message<string, string> { Key = (new Random().Next(1, 10)).ToString(), Value = content });
Console.WriteLine($"delivered to: {deliveryReport.TopicPartitionOffset}");
}
catch (ProduceException<string, string> e)
{
Console.WriteLine($"failed to deliver message: {e.Message} [{e.Error.Code}]");
}
}
}注意:
-
生产端写ack ,消费端不需要。
-
ACK 保证数据不丢失但是会影响到我们性能。越高级别数据不丢失,则写入的性能越差。
-
建议使用异步,性能比较好。
-
ProduceAsync 中的Key:Key 注意是做负载均衡,比如,有三个节点,一个topic,创建了三个分区。一个节点一个分区,如果写入的数据的时候,没有写key,会导致,所有的数据存放到一个分区上面。如果用了分区,必须要写key .根据自己的业务,可以提前配置好。key的随机数,可以根据业务,搞一个权重,如果节点的资源不一样,合理利用资源。
-
数据写入如果默认一个分区,则是有顺序,如果是多个分区,则不能保证数据的顺序。
生产者事务对接代码
如果发送的消息的Topic,是在多个分区,需要用事务的模式来保证多个分区的幂等性。 示例如下:
string brokerList = "192.168.1.2:9092,192.168.1.3:9093,192.168.1.4:9094";
// 不同的topic的testtransactionalId就不同
string topicName = "test";
// 不一样的topic,transactionalId就写的不一样。。
string transactionalId = "transtest1";
var config = new ProducerConfig
{
BootstrapServers = brokerList,
EnableIdempotence = true,
Acks = Acks.All,
TransactionalId = transactionalId,
};
using (var producer = new ProducerBuilder<string, string>(config).Build())
{
try
{
//初始化事务
producer.InitTransactions(DefaultTimeout);
var currentState = ProducerState.InitState;
producer.BeginTransaction();
for (int i = 100; i < 110; i++)
{
var content = i.ToString();
producer.Produce(
topicName, new Message<string, string> { Key = content, Value = content });
}
//提交
producer.CommitTransaction(DefaultTimeout);
}
catch (Exception ex)
{
//回滚
producer.AbortTransaction(DefaultTimeout);
Console.WriteLine(ex.Message);
}
}如果:写入数据有一个 节点的Leader 失败,就会自动的通知其他的Leader 做书的回滚。
消费者对接代码
消费者:有两种方式,一种是推送,一种是拉去。
1. 推送
kafka主动去推数据,如果遇到高并发的时候,可能消费端还没有把之前的数据处理完,然后强推了大量的数据过来,有可能造成我们消费端的挂机。
2. 拉取
消费端主动的去拉取,可能存在数据延迟消费,不会造成我们消费端的宕机,同样的存在一个微循环,不停的拉取数据。
kafka 选取的是拉取的模式去消费数据。对比同样的MQ ,rabbitmq 则,既可以使用拉取,也可以使用推送(推送的时候可以设置限流的方式)的方式去消费。
3. 消费的偏移量Offset
0.9版本之前的编译量是由Zookeeper保存的维护的。
0.9版本之后是由自己维护(topic: __consumer_offsets)的。
public static void Run_Consume(string brokerList, List<string> topics, string group)
{
var config = new ConsumerConfig
{
BootstrapServers = brokerList,
GroupId = group,
// 有些属性可以写,但是没有用到
//Acks = Acks.All,
//消费方式自动提交
EnableAutoCommit = false,
//消费模式
AutoOffsetReset = AutoOffsetReset.Earliest,
//EnablePartitionEof = true,
//PartitionAssignmentStrategy = PartitionAssignmentStrategy.Range,
//FetchMaxBytes =,
//FetchWaitMaxMs=1,
//代表数据超过了6000没有处理完业务,则把数据给其他消费端
//一定要注意。SessionTimeoutMs值一定要小于MaxPollIntervalMs
SessionTimeoutMs = 6000,
MaxPollIntervalMs = 10000,
};
const int commitPeriod = 1;
//提交偏移量的时候,也可以批量去提交
using (var consumer = new ConsumerBuilder<Ignore, string>(config).SetErrorHandler((_, e) => Console.WriteLine($"Error: {e.Reason}")).SetPartitionsAssignedHandler((c, partitions) =>
{
//自定义存储偏移量
//1.每次消费完成,把相应的分区id和offset写入到mysql数据库存储
//2.从指定分区和偏移量开始拉取数据
//分配的时候调用
Console.WriteLine($"Assigned partitions: [{string.Join(", ", partitions)}]");
#region 指定分区消费
// 之前可以自动均衡,现在不可以了
//List<TopicPartitionOffset> topics = new List<TopicPartitionOffset>();
我当前读取所有的分区里面的从10开始
//foreach (var item in partitions)
//{
// topics.Add(new TopicPartitionOffset(item.Topic, item.Partition, new Offset(10)));
//}
//return topics;
#endregion
}) .SetPartitionsRevokedHandler((c, partitions) =>
{
//新加入消费者的时候调用
Console.WriteLine($"Revoking assignment: [{string.Join(", ", partitions)}]");
}).Build())
{
//消费者会影响在平衡分区,当同一个组新加入消费者时,分区会在分配
consumer.Subscribe(topics);
try
{
// 死循环 拉取模式
while (true)
{
try
{
var consumeResult = consumer.Consume();
if (consumeResult.IsPartitionEOF)
{
continue;
}
Console.WriteLine($": {consumeResult.TopicPartitionOffset}::{consumeResult.Message.Value}");
if (consumeResult.Offset % commitPeriod == 0)
{
try
{
//提交偏移量,数据自己已经处理完成了
consumer.Commit(consumeResult);
}
catch (KafkaException e)
{
Console.WriteLine($"Commit error: {e.Error.Reason}");
}
}
}
catch (ConsumeException e)
{
Console.WriteLine($"Consume error: {e.Error.Reason}");
}
}
}
catch (OperationCanceledException)
{
Console.WriteLine("Closing consumer.");
consumer.Close();
}
}
}
//调用方式
Consumer("192.168.1.10:9092,192.168.1.11:9093,192.168.1.12:9094", "test", "groupname");说明:
-
自动ACK:Acks = Acks.All 标记是无效的
-
消费提交:EnableAutoCommit = false,自动提交服务端数据已经消费,服务端标记本数据为。一般设置为:false。如果设置成True自动提交,在接收到数据后处理过程出现异常,会导致无法重复消费这个数据,丢失。如设置成false,可能导致数据的重复消费,比如手动提交时候服务器断开。重新连接后重复消费,解决办法就是:发送消息加上一个唯一ID,消费了就加入到Redis 中,下次来了判断数据是否消费过,没消费就重新消费,消费了就提交。
-
消费模式:AutoOffsetReset:AutoOffsetReset.Latest 即:0,表示消费者消费启动之后的数据。启动之前的服务端还没消费的数据消费不到。AutoOffsetReset.Earliest = 1,每次都从头开始消费没有消费过的数据(推荐模式)。AutoOffsetReset.Error = 2.。报错后无法消费。
-
消费端:组和组之间是广播模式,组内是根据分区数量。多个客户端去消费,如果是组相同则自动做负载均衡,开启的消费的相同组客户端最大数量等于分区的数量,开启多出来的客户端消费不到数据。重新连接新的组则从新的消费该组没有消费的数据与别的组消费数据无关。 原则上是:topic的数量=broker的数量,broker数量=分区数量,分区数量=一个组内的消费者数量。
异常情况消费
当Leader offset 为8 宕机 Follow1 offset 为7 Follow2 offset 为6 Follow2选择为Leader 。消费数据的时候是能从8 消费的,但是Follow2 最为主节点时候,没有8 。这种情况Kafka是这样处理的。
Kafka使用的 LEO和HW的机制去处理的。
LEO:指的是每个副本最大的 offset。
HW:指的是消费者能见到的最大的 offset,ISR队列中最小的 LEO。
这样就保证了消费者看到的是全部备份完的的偏移量了。
高级消费
如果当前超过时间没有消费完成,则返回给另一个分区去消费,以下是设置参数。
SessionTimeoutMs = 6000
MaxPollIntervalMs = 10000注意: MaxPollIntervalMs的值必须大于等于SessionTimeoutMs
上面类似心跳,如果消费水平太慢,则会引起重新分配
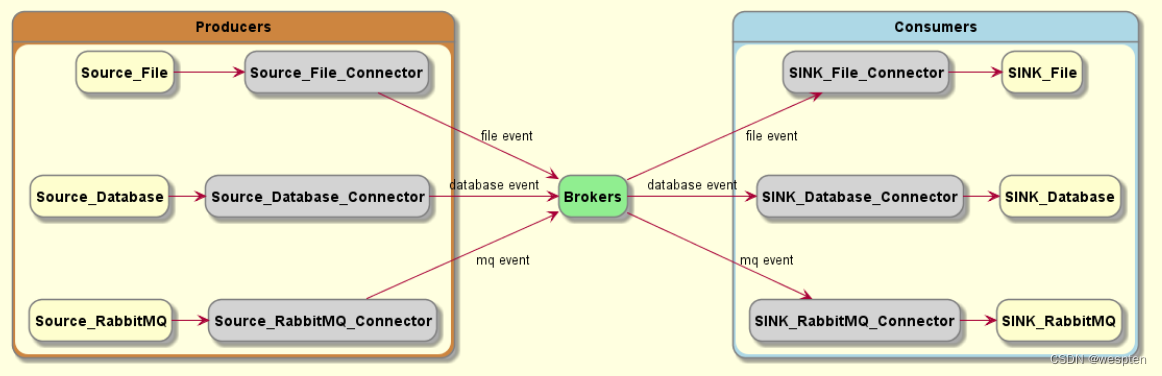
2)Connector
但是,并不是所有 source 或 sink 都能使用 API 的方式,例如,实时捕获数据库的更改、文件的更改,从 RabbitMQ 导入导出消息等等。
这个时候就需要使用 connector 来完成集成。通常情况下,connector 并不需要我们自己开发,kafka 社区为我们提供了大量的 connector 来满足我们的使用需求。
接下来我们再来补充下 broker 的一些细节。
3) topic&partition
通常情况下,我们的 broker 会接收到很多不同类型的 event ,broker 需要区分它们,以便正确地路由。topic 就发挥了作用,它有点类似文件系统的目录,而 event 就类似于目录里的文件,sink 想要什么 event,只要找到对应的 topic 就行了。
同一 topic 可以有零个或多个 producer 和 consumer,不同于传统 MQ,kafka 的 event 消费后并不删除,为什么这么做呢?这个我们后续的博客会说的。

除此之外,一个 topic 会划分成一个或多个 partition,这些 partition 一般分布在不同的 broker 实例。producer 发布的 event 会根据某种策略分配到不同的 partition,这样做的好处是,consumer 可以同时从多台 broker 读取 event,从而大大提高吞吐量。另外,为了高可用,同一个 partition 还会有多个副本,它们分布在不同的 broker 实例。
需要注意一下,当同一 topic 的 event 被分发到多个 partition 时,写入和读取的顺序就不能保证了,对于需要严格控制顺序的 topic,partition 需要设置为 1。
分区的原因:
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了。
(2)可以提高并发,因为可以以Partition为单位读写了。
分区的原则:
(1)指定了patition,则直接使用。
(2)未指定patition但指定key,通过对key的value进行hash出一个patition。
(3)patition和key都未指定,使用轮询选出一个patition。
DefaultPartitioner类:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}4)Streams
kafka 那么受欢迎,还有一个很重要的原因,就是它提供了流式处理类库,支持对存储于Kafka内的数据进行流式处理和分析。

Kafka Streams被认为是开发实时应用程序的最简单方法。它是一个Kafka的客户端API库,编写简单的java和scala代码就可以实现流式处理。
优势:
-
弹性,高度可扩展,容错
-
部署到容器,VM,裸机,云
-
同样适用于小型,中型和大型用例
-
与Kafka安全性完全集成
-
编写标准Java和Scala应用程序
-
在Mac,Linux,Windows上开发
-
Exactly-once 语义
使用场景:
纽约时报使用Apache Kafka和Kafka Streams将发布的内容实时存储和分发到各种应用程序和系统,以供读者使用。
Pinterest大规模使用Apache Kafka和Kafka Streams来支持其广告基础架构的实时预测预算系统。使用Kafka Streams,预测比以往更准确。
作为欧洲领先的在线时尚零售商,Zalando使用Kafka作为ESB(企业服务总线),帮助我们从单一服务架构转变为微服务架构。使用Kafka处理 事件流使我们的技术团队能够实现近乎实时的商业智能。
荷兰合作银行是荷兰三大银行之一。它的数字神经系统Business Event Bus由Apache Kafka提供支持。它被越来越多的财务流程和服务所使用,其中之一就是Rabo Alerts。此服务会在财务事件时实时向客户发出警报,并使用Kafka Streams构建。
LINE使用Apache Kafka作为我们服务的中央数据库,以便彼此通信。每天产生数亿亿条消息,用于执行各种业务逻辑,威胁检测,搜索索引和数据分析。LINE利用Kafka Streams可靠地转换和过滤主题,使消费者可以有效消费的子主题,同时由于其复杂而简单的代码库,保持易于维护性。
Topology:
Kafka Streams通过一个或多个拓扑定义其计算逻辑,其中拓扑是通过流(边缘)和流处理器(节点)构成的图。
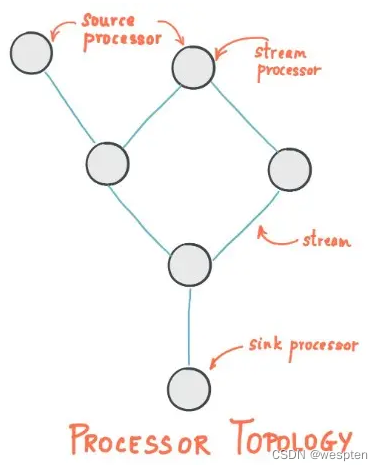
拓扑中有两种特殊的处理器
- 源处理器:源处理器是一种特殊类型的流处理器,没有任何上游处理器。它通过使用来自这些主题的记录并将它们转发到其下游处理器,从一个或多个Kafka主题为其拓扑生成输入流。
- 接收器处理器:接收器处理器是一种特殊类型的流处理器,没有下游处理器。它将从其上游处理器接收的任何记录发送到指定的Kafka主题。
在正常处理器节点中,还可以把数据发给远程系统。因此,处理后的结果可以流式传输回Kafka或写入外部系统。
Kafka在这当中提供了最常用的数据转换操作,例如map,filter,join和aggregations等,简单易用
当然还有一些关于时间,窗口,聚合,乱序处理等。
5)文件储存机制
文件的架构:通过小文件的不断合并最后转成了一个大文件。
结构如图:

保存文件的结构:
000000000000000000000000.log
000000000000000000000000.index
000000000000000000000700.log
000000000000000000000700.index
000000000000000000002000.log
000000000000000000002000.index注意:log文件和index 文件是成对出现的,000000000000000000000000.log 保存的是 0-699 的数据。
数据的查找:通过文件的名字,使用的二分发做的查找。
如下图:
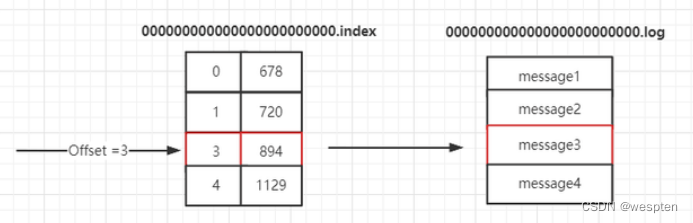
注意:除了爆露出来的偏移量之外,Kafka 内部还key值对应与log文件中。
日志的压缩策略
kafka定期将相同key的消息进行合并,只保留最新的value值。
保存的每一条数据,会记录是增加,删除,还是修改。
自定义存储
自定义存储(解决重复消费)
-
每次消费完成,把相应的分区和offset写入到mysql数据库。
-
从指定分区和偏移量开始拉取数据。
.SetPartitionsAssignedHandler((c, partitions) =>
{ //获取mysql存储结果,从当前开始获取
foreach (var item in partitions)
{ topics.Add(new TopicPartitionOffset(item.Topic, item.Partition, new Offset(10))); } }) consumer.Assign(topics.Select(topic => new TopicPartitionOffset(topic, 1, Offset.Beginning)).ToList());总结:
-
消费者一般使用workservice。
-
消费端只关心topic和偏移量,其余不关心。
-
保留7天,kafka可以配置。默认7天,消息积压有处理。
-
消费数据先消费Leader的。
9、kafka使用场景
1)消息Messaging
Kafka可以替代更传统的消息代理。消息代理的使用有多种原因(将处理与数据生成器分离,缓冲未处理的消息等)。与大多数消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和容错功能,这使其成为大规模消息处理应用程序的理想解决方案。
根据经验,消息传递的使用通常相对较低,但可能需要较低的端到端延迟,并且通常取决于Kafka提供的强大的耐用性保证。
在这个领域,Kafka可与传统的消息传递系统(如ActiveMQ或 RabbitMQ)相媲美。
2)网站活动跟踪
Kafka的原始用例是能够将用户活动跟踪管道重建为一组实时发布 - 订阅源。这意味着站点活动(页面查看,搜索或用户可能采取的其他操作)将发布到中心主题,每个活动类型包含一个主题。这些源可用于订购一系列用例,包括实时处理,实时监控以及加载到Hadoop或离线数据仓库系统以进行脱机处理和报告。
活动跟踪通常非常高,因为为每个用户页面视图生成了许多活动消息。Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
3)度量Metrics
Kafka通常用于运营监控数据。这涉及从分布式应用程序聚合统计信息以生成操作数据的集中式提要。
4)日志聚合
可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
日志聚合通常从服务器收集物理日志文件,并将它们放在中央位置(可能是文件服务器或HDFS)进行处理。Kafka抽象出文件的细节,并将日志或事件数据作为消息流更清晰地抽象出来。这允许更低延迟的处理并更容易支持多个数据源和分布式数据消耗。与Scribe或Flume等以日志为中心的系统相比,Kafka提供了同样出色的性能,由于复制而具有更强的耐用性保证,以及更低的端到端延迟。
5)流处理
许多Kafka用户在处理由多个阶段组成的管道时处理数据,其中原始输入数据从Kafka主题中消费,然后聚合,丰富或以其他方式转换为新主题以供进一步消费或后续处理。
例如,用于推荐新闻文章的处理管道可以从RSS订阅源抓取文章内容并将其发布到“文章”主题; 进一步处理可能会对此内容进行规范化或重复数据删除,并将已清理的文章内容发布到新主题; 最终处理阶段可能会尝试向用户推荐此内容。此类处理管道基于各个主题创建实时数据流的图形。从0.10.0.0开始,这是一个轻量级但功能强大的流处理库,名为Kafka Streams 在Apache Kafka中可用于执行如上所述的此类数据处理。除了Kafka Streams之外,其他开源流处理工具包括Apache Storm和 Apache Samza。
6)Event Sourcing
Event Sourcing是一种应用程序设计风格,其中状态更改记录为按时间排序的记录序列。Kafka对非常大的存储日志数据的支持使其成为以这种风格构建的应用程序的出色后端。
7)提交日志
Kafka可以作为分布式系统的一种外部提交日志。该日志有助于在节点之间复制数据,并充当故障节点恢复其数据的重新同步机制。Kafka中的日志压缩功能有助于支持此用法。在这种用法中,Kafka类似于Apache BookKeeper项目。
8)运营指标
Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。

四、Kafka安装配置
1、Kafka下载
到官网Apache Kafka下载想要的版本。
注:由于Kafka控制台脚本对于基于Unix和Windows的平台是不同的,因此在Windows平台上使用bin\windows\ 而不是bin/ 将脚本扩展名更改为.bat。
[root@along ~]# wget http://mirrors.shu.edu.cn/apache/kafka/2.1.0/kafka_2.13-3.2.1.tgz
[root@along ~]# tar -C /data/ -xvf kafka_2.13-3.2.1.tgz
[root@along ~]# cd /data/kafka_2.11-2.1.0/请注意,有多个可下载的Scala版本,我们选择使用推荐的版本(2.13):
由于Kafka是用Scala语言开发的,运行在JVM上,因此在安装Kafka之前需要先安装JDK。
# yum install java-1.8.0-openjdk* -y进入到解压目录,我们看看 kafka 的目录结构:
接下来,我们启动broker的部分,需要先按照顺序依次启动 zookeeper 和 kafka server。
2、配置启动zookeeper
kafka正常运行,必须配置zookeeper,否则无论是kafka集群还是客户端的生存者和消费者都无法正常的工作的;所以需要配置启动zookeeper服务。
zookeeper一般建议为奇数个(2n+1),方便快速投票和选举,半数以上的才可以选出主机
搭建伪集群, 在同一个Linux中安装三个 ZooKeeper实例。 使用不同的端口实现同时启动。 端口分配如下:
| 主机 | 服务端口 | 投票端口 | 选举端口 |
|---|---|---|---|
| 192.168.159.130 | 2181 | 2881 | 3881 |
| 192.168.159.130 | 2182 | 2882 | 3882 |
| 192.168.159.130 | 2182 | 2882 | 3882 |
1)解压缩
# wget http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz
# tar -zxvf zookeeper-3.4.12.tar.gz
# cd zookeeper-3.4.122)复制配置文件
在zookeeper解压后的conf目录中,把zoo_sample.cfg给复制一份并且名字为zoo.cfg,这是因为zoo_sample.cfg只是配置模板,需要我们以这个模板为基础创建zoo.cfg,并且zookeeper真正读取的是zoo.cfg文件。
# cd zookeeper-3.4.12
# cp conf/zoo_sample.cfg conf/zoo.cfg3)创建 data 数据目录
因为在 zookeeper 中需要临时的数据目录,故在解压后的文件夹中创建文件夹 data目录:
mkdir data另外,需要在每个Zookeeper 应用内的 data目录中增加文件myid,内部定义每个服务的编号. 编号要求为数字,是正整数可以使用回声命名快速定义 myid 文件,这个文件的名字必须是myid,其他的话会启动失败:
echo 1 > myid4)编写Zookeeper配置文件
修改data数据目录的路径,clientPort=2181客户端访问端口,因此三个zookeeper 实例不能端口相同。还需要如下配置:
1. server.服务的编号=IP:投票端口:选举端口。
2. 服务器编号:表示这是第几号服务器
3. 投票端口:是这个服务器与集群中的Leader服务器交换信息的端口,用于决定正在运行的主机是否宕机。
4. 选举端口:如果集群中的Leader服务器挂了,用于决定哪一个 Zookeeper服务作为主机。
三个Zookeeper应用配置一致。
vi /usr/local/solrcloude/zookeeper1/conf/zoo.cfg
server.1=192.168.120.132:2881:3881
server.2=192.168.120.132:2882:3882
server.3=192.168.120.132:2883:38835)复制两份同样的Zookeeper
cp zookeeper1 zookeeper2 -r
cp zookeeper1 zookeeper3 -r复制后,要修改zoo.cfg。
6)启动 Zookeeper测试
要至少启动两个 Zookeeper 启动,启动单一Zookeeper,无法正常提供服务。
# 启动
zookeeper1/bin/zkServer.sh start conf/zoo.cfg &
bin/zkCli.sh
# 查看状态
zookeeper1/bin/zkServer.sh status7)操作zkClinet
zkCli.sh 进入zookeeper客户端,根据提示命令进行操作:
查找(只能是绝对路径):
ls / ls /zookeeper创建并赋值:
create /bhz hadoop获取:
get /bhz设值:
set /bhz baihezhuo可以看到zookeeper集群的数据一致性,创建节点有俩种类型:短暂(ephemeral)和持久(persistent)。
8)zoo.cfg详解
tickTime: 基本事件单元,以毫秒为单位。这个时间是作为 Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔 tickTime时间就会发送一个心跳。
dataDir: 存储内存中数据库快照的位置,顾名思义就是 Zookeeper保存数据的目录,默认情况下, Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort: 这个端口就是客户端连接 Zookeeper服务器的端口, Zookeeper会监听这个端口,接受客户端的访问请求。
initLimit: 这个配置项是用来配置 Zookeeper接受客户端初始化连接时最长能忍受多少个心跳时间间隔数,当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20 秒。
syncLimit: 这个配置项标识Leader 与Follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
9)observer模式配置
该模式运行的zookeeper
- 不参与选举,
- 不参与数据事务提交的ack应答
注意:观察者机器数据也是跟集群同步的。
配置很简单:
在任何想变成Observer模式的配置文件(zoo.cfg)中加入如下配置:peerType=observer
并在所有Server的配置文件(zoo.cfg)中,配置成Observer模式的server的那行配置追加:observer,例如:
server.4=192.168.56.101:2164:2174:observer案例:
# observer 机器需要配置
peerType=observer
server.1=192.168.56.101:2161:2171
server.2=192.168.56.101:2162:2172
server.3=192.168.56.101:2163:2173
#所有机器都需要配置这个
server.4=192.168.56.101:2164:2174:observer
3、配置kafka
现在来启动kafka服务,启动脚本语法:
kafka-server-start.sh [-daemon] server.properties可以看到,server.properties的配置路径是一个强制的参数,-daemon表示以后台进程运行,否则ssh客户端退出后,就会停止服务。(注意,在启动kafka时会使用linux主机名关联的ip地址,所以需要把主机名和linux的ip映射配置到本地host里,用vim /etc/hosts)
# bin/kafka-server-start.sh -daemon config/server.properties
我们进入zookeeper目录通过zookeeper客户端查看下zookeeper的目录树
# bin/zkCli.sh
# ls / #查看zk的根目录kafka相关节点
# ls /brokers/ids #查看kafka节点打开另一个会话,再启动 kafka server。
修改配置文件:
[root@along kafka_2.11-2.1.0]# grep "^[^#]" config/server.properties
broker.id=0
listeners=PLAINTEXT://localhost:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
注:可根据自己需求修改配置文件
broker.id:#唯一标识ID
listeners=PLAINTEXT://localhost:9092:#kafka服务监听地址和端口
log.dirs:#日志存储目录
zookeeper.connect:#指定zookeeper服务配置环境变量:
[root@along ~]# vim /etc/profile.d/kafka.sh
export KAFKA_HOME="/data/kafka_2.11-2.1.0"
export PATH="${KAFKA_HOME}/bin:$PATH"
[root@along ~]# source /etc/profile.d/kafka.sh配置服务启动脚本:
[root@along ~]# vim /etc/init.d/kafka
#!/bin/sh
#
# chkconfig: 345 99 01
# description: Kafka
#
# File : Kafka
#
# Description: Starts and stops the Kafka server
#
source /etc/rc.d/init.d/functions
KAFKA_HOME=/data/kafka_2.11-2.1.0
KAFKA_USER=root
export LOG_DIR=/tmp/kafka-logs
[ -e /etc/sysconfig/kafka ] && . /etc/sysconfig/kafka
# See how we were called.
case "$1" in
start)
echo -n "Starting Kafka:"
/sbin/runuser -s /bin/sh $KAFKA_USER -c "nohup $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties > $LOG_DIR/server.out 2> $LOG_DIR/server.err &"
echo " done."
exit 0
;;
stop)
echo -n "Stopping Kafka: "
/sbin/runuser -s /bin/sh $KAFKA_USER -c "ps -ef | grep kafka.Kafka | grep -v grep | awk '{print \$2}' | xargs kill \-9"
echo " done."
exit 0
;;
hardstop)
echo -n "Stopping (hard) Kafka: "
/sbin/runuser -s /bin/sh $KAFKA_USER -c "ps -ef | grep kafka.Kafka | grep -v grep | awk '{print \$2}' | xargs kill -9"
echo " done."
exit 0
;;
status)
c_pid=`ps -ef | grep kafka.Kafka | grep -v grep | awk '{print $2}'`
if [ "$c_pid" = "" ] ; then
echo "Stopped"
exit 3
else
echo "Running $c_pid"
exit 0
fi
;;
restart)
stop
start
;;
*)
echo "Usage: kafka {start|stop|hardstop|status|restart}"
exit 1
;;
esac
4、启动kafka服务
后台启动zookeeper服务:
[root@along ~]# nohup zookeeper-server-start.sh /data/kafka_2.11-2.1.0/config/zookeeper.properties &
启动kafka服务:
[root@along ~]# service kafka start
Starting kafka (via systemctl): [ OK ]
[root@along ~]# service kafka status
Running 86018
[root@along ~]# ss -nutl
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp LISTEN 0 50 :::9092 :::*
tcp LISTEN 0 50 :::2181 :::*
五、Kafka使用
producer 发布的 event 会持久化在对应的topic中,才能路由给正确的consumer。所以,在读写 event 之前,我们需要先创建 topic。
1、创建主题topics
创建一个名为along的主题,它只包含一个分区,只有一个副本:
[root@along ~]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic along
Created topic "along".选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
如果我们运行list topic命令,我们现在可以看到该主题:
[root@along ~]# kafka-topics.sh --list --zookeeper localhost:2181
along除了我们通过手工的方式创建Topic,我们可以配置broker,当producer发布一个消息某个指定的Topic,但是这个Topic并不存在时,就自动创建。
2、发送一些消息
接下来我们用 kafka 自带的 console-consumer 和 console-producer 读写 event。它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。
使用 console-producer 写 event 时,我们每输入一行并回车,就会向 topic 写入一个 event。默认情况下,每行将作为单独的消息发送。
运行生产者,然后在控制台中键入一些消息以发送到服务器。
[root@along ~]# kafka-console-producer.sh --broker-list localhost:9092 --topic along
>This is a message
>This is another message写完之后我们可以按 Ctrl + C 退出。
启动消费者
接着,我们使用 console-consumer 读 event,它会将消息转储到标准输出。可以看到,刚写的 event 被读到了。
[root@along ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic along --from-beginning
This is a message
This is another message读完我们按 Ctrl + C 退出。
我们可以在两个会话中保持 producer 和 consumer 不退出,当我们在 producer 写入 event 时, consumer 将实时读取到。
前面提到过,topic 的 event 会被持久化下来,而且被消费过的 event 并不会删除。这一点很容易验证,我们可以再开一个 consumer 来读取,它还是能读到被别人读过的 event。
以上所有的命令都有一些附加的选项;当我们不携带任何参数运行命令的时候,将会显示出这个命令的详细用法。
还有一些其他命令如下:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --consumer-property client.id=consumer-1 --topic test #新版本查看组名:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list --new-consumer查看消费者的消费偏移量:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroup消费多主题:
# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist "test|test-2"单播消费:
一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可。分别在两个客户端执行如下消费命令,然后往主题里发送消息,结果只有一个客户端能收到消息。
# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test 多播消费:
一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费组即可。我们再增加一个消费者,该消费者属于testGroup-2消费组,结果两个客户端都能收到消息。
# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup-2 --topic test 查看某个topic的详情:
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper localhost:2181 \
--describe --topic test删除topic:
bin/kafka-topics.sh --zookeeper localhost:2181 \
--delete --topic test需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
3、使用Connect导入/导出数据
从控制台写入数据并将其写回控制台是一个方便的起点,但有时候可能希望使用其他来源的数据或将数据从Kafka导出到其他系统,而不是编写自定义集成代码。
有的 source 或 sink 需要依赖 connector 来读写 event,演示如何从已有文件中将 event 导入 topic,并从 topic 中导出到另一个文件中。
Kafka Connect是Kafka附带的工具,用于向Kafka导入和导出数据。它是一个可扩展的工具,运行连接器,实现与外部系统交互的自定义逻辑。我们将了解如何使用简单的连接器运行Kafka Connect,这些连接器将数据从文件导入Kafka主题并将数据从Kafka主题导出到文件。
首先我们需要一个可以导入导出文件的 connector,默认情况下,在 kafka 的 libs 目录就有这样一个 jar 包--connect-file-3.2.1.jar,我们需要在 connect 的配置中引入这个包。
vi config/connect-standalone.properties按 i 进入编辑,添加或修改plugin.path=libs/connect-file-3.2.1.jar。
按 ESC 后输入 :wq 保存并退出。除此之外,这个文件还可以用来配置需要连接哪个 broker,以及 event 的序列化方式等。

然后,我们创建一个 test.txt 作为 event source,并写入 event:
[root@along ~]# echo -e "foo\nbar" > test.txt
或者在Windows上:
> echo foo> test.txt
> echo bar>> test.txt接下来,我们先启动 event source 的 connector,将 test.txt 的 event 写入名为 connect-test 的 topic。config/connect-file-source.properties 已经配置好了connector 名称、event source 的文件、topic等等。
启动两个以独立模式运行的连接器,这意味着它们在单个本地专用进程中运行,提供三个配置文件作为参数。
第一个始终是Kafka Connect流程的配置,包含常见配置,例如要连接的Kafka代理和数据的序列化格式。
其余配置文件均指定要创建的连接器。这些文件包括唯一的连接器名称,要实例化的连接器类以及连接器所需的任何其他配置。
[root@along ~]# connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
[2019-01-16 16:16:31,884] INFO Kafka Connect standalone worker initializing ... (org.apache.kafka.connect.cli.ConnectStandalone:67)
[2019-01-16 16:16:31,903] INFO WorkerInfo values:
... ...注:Kafka附带的这些示例配置文件使用您之前启动的默认本地群集配置并创建两个连接器:第一个是源连接器,它从输入文件读取行并生成每个Kafka主题,第二个是宿连接器从Kafka主题读取消息并将每个消息生成为输出文件中的一行。
执行片刻后我们可以按 Ctrl + C 退出。
检验是否导入成功(另起终端)
在启动过程中,您将看到许多日志消息,包括一些指示正在实例化连接器的日志消息。
- 一旦Kafka Connect进程启动,源连接器应该开始从test.txt主题读取行并将其生成到主题connect-test,并且接收器连接器应该开始从主题读取消息connect-test 并将它们写入文件test.sink.txt。我们可以通过检查输出文件的内容来验证数据是否已通过整个管道传递:
[root@along ~]# cat test.sink.txt
foo
bar这时,我们可以先通过 consumer-console 查看 topic 上是否有这些 event。可以看到,event 已经成功导入。
[root@along ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}请注意,数据存储在Kafka主题中connect-test,因此我们还可以运行控制台使用者来查看主题中的数据(或使用自定义使用者代码来处理它)。
继续追加数据,验证:
[root@along ~]# echo Another line>> test.txt
[root@along ~]# cat test.sink.txt
foo
bar
Another line
[root@along ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
{"schema":{"type":"string","optional":false},"payload":"Another line"4、使用streams处理
首先提供WordCount的java版和scala版本。
java8+:
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}scala:
import java.util.Properties
import java.util.concurrent.TimeUnit
import org.apache.kafka.streams.kstream.Materialized
import org.apache.kafka.streams.scala.ImplicitConversions._
import org.apache.kafka.streams.scala._
import org.apache.kafka.streams.scala.kstream._
import org.apache.kafka.streams.{KafkaStreams, StreamsConfig}
object WordCountApplication extends App {
import Serdes._
val props: Properties = {
val p = new Properties()
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application")
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092")
p
}
val builder: StreamsBuilder = new StreamsBuilder
val textLines: KStream[String, String] = builder.stream[String, String]("TextLinesTopic")
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count()(Materialized.as("counts-store"))
wordCounts.toStream.to("WordsWithCountsTopic")
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
streams.start()
sys.ShutdownHookThread {
streams.close(10, TimeUnit.SECONDS)
}
}如果kafka已经启动了,可以跳过前两步。
1. 启动ZooKeeper服务器:
> bin/zookeeper-server-start.sh config/zookeeper.properties
INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...2. 启动Kafka服务器:
> bin/kafka-server-start.sh config/server.properties
INFO Verifying properties (kafka.utils.VerifiableProperties)
INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...3. 创建topic 启动生产者
我们创建名为streams-plaintext-input的输入主题和名为streams-wordcount-output的输出主题:
> bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".
> bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".查看:
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:1 Configs:cleanup.policy=compact
Topic: streams-wordcount-output Partition: 0 Leader: 0 Replicas: 0 Isr: 04. 启动WordCount
以下命令启动WordCount演示应用程序:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示应用程序将从输入主题stream-plaintext-input读取,对每个读取消息执行WordCount算法的计算,并连续将其当前结果写入输出主题streams-wordcount-output。因此,除了日志条目之外不会有任何STDOUT输出,因为结果会写回Kafka。
现在我们可以在一个单独的终端中启动控制台生成器,为这个主题写一些输入数据:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
并通过在单独的终端中使用控制台使用者读取其输出主题来检查WordCount演示应用程序的输出:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer5. 处理数据
我们在生产者端输入一些数据。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka输出端:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1继续输入:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
hello kafka streams> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2我们看到随着数据实时输入,wordcount的结果实时的输出了。
5、停止Kafka
可以通过Ctrl + C按顺序停止控制台使用者,控制台生产者,Wordcount应用程序,Kafka代理和ZooKeeper服务器。
我们可以通过以下步骤关闭 kafka。
-
如果 producer 或 consumer 还在运行,Ctrl + C 退出;
-
Ctrl + C 退出 kafka server;
-
Ctrl + C 退出 zookeeper;
如果想清除 kafka 的数据,包括我们创建的 topic 和 event、日志等,执行以下命令:
rm -rf /tmp/kafka-logs /tmp/zookeeper /tmp/connect.offsets六、Kafka HA集群
到目前为止,我们一直在与一个broker运行,但这并不好玩。对于Kafka,单个代理只是一个大小为1的集群,因此除了启动一些代理实例之外没有太多变化。但是为了感受它,让我们将我们的集群扩展到三个节点(仍然在我们的本地机器上)。
集群的结构
如下图:
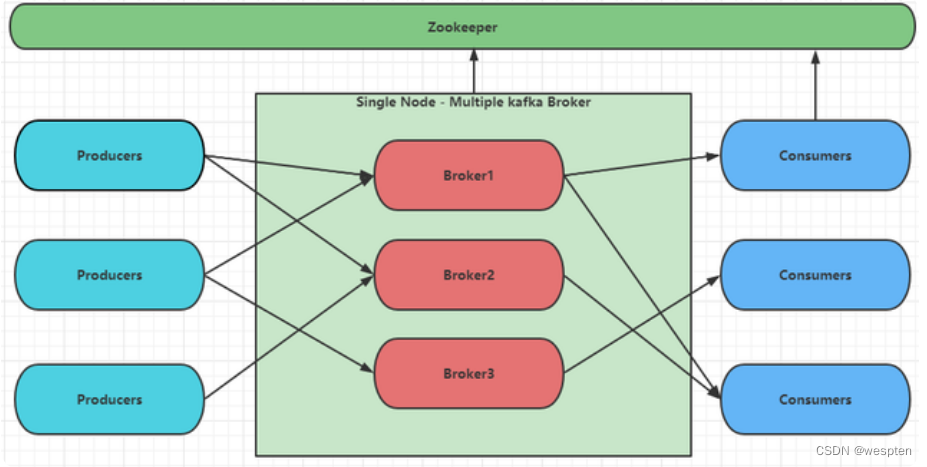
Zookeeper:对kafka选举做集群的节点的选举,可以看作是个数据库,可做分布式锁,可实现强一致性。
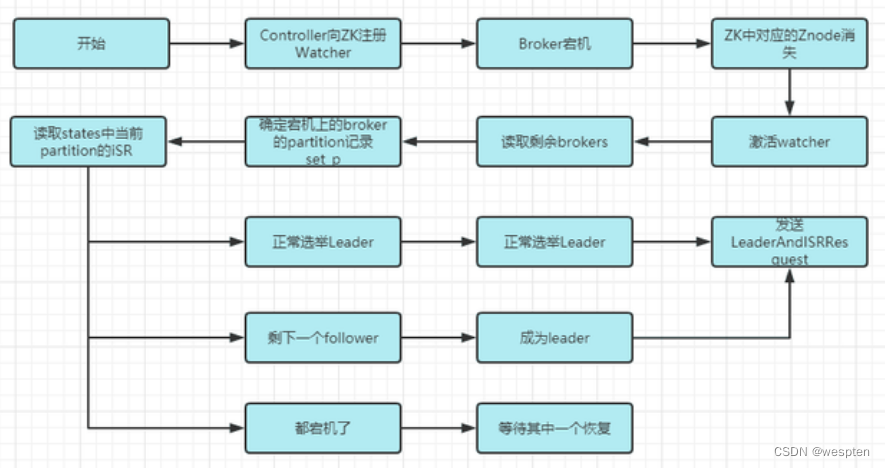
kafka每个节点服务运行后,首先向zk中注册 watcher ,注册成功后watcher就与该节点之间产生心跳,运行一段时间后当主节点宕机后,其对应的zk中的节点注册也会消失。同时激活watcher,读取剩下的所有节点确定宕机的节点的分区与消费信息,然后从剩下的节点中做选举。其中选举有三种情况:
-
正常选举:剩下的节点向ZK 发送指令LeadersandISR,写的快的节点为新的leader。
-
剩下一个节点 ,这个节点直接成为leader。
-
所有节点都宕机,等待其中一个恢复中。
Kafka集群消息管理
以下是示意图:
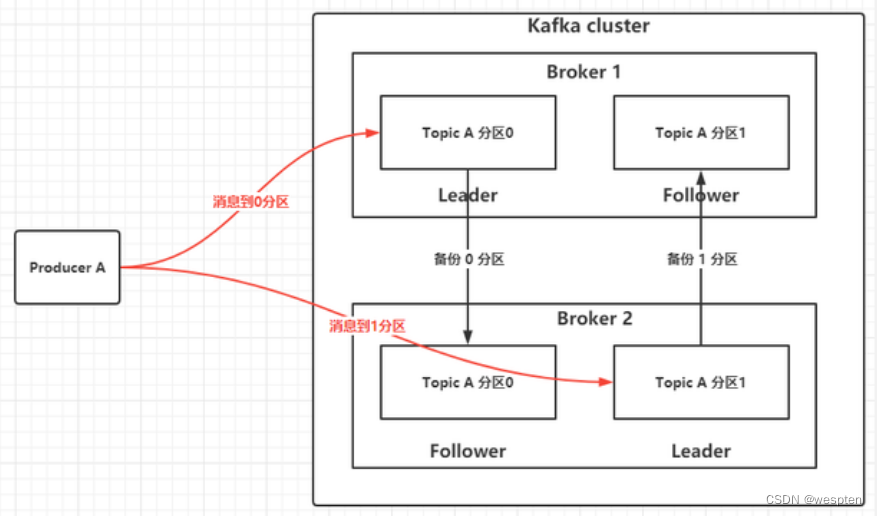
生产者生成的消息对Key做Hash 后做相应的规则区分放到 分区0/1 中的Leader中,Leader 会内部把数据备份到其他broker的备份中,这样的交叉备份的好处就是当其中一个broker 宕机后,不会导致数据的丢失。
1、准备配置文件
现在我们在一台机器上同时启动三个broker实例。
首先,我们需要建立好其他2个broker的配置文件:
[root@along kafka_2.11-2.1.0]# cd /data/kafka_2.11-2.1.0/
[root@along kafka_2.11-2.1.0]# cp config/server.properties config/server-1.properties
[root@along kafka_2.11-2.1.0]# cp config/server.properties config/server-2.properties
[root@along kafka_2.11-2.1.0]# vim config/server-1.properties
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
[root@along kafka_2.11-2.1.0]# vim config/server-2.properties
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2注:该broker.id 属性是群集中每个节点的唯一且永久的名称。我们必须重新指定端口和日志目录,因为我们在同一台机器上运行多个实例,如果不进行修改的话,consumer只能获取到一个instance实例的信息,或者是相互之间的数据会被影响。
配置文件说明:
vi config/server.properties
输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181配置环境变量:
sudo vi /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/data/kafka_2.11-2.1.0
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile分发安装包:
xsync /data/kafka_2.11-2.1.0注意:分发之后记得配置其他机器的环境变量。
2、开启集群另2个kafka服务
目前我们已经有一个zookeeper实例和一个broker实例在运行了,现在我们只需要在启动2个broker实例即可:
[root@along ~]# nohup kafka-server-start.sh /data/kafka_2.11-2.1.0/config/server-1.properties &
[root@along ~]# nohup kafka-server-start.sh /data/kafka_2.11-2.1.0/config/server-2.properties &
[root@along ~]# ss -nutl
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp LISTEN 0 50 ::ffff:127.0.0.1:9092 :::*
tcp LISTEN 0 50 ::ffff:127.0.0.1:9093 :::*
tcp LISTEN 0 50 ::ffff:127.0.0.1:9094 :::*注:broker.id不得重复,broker.id=1、broker.id=2
3、在集群中进行操作
现在我们创建一个新的topic,备份因子设置为3:
[root@along ~]# kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Created topic "my-replicated-topic".现在我们已经有了集群,并且创建了一个3个备份因子的topic,但是到底是哪一个broker在为这个topic提供服务呢(因为我们只有一个分区,所以肯定同时只有一个broker在处理这个topic)。
在一个集群中,运行describe topics命令查看哪个broker正在做什么:‘
[root@along ~]# kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1注释:第一行给出了所有分区的摘要,之后的每一行表示每一个partition的信息。因为目前我们只有一个partition,因此关于partition的信息只有一行。
“leader”:负责给定分区的所有读取和写入的请求,每个节点将成为随机选择的分区部分的领导者,leader信息可以在zookeeper里的/contronller目录查看。
“replicas”:表示某个partition在哪几个broker上存在备份。不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。
“isr”:replicas的一个子集,它只列出当前还存活着的,并且备份了该partition的节点。
请注意,Leader: 2,在我的示例中,节点2是该主题的唯一分区的Leader,即使用server.properties启动的那个进程。
可以在我们创建的原始主题上运行相同的命令,以查看它的位置:
[root@along ~]# kafka-topics.sh --describe --zookeeper localhost:2181 --topic along
Topic:along PartitionCount:1 ReplicationFactor:1 Configs:
Topic: along Partition: 0 Leader: 0 Replicas: 0 Isr: 0没有什么值得惊讶的地方,我们之前设置了topic的partition数量为1,备份因子为1,因此显示就如上所示了。
向我们的新主题发布一些消息:
[root@along ~]# kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
>my test message 1
>my test message 2现在开始消费:
[root@along ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
my test message 1
my test message 24、测试集群的容错性
现在让我们测试一下容错性。Broker 2 充当leader 所以让我们杀了它:
[root@along ~]# ps aux | grep server-2.properties |awk '{print $2}'
106737
[root@along ~]# kill -9 106737
[root@along ~]# ss -nutl
tcp LISTEN 0 50 ::ffff:127.0.0.1:9092 :::*
tcp LISTEN 0 50 ::ffff:127.0.0.1:9093 :::*leader 已切换到其中一个从属节点,节点2不再位于同步副本集中:
[root@along ~]# kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 0 Replicas: 2,0,1 Isr: 0,1我们可以看到,leader节点已经变成了broker 0。要注意的是,在Isr中,已经没有了2号节点。leader的选举也是从ISR(in-sync replica)中进行的。
即使最初接受写入的leader 已经失败,这些消息仍可供消费:
[root@along ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
my test message 1
my test message 25、关闭集群
在三台机器上分别执行:
bin/kafka-server-stop.sh stop6、kafka分区leader选举原理

kafka的组协调器与消费者协调器,组协调器负责选举出消费者leader,消费者leader根据分区分配策略匹配消费者与分区的消费关系。
补充:
分区与消费者消费分配策略:
round-robin分区分配策略
七、Kafka集群搭建在SASL/PLAIN下实现动态权限
目前的三套kafka集群版本比较老,并且磁盘容量即将到达限制,无法满足日益增长的产品需求。故计划重新搭建一套新版本的kafka集群,并验证下新版本的权限控制功能,是否能满足线上需求。
1、zookeeper的搭建过程中的问题
问题1 :启动zk失败,查看log,报错如下:
java.lang.UnsupportedClassVersionError: org/springframework/web/SpringServletContainerInitializer : Unsupported major.minor version 52.0 (unable to load class org.springframework.web.SpringServletContainerInitializer)原因:是java的版本不对,需要的是jdk 1.8 实际线上默认安装的是jdk 1.7,安装1.8后zk正常启动。
问题2:zk启动后,集群状态不对,参看log,报错如下:
ERROR [/xxxxx:3888:QuorumCnxManager$Listener@958] - Exception while listening
java.net.BindException: Cannot assign requested address (Bind failed)
at java.net.PlainSocketImpl.socketBind(Native Method)
at java.net.AbstractPlainSocketImpl.bind(AbstractPlainSocketImpl.java:387)
at java.net.ServerSocket.bind(ServerSocket.java:375)
at java.net.ServerSocket.bind(ServerSocket.java:329)原因:在zoo.cfg文件加上参数quorumListenOnAllIPs=true,貌似物理机上不用加,测试的三台是NVM,可能存在着网络上的一些设置。
官网原文:quorumListenOnAllIPs:当设置为true时,ZooKeeper服务器将在所有可用IP地址上侦听来自其对等方的连接,而不仅是在配置文件的服务器列表中配置的地址。它会影响处理ZAB协议和快速领导者选举协议的连接。默认值为false。
问题3:集群启动过程中总有个节点无法加入集群,log中看到链接失败和一个warn:
WARN [QuorumConnectionThread-[myid=3]-3:QuorumCnxManager@381] - Cannot open channel to 2 at election address /xxxx:13889
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.initiateConnection(QuorumCnxManager.java:373)
at org.apache.zookeeper.server.quorum.QuorumCnxManager$QuorumConnectionReqThread.run(QuorumCnxManager.java:436)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)观察这个warn发现 Cannot open channel to 2 at election address /xxxx:13889,但是这个节点的myid 是 3。
原因:zoo.cfg中配置和myid配置,有两个节点写反了。。。 server.2服务器的myid配置为3了。
2、kafka集群限管理
kafka自带的权限控制,不符合需求,准备尝试改下kafka的源码看行不行。
1. 下载kafka2.7.1源码。官网下载即可。
2. 修改权限认证部分的代码
路径:
/xxxx/kafka-2.7.1-src/clients/src/main/java/org/apache/kafka/common/security/plain/internals/PlainServerCallbackHandler.java3. 编译,修改完代码后 确认下安装了java1.8 然后在源码根目录执行:
./gradlew clean build -x test
然后执行 ./gradlew jar 打jar包,修改一些语法错误后,居然就成功了。
然后执行生成jar包 ./gradlew srcJar

生成jar包后,我们只需要kafka_client.jar 找了下在 xxx/kafka-2.7.1-src/clients/build/libs/ 目录下发现了 kafka-clients-2.7.1.jar kafka-clients-2.7.1-sources.jar两个jar包,应该就是他了!
接下来将kafka-clients-2.7.1.jar copy到kafka/libs 目录下,覆盖原有的jar包,至此源码修改部分完成,下面开始配置SASL/PLAIN权限认证部分。
4. 配置zookeeper
在zoo.cfg加配置,申明权限认证方式,这是指broker和zookeepr的认证:
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
requireClientAuthScheme=sasl
jaasLoginRenew=3600000新建zk_server_jaas.conf文件,指定链接到zookeeper需要的用户名和密码:
Server {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-2019"
user_kafka="kafka-2019"
user_producer="prod-2019";
};从kafka/libs下copy 以下jar包覆盖到 zk/lib下:
kafka-clients-0.10.0.1.jar
lz4-1.3.0.jar
slf4j-api-1.7.21.jar
slf4j-log4j12-1.7.21.jar
snappy-java-1.1.2.6.jar修改zkEnv.sh 脚本,最后一行是新建的,指定zk_server_jaas.conf的路径:
#add the zoocfg dir to classpath
CLASSPATH="$ZOOCFGDIR:$CLASSPATH"
for i in "$ZOOBINDIR"/../zookeeper-server/src/main/resources/lib/*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
SERVER_JVMFLAGS=" -Djava.security.auth.login.config=/data1/apache-zookeeper-3.5.9-bin/conf/zk_server_jaas.conf "依次重启所有zk节点,并观察是否又报错,无报错则基本问题了。
5. 配置kafka
新建kafka_server_jaas.conf文件,内容如下 KafkaServer 配置的是kafka集群的用户权限,其中username和password是broker之间通信使用用户密码,user_xxx="yyy"是定义的 可以生产消费的用户,xxx是用户名,yyy是密码,原始的权限控制 所使用的用户必须都在本文件里配置,无法动态增加。 Client 配置的是broker和zk链接的用户密码,其内容和上文zk的配置对应起来即可。
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin"
user_admin="admin"
user_producer="producer"
user_consumer="consumer";
};
Client {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="kafka"
password="kafka-2019";
};配置 server.properties,如下:
listeners=SASL_PLAINTEXT://xx.xx.xx.xx:19508
advertised.listeners=SASL_PLAINTEXT://xx.xx.xx.xx:19508
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
allow.everyone.if.no.acl.found=true
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
super.users=User:admin修改kafka-run-class.sh脚本,将jass文件路径加入启动参数里,所以如果要动态修改用户参数,需要重启。
old
# Generic jvm settings you want to add
if [ -z "$KAFKA_OPTS" ]; then
KAFKA_OPTS=""
fi
new
# Generic jvm settings you want to add
if [ -z "$KAFKA_OPTS" ]; then
KAFKA_OPTS="-Djava.security.auth.login.config=/data1/kafka_2.13-2.7.1/config/kafka_server_jaas.conf"
fi至此,zk和kafka配置完毕。
6. 测试
下面是测试阶段,测试将从 python客户端 和 命令行 两个角度进行验证,命令行比较复杂。
申请topic:
bin/kafka-topics.sh --create --zookeeper xxxx:2181,xxxx:2181,xxxx:2181 --topic test10 --partitions 10 --replication-factor 3配置producer.properties 和 consumer.properties,这里是在指定权限认证方式。
producer.properties 新增:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAINconsumer.properties 新增:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
# consumer group id
group.id=test-group新增 kafka_client_scram_consumer_jaas.conf,kafka_client_scram_producer_jaas.conf 文件,这里指定的是生产者和消费者使用的用户名和密码,注意这里的用户名和密码和kafka_server_jaas.conf不一样。
kafka_client_scram_consumer_jaas.conf 内容:
KafkaClient {
org.apache.kafka.common.security.scram.ScramLoginModule required
username="consumer_test"
password="consumer_test";
};kafka_client_scram_producer_jaas.conf 内容:
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="producer_test"
password="producer_test";
};修改kafka-console-consumer.sh 和 kafka-console-producer.sh 文件,建议copy一份,这里使用的是kafka-console-consumer-scram.sh 和 kafka-console-producer-scram.sh,这里是将相应的jaas文件导入。
kafka-console-consumer-scram.sh:
old
exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleConsumer "$@"
new
exec $(dirname $0)/kafka-run-class.sh -Djava.security.auth.login.config=/data1/kafka_2.13-2.7.1/config/kafka_client_scram_consumer_jaas.conf kafka.tools.ConsoleConsumer "$@"kafka-console-producer-scram.sh:
old
exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleProducer "$@"
new
exec $(dirname $0)/kafka-run-class.sh -Djava.security.auth.login.config=/data1/kafka_2.13-2.7.1/config/kafka_client_scram_producer_jaas.conf kafka.tools.ConsoleProducer "$@"测试下生产者。
这里的用户名密码是producer_test : producer_test1
>>bin/kafka-console-producer-scram.sh --bootstrap-server 10.182.13.237:19508,10.182.13.238:19508 --topic test10 --producer.config ./config/producer.properties
[2021-07-13 11:54:17,303] ERROR Error when sending message to topic test10 with key: null, value: 4 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback)
org.apache.kafka.common.errors.SaslAuthenticationException: Authentication failed: Invalid username or password这里的用户名密码是producer_test :producer_test
>>bin/kafka-console-producer-scram.sh --bootstrap-server 10.182.13.237:19508,10.182.13.238:19508 --topic test10 --producer.config ./config/producer.properties
>test:1
>测试下消费者。
bin/kafka-console-consumer-acl.sh --bootstrap-server 10.182.13.237:19508 --topic test10 --from-beginning --consumer.config ./config/consumer.properties这里的用户名密码是consumer_test : consumer_test1
>>bin/kafka-console-consumer-scram.sh --bootstrap-server 10.182.13.237:19508 --topic test10 --from-beginning --consumer.config ./config/consumer.properties
[2021-07-13 11:58:49,030] ERROR [Consumer clientId=consumer-test-group-1, groupId=test-group] Connection to node -1 (10.182.13.237/10.182.13.237:19508) failed authentication due to: Authentication failed: Invalid username or password (org.apache.kafka.clients.NetworkClient)
[2021-07-13 11:58:49,031] WARN [Consumer clientId=consumer-test-group-1, groupId=test-group] Bootstrap broker 10.182.13.237:19508 (id: -1 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2021-07-13 11:58:49,032] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$)
org.apache.kafka.common.errors.SaslAuthenticationException: Authentication failed: Invalid username or password
Processed a total of 0 messages这里的用户名密码是consumer_test : consumer_test
>>bin/kafka-console-consumer-scram.sh --bootstrap-server 10.182.13.237:19508 --topic test10 --from-beginning --consumer.config ./config/consumer.properties
[2021-07-13 11:57:19,626] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$)
org.apache.kafka.common.errors.GroupAuthorizationException: Not authorized to access group: test-group
Processed a total of 0 messages看着是group 未授权。
授权group:
bin/kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=10.182.9.145:2181,10.182.13.237:2181,10.182.13.238:2181 --add --allow-principal User:consumer_test --operation Read --group test-group再来一次:
>>bin/kafka-console-consumer-scram.sh --bootstrap-server 10.182.13.237:19508 --topic test10 --from-beginning --consumer.config ./config/consumer.properties
test:1
test:1这就有结果了。
从目前看。用户名和密码一致,则认证通过,不一致则不通过,不需要授read / write权限,但是group read 权限需要授予
下面使用python客户端测试,,代码如下,很简单。
import json
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=["10.182.9.145:19508"],
security_protocol = "SASL_PLAINTEXT",
sasl_mechanism = 'PLAIN',
sasl_plain_username = "producer_aaa",
sasl_plain_password = "producer_aaa")
data = json.dumps({
"test": "1"
})
for i in range(1,10):
producer.send("test10",value=bytes(data))
producer.close()#!/usr/bin/env python
from kafka import KafkaConsumer
# To consume messages
consumer = KafkaConsumer('test10',
group_id='test-group',
bootstrap_servers=['10.182.9.145:19508'],
auto_offset_reset="earliest",
security_protocol = "SASL_PLAINTEXT",
sasl_mechanism = "PLAIN",
sasl_plain_username = "consumer_test",
sasl_plain_password = "consumer_test"
)
for message in consumer:
# message value is raw byte string -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))目前的问题是,需要完善的权限控制,但是现在生产者默认有所有topic的写入权限,消费者可以用group控制,这不符合线上的要求,按理说kafka的认证和授权是分开的,在源码上只修改了认证部分。
原因:如果一个topic创建后,不申请任何权限,那么它就是所有用户(通过认证)都能访问的,如果对此topic进行任意授权,那就只能让授权列表中的用户访问了。
目标,就贴一下修改细节,修改的函数如下,替换了authenticate 函数的内容,将认证的逻辑修改为,如果用户名和密码一致则认证通过。
// protected boolean authenticate(String username, char[] password) throws IOException {
// if (username == null)
// return false;
// else {
// String expectedPassword = JaasContext.configEntryOption(jaasConfigEntries,
// JAAS_USER_PREFIX + username,
// PlainLoginModule.class.getName());
// return expectedPassword != null && Arrays.equals(password, expectedPassword.toCharArray());
// }
// }
protected boolean authenticate(String username, char[] password) throws IOException {
if (username == null)
return false;
else {
return expectedPassword != null && Arrays.equals(password, username.toCharArray());
}
}接下来,需要再进一步,将逻辑修改为,读取本地文件,判断用户名和密码是否在文件内 来决定是否通过认证,此举是为了便于管理业务的用户和密码。
代码修改如下,逻辑很简单,是否通过认证是通过查找users.properties文件的内容确定的:
protected boolean authenticate(String username, char[] password) throws IOException {
String pass = String.valueOf(password);
int flag = readFileContent("/xxxx/kafka_2.13-2.7.1/config/users.properties", username, pass);
if (flag == 1)
return true;
return false;
}
public static int readFileContent(String fileName, String username, String pass) {
File file = new File(fileName);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempStr;
String[] userandpassword;
while ((tempStr = reader.readLine()) != null) {
userandpassword = tempStr.split(":");
if (userandpassword[0].equals(username) && userandpassword[1].equals(pass))
return 1;
}
reader.close();
return 0;
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
return 0;
}重新打包,生成jar文件,替换kafka-clients-2.7.1.jar文件,然后重启kafka集群。
此时出现大量报错:如下
[2021-07-14 16:59:43,312] ERROR [Controller id=145, targetBrokerId=145] Connection to node 145 (xx.xx.xx.xx/xx.xx.xx.xx:19508) failed authentication due to: Authentication failed: Invalid username or password (org.apache.kafka.clients.NetworkClient)
[2021-07-14 16:59:43,413] INFO [SocketServer brokerId=145] Failed authentication with /xx.xx.xx.xx (Authentication failed: Invalid username or password) (org.apache.kafka.common.network.Selector)
[2021-07-14 16:59:43,485] INFO [Controller id=145, targetBrokerId=237] Failed authentication with xx.xx.xx.xx/xx.xx.xx.xx (Authentication failed: Invalid username or password) (org.apache.kafka.common.network.Selector)
[2021-07-14 16:59:43,485] ERROR [Controller id=145, targetBrokerId=237] Connection to node 237 (xx.xx.xx.xx/xx.xx.xx.xx:19508) failed authentication due to: Authentication failed: Invalid username or password (org.apache.kafka.clients.NetworkClient)
[2021-07-14 16:59:43,713] INFO [Controller id=145, targetBrokerId=145] Failed authentication with xx.xx.xx.xx/xx.xx.xx.xx (Authentication failed: Invalid username or password) (org.apache.kafka.common.network.Selector)
[2021-07-14 16:59:43,713] ERROR [Controller id=145, targetBrokerId=145] Connection to node 145 (xx.xx.xx.xx/xx.xx.xx.xx:19508) failed authentication due to: Authentication failed: Invalid username or password (org.apache.kafka.clients.NetworkClient)
[2021-07-14 16:59:43,815] INFO [SocketServer brokerId=145] Failed authentication with /xx.xx.xx.xx (Authentication failed: Invalid username or password) (org.apache.kafka.common.network.Selector)原因是broker之间,broker和zookeeper之间的认证也是用的authenticate函数,但是目前users.properties文件里为空,所以所有的认证都失败了,在文件中补全所有的用户名和密码后,报错消失。
下面使用python 客户端进行测试。
创建测试topic test11
bin/kafka-topics.sh --create --zookeeper xxxx:2181,xxxx:2181,xxxx:2181 --topic test11 --partitions 10 --replication-factor 3此时通过python produce写入数据报错 用户名和密码为producer_zzz,producer_lll
D:\python_pycharm\venv\Scripts\python.exe D:/python_pycharm/kafka_demo/kakfa_produce.py
Traceback (most recent call last):
File "D:/python_pycharm/kafka_demo/kakfa_produce.py", line 10, in <module>
sasl_plain_password="producer_lll")
File "D:\python_pycharm\venv\lib\site-packages\kafka\producer\kafka.py", line 347, in __init__
**self.config)
File "D:\python_pycharm\venv\lib\site-packages\kafka\client_async.py", line 216, in __init__
self._bootstrap(collect_hosts(self.config['bootstrap_servers']))
File "D:\python_pycharm\venv\lib\site-packages\kafka\client_async.py", line 250, in _bootstrap
bootstrap.connect()
File "D:\python_pycharm\venv\lib\site-packages\kafka\conn.py", line 374, in connect
if self._try_authenticate():
File "D:\python_pycharm\venv\lib\site-packages\kafka\conn.py", line 451, in _try_authenticate
raise self._sasl_auth_future.exception # pylint: disable-msg=raising-bad-type
kafka.errors.AuthenticationFailedError: AuthenticationFailedError: Authentication failed for user producer_zzz可以看到是 认证失败。
然后在users.properties 文件中加上producer_zzz:producer_lll 再试一次:
D:\python_pycharm\venv\Scripts\python.exe D:/python_pycharm/kafka_demo/kakfa_produce.py
Process finished with exit code 0可以发现写入成功了,这是由于新topic没有进行授权,默认所有produce都可以写入,也证实了现在用户可以热更新了。
更进一步的测试,进行授权:
bin/kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=xx.xx.xx.xx:2181 --add --allow-principal User:producer_zzz --operation Write --topic test11这是其他的用户就不能随意写了,其他用户的报错如下。而producer_zzz用户还是可以的。
D:\python_pycharm\venv\Scripts\python.exe D:/python_pycharm/kafka_demo/kakfa_produce.py
Traceback (most recent call last):
File "D:/python_pycharm/kafka_demo/kakfa_produce.py", line 37, in <module>
producer.send("test11",value=bytes(data))
File "D:\python_pycharm\venv\lib\site-packages\kafka\producer\kafka.py", line 504, in send
self._wait_on_metadata(topic, self.config['max_block_ms'] / 1000.0)
File "D:\python_pycharm\venv\lib\site-packages\kafka\producer\kafka.py", line 631, in _wait_on_metadata
"Failed to update metadata after %.1f secs." % max_wait)
kafka.errors.KafkaTimeoutError: KafkaTimeoutError: Failed to update metadata after 60.0 secs.接下来测试consumer。
直接运行报错:
D:\python_pycharm\venv\Scripts\python.exe D:/python_pycharm/kafka_demo/kafka_consumer.py
Traceback (most recent call last):
File "D:/python_pycharm/kafka_demo/kafka_consumer.py", line 16, in <module>
for message in consumer:
File "D:\python_pycharm\venv\lib\site-packages\kafka\vendor\six.py", line 561, in next
return type(self).__next__(self)
File "D:\python_pycharm\venv\lib\site-packages\kafka\consumer\group.py", line 1075, in __next__
return next(self._iterator)
File "D:\python_pycharm\venv\lib\site-packages\kafka\consumer\group.py", line 998, in _message_generator
self._coordinator.ensure_coordinator_known()
File "D:\python_pycharm\venv\lib\site-packages\kafka\coordinator\base.py", line 225, in ensure_coordinator_known
raise future.exception # pylint: disable-msg=raising-bad-type
kafka.errors.GroupAuthorizationFailedError: [Error 30] GroupAuthorizationFailedError: test-group在users.properties 加用户名和密码,consumer 授予read 权限,group 授权 一条龙执行:
bin/kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=xx.xx.xx.xx:2181 --add --allow-principal User:consumer_zzz --operation Read --topic test11
bin/kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=xx.xx.xx.xx:2181 --add --allow-principal User:consumer_zzz --operation Read --group test-group消费成功!
D:\python_pycharm\venv\Scripts\python.exe D:/python_pycharm/kafka_demo/kafka_consumer.py
test11:8:0: key=None value={"test": "1"}
test11:5:0: key=None value={"test": "1"}
test11:3:0: key=None value={"test": "1"}
test11:0:0: key=None value={"test": "1"}
test11:6:0: key=None value={"test": "1"}
test11:6:1: key=None value={"test": "1"}
test11:10:0: key=None value={"test": "1"}
test11:4:0: key=None value={"test": "1"}
test11:4:1: key=None value={"test": "1"}至此,kafka2.7.1版本搭建以及动态的权限认证问题基本解决.
八、Docker搭建Kafka集群
1、单机版(Docker 搭建)
搭建使用docker-compose.yml:
version: '2'
services:
zoo1:
image: wurstmeister/zookeeper
restart: unless-stopped
hostname: zoo1
ports:
- "6181:2181"
container_name: zookeeper_kafka
# kafka version: 1.1.0
# scala version: 2.12
kafka1:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 81.70.91.63
# zoo1:2181 也可以改成:81.70.91.63:6181
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CREATE_TOPICS: "stream-in:1:1,stream-out:1:1"
depends_on:
- zoo1
container_name: kafka运行:
到docker-compose.yml 所在的目录下运行:docker-compose up -d。
2、集群版(Docker 搭建)
首先对zookeeper 做集群。
以下是 zk.yml 文件:
version: '3.4'
services:
zoo1:
image: zookeeper:3.4
restart: always
container_name: zoo1
ports:
- 2184:2181
volumes:
- "/szw/volume/zkcluster/zoo1/data:/data"
- "/szw/volume/zkcluster/zoo1/datalog:/datalog"
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
networks:
kafka:
ipv4_address: 172.19.0.11
zoo2:
restart: always
hostname: zoo2
container_name: zoo2
ports:
- 2185:2181
volumes:
- "/szw/volume/zkcluster/zoo2/data:/data"
- "/szw/volume/zkcluster/zoo2/datalog:/datalog"
ZOO_MY_ID: 2
.1=.2=0.0.0.0:2888:3888 server.3=
networks:
kafka:
172.19.0.12
zoo3:
restart: always
hostname: zoo3
container_name: zoo3
ports:
- 2186:2181
volumes:
- "/szw/volume/zkcluster/zoo3/data:/data"
- "/szw/volume/zkcluster/zoo3/datalog:/datalog"
ZOO_MY_ID: 3
.1=.2=.3=0.0.0.0:2888:3888
networks:
kafka:
172.19.0.13
networks:
kafka:
external:
name: kafkaKafka 做集群。
以下是:kafka.yml 文件
version:
services:
kafka1:
restart: always
hostname: kafka1
container_name: kafka1
privileged: true
ports:
- 9092:9092
KAFKA_ADVERTISED_HOST_NAME: kafka1
KAFKA_LISTENERS: PLAINTEXT://kafka1:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://81.70.91.63:9092
KAFKA_ADVERTISED_PORT: 9092
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- /szw/volume/kfkluster/kafka1/logs:/kafka
external_links:
- zoo1
- zoo2
- zoo3
networks:
kafka:
172.19.0.14
kafka2:
restart: always
hostname: kafka2
container_name: kafka2
true
ports:
- 9093:9093
KAFKA_ADVERTISED_HOST_NAME: kafka2
KAFKA_LISTENERS: PLAINTEXT://kafka2:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://81.70.91.63:9093
9093
volumes:
- /szw/volume/kfkluster/kafka2/logs:/kafka
- zoo1
- zoo2
- zoo3
networks:
kafka:
172.19.0.15
kafka3:
restart: always
hostname: kafka3
container_name: kafka3
true
ports:
- 9094:9094
KAFKA_ADVERTISED_HOST_NAME: kafka3
KAFKA_LISTENERS: PLAINTEXT://kafka3:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://81.70.91.63:9094
9094
volumes:
- /szw/volume/kfkluster/kafka3/logs:/kafka
- zoo1
- zoo2
- zoo3
networks:
kafka:
172.19.0.16
networks:
kafka:
external:
name: kafka界面管理工具:用来监控集群管理。
以下是:kafkamanage.yml 文件:
version: "3.4"
services:
kafka-manager:
image: sheepkiller/kafka-manager:latest
restart: always
container_name: kafka-manager
hostname: kafka-manager
ports:
- 9000:9000
ZK_HOSTS: zoo1:2181,zoo2:2181,zoo3:2181
KAFKA_BROKERS: kafka1:9092,kafka2:9092,kafka3:9092
APPLICATION_SECRET: letmein
KM_ARGS: -Djava.net.preferIPv4Stack=true
networks:
kafka:
ipv4_address: 172.19.0.17
networks:
kafka:
external:
name: kafka启动:
#docker-compose 默认会创建网络,不需要手动执行
#如果执行错误,则需要删除其他的network
#docker network ls
#查看详细的 network
#docker network inspect name/id
#
docker network create --driver bridge --subnet 172.19.0.0/16 --gateway 172.19.0.1 kafka
docker-compose -f zk.yml -f kafka.yml -f kafkamanage.yml up -d安装成功: 访问 kafkamanage 管理工具的地址:(81.70.91.63:9000/)

注意:添加cluster 和 Zookeeper host 注意默认数值提示,保存。
添加成功后:
九、Kafka生产者原理详解
1、Kafka生产者概述
Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
一个消息记录是一个 ProducerRecord 对象,对象包含了四个属性:Topic,partition,key,value;topic 和 value 是必须的,key 和 partition 是可选的。
构建好一个消息对象后,就要准备发送了,在发送的时候,生产者需要将 key 和 value 序列化成 byte 数组,发送会经过分区器,如果指定了 key,那么相同 key 的消息会发往同一个分区,如果实现了自定义分区器,那么就会走自定义分区器进行分区路由,否则就是根据 kafka 客户端 api 的 hash 算法将消息发送到计算出来的分区。
发送的时候并不是来一个消息就发送一个消息,这样的话吞吐量比较低,并且频繁的进行网络请求,消息是按照批次来发送的或者等待时间来发的的。
2、生产者消息发送流程
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
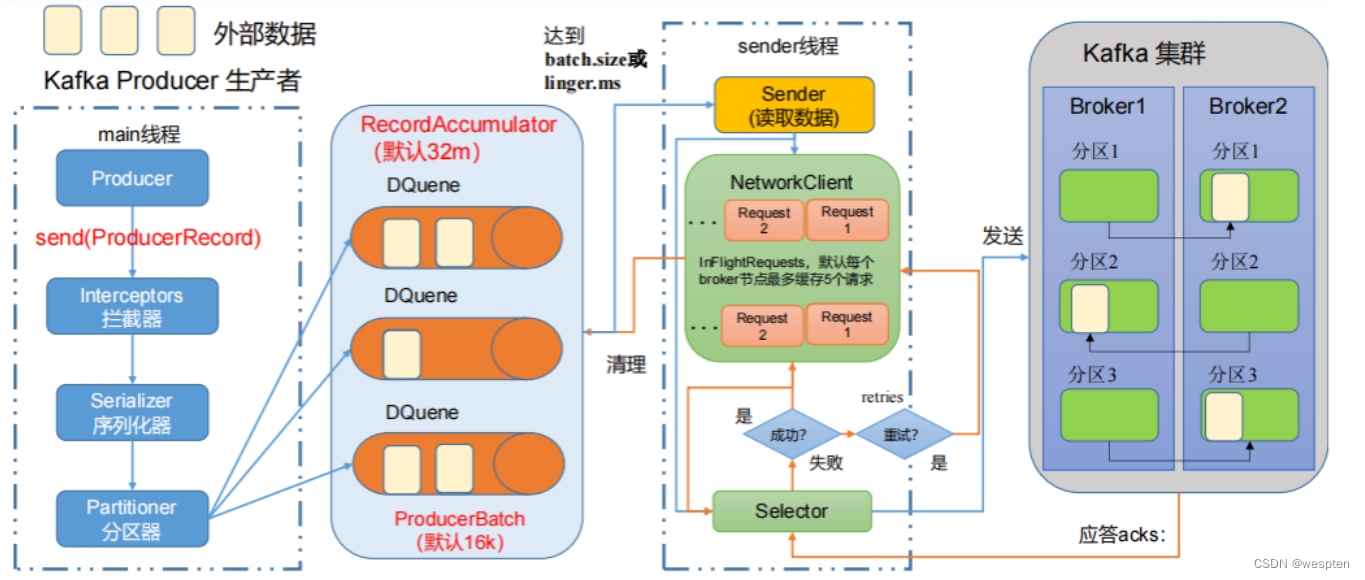
参数说明:
batch.size:只有数据积累到batch.size之后,sender才会发送数据。默认16k
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟
buffer.memoryRecordAccumulator: 缓冲区总大小,默认 32m。
compression.type:生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。支持压缩类型:none、gzip、snappy、lz4 和 zstd。
enable.idempotence:是否开启幂等性,默认 true,开启幂等性。
retries:当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是 int 最大值,2147483647。
应答ACKs:
0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader收到数据后应答。
-1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。-1和all等价。3、producer发布消息机制剖析
1)写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)
2)消息路由
1. producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。
2. 分区算法策略(生产者发送消息的分区策略)。
3)写入流程
1. producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader。
2. producer 将消息发送给该 leader。
3. leader 将消息写入本地 log。
4. followers 从 leader pull 消息,写入本地 log 后 向leader 发送 ACK。
5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset)并向roducer 发送 ACK。
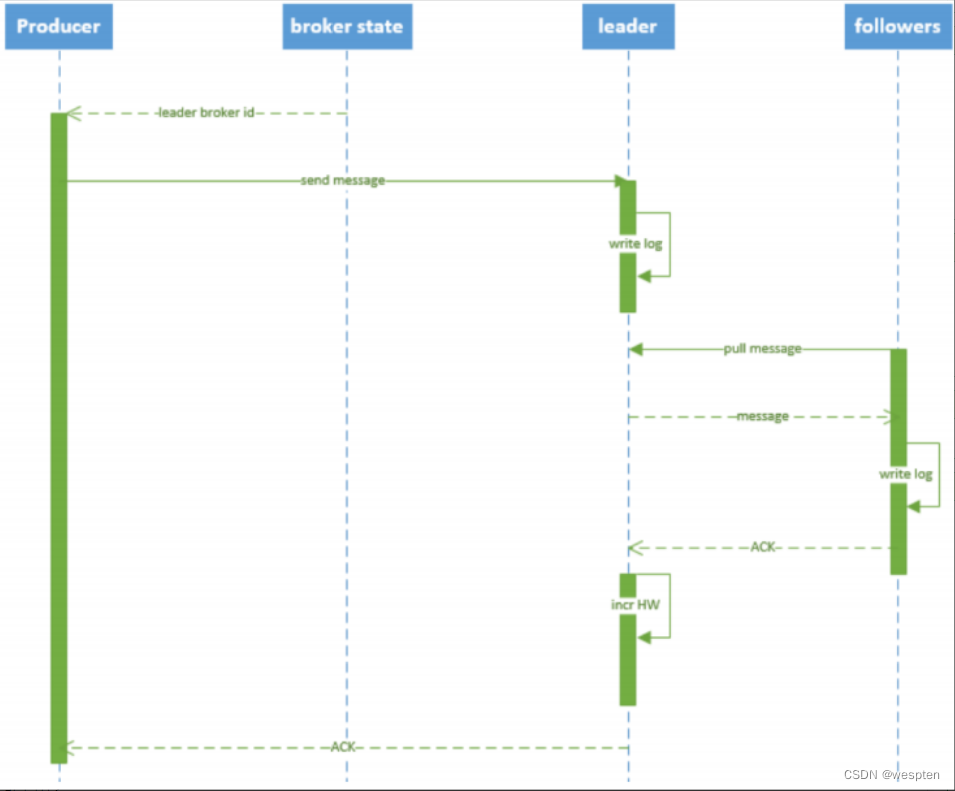
4、异步发送 API
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>import com.alibaba.fastjson.JSON;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
public class MsgProducer {
private final static String TOPIC_NAME = "my-replicated-topic";
public static void main(String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094");
/*
发出消息持久化机制参数
*/
/*props.put(ProducerConfig.ACKS_CONFIG, "1");
*//*
发送失败会重试发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如网络抖动,所以需要在 接收者那边做好消息接收的幂等性处理
//注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//重试间隔设置
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
//设置发送消息的本地缓冲区,
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
*//*
kafka本地线程会从缓冲区取数据,批量发送到broker,
设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去
*//*
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
*//*
默认值是0,意思就是消息必须立即被发送,但这样会影响性能
一般设置10毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果10毫秒内,这个batch满了16kb就会随batch一起被发送出去
如果10毫秒内,batch没满,那么也必须把消息发送出去,不能让消息的发送延迟时间太长
*//*
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);*/
//把发送的key从字符串序列化为字节数组
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//把发送消息value从字符串序列化为字节数组
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int msgNum = 5;
final CountDownLatch countDownLatch = new CountDownLatch(msgNum);
for (int i = 1; i <= msgNum; i++) {
Order order = new Order(i, 100 + i, 1, 1000.00);
//指定发送分区
/*ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, 0, order.getOrderId().toString(), JSON.toJSONString(order));*/
//未指定发送分区,具体发送的分区计算公式:hash(key)%partitionNum
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, order.getOrderId().toString(), JSON.toJSONString(order));
//等待消息发送成功的同步阻塞方法
/*RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("同步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" + metadata.offset());*/
//异步回调方式发送消息 ,
producer.send(producerRecord, new Callback() {
// 回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception),
// 如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("发送消息失败:" + exception.getStackTrace());
}
if (metadata != null) {
System.out.println("异步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" + metadata.offset());
}
countDownLatch.countDown();
}
});
//送积分 TODO
countDownLatch.await(5, TimeUnit.SECONDS);
producer.close();
}
}5、生产者分区
1)Kafka 分区好处
1. 便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
2. 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
2)Kafka 分区说明
1. 为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
2. 一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower;Leader 副本才能向外提供服务, Follower副本只有Leader副本挂了,通过某些规则进行选举之后,某个Follower变成了Leader之后才能才能向外提供服务。

查看下topic的情况:
bin/kafka‐topics.sh ‐‐describe ‐‐zookeeper 192.168.65.60:2181 ‐‐topic test1第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息。
Leader节点负责给定partition的所有读写请求。replicas 表示某个partition在哪几个broker上存在备份,不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
3. 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
4. 每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
5. 一个分区就是一个提交日志,消息以追加的方式写入分区,然 后以先入先出的顺序读取,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序。
但可以保证消息在单个分区内的顺序:
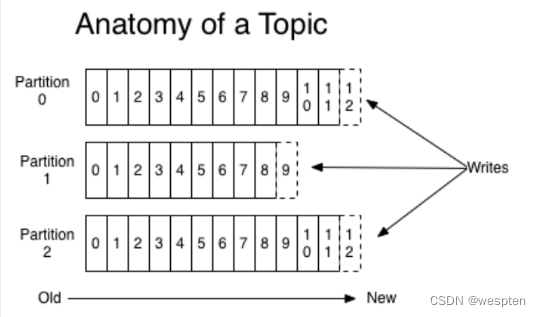
6. Partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
7. 每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
3)生产者发送消息的分区策略
① 指定分区
1. 指明partition的情况下,直接将指明的值作为partition值;例如partition=0,所有数据写入分区0。
2. 对应的构造方法:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers){}
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {}
public ProducerRecord(String topic, Integer partition, K key, V value) {}② 没有指定分区
1. 没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值。
2. 例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1 对应的value1写入1号分区,key2对应的value2写入0号分区。
对应的构造方法:
public ProducerRecord(String topic, K key, V value){}③ 既没有指定分区,也没有指定k
1. 既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区。待该分区的batch已满或者或者linger.ms设置的时间到,Kafka再随机一个分区进行使用(和上一次的分区不同)
2. 例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到,Kafka再随机一个分区进行使用(如果还是0会继续随机)。
对应构造方法:
public ProducerRecord(String topic, V value)④ 自定义分区器
1. 需求:如果研发人员可以根据企业需求,自己重新实现分区器。
2. 实现步骤:定义类实现 Partitioner 接口。重写 partition()方法。
在生产者发送消息时配置如下配置:
// 添加自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.kafka.producer.MyPartitioner");自定义分区器代码如下:
/**
* 1. 实现接口 Partitioner
* 2. 实现 3 个方法:partition,close,configure
* 3. 编写 partition 方法,返回分区号
*/
public class CustomPartitioner implements Partitioner {
/**
* 返回信息对应的分区
* @param topic 主题
* @param key 消息的 key
* @param keyBytes 消息的 key 序列化后的字节数组
* @param value 消息的 value
* @param valueBytes 消息的 value 序列化后的字节数组
* @param cluster 集群元数据可以查看分区信息
* @return
*/
@Override
public int partition(String topic, Object key, byte[]
keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取消息
String msgValue = value.toString();
// 创建 partition
int partition;
// 判断消息是否包含 test
if (msgValue.contains("test")){
partition = 0;
}else {
partition = 1;
}
// 返回分区号
return partition;
}
// 关闭资源
@Override
public void close() {
}
// 配置方法
@Override
public void configure(Map<String, ?> configs) {
} }6、生产经验之生产者如何提高吞吐量
通过修改如下的参数配置就可以提升生产者的吞吐量。
① buffer.memory
1. 设置发送消息的缓冲区,默认值是33554432,就是32MB。
2. 如果发送消息出去的速度小于写入消息进去的速度,就会导致缓冲区写满,此时生产消息就会阻塞住,所以说这里就应该多做一些压测,尽可能保证说这块缓冲区不会被写满导致生产行为被阻塞住。
② compression.type
默认是none,不压缩,但是也可以使用snappy压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的cpu开销。
③ batch.size
1. 批次大小,设置batch的大小,如果 batch 太小,会导致频繁网络请求,吞吐量下降。
2. 如果batch太大,会导致一条消息需要等待很久才能被发送出去,而且会让内存缓冲区有很大压力,过多数据缓冲在内存里。
3. 其默认值是:16384,就是16kb,也就是一个batch满了16kb就发送出去,一般在实际生产环境,这个batch的值可以增大一些来提升吞吐量。
④ linger.ms
1. 默认是0,意思就是消息必须立即被发送,但是这是不对的。
2. 一般设置一个100毫秒之类的,这样的话就是说,消息会被装进batch,如果100毫秒内,这个batch装满了16kb(默认),自然就会发送出去。
3. 但是如果100毫秒内,batch没满,那么也必须把消息发送出去了,不能让消息的发送延迟时间太长,也避免给内存造成过大的一个压力。
4. linger.ms设置太大,消息的延迟时间就会太长,设置太小会导致频繁网络请求,吞吐量下降。
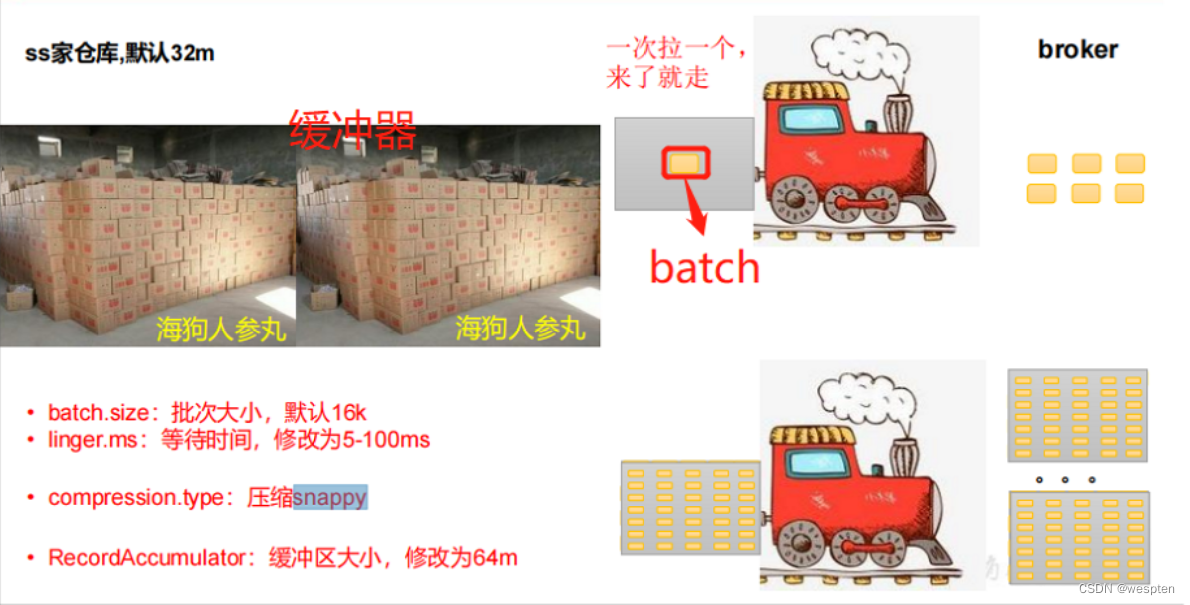
7、生产经验之数据可靠性
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2。
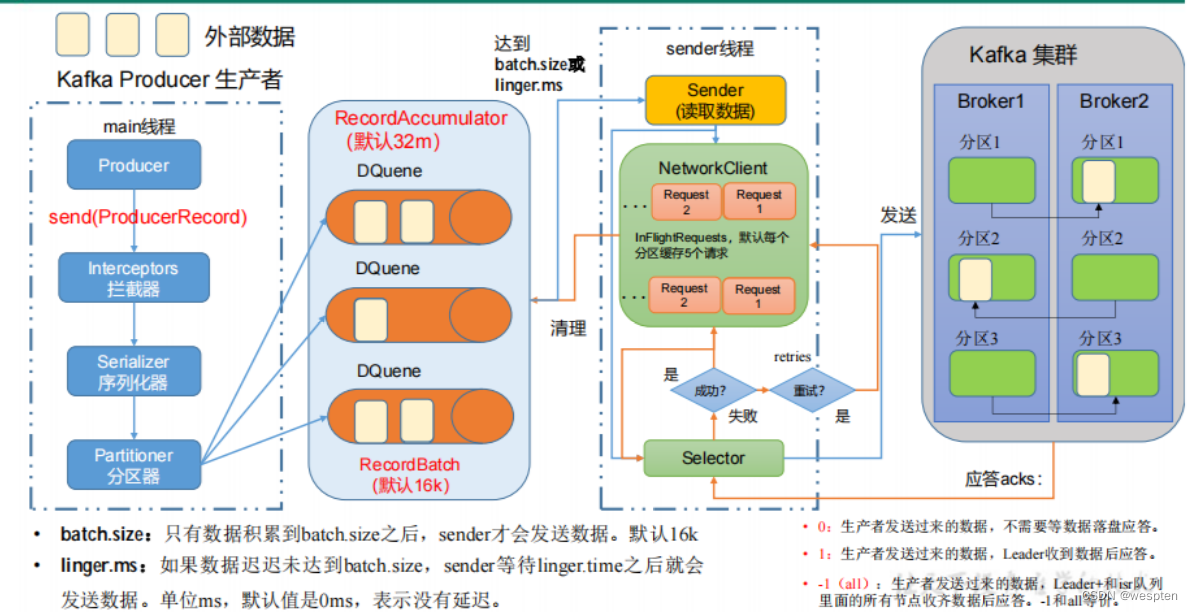
1)ACK应答级别
kafka的ACK应答级别有三种,分别是 0、1和-1(all)
① 0:生产者发送过来的数据,不需要等数据落盘应答 , 数据可靠性分析:丢数。
表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息,大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
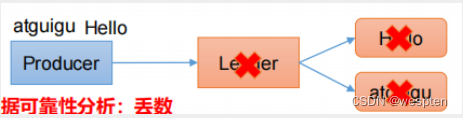
② 1:生产者发送过来的数据,Leader收到数据后应答。数据可靠性分析:丢数。
ps:至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。

③ -1(all) :生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答(节点个数可配置)
这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证,一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果min.insync.replicas配置的是1则也可能丢消息,跟acks=1情况类似
2)min.insync.replicas参数说明
极端情况1:默认min.insync.replicas=1,极端情况下如果ISR中只有leader一个副本时满足min.insync.replicas=1这个条件,此时producer发送的数据只要leader同步成功就会返回响应,如果此时leader所在的broker crash了,就必定会丢失数据!这种情况不就和acks=1一样了!所以我们需要适当的加大min.insync.replicas的值。
极端情况2:min.insync.replicas=3(等于副本数),这种情况下要一直保证ISR中有所有的副本,且producer发送数据要保证所有副本写入成功才能接收到响应!一旦有任何一个broker crash了,ISR里面最大就是2了,不满足min.insync.replicas=3,就不可能发送数据成功了!
根据这两个极端的情况可以看出min.insync.replicas的取值,是kafka系统可用性和数据可靠性的平衡!
① 减小min.insync.replicas的值,一定程度上增大了系统的可用性,允许kafka出现更多的副本broker crash并且服务正常运行;但是降低了数据可靠性,可能会丢数据(极端情况1)。
② 增大min.insync.replicas的值,一定程度上增大了数据的可靠性,允许一些broker crash掉,且不会丢失数据(只要再次选举的leader是从ISR中选举的就行);但是降低了系统的可用性,会允许更少的broker crash(极端情况2)。
问题:Leader收到数据,所有Follower都开始同步数据,但有一个Follower,因为某种故障,迟迟不能与Leader进行同步,那这个问题怎么解决呢?
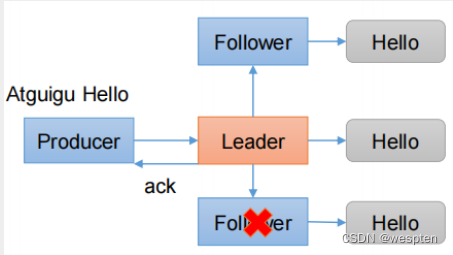
Kafak解决方案:
Leader维护了一个动态的in-sync replica set(ISR),意为和Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2),如果Follower长时间未向。Leader发送通信请求或同步数据,则该Follower将被踢出ISR。
该时间阈值由replica.lag.time.max.ms参设定,默认30s。例如2超时,(leader:0, isr:0,1)。这样就不用等长期联系不上或者已经故障的节点。
数据可靠性分析 :
1. 如果分区副本设置为1个,或 者ISR里应答的最小副本数量( min.insync.replicas 默认为1)设置为1,和ack=1的效果是一样的,仍然有丢数的风险(leader:0,isr:0)。
2. 总结得出:数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2。
可靠性总结:
1. acks=0,生产者发送过来数据就不管了,可靠性差,效率高;大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
2.a cks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等。
3. acks=-1或者all,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低。
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
8、生产经验——数据去重
数据重复性性分析:
接收了两份Hello数据,导致数据重复,该如何解决数据重复?
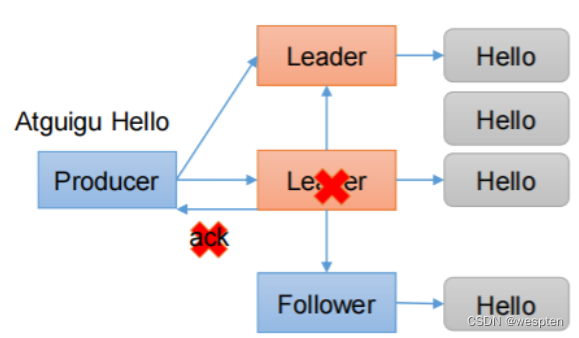
1)数据传递语义
1. 至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2,可以保证数据不丢失,但是不能保证数据不重复。
2. 最多一次(At Most Once)= ACK级别设置为0,可以保证数据不重复,但是不能保证数据不丢失。
3. 精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
2)幂等性
1. 幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
2. 精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2)。
3. 重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。
4. 所以幂等性只能保证的是在单分区单会话内不重复。
5. 开启幂等性参数 enable.idempotence 默认为 true,false 关闭。
3)生产者事务
1. Kafka的事务主要是保障一次发送多条消息的事务一致性(要么同时成功要么同时失败)。
2. 说明:开启事务,必须开启幂等性。
3. Producer 在使用事务功能前,必须先自定义一个唯一的 transactional.id.有了 transactional.id,即使客户端挂掉了,它重启后也能继续处理未完成的事务。
4. 一般在kafka的流式计算场景用得多一点,比如,kafka需要对一个topic里的消息做不同的流式计算处理,处理完分别发到不同的topic里,这些topic分别被不同的下游系统消费(比如hbase,redis,es等),这种我们肯定希望系统发送到多个topic的数据保持事务一致性。Kafka要实现类似Rocketmq的分布式事务需要额外开发功能。
Kafka 的事务一共有如下 5 个 API:
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
单个 Producer,使用事务保证消息的仅一次发送:
package com.test.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerTransactions {
public static void main(String[] args) throws
InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9092");
// key,value 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 设置事务 id(必须),事务 id 任意起名
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction_id_0");
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 初始化事务
kafkaProducer.initTransactions();
// 开启事务
kafkaProducer.beginTransaction();
try {
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
// 发送消息
kafkaProducer.send(new ProducerRecord<>("first",
"atguigu " + i));
}
// int i = 1 / 0;
// 提交事务
kafkaProducer.commitTransaction();
} catch (Exception e) {
// 终止事务
kafkaProducer.abortTransaction();
} finally {
// 5. 关闭资源
kafkaProducer.close();
}
} }9、生产经验之数据顺序
1)数据有序
1. 单分区内,有序多分区,分区与分区间无序。
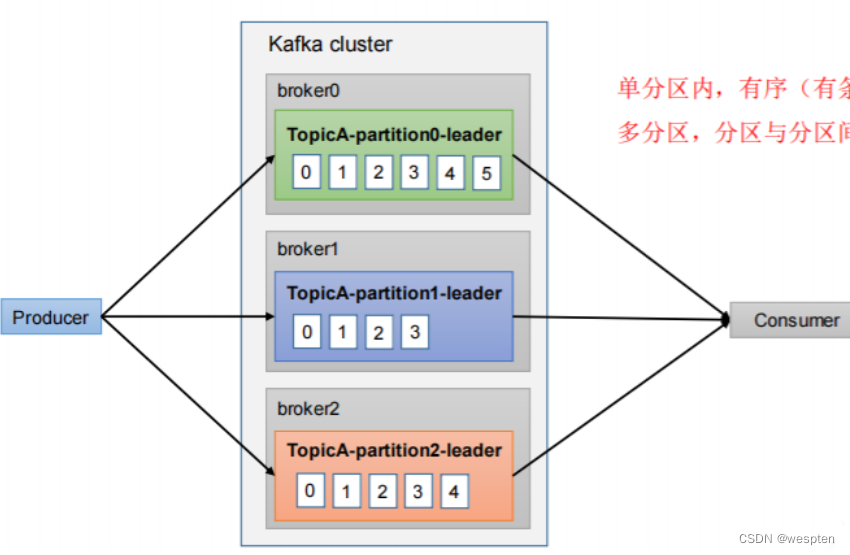
2. kafka在1.x版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。3. kafka在1.x及以后版本保证数据单分区有序,条件如下:
(1)开启幂等性
max.in.flight.requests.per.connection //需要设置小于等于5。(2)未开启幂等性
max.in.flight.requests.per.connection //需要设置为1。(3) 原因说明
因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,故无论如何,都可以保证最近5个request的数据都是有序的。
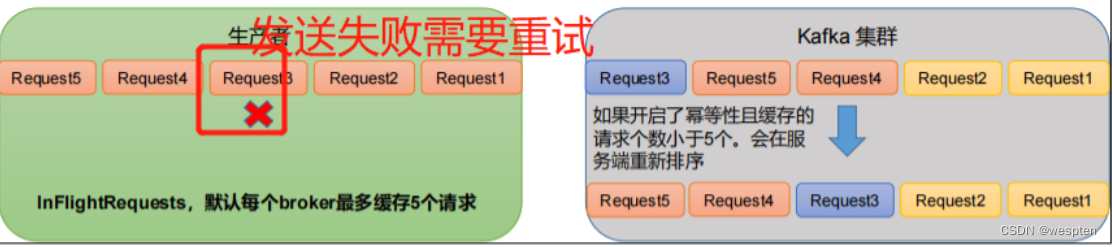
十、Kafka消费者原理详解
1、Kafka消费者简介
1. 消息消费者,向 Kafka broker 取消息的客户端。
2. 与生产者对应的是消费者, 应用程序可以通过KafkaConsumer来订阅主题, 并从订阅的topic中拉取消息。 每个消费者都有一 个对应的消费组。 当消息发布到主题后, 只会被投递给订阅它的每个消费组中的一 个消费者。
3. 单播消费:一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可。
4. 多播消费:一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费组即可。
2、Kafka 消费方式
1. pull(拉)模 式:consumer采用从broker中主动拉取数据, consumer 可以根据的消费能力以适当的速率消费消息。Kafka采用这种方式,缺点:如 果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
2. push(推)模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,而且每个消费者的消费速率也不同,所以很难适应所有消费者的消费速率。
例如推送的速度是50m/s,Consumer1、Consumer2就来不及处理消息。
3. 对于 Kafka 而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
4. pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,可以在拉取请求中 设置允许消费者请求在等待数据到达的“长轮询”中进行阻塞(并且可选地等待到给定的字节数,以确保大的传输大小)。

3、消费者总体工作流程
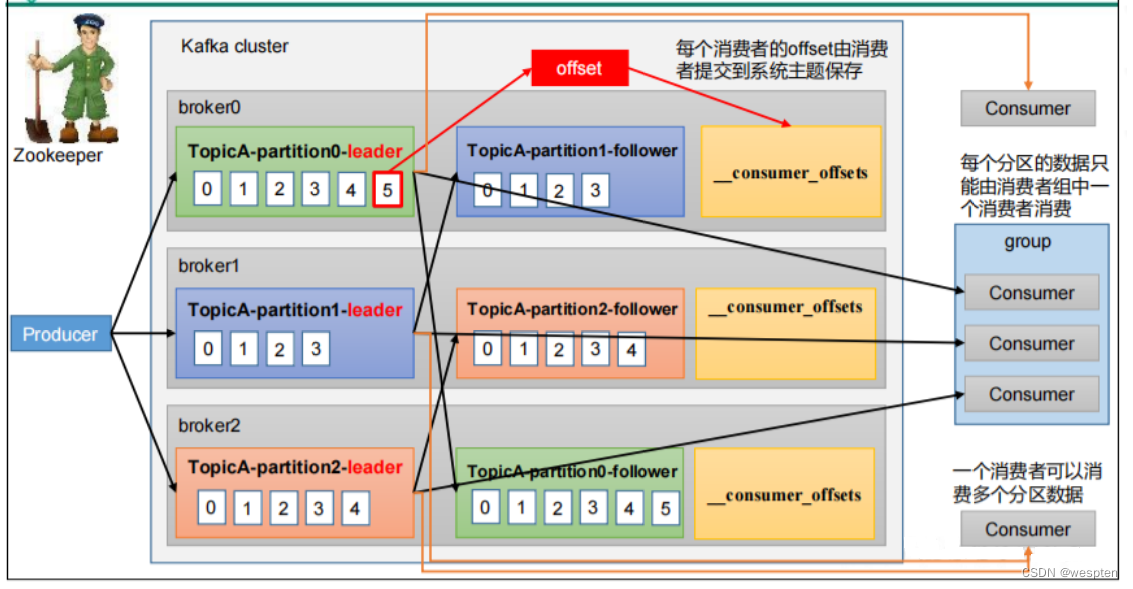
4、消费者组原理
kafka使用一种消费者组(Consumer Group)机制,就同时实现了传统消息引擎系统的两大模型:如果所有的消费者实例都属于一个消费者组那就是点对点模型,如果所有消费者实例各自是独立的消费者那就是发布订阅模型。
1)费者组Consumer Group
1. 消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同
2. 每个Consumer属于一个特定的Consumer Group,并且每个消费者Consumer都有一个group id,group id相同的多个消费者自动成为一个消费者组;
3. 所有的消费者都属于某个消费者组,对于某个分区而言,即消费者组是逻辑上的一个订阅者
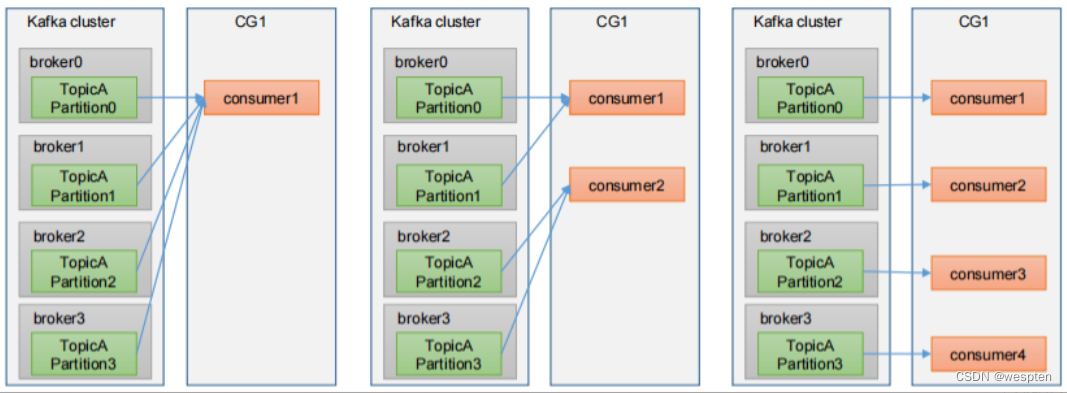
4. 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响
5. 一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息
6. 如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息

2)消费者组初始化流程
① coordinator的选择
1. coordinator:辅助实现消费者组的初始化和分区的分配。
2. 每个consumer group都会选择一个broker作为自己的组协调器coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后触发消费者rebalance(再平衡)。
3. coordinator选择公式: coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量)。
4. 例如:.groupid的hashcode值 = 1,1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
5. consumer group中的每个consumer启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。
② 消费者组的初始化和分区的分配
1. 根据coordinator选择公式选择 协调器coordinator节点 ,然后每个consumer启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。
2. 在成功加入到消费组之后,每个consumer都给coordinator发送JoinGroup请求。
3. 由coordinator节点选出一个consumer作为消费者leader 节点。
4. 然后coordinator节点把所有消费者以及把要消费的topic情况发送给leader 消费者。
5. 消费者leader会负责制定消费方案(消费者如何消费消息,消费那个分区等信息),把消费方案发给coordinator。
6. Coordinator就把消费方案下发给各个consumer。
7. 每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平横。

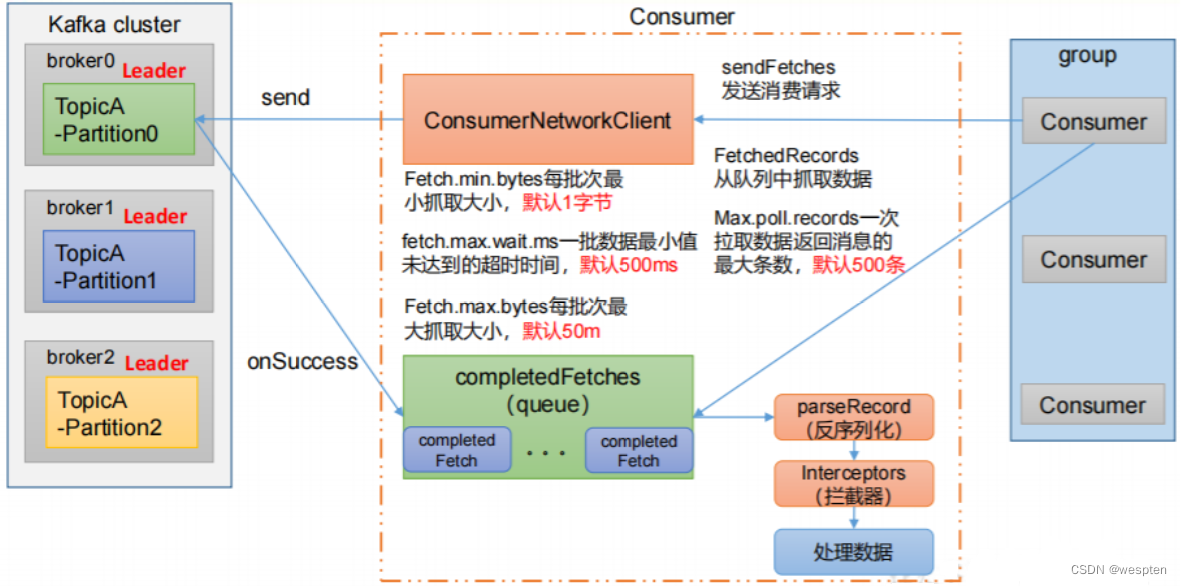
1. Fetch.min.bytes:每批次最小抓取大小,默认1字节。
2. fetch.max.wait.ms:一批数据最小值未达到的超时时间,默认500ms。
3. Fetch.max.bytes:每批次最大抓取大小,默认50m。
4. Max.poll.records:一次拉取数据返回消息的最大条数,默认500条。
5. auto.offset.reset:关乎kafka数据的读取,是一个非常重要的设置。
常用的二个值是latest和earliest,默认是latest:
latest(默认) :只消费自己启动之后发送到主题的消息,earliest:第一次从头开始消费,以后按照消费offset记录继续消费。
auto.offset.reset最好不要设置为latest,因为如果分区内的数据未被消费过,这时消费者上线,会导致消费者无法消费到前面的数据(当然也得看应用场景,如果认为这种情况的数据就该丢失,那当我没说)。
auto.offset.reset设置为earliest时,可能会有重复消费的问题,这就需要消费者端做数据去重处理。
③ 消费者常用API
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class MsgConsumer {
private final static String TOPIC_NAME = "my-replicated-topic";
private final static String CONSUMER_GROUP_NAME = "testGroup";
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094");
// 消费分组名
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
// 是否自动提交offset,默认就是true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
/*
当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费
latest(默认) :只消费自己启动之后发送到主题的消息
earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费)
*/
//props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
/*
consumer给broker发送心跳的间隔时间,broker接收到心跳如果此时有rebalance发生会通过心跳响应将
rebalance方案下发给consumer,这个时间可以稍微短一点
*/
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
/*
服务端broker多久感知不到一个consumer心跳就认为他故障了,会将其踢出消费组,
对应的Partition也会被重新分配给其他consumer,默认是10秒
*/
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
//一次poll最大拉取消息的条数,如果消费者处理速度很快,可以设置大点,如果处理速度一般,可以设置小点
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
/*
如果两次poll操作间隔超过了这个时间,broker就会认为这个consumer处理能力太弱,
会将其踢出消费组,将分区分配给别的consumer消费
*/
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// 消费指定分区
//consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//消息回溯消费
/*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));*/
//指定offset消费
/*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);*/
//从指定时间点开始消费
/*List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME);
//从1小时前开始消费
long fetchDataTime = new Date().getTime() - 1000 * 60 * 60;
Map<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo par : topicPartitions) {
map.put(new TopicPartition(topicName, par.partition()), fetchDataTime);
}
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) continue;
Long offset = value.offset();
System.out.println("partition-" + key.partition() + "|offset-" + offset);
System.out.println();
//根据消费里的timestamp确定offset
if (value != null) {
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
}*/
while (true) {
/*
* poll() API 是拉取消息的长轮询
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(),
record.offset(), record.key(), record.value());
}
/*if (records.count() > 0) {
// 手动同步提交offset,当前线程会阻塞直到offset提交成功
// 一般使用同步提交,因为提交之后一般也没有什么逻辑代码了
consumer.commitSync();
// 手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for " + offsets);
System.err.println("Commit failed exception: " + exception.getStackTrace());
}
}
});
}*/
}
}
}④ 生产经验——分区的分配以及再平衡
一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据,所以就需要分区的分配以及再平衡
1. 分区分配策略
Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。可以通过配置参数partition.assignment.strategy,修改消费者与订阅主题之间的分区分配策略
默认策略是Range + CooperativeSticky。Kafka可以同时使用多个分区分配策略
2. 分区分配策略之Range 以及再平衡
Range 是对每个 topic 而言的。首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
假如现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2,7/3 = 2 余 1 ,除不尽,那么 消费者 C0 便会多消费 1 个分区。假如 8/3=2余2,除不尽,那么C0和C1分别多消费一个。

注意:如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有 N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区,容易产生数据倾斜。
5、分区分配策略Range的再平衡案例
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)45s(session.timeout.ms=45s)消费者都会和coordinator保持心跳(默认3s)不能超过45s,一旦超时该消费者会被移除。
结果:1 号消费者消费到 3、4 号分区的数据。2 号消费者消费到 5、6 号分区的数据; 0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
再次重新发送消息观看结果(45s 以后)
结果:1 号消费者:消费到 0、1、2、3 号分区数据,2 号消费者:消费到 4、5、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
(2)分区分配策略之RoundRobin以及再平衡
1. RoundRobin 针对集群中所有Topic而言,RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
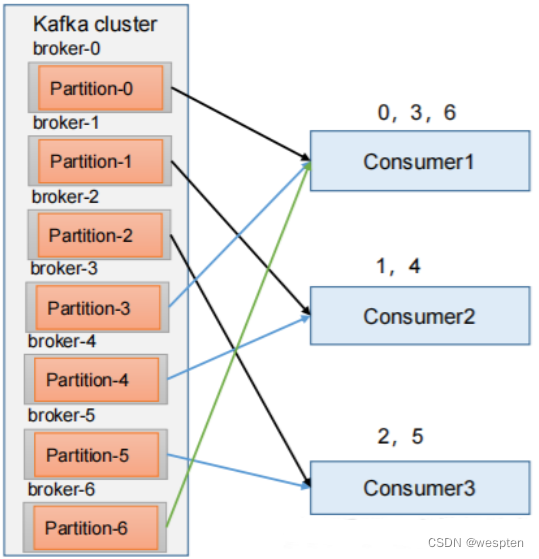
(3)分区分配策略RoundRobin的再平衡案例:
停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)
结果:1 号消费者消费到 2、5 号分区的数据,2 号消费者消费到 4、1 号分区的数据, 0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、6 和 3 号分区数据,分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
再次重新发送消息观看结果(45s 以后)。
结果:1 号消费者消费到 0、2、4、6 号分区的数据,2 号消费者消费到 1、3、5 号分区的数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
(4)分区分配策略之Sticky以及再平衡
1. 粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
2.粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
3.sticky(粘性分区)策略初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下三个原则。
1)分区的分配要尽可能均匀 。
2)分区的分配尽可能与上次分配的保持相同。
3)当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。
(5)Sticky 分区分配再平衡案例
停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
结果:1 号消费者消费到 2,5,3 号分区的数据, 2 号消费者消费到 4,6 号分区的数据, 0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
再次重新发送消息观看结果(45s 以后)。
结果:1 号消费者消费到 2、3、5 号分区的数据。2 号消费者消费到 0、1、4、6 号分区的数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
6、offset 位移
1)offset的默认维护位置
1. 从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
2. Kafka0.9版本之前,consumer默认将offset保存在Zookeeper中。
3. __consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行清理,也就是每个 group.id+topic+分区号就保留最新数据。
4. 每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets。
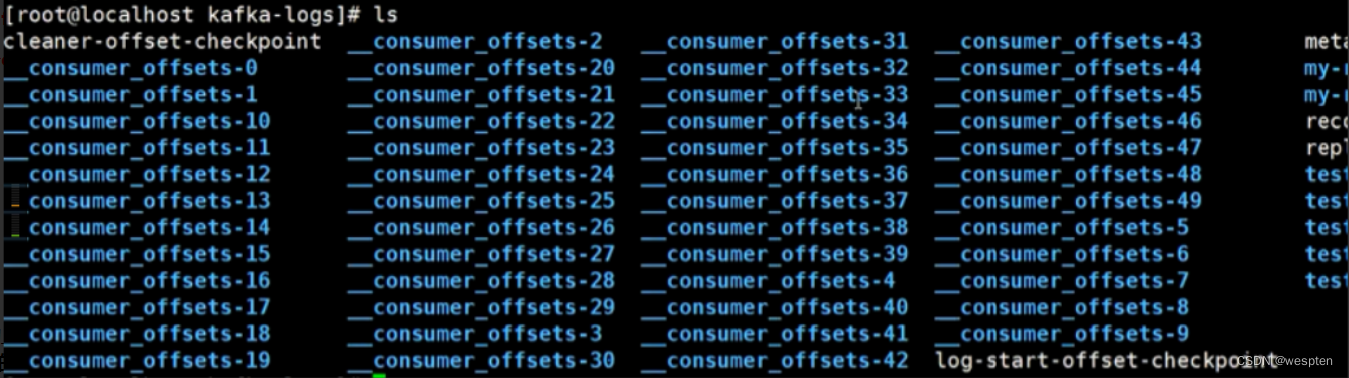
5. 因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
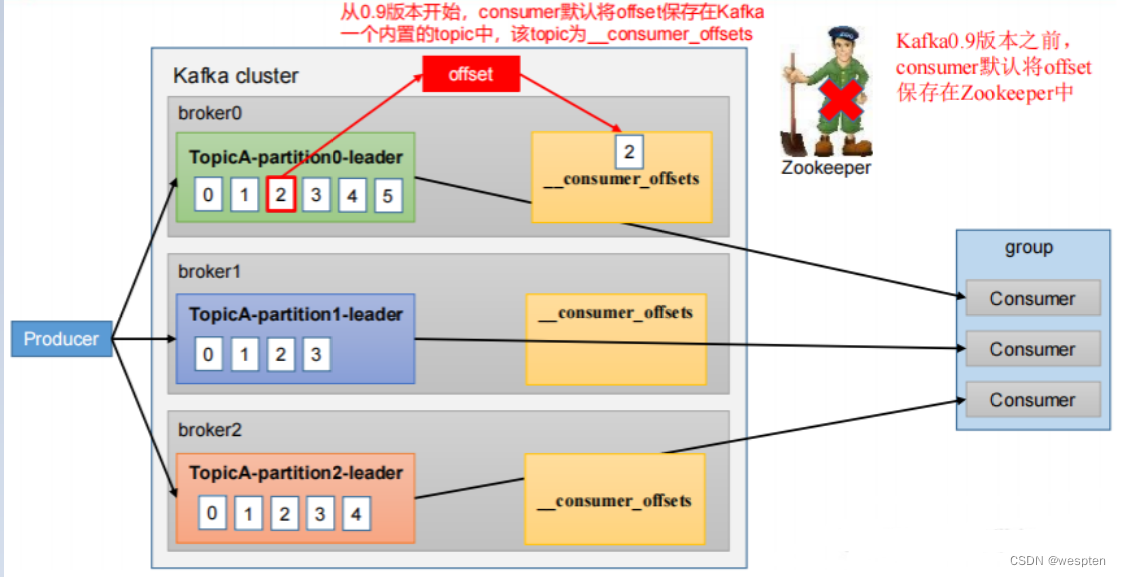
2)自动提交 offset
1. 为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
2. 消费者会每隔一段时间地自动向服务器提交偏移量。

3. 自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能,默认是true
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s重复消费
问题:自动提交offset引起引起重复消费问题;已经消费了数据,但是 offset 没提交。
问题的发生:Consumer每5s提交offset 如果提交offset后的2s,consumer挂了, 再次重启consumer,则从上一次提交的offset处继续消费,导致重复消费。

问题解决方案:怎么能做到既不漏消费(后面讲)也不重复消费呢?详看消费者事务。
3)手动提交 offset
1. 虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
2. 手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。
3. 两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
4. api参考上面代码。

① commitSync(同步提交)
1. 必须等待offset提交完毕,再去消费下一批数据。
2. 提交的一批数据最高的偏移量提交,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败)。
3. 由于同步提交 offset 有失败重试机制,故更加可靠,但是由于一直等待提交结果,提交的效率比较低,因此吞吐量会受到很大的影响,但是也提高了可靠性。
② commitAsync(异步提交)
1. 发送完提交offset请求后,就开始消费下一批数据了。
2. 提交的一批数据最高的偏移量提交,而异步提交则没有失败重试机制,故有可能提交失败,介于commitSync(同步提交)效率低的问题,因此更多的情况下,会选用异步提交 offset 的方式。
③ 漏消费
问题:手动提交offset引起引起漏消费问题;先提交 offset 后消费,有可能会造成数据的漏消费。
问题的发生:当offset被提交时,数据还在内存中未落盘,此时刚好消费者线程被kill掉或者挂了,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。

问题解决方案:怎么能做到既不漏消费(后面讲)也不重复消费呢?详看消费者事务。
④ 指定 Offset 消费
1. 当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
2. auto.offset.reset = earliest | latest | none 默认是 latest.
earliest:自动将偏移量重置为最早的偏移量,--from-beginning。
latest(默认值):自动将偏移量重置为最新偏移量。
none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。

3. 如何实现
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) continue;
Long offset = value.offset();
System.out.println("partition-" + key.partition() + "|offset-" + offset);
System.out.println();
//根据消费里的timestamp确定offset
if (value != null) {
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
}*/7、生产经验——消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset,过程做原子绑定,需要将Kafka的offset保存到支持事务的自定义介质(比 如MySQL)
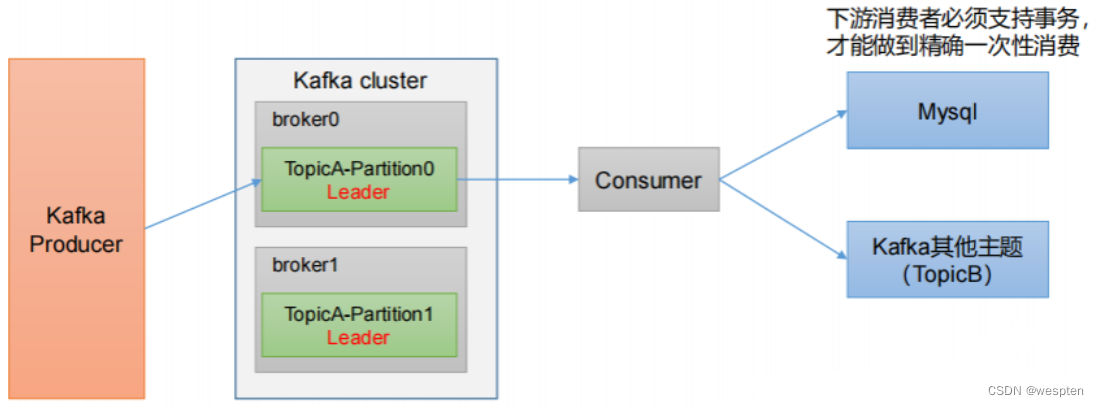
8、生产经验——数据积压(消费者如何提高吞吐量)
情况1:由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。
情况2:线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。
情况1解决方案:可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。
情况2解决方案:
1)如果是Kafka消费能力不足:则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数(两者缺一不可)。
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。
3)优化参数1:fetch.max.bytes :默认 Default: 52428800(50m)消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (brokerconfig)or max.message.bytes (topic config)影响。
4)优化参数2:max.poll.records:一次 poll 拉取数据返回消息的最大条数,默认是 500 条。

十一、Kafka Broker原理详解
1、Zookeeper 存储的 Kafka 信息
如何查看:
(1)启动 Zookeeper 客户端。
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
(2)通过 ls 命令可以查看 kafka 相关信息。在zookeeper的服务端存储的Kafka相关信息:
1)/kafka/brokers/ids [0,1,2] 记录有哪些服务器,在配置文件中配置的那个 broker.id这个就用于唯一标识kafka的一个服务实例,kafka启动的时候,会将这个信息上报zk
2)/kafka/brokers/topics/first/partitions/0/state {"leader":1 ,"isr":[1,0,2] }记录了在first中,0号分区下谁是Leader,有哪些服务器可用
3)/kafka/controller{“brokerid”:0}辅助选举Leader
4) /kafka/consumers 0.9版本之前用于保存offset信息,0.9版本之后offset存储在kafka主题中
5) 其他信息
admin,里面维护着删除的topic信息
brokers,维护着kafkabroker相关的节点信息,包括topic、topic中的分区信息等
cluster,集群元信息
consumers,0.9版本之前用于保存offset信息,0.9版本之后offset存储在kafka主题中
controller,维护着集群中leader信息
config,存储集群配置相关的信息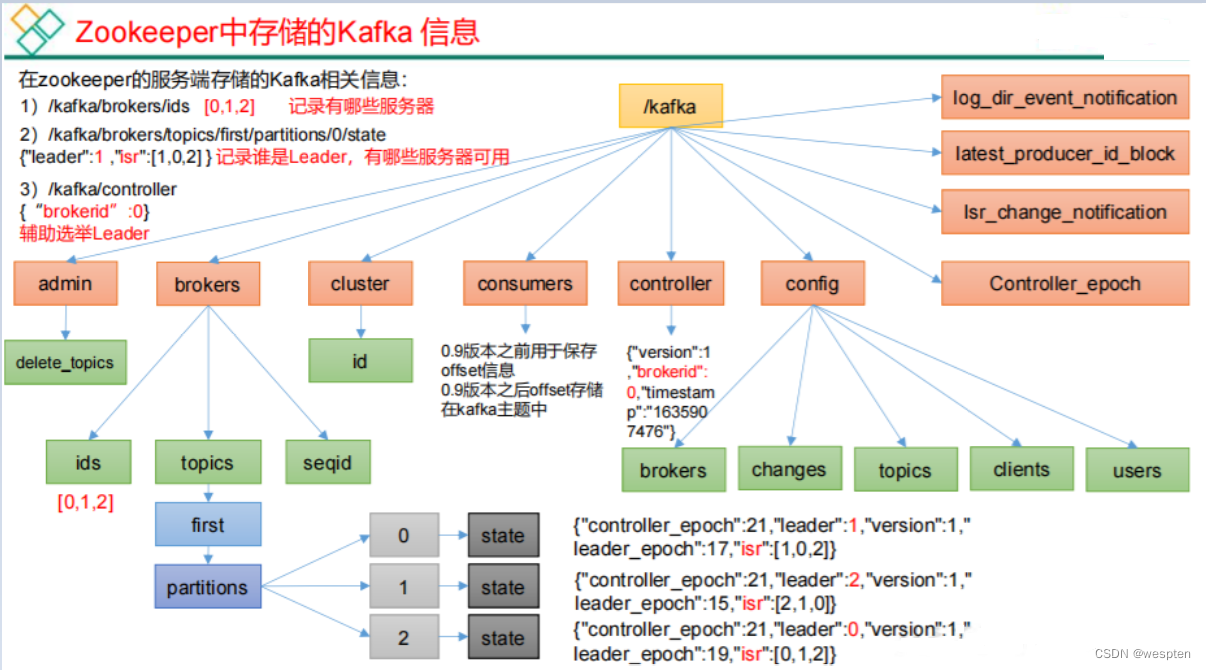
2、Broker 重要参数
1. replica.lag.time.max.ms: ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。
2. Aaauto.leader.rebalance.enable 默认是 true。 自动 Leader Partition 平衡。
3. leader.imbalance.per.broker.percentage 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。
4. leader.imbalance.check.interval.seconds 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
5 .log.segment.bytes: Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。
6. log.index.interval.bytes:默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。
7. log.retention.hour Kafka 中数据保存的时间,默认 7 天。
8. log.retention.minutes: Kafka 中数据保存的时间,分钟级别,默认关闭。
9. log.retention.ms: Kafka 中数据保存的时间,毫秒级别,默认关闭。
10. log.retention.check.interval.ms:检查数据是否保存超时的间隔,默认是 5 分钟。
11. log.retention.bytes: 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。
12. log.cleanup.policy: 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。
13. num.io.threads: 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。
14. num.replica.fetchers:副本拉取线程数,这个参数占总核数的 50%的 1/3。
15. num.network.threads:默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。
16. log.flush.interval.messages:强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。
17. log.flush.interval.ms: 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。
3、Kafka 副本
副本基本信息
1)Kafka 副本作用:提高数据可靠性。
2)Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader,然后 Follower 找 Leader 进行同步数据。
4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
5)副本进入ISR列表有两个条件:
1. 副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通。
2. 副本能复制leader上的所有写操作,并且不能落后太多。(如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s)。
Leader 选举流程
① Kafka核心总控制器Controller
1. 在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态,同时负责管理集群broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
2. 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
3. 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
4. 当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
5. Controller 的信息同步工作是依赖于 Zookeeper 的。
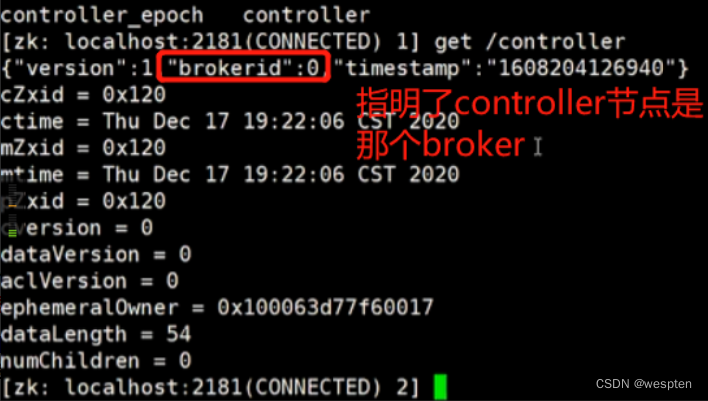
② Controller选举机制
1. 在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点.zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。
2. 当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
3.具备控制器身份的broker需要比其他普通的broker多一份职责,例如下:
1) 监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
2) 监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
3) 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
4) 更新集群的元数据信息,同步到其他普通的broker节点中。
③ 副本Leader 选举流程
1)核心总控制器Controller选举成功之后,开始选择Leader副本。
2)由选举出来的Controller监听brokers节点变化 ->(/kafka/brokers/ids [0,1,2]),同时决定Leader的选举。
3)选举规则:在isr中存活为前提,按照AR中排在前面的优先。例如ar[1,0,2],isr [1,0,2],那么leader就会按照1,0,2的顺序轮询。
4)Controller将节点副本的Leader和Follower信息上传到ZK->(/brokers/topics/first/partitions/0/state"leader"1: ,"isr":[1,0,2 ])。
5)其他contorller从zk同步Leader和Follower等相关信息。
6)假设Broker1中Leader挂了,这时由选举出来的Controller监听brokers节点变化.同时拉取ISR存活节点副本数。
7)重新选举新的Leader,并且更新Leader及ISR。
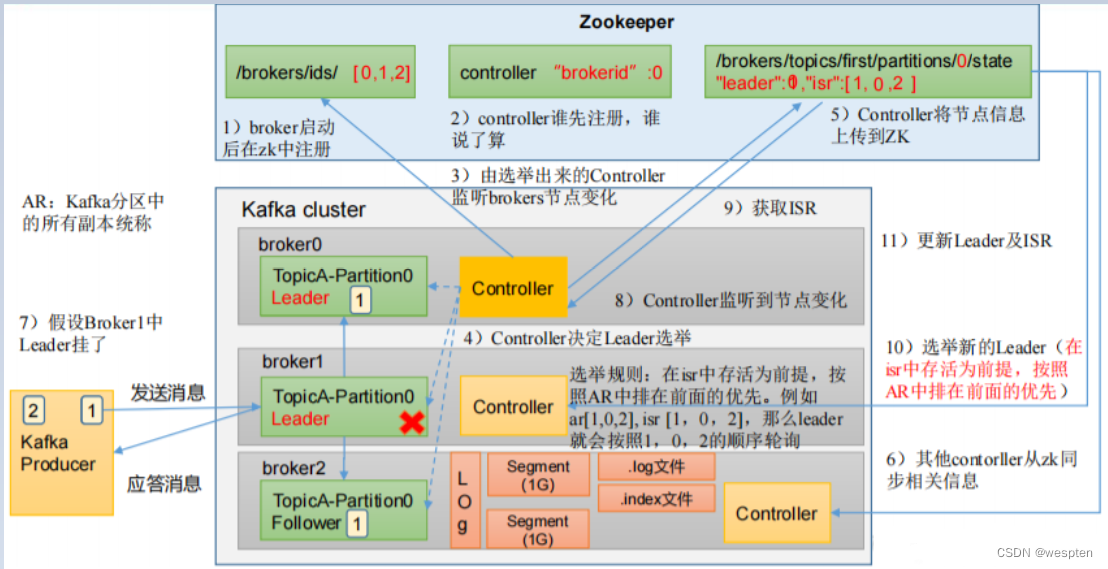
Leader 和 Follower故障处理细节
① HW与LEO
1. LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。
2. HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW,也就是所有副本中最小的LEO.保证消费者消费数据的一致性。
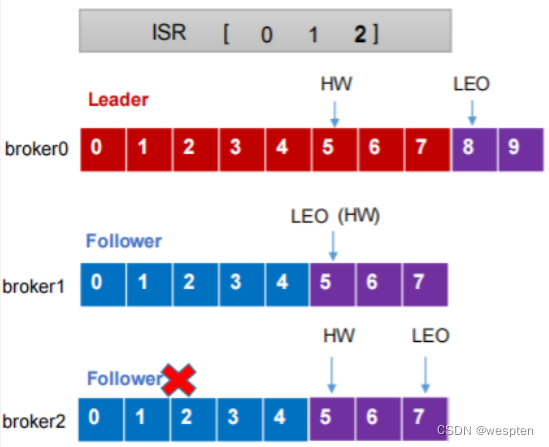
3. consumer最多只能消费到HW所在的位置。
4. 每个replica都有HW,leader和follower各自负责更新自己的HW的状态。
5. leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。
6. 这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broker的读取请求,没有HW的限制。
② ISR以及HW和LEO的流转过程
1. Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。
2. 而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
3. 流转过程
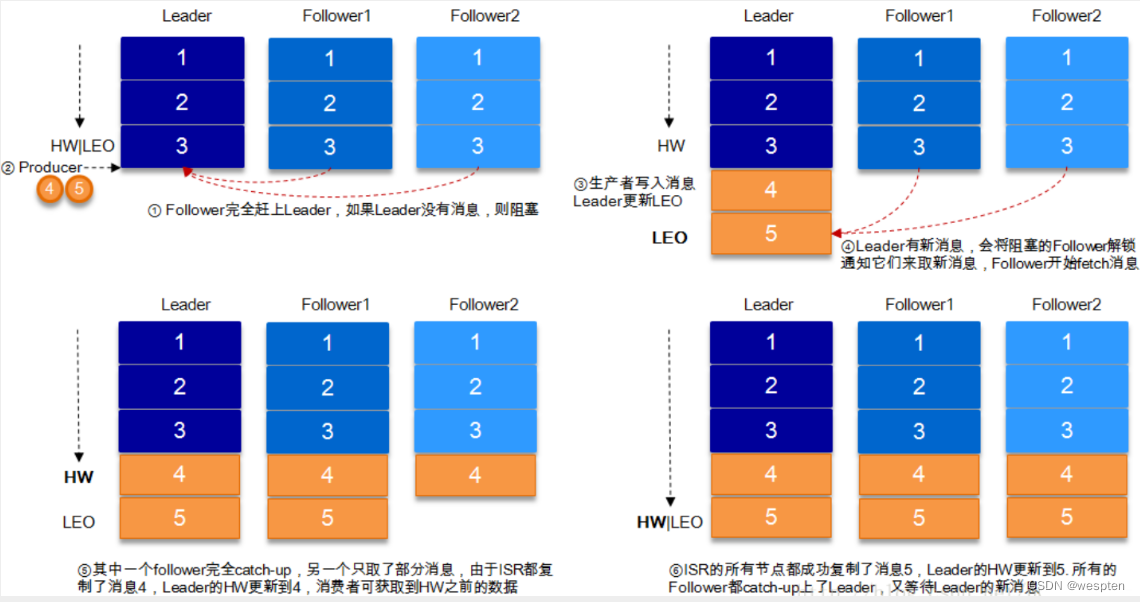
4. 结合HW和LEO看下 acks=1的情况

Follower故障
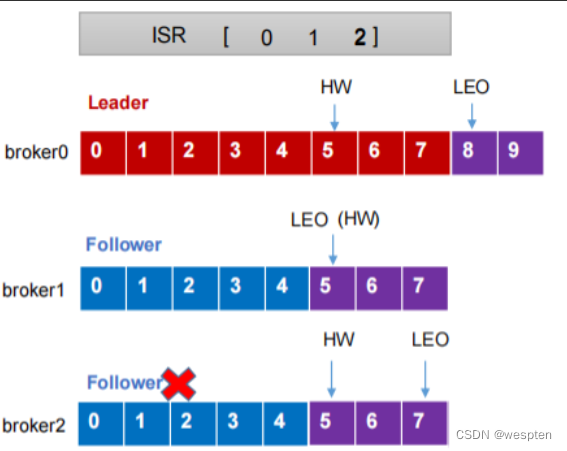
Follower故障说明:
(1) Follower发生故障后会被临时踢出ISR, 这个期间Leader和其他的Follower继续接收数据
(2)待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
(3)等该Follower的LEO大于等于该Partition的HW,即该Follower追上Leader之后,就可以重新加入ISR了。
Leader故障
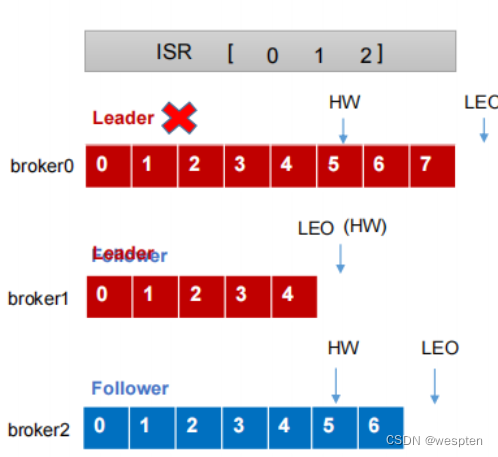
Leader故障说明:
(1)Leader发生故障之后,会从ISR中选出一个新的Leader
(2)为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
生产经验——Leader Partition 负载平衡
1. 正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
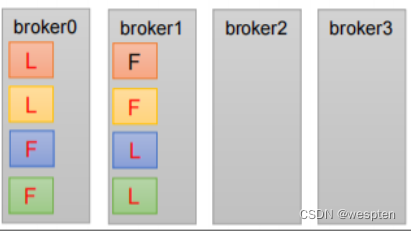
2.下面拿一个主题举例说明,假设集群只有一个主题如下图所示:

针对broker0节点,分区2的AR优先副本是0节点,但是0节点却不是Leader节点,所以不平衡数加1,AR副本总数是4,所以broker0节点不平衡率为1/4>10%,需要再平衡。
broker2和broker3节点和broker0不平衡率一样,需要再平衡。Broker1的不平衡数为0,不需要再平衡。
3. 参数:
1. auto.leader.rebalance.enable,默认是true。 自动Leader Partition 平衡,生产建议关闭或者允许的不平衡的leader的比率设置大一些, 否则会消耗大量服务器的性能。
2. leader.imbalance.per.broker.percentage,默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。
3. leader.imbalance.check.interval.seconds,默认值300秒。检查leader负载是否平衡的间隔时间。
4、文件存储机制
1)Topic 数据的存储机制
1. Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。
2. Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。
3. Kafka 一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。
4. Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段(segment)文件的大小,最大就是 1GB。
5. 一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling,正在被写入的那个日志段文件,叫做 active log segment。

总结:
1) 一个topic分为多个partition,一个partition分为多个segment,每个segment文件的大小,最大就是 1GB,每个segment文件包括:“.index”文件、“.log”文件和.timeindex等文件。
2) .log 日志文件,主要存offset和消息体。
3) index 偏移量索引文件,部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件(index为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引)。
4) timeindex 时间戳索引文件 ,也就是消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,如果需要按照时间来定位消息的offset,会先在这个文件里查找。
5) 说明:index和log文件以当前segment的第一条消息的offset命名。
6). Index文件中保存的offset为相对offset,这样能确保offset的值所占空间不会过大,因此能将offset的值控制在固定大小。
2)数据的查找过程
1. 根据目标offset定位Segment文件。
2. 找到小于等于目标offset的最大offset对应的索引项,定位到log文件。
3. 向下遍历找到目标Record。
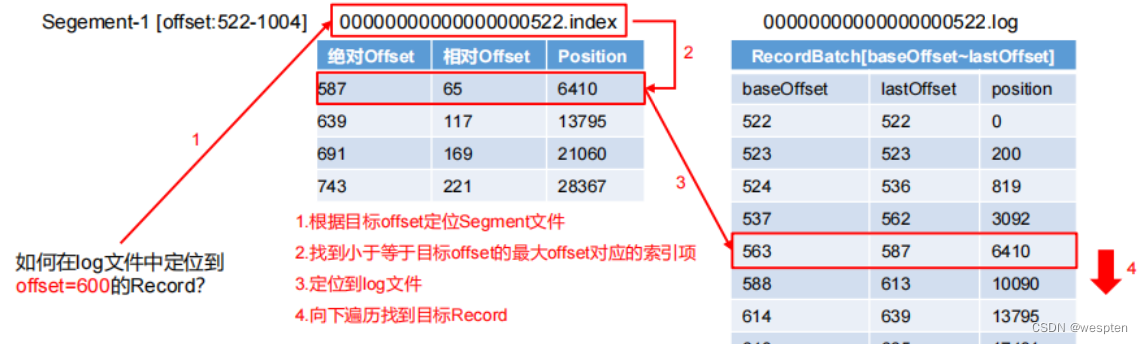
3)日志存储参数配置
1. log.segment.bytes:Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G。
2. log.index.interval.bytes:默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 稀疏索引。
4)文件清理策略
1. Kafka 中默认的日志保存时间为 7 天。
2. Kafka 中提供的日志清理策略有 delete 和 compact 两种。
① 清理策略的参数配置
1. log.retention.hours:小时,默认 7 天。
2. log.retention.minutes:分钟。
3. log.retention.ms:毫秒。
4. 前三种参数说明:优先级->如果配置了毫秒参数,则其他分钟与小时参数无效,如果配置了分钟参数,小时参数无效。
5. log.retention.check.interval.ms:负责设置检查周期,默认 5 分钟。
6. log.cleanup.policy = delete 或者compact: 清理策略配置 ,默认为delete。
7. log.retention.bytes:在清理策略为delete时,基于Segment大小删除时,用于设置segment日志大小,默认等于-1,表示无穷大。
② 文件清理策略之delete
1. delete 日志删除:将过期数据删除。
2. 基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
3. 基于大小:默认关闭。超过设置的所有日志总大小(可配置),删除最早的 segment(不推荐)。
4. 问题1:如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?
5. 问题1解决方案:数据过期的就等着,等着日志文件中,最大的时间戳对应数据过期后一起删除。
③ 文件清理策略之compact
1. compact日志压缩:对于相同key的不同value值,只保留最后一个版本。
2. 这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
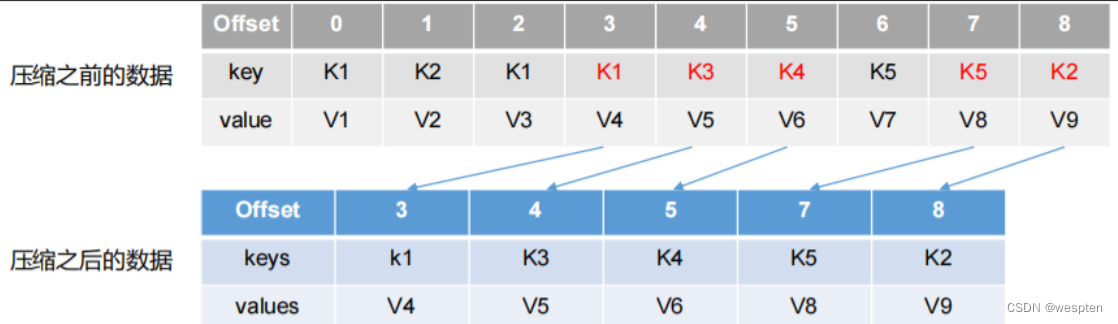
3. 压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。
5)高效读写数据
1. Kafka 本身是分布式集群,可以采用分区技术,并行度高。
2. 读数据采用稀疏索引,可以快速定位要消费的数据。
3. 顺序写磁盘。
4. 页缓存 + 零拷贝技术。
① 顺序写磁盘
1. kafka消息不能修改以及不会从文件中间删除保证了磁盘顺序读,kafka的消息写入文件都是追加在文件末尾,不会写入文件中的某个位置(随机写)保证了磁盘顺序写。
2. Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。
3. 官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
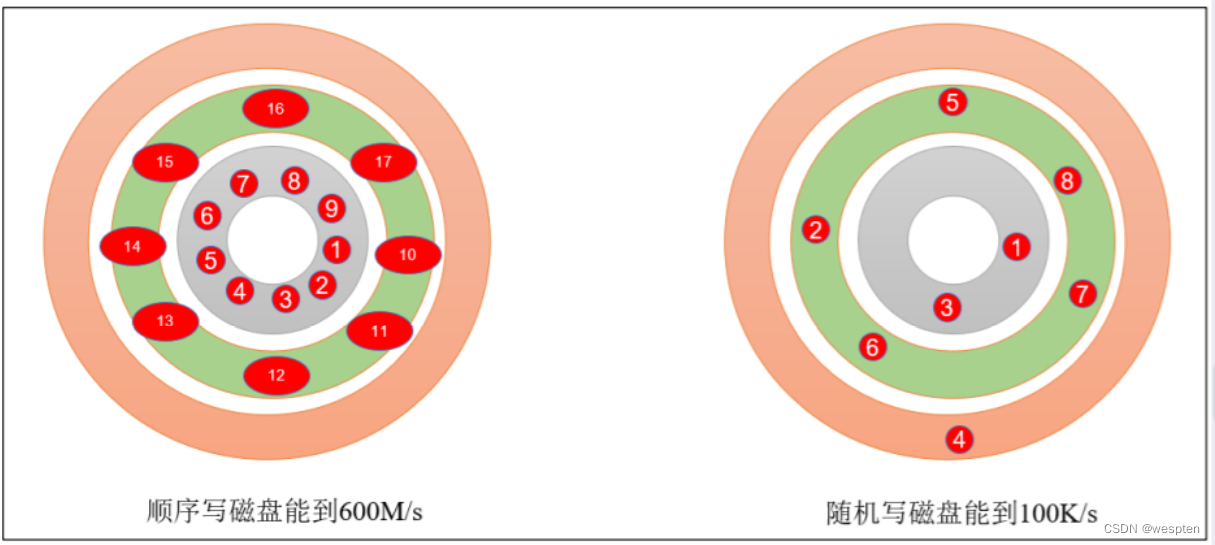
② 页缓存 + 零拷贝技术
1. 零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。
2. PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。 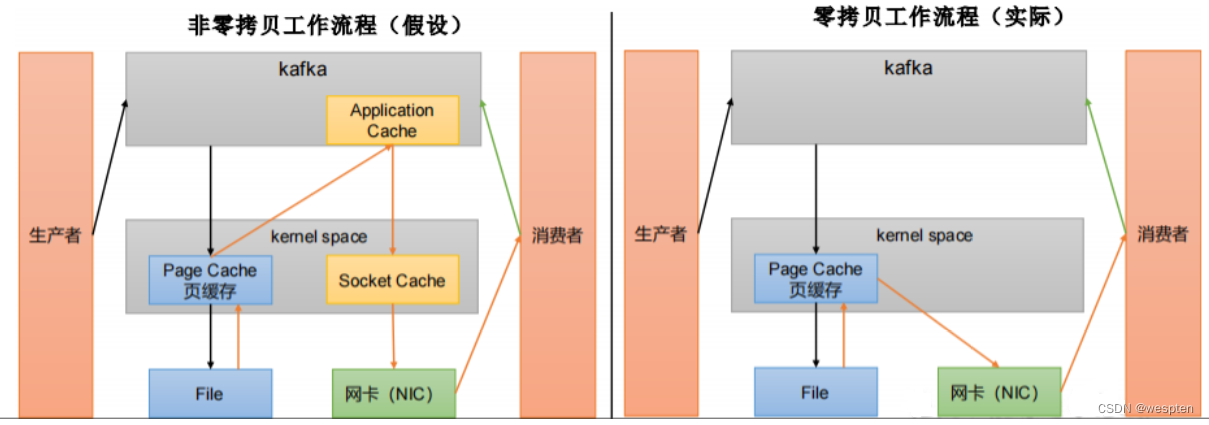
③ 参数配置
1. log.flush.interval.messages:强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。
2. log.flush.interval.ms:每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理。