并行度设置&优先级
并行度(Parallelism)
并行度的设置
在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
代码中设置
我们在代码中,可以很简单地在算子后跟着调用setParallelism()方法,来设置当前算子的并行度:
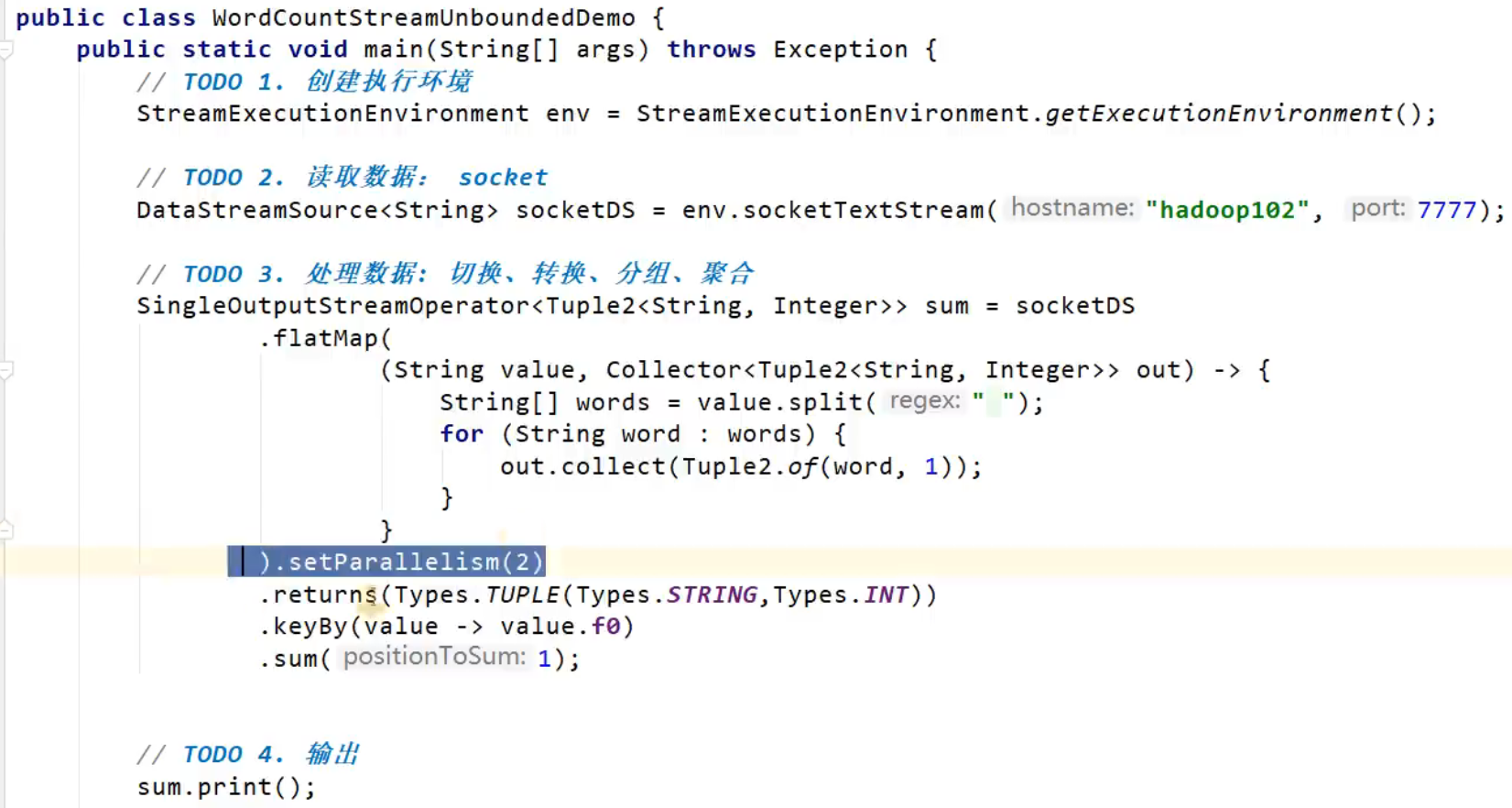
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
这种方式设置的并行度,只针对当前算子有效。
另外,我们也可以直接调用执行环境的setParallelism()方法,全局设定并行度:
env.setParallelism(2);
这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
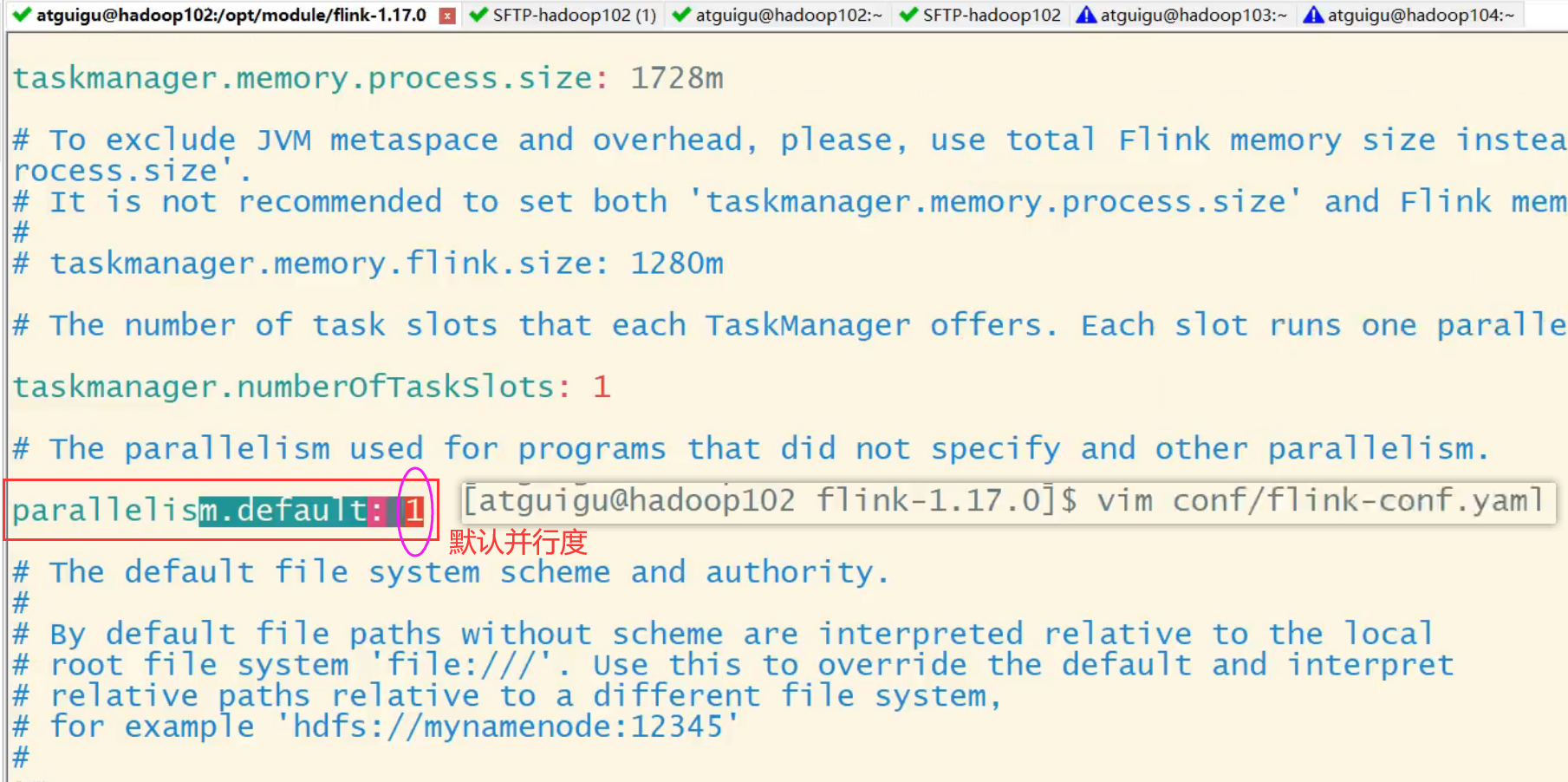
提交应用时设置
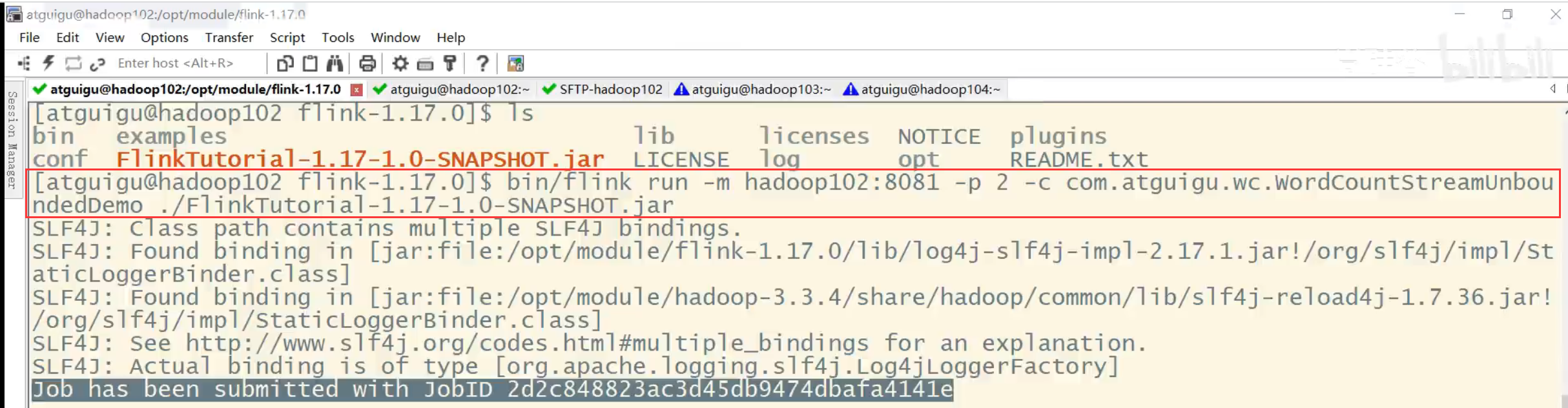
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置:
bin/flink run –p 2 –c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
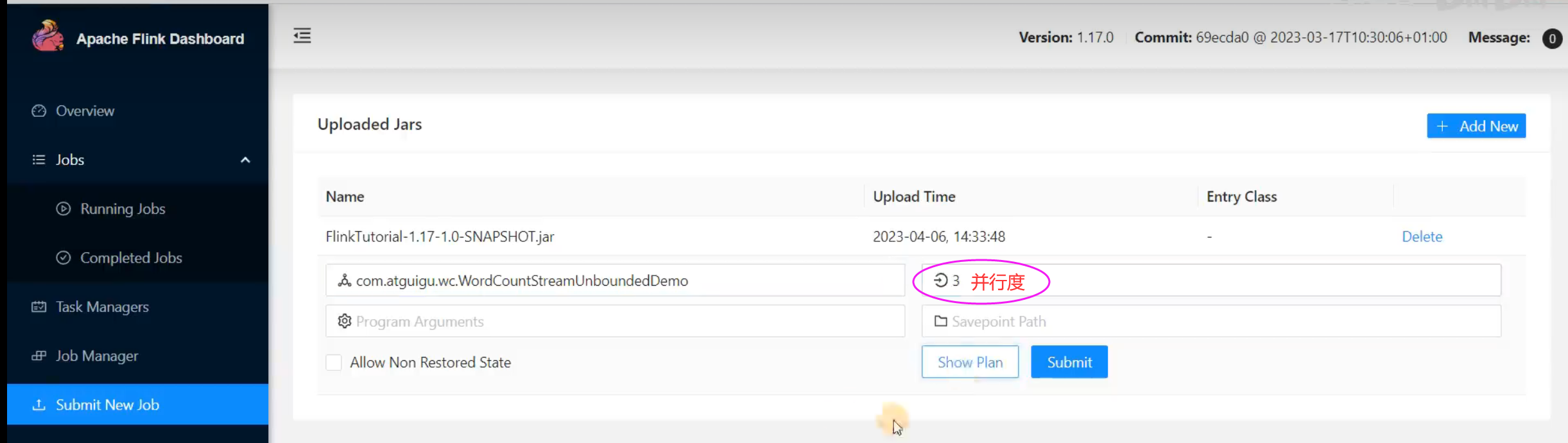
如果我们直接在Web UI上提交作业,也可以在对应输入框中直接添加并行度。
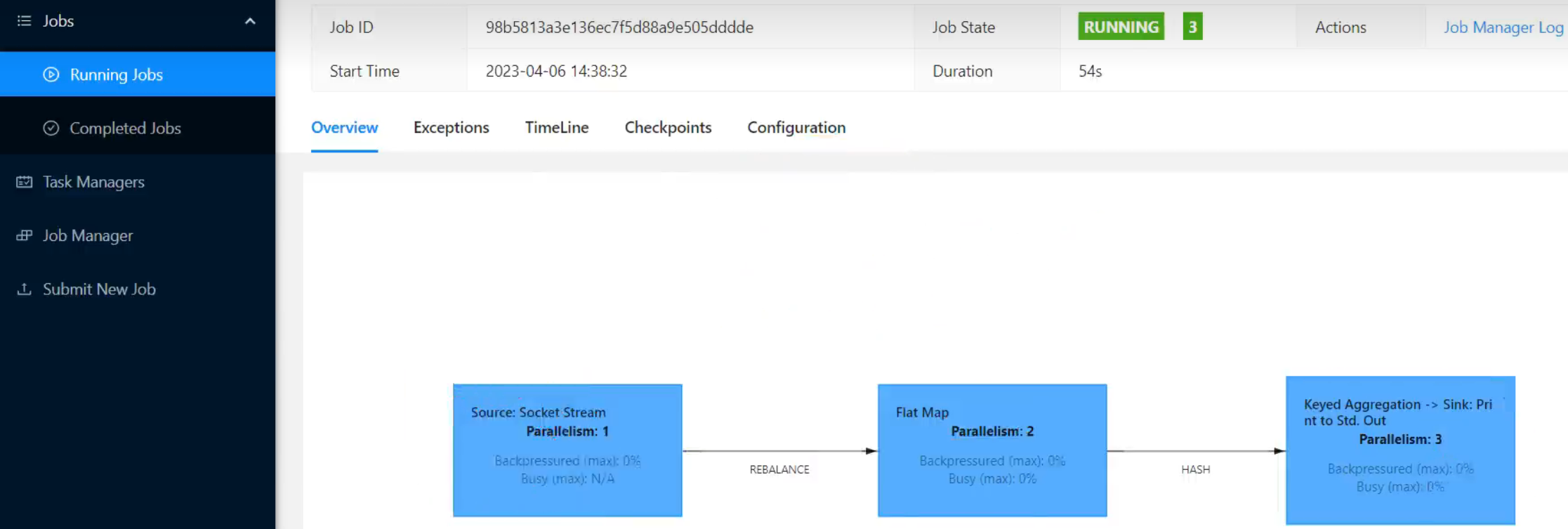
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author
* @version 1.0
*/
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
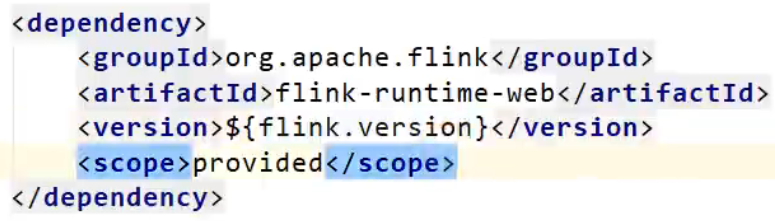
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2.读取数据: socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3.处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING,Types.INT))
// .returns(new TypeHint<Tuple2<String, Integer>>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4.输出
sum.print();
// TODO 5.执行
env.execute();
}
}
/**
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
*/
并行度的优先级
代码:算子 > 代码:env > 提交时指定 > 配置文件